吴裕雄 python 机器学习——模型选择参数优化随机搜索寻优RandomizedSearchCV模型
import scipy from sklearn.datasets import load_digits
from sklearn.metrics import classification_report
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV,RandomizedSearchCV #模型选择参数优化随机搜索寻优RandomizedSearchCV模型
def test_RandomizedSearchCV():
'''
测试 RandomizedSearchCV 的用法。使用 LogisticRegression 作为分类器,主要优化 C、multi_class 等参数。其中 C 的分布函数为指数分布
'''
### 加载数据
digits = load_digits()
X_train,X_test,y_train,y_test=train_test_split(digits.data, digits.target,test_size=0.25,random_state=0,stratify=digits.target)
#### 参数优化 ######
tuned_parameters ={ 'C': scipy.stats.expon(scale=100), # 指数分布
'multi_class': ['ovr','multinomial']}
clf=RandomizedSearchCV(LogisticRegression(penalty='l2',solver='lbfgs',tol=1e-6),tuned_parameters,cv=10,scoring="accuracy",n_iter=100)
clf.fit(X_train,y_train)
print("Best parameters set found:",clf.best_params_)
print("Randomized Grid scores:")
# for params, mean_score, scores in clf.fit_params,clf.mean_score,clf.score:
# print("\t%0.3f (+/-%0.03f) for %s" % (mean_score, scores() * 2, params))
# print("\t%0.3f (+/-%0.03f) for %s" % (clf.mean_score,clf.score * 2, clf.fit_params))
print(clf) print("Optimized Score:",clf.score(X_test,y_test))
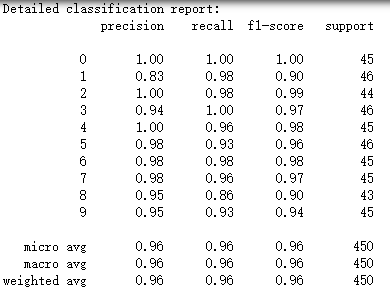
print("Detailed classification report:")
y_true, y_pred = y_test, clf.predict(X_test)
print(classification_report(y_true, y_pred)) #调用RandomizedSearchCV()
test_RandomizedSearchCV()

吴裕雄 python 机器学习——模型选择参数优化随机搜索寻优RandomizedSearchCV模型的更多相关文章
- 吴裕雄 python 机器学习——模型选择参数优化暴力搜索寻优GridSearchCV模型
import scipy from sklearn.datasets import load_digits from sklearn.metrics import classification_rep ...
- 吴裕雄 python 机器学习——模型选择验证曲线validation_curve模型
import numpy as np import matplotlib.pyplot as plt from sklearn.svm import LinearSVC from sklearn.da ...
- 吴裕雄 python 机器学习——模型选择学习曲线learning_curve模型
import numpy as np import matplotlib.pyplot as plt from sklearn.svm import LinearSVC from sklearn.da ...
- 吴裕雄 python 机器学习——模型选择回归问题性能度量
from sklearn.metrics import mean_absolute_error,mean_squared_error #模型选择回归问题性能度量mean_absolute_error模 ...
- 吴裕雄 python 机器学习——模型选择分类问题性能度量
import numpy as np import matplotlib.pyplot as plt from sklearn.svm import SVC from sklearn.datasets ...
- 吴裕雄 python 机器学习——模型选择数据集切分
import numpy as np from sklearn.model_selection import train_test_split,KFold,StratifiedKFold,LeaveO ...
- 吴裕雄 python 机器学习——模型选择损失函数模型
from sklearn.metrics import zero_one_loss,log_loss def test_zero_one_loss(): y_true=[1,1,1,1,1,0,0,0 ...
- 吴裕雄 python 机器学习——分类决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
随机推荐
- 【Python】简单计算器
#python 3.7.1 print("operation codes are:") print("1 for multiply") print(" ...
- stopPropagation() 方法
定义和用法 不再派发事件. 终止事件在传播过程的捕获.目标处理或起泡阶段进一步传播.调用该方法后,该节点上处理该事件的处理程序将被调用,事件不再被分派到其他节点. 语法 event.stopPropa ...
- 【AHOI2005】约数研究
发现luogu的UI改版后AC以后不能给题目评定难度了…… P1403 [AHOI2005]约数研究 类似素数筛的一道题,不过是约数. 先顺手写了个暴力做法,TLE定了~ #include<bi ...
- Json.Net的介绍与简单实用(兼容2.0/3.0/3.5/4.5/RT)
本文的前提是你已经熟悉Json,如果您还不知道什么是Json是什么,请自行查看维基百科. 一.Json.Net是什么? Json.Net是一个读写Json效率比较高的.Net框架.Json.Net 使 ...
- anniversary party_hdu1520
本来以为是一道很简单的提,可以分分钟解决(实际上就是很简单) 然而一直报错,找半天,竟然要多组输入(还是太菜了) 所以每组需要先初始化, 这是一道树形DP的简单题,具体思路就是我选这个上司就不能选他的 ...
- jvm(3):JVM调优
typora-root-url: ./ JVM调优思路 目的:减少full GC次数.减少STW时间(一次GC的时间) 手段: 打印GC日志-XX:+PrintGCDetails -XX:+Print ...
- maskrcnn实现.md
mask rcnn学习 Mask R-CNN实现(https://engineering.matterport.com/splash-of-color-instance-segmentation-wi ...
- django 400报错
最近做一个django项目,在设置了 DEBUG=False之后,访问接口,报错400. 何解??? 查资料,得知: ...
- NOIP做题练习(day2)
A - Reign 题面 题解 最大子段和+\(DP\). 预处理两个数组: \(p[i]\)表示 \(i\) 之前的最大子段和. \(l[i]\)表示 \(i\) 之后的最大子段和. 最后直接输出即 ...
- 每天进步一点点------ISE 12.4的FPGA设计基本流程
基于ISE 12.4的FPGA设计基本流程 ISE是使用XILINX的FPGA的必备的设计工具,它可以完成FPGA开发的全部流程,包括设计输入.仿真.综合.布局布线.生成BIT文件.配置以及在线调试等 ...