八、ORDER BY优化
前言:在使用order by时,经常出现Using filesort,因此对于此类sql语句需尽力优化,使其尽量使用Using index。
0.准备
#1.创建test表。
drop table if exists test;create table test(id int primary key auto_increment,c1 varchar(10),c2 varchar(10),c3 varchar(10),c4 varchar(10),c5 varchar(10)) ENGINE=INNODB default CHARSET=utf8;insert into test(c1,c2,c3,c4,c5) values('a1','a2','a3','a4','a5');insert into test(c1,c2,c3,c4,c5) values('b1','b2','b3','b4','b5');insert into test(c1,c2,c3,c4,c5) values('c1','c2','c3','c4','c5');insert into test(c1,c2,c3,c4,c5) values('d1','d2','d3','d4','d5');insert into test(c1,c2,c3,c4,c5) values('e1','e2','e3','e4','e5');
#2.创建索引。
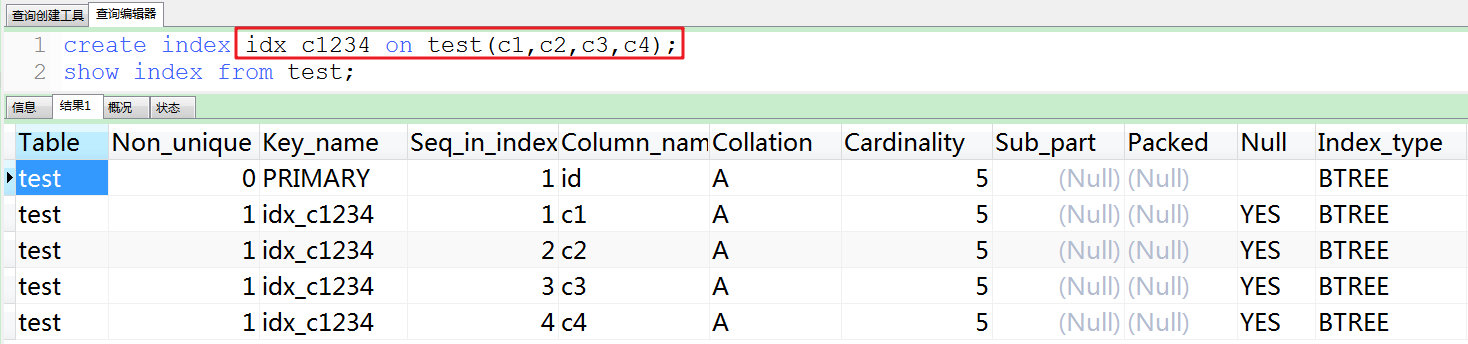
1.根据Case分析order by的使用情况
Case 1:

分析:
①在c1,c2,c3,c4上创建了索引,直接在c1上使用范围,导致了索引失效,全表扫描:type=ALL,ref=Null。因为此时c1主要用于排序,并不是查询。
②使用c1进行排序,出现了Using filesort。
③解决方法:使用覆盖索引。

Case 1.1:

分析:
排序时按照索引的顺序,所以不会出现Using filesort。
Case 1.2:

分析:
出现了Using filesort。原因:排序用的c2,与索引的创建顺序不一致,对比Case1.1可知,排序时少了c1(带头大哥),因此出现Using filesort。
Case 1.3:

分析:
出现了Using filesort。因为排序索引列与索引创建的顺序相反,从而产生了重排,也就出现了Using filesort。
Case 2:


分析:
直接使用c2进行排序,出现Using filesort,因为不是从最左列索引开始排序的(没有带头大哥)。
Case 2.1:

分析:
排序使用了索引顺序(带头大哥在),因此不会出现Using filesort。
Case 2.2:

