第七篇 css选择器实现字段解析
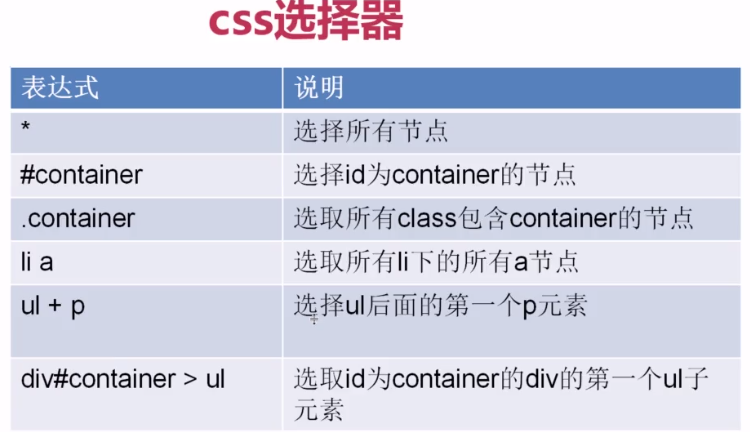
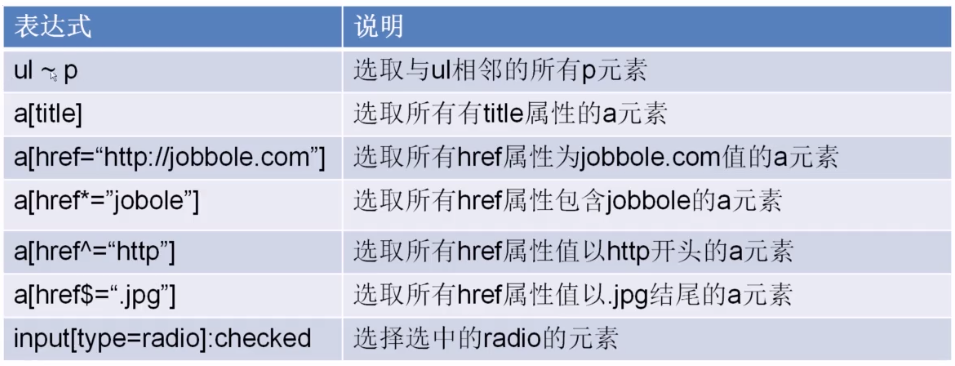
CSS选择器的作用实际和xpath的一样,都是为了定位具体的元素

举例我要爬取下面这个页面的标题
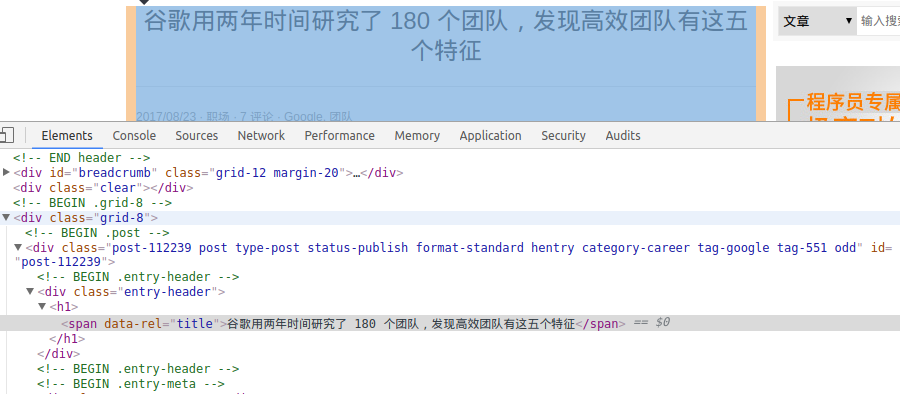
In []: title = response.css(".entry-header h1")
In []: title
Out[]: [<Selector xpath="descendant-or-self::*[@class and contains(concat(' ', normalize-space(@class), ' '), ' entry-header ')]/descendant-or-self::*/h1" data='<h1>谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征</h1>'>]
In []: title = response.css(".entry-header h1").extract()
In []: title
Out[]: ['<h1>谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征</h1>']
In []: ##可以使用css的::text取到内容
In []: title = response.css(".entry-header h1::text").extract()
In []: title
Out[]: ['谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征']
获取文章创建日期:
In []: date_text = response.css(".entry-meta-hide-on-mobile").extract()
In []: date_text
Out[]: ['<p class="entry-meta-hide-on-mobile">\r\n\r\n 2017/08/23 · <a href="http://blog.jobbole.com/category/career/" rel="category tag">职场</a>\r\n \r\n · <a href="#article-comment"> 7 评论 </a>\r\n \r\n\r\n \r\n · <a href="http://blog.jobbole.com/tag/google/">Google</a>, <a href="http://blog.jobbole.com/tag/%e5%9b%a2%e9%98%9f/">团队</a>\r\n \r\n</p>']
In []: date_text = response.css(".entry-meta-hide-on-mobile::text").extract()
In []: date_text
Out[]:
['\r\n\r\n 2017/08/23 · ',
'\r\n \r\n · ',
'\r\n \r\n\r\n \r\n · ',
', ',
'\r\n \r\n']
In []: date_text = response.css(".entry-meta-hide-on-mobile::text").extract()[
