1、腾讯云搭建Hadoop3集群
1主机名和IP配置
1.1主机名
1.首先使用root用户名和root密码分别登录三台服务器
2.分别在三台虚拟机上执行命令:
hostnamectl set-hostname node1
hostnamectl set-hostname node2
hostnamectl set-hostname node3
3.分别在三台服务器上执行logout
1.2 IP设置
systemctl restart network
2配置免密登录
2.1 生成公钥和私钥
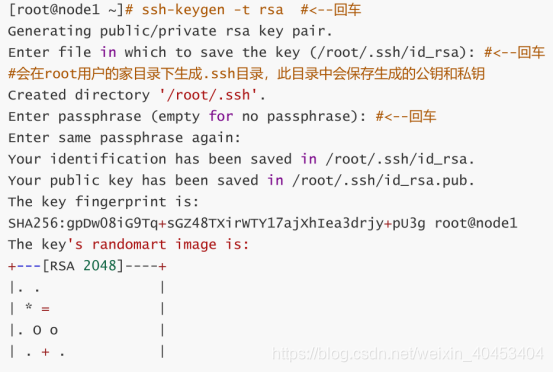
使用此命令:ssh-keygen -t rsa 分别在三台机器中都执行一遍,这里只在node1上做演示,其他两台机器也需要执行此命令。
2.2 配置hosts文件
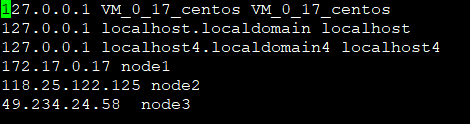
hosts文件中配置三台机器ip和主机名的映射关系,其他两台机器按照相同的方式操作:vi /etc/hosts
特别注意的是如果在云服务器中配置,本节点的IP地址一定要配置内网地址
127.17.0.17是服务器node1的内网地址
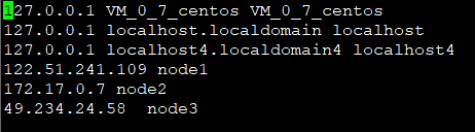
127.17.0.7是服务器node2的内网地址
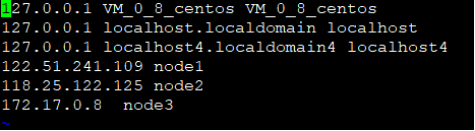
127.17.0.8是服务器node3的内网地址
2.3 拷贝公钥文件
(1)将node1的公钥拷贝到node2,node3上
(2)将node2的公钥拷贝到node1,node3上
(3)将node3的公钥拷贝到node1,node2上
以下以node1为例执行秘钥复制命令:ssh-copy-id -i 主机名

2.4验证免密登录配置
确保每一个服务器到其他服务器都可以免密登录
ssh node#
2.5添加本地认证公钥到认证文件中
cd ~
cd .ssh/
cat id_rsa.pub >> authorized_keys

3安装Hadoop
3.1创建hadoop用户组和hadoop用户
groupadd hadoop
useradd -g hadoop hadoop
id hadoop
设置密码:passwd hadoop
chown -R hadoop:hadoop /home/hadoop/
chmod -R 755 /home/hadoop/
#把root用户的环境变量文件复制并覆盖hadoop用户下的.bash_profile
cp .bash_profile /home/hadoop/


3.2Hadoop用户进行免密登录
su - hadoop
source.bash_profile
ssh-keygen -t rsa
cd ~
chmod -R 755 .ssh/
chmod 644 *
chmod 600 id_rsa
chmod 600 id_rsa.pub
将node1的hadoop用户公钥拷贝到node2,node3上
将node2的hadoop用户公钥拷贝到node1,node3上
将node3的hadoop用户公钥拷贝到node1,node2上
ssh-copy-id -i 主机名
验证免密登录配置:ssh 主机名,确保每台每台服务器的hadoop用户都可以免密登录其他的服务器。
添加本地认证公钥到认证文件中,对每台服务器进行如下操作:
cat id_rsa.pub >> authorized_keys
3.3配置Hadoop
(1)创建hadoop安装目录: mkdir -p /opt/bigdata
(2)解压hadoop-3.1.2.tar.gz
tar -xzvf hadoop-3.1.2.tar.gz -C /opt/bigdata/
(3)配置Hadoop环境变量
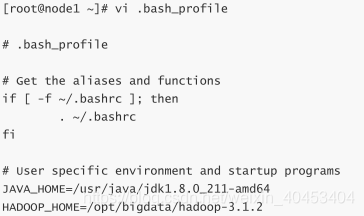
vi .bash_profile
配置详细信息:
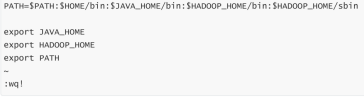
JAVA_HOME=/usr/java/jdk1.8.0_211-amd64
HADOOP_HOME=/opt/bigdata/hadoop-3.1.2
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME
export HADOOP_HOME
export PATH
(4)验证Hadoop环境变量
source .bash_profile
hadoop version
显示出hadoop版本信息表示安装和环境变量成功.