分析:
虽然排序的字段列与索引顺序一样,且order by默认升序,这里c2 desc变成了降序,导致与索引的排序方式不同,从而产生Using filesort。
总结:
①MySQL支持两种方式的排序filesort和index,Using index是指MySQL扫描索引本身完成排序。index效率高,filesort效率低。
②order by满足两种情况会使用Using index。
#1.order by语句使用索引最左前列。
#2.使用where子句与order by子句条件列组合满足索引最左前列。
③尽量在索引列上完成排序,遵循索引建立(索引创建的顺序)时的最佳左前缀法则。
④如果order by的条件不在索引列上,就会产生Using filesort。
#1.filesort有两种排序算法:双路排序和单路排序。
双路排序:在MySQL4.1之前使用双路排序,就是两次磁盘扫描,得到最终数据。读取行指针和order by列,对他们进行排序,然后扫描已经排好序的列表,按照列表中的值重新从列表中读取对应的数据输出。即从磁盘读取排序字段,在buffer进行排序,再从磁盘取其他字段。
如果使用双路排序,取一批数据要对磁盘进行两次扫描,众所周知,I/O操作是很耗时的,因此在MySQL4.1以后,出现了改进的算法:单路排序。
单路排序:从磁盘中查询所需的列,按照order by列在buffer中对它们进行排序,然后扫描排序后的列表进行输出。它的效率更高一些,避免了第二次读取数据,并且把随机I/O变成了顺序I/O,但是会使用更多的空间,因为它把每一行都保存在内存中了。
#2.单路排序出现的问题。
当读取数据超过sort_buffer的容量时,就会导致多次读取数据,并创建临时表,最后多路合并,产生多次I/O,反而增加其I/O运算。
解决方式:
a.增加sort_buffer_size参数的设置。
b.增大max_length_for_sort_data参数的设置。
⑤提升order by速度的方式:
#1.在使用order by时,不要用select *,只查询所需的字段。
因为当查询字段过多时,会导致sort_buffer不够,从而使用多路排序或进行多次I/O操作。
#2.尝试提高sort_buffer_size。
#3.尝试提高max_length_for_sort_data。
⑥附上一张从视频中截取出来的总结图。
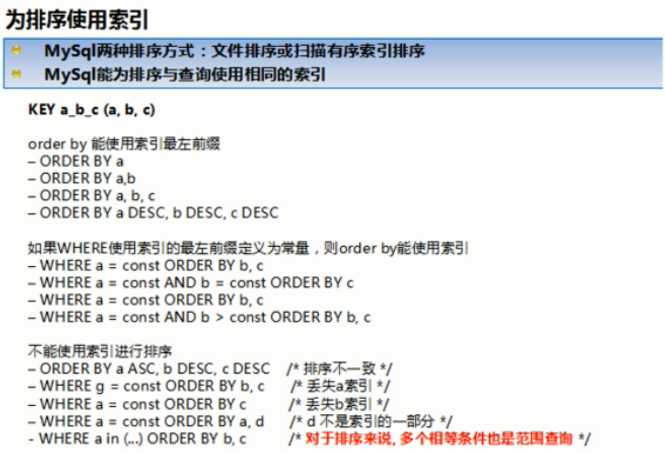
⑦group by与order by很类似,其实质是先排序后分组,遵照索引创建顺序的最佳左前缀法则。当无法使用索引列的时候,也要对sort_buffer_size和max_length_for_sort_data参数进行调整。注意where高于having,能写在where中的限定条件就不要去having限定了。
八、ORDER BY优化的更多相关文章
- MySQL性能优化,MySQL索引优化,order by优化,explain优化
前言 今天我们来讲讲如何优化MySQL的性能,主要从索引方面优化.下期文章讲讲MySQL慢查询日志,我们是依据慢查询日志来判断哪条SQL语句有问题,然后在进行优化,敬请期待MySQL慢查询日志篇 建表 ...
- 8.2.1.15 ORDER BY Optimization ORDER BY 优化
8.2.1.15 ORDER BY Optimization ORDER BY 优化 在一些情况下, MySQL 可以使用一个索引来满足一个ORDER BY 子句不需要做额外的排序 index 可以用 ...
- Mysql序列(七)—— order by优化
前言 在mysql中满足order by的处理方式有两种: 让索引满足排序,即扫描有序索引然后再找到对应的行结果,这样结果即是有序: 使用索引查询出结果或者扫描表得到结果然后使用filesort排序: ...
- Mysql查询优化汇总 order by优化例子,group by优化例子,limit优化例子,优化建议
Mysql查询优化汇总 order by优化例子,group by优化例子,limit优化例子,优化建议 索引 索引是一种存储引擎快速查询记录的一种数据结构. 注意 MYSQL一次查询只能使用一个索引 ...
- MySQL高级知识(八)——ORDER BY优化
