拒绝低效!Python教你爬虫公众号文章和链接
本文首发于公众号「Python知识圈」,如需转载,请在公众号联系作者授权。
前言
上一篇文章整理了的公众号所有文章的导航链接,其实如果手动整理起来的话,是一件很费力的事情,因为公众号里添加文章的时候只能一篇篇的选择,是个单选框。
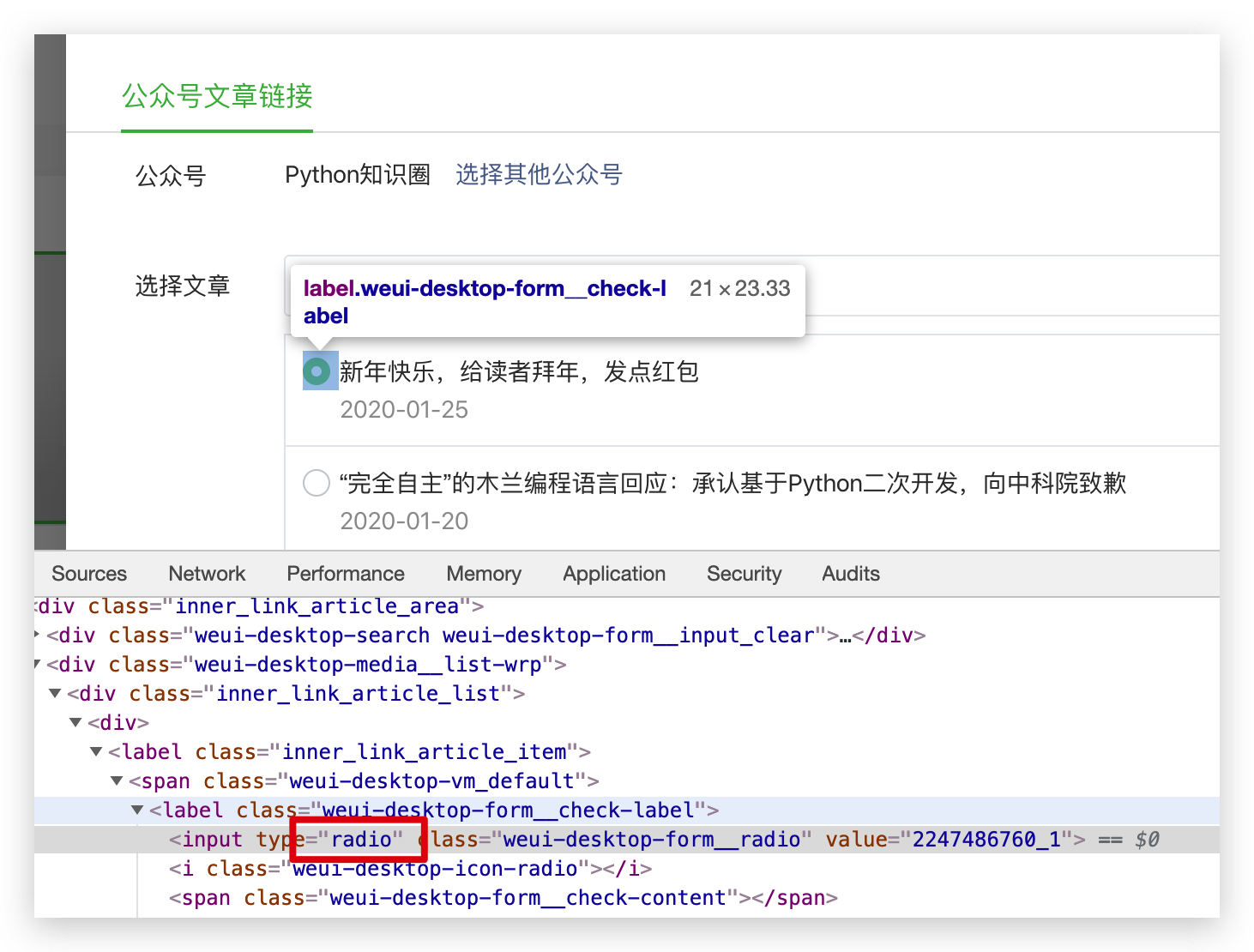
面对几百篇的文章,这样一个个选择的话,是一件苦差事。
pk哥作为一个 Pythoner,当然不能这么低效,我们用爬虫把文章的标题和链接等信息提取出来。
抓包
我们需要通过抓包提取公众号文章的请求的 URL,参考之前写过的一篇抓包的文章 Python爬虫APP前的准备,pk哥这次直接抓取 PC 端微信的公众号文章列表信息,更简单。
我以抓包工具 Charles 为例,勾选容许抓取电脑的请求,一般是默认就勾选的。
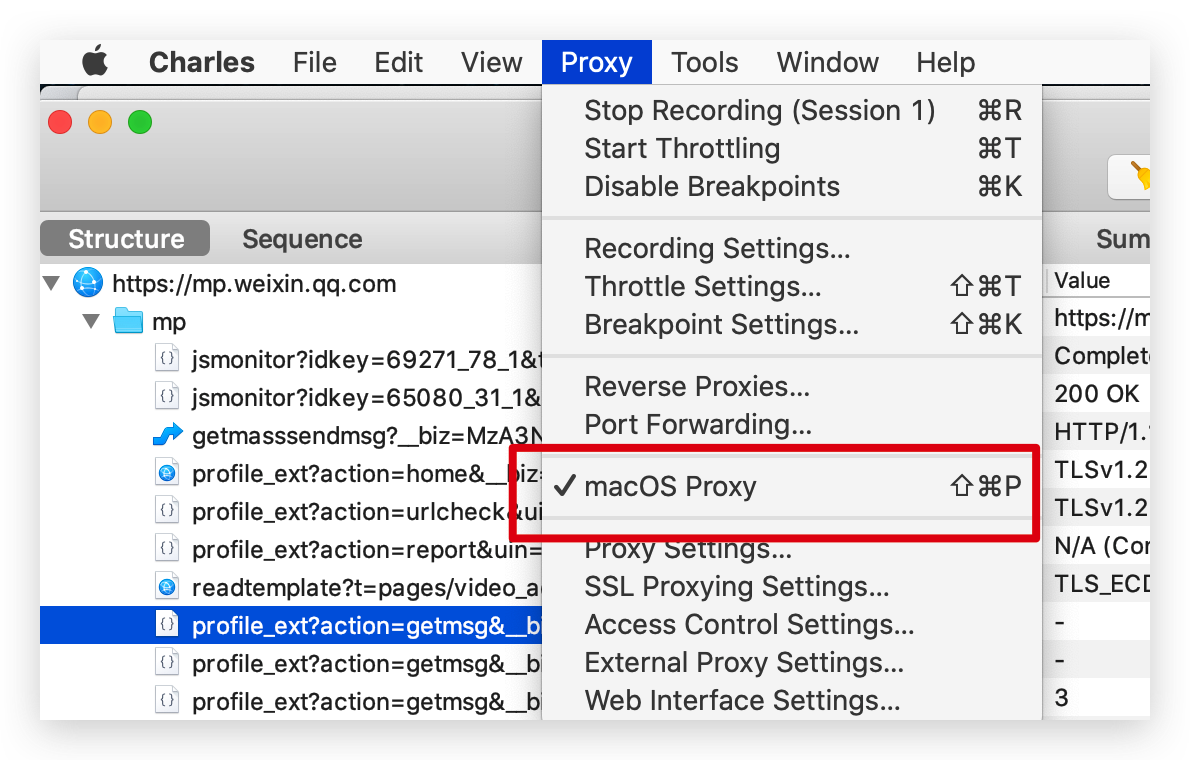
为了过滤掉其他无关请求,我们在左下方设置下我们要抓取的域名。