hadoop用户下也需要按照root用户配置环境变量的方式操作一下
(5)配置hadoop-env.sh
这个文件只需要配置JAVA_HOME的值即可,在文件中找到export JAVA_HOME字眼的位置,删除最前面的#
cd /opt/bigdata/hadoop-3.1.2/etc/hadoop/
vi hadoop-env.sh
详细配置:
export JAVA_HOME=/usr/java/jdk1.8.0_211-amd64
(6)配置core-site.xml
cd /opt/bigdata/hadoop-3.1.2/etc/hadoop/
vi core-site.xml
<configuration>
<!-- 指定hdfs的namenode主机的hostname -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<!-- io操作流的配置 -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!--hadoop集群临时数据存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop-3.1.2/tmpdata</value>
</property>
</configuration>
(7)配置hdfs-site.xml
vi hdfs-site.xml
<configuration>
<!--namenode元数据存储目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/bigdata/hadoop-3.1.2/hadoop/hdfs/name/</value>
</property>
<!--指定block块的的大小-->
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<!-- -->
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<!--工作节点的数据块存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/bigdata/hadoop-3.1.2/hadoop/hdfs/data/</value>
</property>
<!--block的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
(8)配置mapred-site.xml
配置/opt/bigdata/hadoop-3.1.2/etc/hadoop/目录下的mapred-site.xml
vi mapred-site.xml
<!--指定运行mapreduce的环境是yarn -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
(9)配置yarn-site.xml
配置/opt/bigdata/hadoop-3.1.2/etc/hadoop/目录下的yarn-site.xml
vi yarn-site.xml
<configuration>
<!--指定resourcemanager的位置-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node1:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node1:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>node1:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>node1:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>node1:18088</value>
</property>
</configuration>
(10)编辑works
配置/opt/bigdata/hadoop-3.1.2/etc/hadoop/目录下的works
vi works

(11)远程复制hadoop到集群机器
进入到root用户家目录下:cd ~
使用scp远程拷贝命令将root用户的环境变量配置文件复制到node2
scp .bash_profile root@node2:~
使用scp远程拷贝命令将root用户的环境变量配置文件复制到node3
scp .bash_profile root@node3:~
进入进入到hadoop的share目录下
cd /opt/bigdata/hadoop-3.1.2/share/
删除doc目录,这个目录存放的是用户手册,比较大,等会儿下面进行远程复制的时候时间比较长,删除后节约复制时间
rm -rf doc/
scp -r /opt root@node2:/
scp -r /opt root@node3:/
3.3.1使集群所有机器环境变量生效
在node2,node3的root用户家目录下使环境变量生效
node2节点如下操作:
cd ~
source .bash_profile
hadoop version
node3节点同样操作
3.3.2修改hadoop用户hadoop安装目录的权限
node2,node3也需要进行如下操作
node1登陆root用户
su root
chown -R hadoop:hadoop /opt/
chmod -R 755 /opt/
chmod -R g+w /opt/
chmod -R o+w /opt/

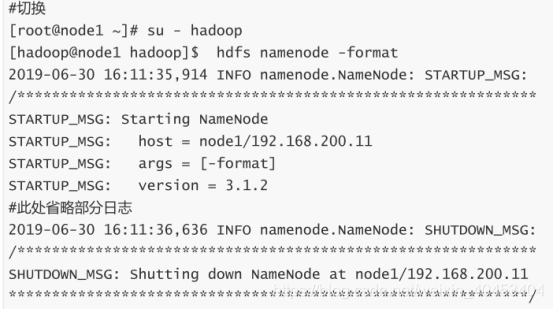
3.4格式化hadoop
su - hadoop
hdfs namenode -format
3.5启动集群
start-all.sh

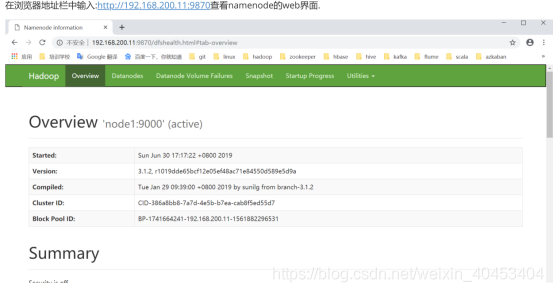
在浏览器地址栏中输入:http://192.168.200.11:9870查看namenode的web界面
3.6运行mapreduce程序
hdfs dfs -ls /
hdfs dfs -mkdir /test
hdfs dfs -ls /
touch words
vi words
hdfs dfs -put words /test
hdfs dfs -ls -r /test