前言:在使用order by时,经常出现Using filesort,因此对于此类sql语句需尽力优化,使其尽量使用Using index. 0.准备 #1.创建test表. drop table i ...
- mysql order by 优化 |order by 索引的应用
在某些场景,在不做额外的排序情况下,MySQL 可以使用索引来满足 ORDER BY 子句的优化.虽然 ORDER BY并不完全精确地匹配索引,但是索引还是会被使用,只要在WHERE子句中,所有未被使 ...
- order by优化--Order By实现原理分析和Filesort优化
在MySQL中的ORDER BY有两种排序实现方式: 1.利用有序索引获取有序数据 2.文件排序 在使用explain分析查询的时候,利用有序索引获取有序数据显示Using index.而文件排序显示 ...
- hive学习(八)hive优化
Hive 优化 1.核心思想: 把Hive SQL 当做Mapreduce程序去优化 以下SQL不会转为Mapreduce来执行 select仅查询本表字段 where仅对本表字段做条件过滤 Ex ...
- mysql实战优化之六:Order by优化 sql优化、索引优化
在MySQL中的ORDER BY有两种排序实现方式: 1.利用有序索引获取有序数据 2.文件排序 在使用explain分析查询的时候,利用有序索引获取有序数据显示Using index.而文件排序显示 ...
随机推荐
- Educational Codeforces Round 80 A-E简要题解
contest链接:https://codeforces.com/contest/1288 A. Deadline 题意:略 思路:根据题意 x + [d/(x+1)] 需要找到一个x使得上式小于等于 ...
- 剑指offer 面试题. 剪绳子
题目描述 给你一根长度为n的绳子,请把绳子剪成整数长的m段(m.n都是整数,n>1并且m>1),每段绳子的长度记为k[0],k[1],...,k[m].请问k[0]xk[1]x...xk[ ...
- mysql 原有的主键情况下设置自增字段
mysql 的自增字段只能是主键,如果原表已经有主键,需要设置自增字段应该怎么做呢? 1.alter table bu_staff drop primary key; 先删除表的主键 id为原表 ...
- 关于memset....我太难了
众所周知memset是个清空数组的好东西 然而...它慢的要死 直接让我从30ms炸到1045ms 于是快乐tle .... 是我的错 所以以后还是手动清空 (我真快乐)
- pip知识点
pip第三方模块保存在\Lib\site-packages目录 安装第三方模块:\Script目录下->shift+鼠标右点打开powershift窗口 ->pip install 模块名 ...
- 题解【洛谷P1407】 [国家集训队]稳定婚姻
题面 题解 很好的\(Tarjan\)练习题. 主要讲一下如何建图. 先用\(STL \ map\)把每个人的名字映射成数字. 输入第\(i\)对夫妻时把女性映射成\(i\),把男性映射成\(i+n\ ...
- 总结下抽象类Abstract和虚方法Virtual(易混点)
1.普通类中可以有普通方法和虚方法,在被继承时,虚方法可以选择重写(override)或者不重写 2.抽象类中可以有普通方法和虚方法和抽象方法,当被继承时 如下 1.普通方法不能被子类重写 2.虚方法 ...
- springboot+jwt
大概了解下SpringMVC和jwt,百度 代码: 1.整体框架 2.controller package com.yiyezhiqiu.jwt.jwt.controller; import com. ...
- ThinkPhp5 中Volist标签的用法
Volist标签一般是和内置方法assign()搭配使用,将值从后台传到前台,是当下比较流行的一种传值方法 本文实例讲述了ThinkPHP模板循环输出Volist标签用法.分享给大家供大家参考,具体如 ...
- 联想ideapad关闭Fn
1.打开bios 开启/重启电脑的时候长按Fn+F2,就可以打开bios面板 2.切换到configuration菜单 使用键盘的右箭头将切换到configuration 3.关闭Fn 使用键盘下箭头 ...