打开 PC 端微信,打开 「Python知识圈」公众号文章列表后,Charles 就会抓取到大量的请求,找到我们需要的请求,返回的 JSON 信息里包含了文章的标题、摘要、链接等信息,都在 comm_msg_info 下面。
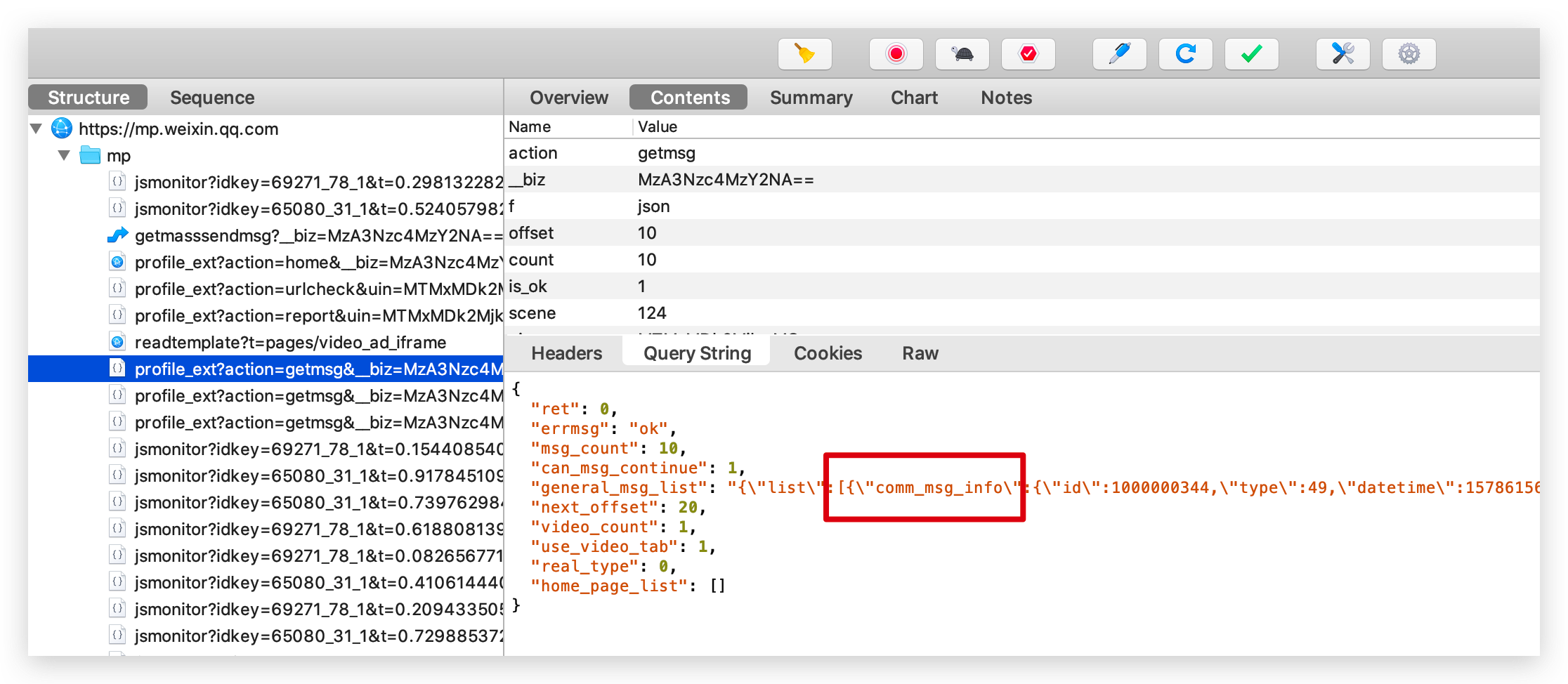

这些都是请求链接后的返回,请求链接 url 我们可以在 Overview 中查看。
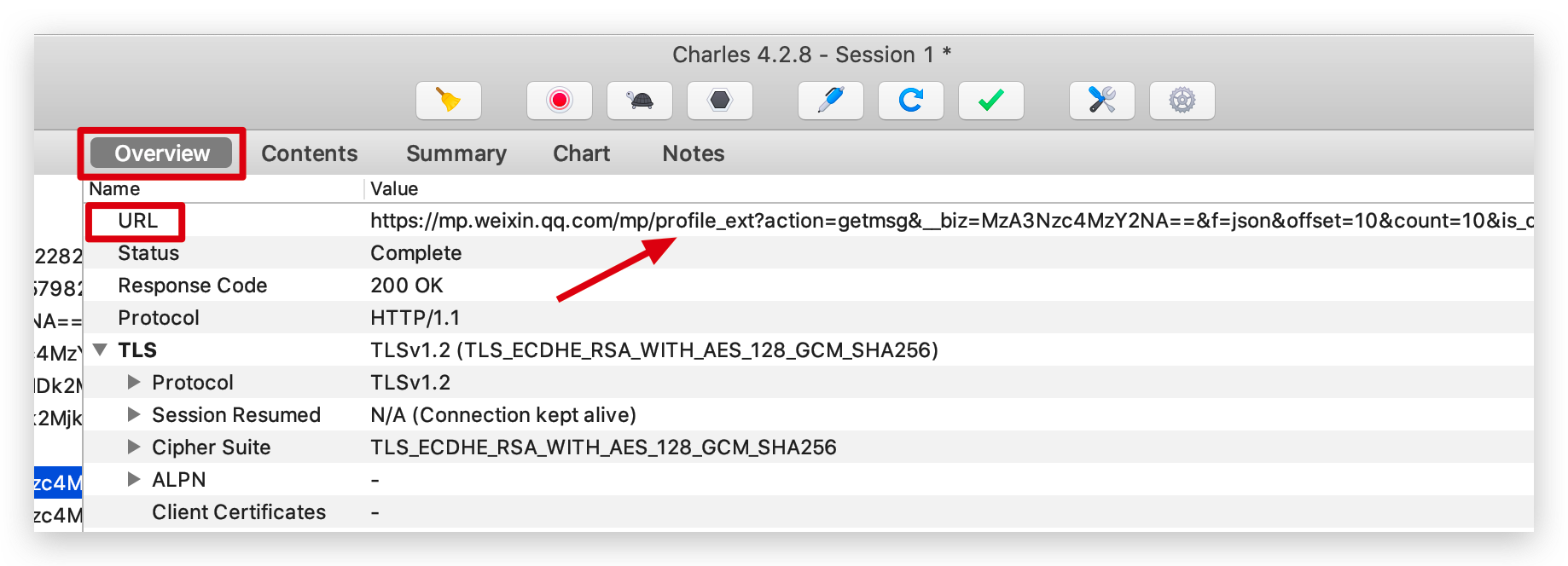
通过抓包获取了这么多信息后,我们可以写爬虫爬取所有文章的信息并保存了。
初始化函数
公众号历史文章列表向上滑动,加载更多文章后发现链接中变化的只有 offset 这个参数,我们创建一个初始化函数,加入代理 IP,请求头和信息,请求头包含了 User-Agent、Cookie、Referer。
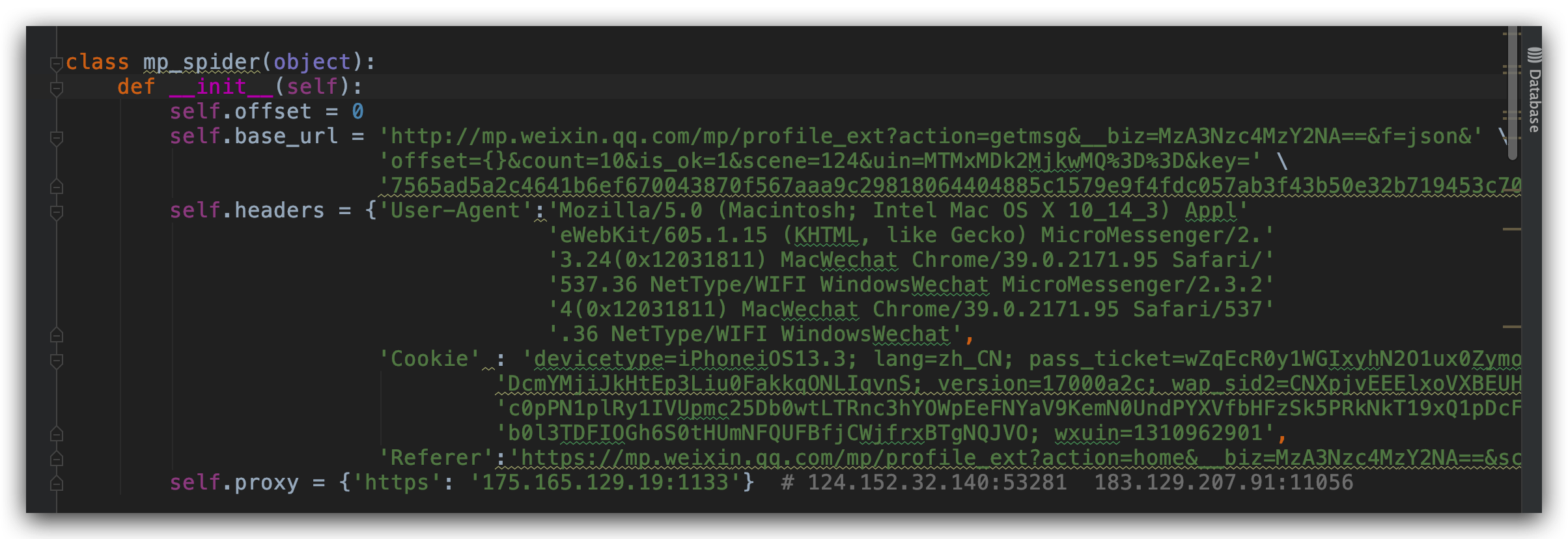
这些信息都在抓包工具可以看到。
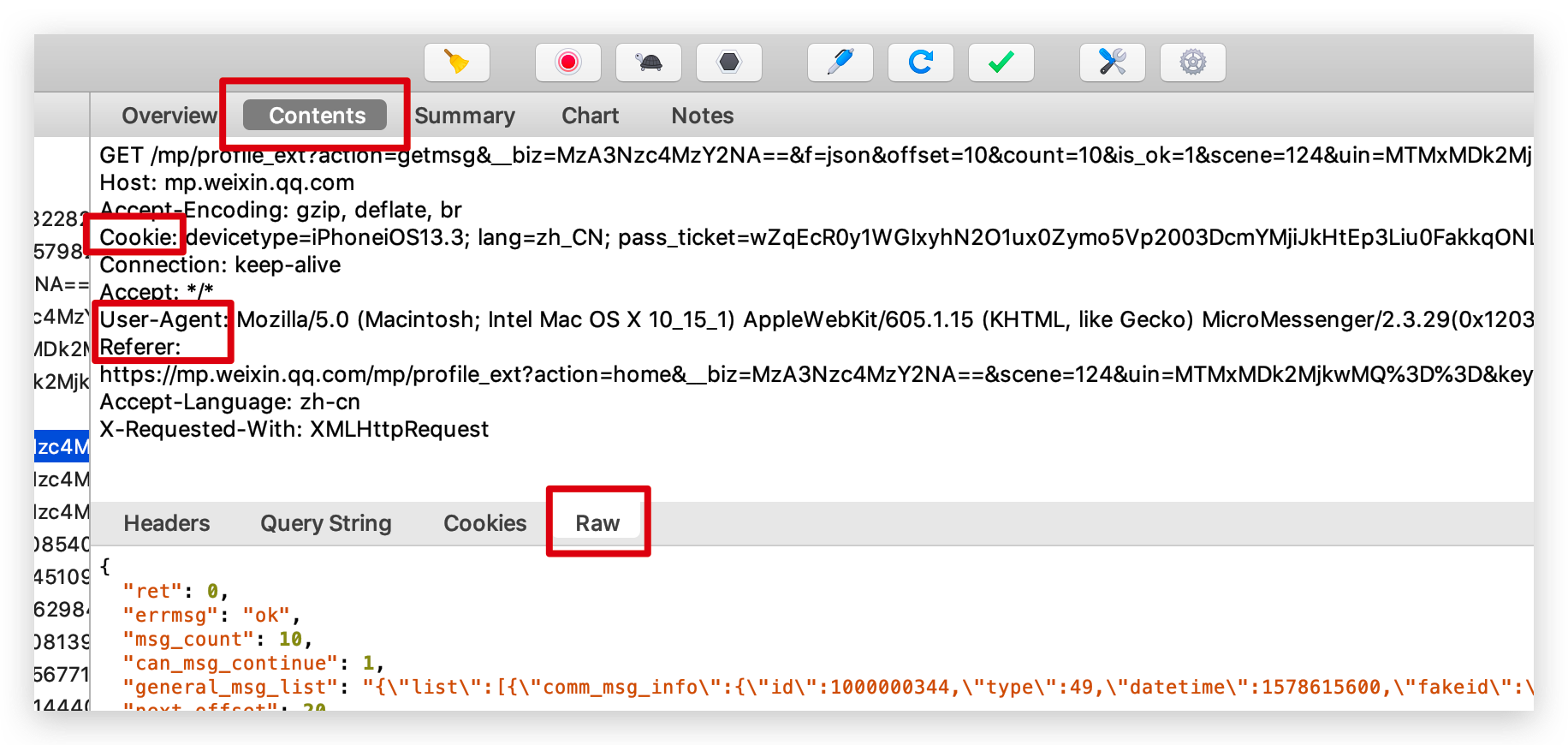
请求数据