执行:hadoop jar /opt/bigdata/hadoop-3.1.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-
3.1.2.jar wordcount /test/words /test/output
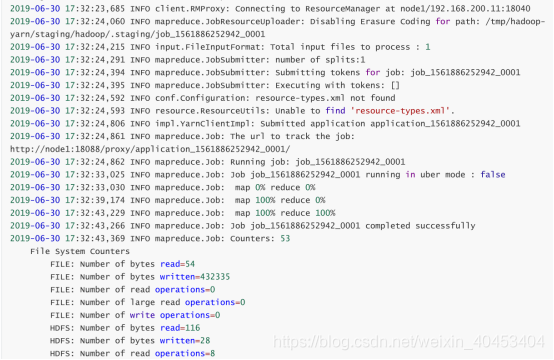
执行:hdfs dfs -text /test/output/part-r-00000

本文使用的是hadoop3.1.3
链接:https://pan.baidu.com/s/1n32rpv-GAjvt7hFZkOnWhw
提取码:2jzu
1、腾讯云搭建Hadoop3集群的更多相关文章
- 阿里云搭建hadoop集群服务器,内网、外网访问问题(详解。。。)
这个问题花费了我将近两天的时间,经过多次试错和尝试,现在想分享给大家来解决此问题避免大家入坑,以前都是在局域网上搭建的hadoop集群,并且是局域网访问的,没遇见此问题. 因为阿里云上搭建的hadoo ...
- 阿里云搭建redis集群
1.安装redis # 下载redis包 wget http://download.redis.io/releases/redis-5.0.5.tar.gz tar -zxvf redis-5.0.5 ...
- Hadoop3集群搭建之——hive添加自定义函数UDF
上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoo ...
- Hadoop3集群搭建之——hbase安装及简单操作
折腾了这么久,hbase终于装好了 ------------------------- 上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hado ...
- Hadoop3集群搭建之——hive添加自定义函数UDTF (一行输入,多行输出)
上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoo ...
- Hadoop3集群搭建之——hive添加自定义函数UDTF
上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoo ...
- Hadoop3集群搭建之——hive安装
Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hbase安装及简单操作 现在到 ...
- Hadoop3集群搭建之——配置ntp服务
上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 下篇: Hadoop3集群搭建之——hive安装 Hadoop3集群搭建之——hbase安装及简 ...
- Hadoop3集群搭建之——安装hadoop,配置环境
接上篇:Hadoop3集群搭建之——虚拟机安装 下篇:Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoop3集群搭建之——hbase安装及简单操作 上篇已 ...
随机推荐
- 自己用C语言写RH850 F1L serial bootloader
了解更多关于bootloader 的C语言实现,请加我QQ: 1273623966 (验证信息请填 bootloader),欢迎咨询或定制bootloader(在线升级程序). 由于有了RH850 F ...
- CentOS6.5安装指定的PHP版本(php5.5)(转)
查询是否安装有php #rpm -qa|grep php 删除之前安装的php版本 (yum install 安装) #rpm -e php-fpm-5.3.3-47.el6.x86_64 --nod ...
- Leetcode:面试题 04.03. 特定深度节点链表
Leetcode:面试题 04.03. 特定深度节点链表 Leetcode:面试题 04.03. 特定深度节点链表 先贴一下自己写过一个模板,按层数遍历: https://www.cnblogs.co ...
- SAP MM 自定义条件类型出现在采购信息记录的'条件'界面里 ?
SAP MM 自定义条件类型出现在采购信息记录的'条件'界面里 ? 我在SAP系统里复制某个标准的采购条件类型,创建了一个新的自定义条件类型ZC05,并将其分配采购定价过程RM0000. 结果却出现一 ...
- linux下(centos7)docker安装
参考链接https://docs.docker.com/install/linux/docker-ce/centos/ 第一步,确定是centos7及以上版本 cat /etc/redhat-rele ...
- B样条曲线方程和C++实现
功能:根据参数u值和k(大小为阶数值)与节点矢量,计算第i个k次B样条基数 输入参数: u—参数值:k—大小值为阶数:i—第i个k次B样条的支撑区间左端节点的下标:aNode为节点向量. 输出参数:返 ...
- 【python人脸识别】使用opencv识别图片中的人脸
概述: OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉库 为什么有OpenCV? 计算机视觉市场巨大而且持续增长,且这方面没有标准API,如今的计算机视觉软件大概有以下三种: 1.研究 ...
- Java对象拷贝备忘
列举 //cglib net.sf.cglib.beans.BeanCopier.create net.sf.cglib.beans.BeanCopier.copy //spring-beans or ...
- 【python基础语法】函数的作用域和内置函数和关键字(第7天课堂笔记)
一.函数的作用域: 1.全局变量 2.局部变量 3.global 二.内置函数 1.常见的内置函数 print : 输出 input : 输入 type : 查看数据类型 id : 获取数据的内存地址 ...
- 除了降低成本和加速数字化转型,低代码还能给企业带来什么价值 ZT
翻译自:https://dzone.com/articles/measuring-the-roi-of-low-code-1,有删改 低代码 是一种近些年兴起的企业软件快速开发技术和工具.借助低代码使 ...