通过抓包分析出来了请求链接,我们就可以用 requests 库来请求了,用返回码是否为 200 做一个判断,200 的话说明返回信息正常,我们再构建一个函数 parse_data() 来解析提取我们需要的返回信息。
def request_data(self):
try:
response = requests.get(self.base_url.format(self.offset), headers=self.headers, proxies=self.proxy)
print(self.base_url.format(self.offset))
if 200 == response.status_code:
self.parse_data(response.text)
except Exception as e:
print(e)
time.sleep(2)
pass
提取数据
通过分析返回的 Json 数据,我们可以看到,我们需要的数据都在 app_msg_ext_info 下面。
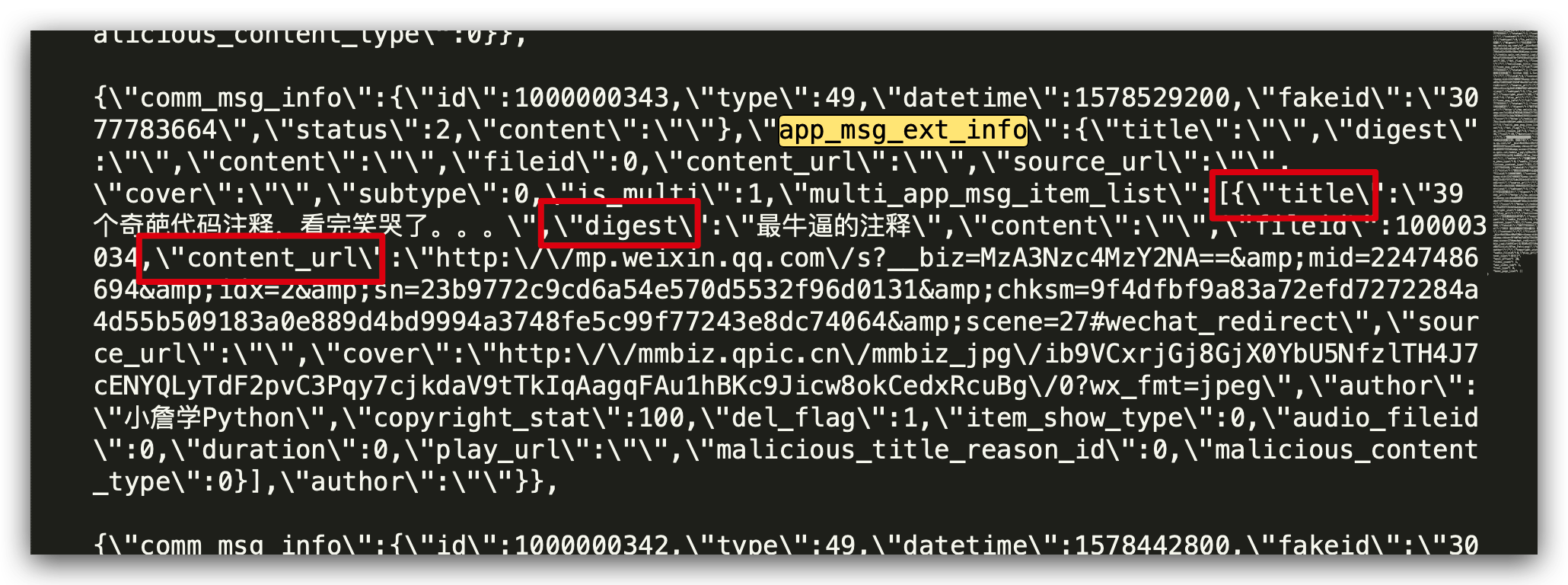
我们用 json.loads 解析返回的 Json 信息,把我们需要的列保存在 csv 文件中,有标题、摘要、文章链接三列信息,其他信息也可以自己加。
def parse_data(self, responseData):
all_datas = json.loads(responseData)
if 0 == all_datas['ret'] and all_datas['msg_count']>0:
summy_datas = all_datas['general_msg_list']
datas = json.loads(summy_datas)['list']
a = []
for data in datas:
try:
title = data['app_msg_ext_info']['title']
title_child = data['app_msg_ext_info']['digest']
article_url = data['app_msg_ext_info']['content_url']
info = {}
info['标题'] = title
info['小标题'] = title_child
info['文章链接'] = article_url
a.append(info)
except Exception as e:
print(e)
continue
print('正在写入文件')
with open('Python公众号文章合集1.csv', 'a', newline='', encoding='utf-8') as f:
fieldnames = ['标题', '小标题', '文章链接'] # 控制列的顺序
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(a)
print("写入成功")
print('----------------------------------------')
time.sleep(int(format(random.randint(2, 5))))
self.offset = self.offset+10
self.request_data()
else:
print('抓取数据完毕!')
这样,爬取的结果就会以 csv 格式保存起来。
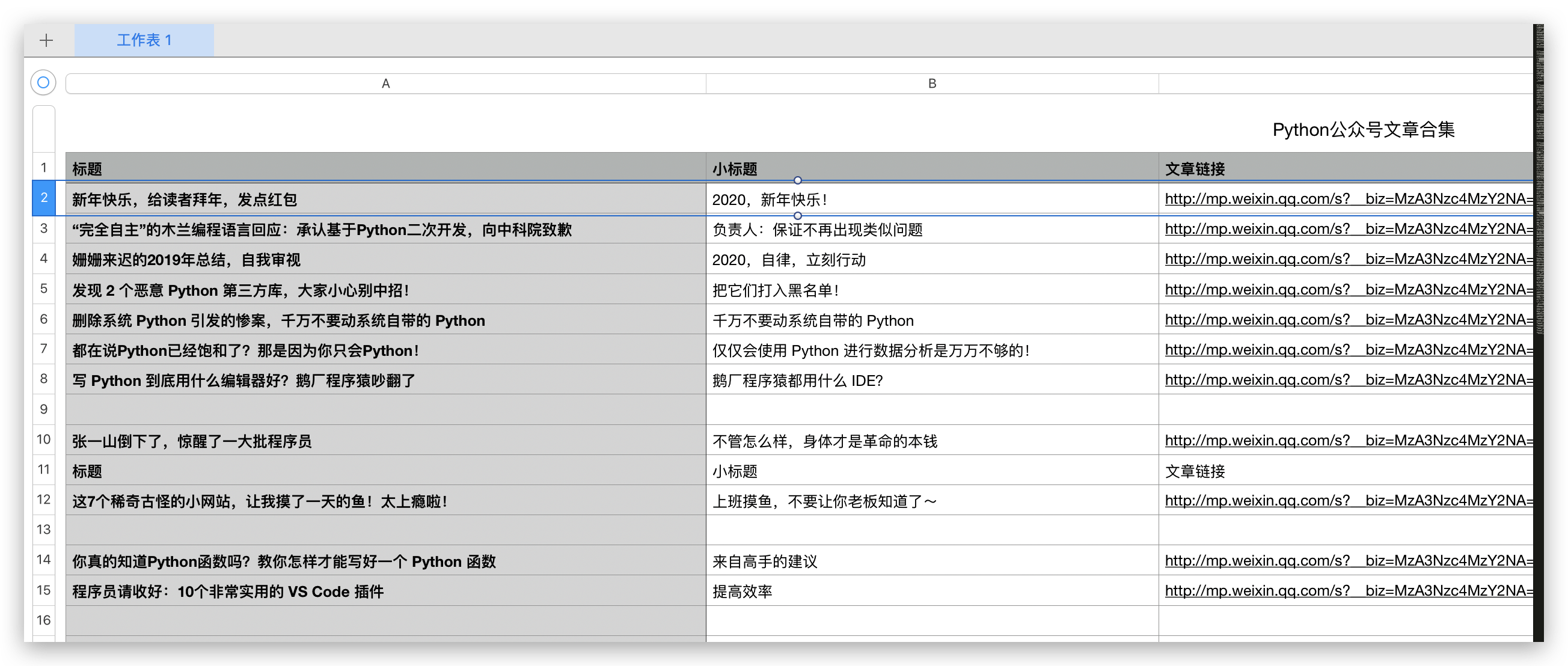
运行代码时,可能会遇到 SSLError 的报错,最快的解决办法就是 base_url 前面的 https 去掉 s 再运行。
保存markdown格式的链接
经常写文章的人应该都知道,一般写文字都会用 Markdown 的格式来写文章,这样的话,不管放在哪个平台,文章的格式都不会变化。
在 Markdown 格式里,用 [文章标题](文章url链接) 表示,所以我们保存信息时再加一列信息就行,标题和文章链接都获取了,Markdown 格式的 url 也就简单了。
md_url = '[{}]'.format(title) + '({})'.format(article_url)
爬取完成后,效果如下。
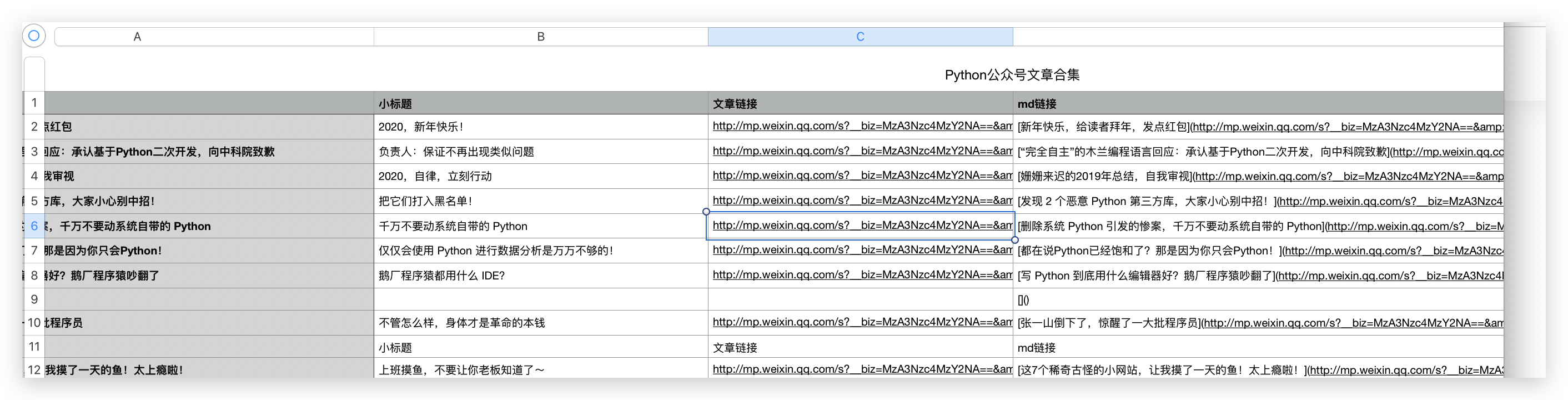
我们把 md链接这一列全部粘贴到 Markdown 格式的笔记里就行了,大部分的笔记软件都知道新建 Markdown 格式的文件的。
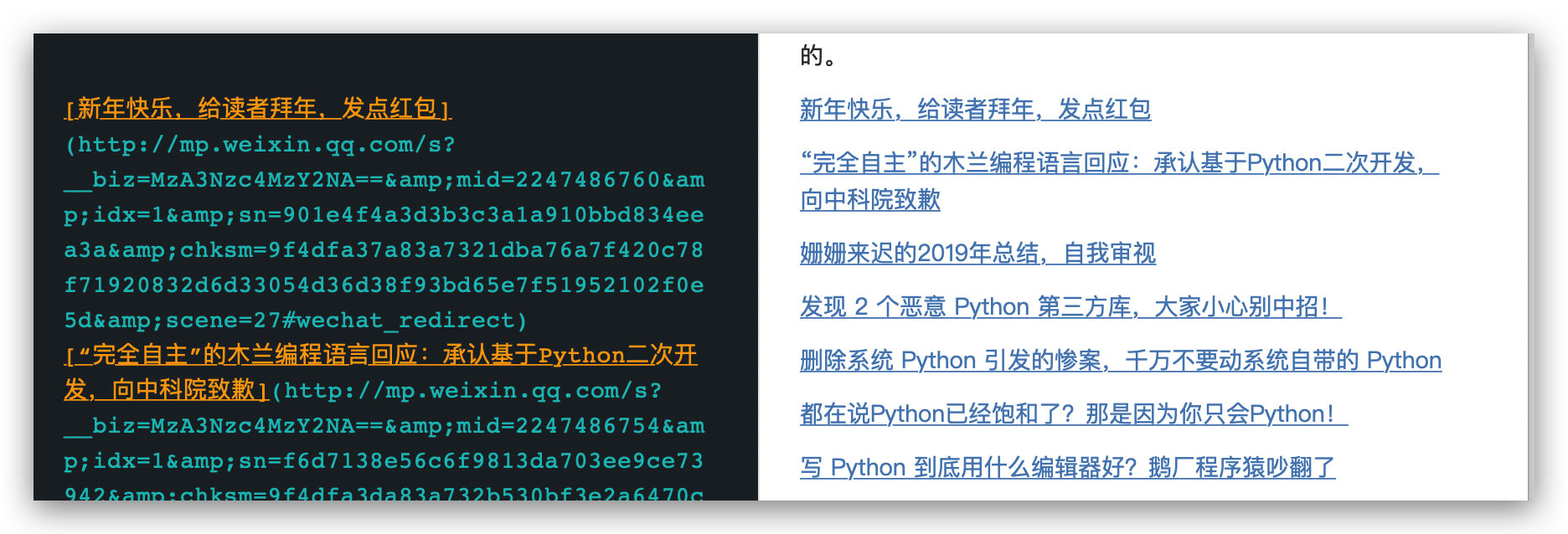
这样,这些导航文章链接整理起来就是分类的事情了。
你用 Python 解决过生活中的小问题吗?欢迎留言讨论。
拒绝低效!Python教你爬虫公众号文章和链接的更多相关文章
- 使用Python爬取微信公众号文章并保存为PDF文件(解决图片不显示的问题)
前言 第一次写博客,主要内容是爬取微信公众号的文章,将文章以PDF格式保存在本地. 爬取微信公众号文章(使用wechatsogou) 1.安装 pip install wechatsogou --up ...
- 50行Python代码,教你获取公众号全部文章
> 本文首发自公众号:python3xxx 爬取公众号的方式常见的有两种 - 通过搜狗搜索去获取,缺点是只能获取最新的十条推送文章 - 通过微信公众号的素材管理,获取公众号文章.缺点是需要申请自 ...
- python爬取微信公众号
爬取策略 1.需要安装python selenium模块包,通过selenium中的webdriver驱动浏览器获取Cookie的方法.来达到登录的效果 pip3 install selenium c ...
- Python 微信公众号文章爬取
一.思路 我们通过网页版的微信公众平台的图文消息中的超链接获取到我们需要的接口 从接口中我们可以得到对应的微信公众号和对应的所有微信公众号文章. 二.接口分析 获取微信公众号的接口: https:// ...
- Markdown 直接转换公众号文章,不再为排版花时间
上一篇「又一家数据公司被查,爬虫到底做错了什么?」反响强烈,虽然我这是新号,但还是获得了不少公众号的转发,借机也结识了很多业内大佬,在此感谢大家的抬爱! 同时也有不少号主问我的文章排版是用的哪个网站, ...
- 破解微信防盗链&微信公众号文章爬取方案
破解微信图文防盗链:https://www.cnblogs.com/xsxshmily/p/8000043.html 图片解除防盗链:https://blog.csdn.net/show_ljw/ar ...
- Chrome浏览器保存微信公众号文章中的图片
用chrome浏览器打开微信公众号文章中时,另存为图片时保存的是640.webp,不是图片本身,用IE则没有此问题.大部分chrome插件也无法保存图片. 经过多番尝试,找到一款插件可以批量保存微信公 ...
- pc端引入微信公众号文章
最近做了一个小需求,结果坑特别多..... 需求是这样的,要给公司内部做一个微信公众号广告投票系统,整个项目就不多赘述了,有个小功能,要求是这样的: 点击某条记录后的“投票”按钮,在当前页面弹出弹窗显 ...
- 你所不知道的 Kindle - 阅读微信公众号文章
Kindle 是一款非常优秀的阅读设备,它为我们提供了非常舒服的阅读体验,并且配合强大的亚马逊图书资源,应该是目前最好的阅读设备之一.Kindle 在已有的成就下还一直在努力提升用户体验.为中国用户开 ...
随机推荐
- Java:Excel文件上传至后台
之前的项目中有遇到上传Excel文件的需求,简单说就是解析一个固定格式的Excel表格,然后存到数据库对应的表中,表格如下: 项目采用SSM架构,mvc模式,显而易见,这个Excel表需要拆成两个表, ...
- 浅谈Linux下/etc/passwd文件
浅谈Linux 下/etc/passwd文件 看过了很多渗透测试的文章,发现在很多文章中都会有/etc/passwd这个文件,那么,这个文件中到底有些什么内容呢?下面我们来详细的介绍一下. 在Linu ...
- 负载均衡基本原理与lvs
前言: 之前在山西的项目上使用的是lvs下的NAT模式,但另外两个模式并没有涉及,今天系统的整理下关于负载均衡的相关理论与lvs各模式的相关优点与不足,知其然与所以然,而后能针对性的应用: 基本介绍 ...
- linux条件变量使用和与信号量的区别
近来在项目中用到条件变量和信号量做同步时,这一块一直都有了解,但也一直没有总结,这次总结一下,给大家提供点参考,也给自己留点纪念. 首先,关于信号量和条件变量的概念可以自行查看APUE,我这直接把AP ...
- mysql索引最佳实践
索引最佳实践使用的表CREATE TABLE `employees` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(24) NOT ...
- list绑定
/** * 首页信息查询的回调函数 * @param 返回值 */ M_Main.ajaxCallBack = function (data){ var dataSource = data.resiC ...
- Python学到什么程度可以面试工作(解答一)
本文整理了 26 个 Python 有用的技巧,将按照首字母从 A~Z 的顺序分享其中一些内容. all 或 any 人们经常开玩笑说 Python 是“可执行的伪代码”,但是当你可以这样编写代码时, ...
- UGUI ScrollView中显示模型和特效
游戏开发中有时候会遇到在UI上显示模型和特效的需求,这次需要在ScrollView上显示.我们使用UGUI的Screen Space - Camera模式,修改模型和特效的layer使之显示在UI上面 ...
- Java 利用Map集合计算一个字符串中每个字符出现的次数
步骤分析 1.给出一串字符串,字符串中可以包含字母.数字.符号等等. 2.创建一个Map集合,key是字符串中的字符,value是字符的个数. 3.遍历字符串,获取每一个字符. 5.使用获取到的字符, ...
- H5录音音频可视化-实时波形频谱绘制、频率直方图
这段时间给GitHub Recorder开源库添加了两个新的音频可视化功能,比以前单一的动态波形显示丰富了好多(下图后两行是不是比第一行看起来丰满些):趁热打铁写了一个音频可视化相关扩展测试代码,下面 ...