...: ]
In []: date_text
Out[]: '\r\n\r\n 2017/08/23 · '
In []: date_text = response.css(".entry-meta-hide-on-mobile::text").extract()[
...: ].strip()
In []: date_text
Out[]: '2017/08/23 ·'
In []: date_text = response.css(".entry-meta-hide-on-mobile::text").extract()[
...: ].strip().replace("·","").strip()
In []: date_text
Out[]: '2017/08/23'
获取评论数
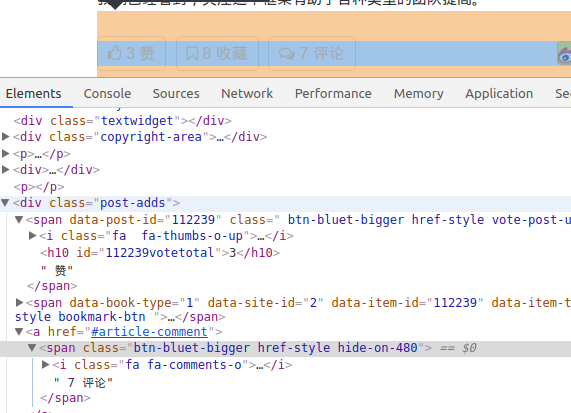
In []: comment_num = response.css("a[href='#article-comment']")
In []: comment_num
Out[]:
[<Selector xpath="descendant-or-self::a[@href = '#article-comment']" data='<a href="#article-comment"> 7 评论 </a>'>,
<Selector xpath="descendant-or-self::a[@href = '#article-comment']" data='<a href="#article-comment"><span class="'>]
In []: comment_num = response.css("a[href='#article-comment'] span::text").ext
...: ract()
In []: comment_num
Out[]: [' 7 评论']
In []: comment_num = response.css("a[href='#article-comment'] span::text").ext
...: ract().strip()
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input--18ae8761867f> in <module>()
----> comment_num = response.css("a[href='#article-comment'] span::text").extract().strip()
AttributeError: 'list' object has no attribute 'strip'
In []: comment_num = response.css("a[href='#article-comment'] span::text").ext
...: ract()[]
In []: comment_num
Out[]: ' 7 评论'
In []:
PS:css选择器里,不同标签使用空格隔开
第七篇 css选择器实现字段解析的更多相关文章
- css选择器优先级全解析
这样一个问题: <!doctype html> <htmllang="en"> <head> <metacharset="UTF ...
- 第七篇 CSS盒子
CSS盒子模型 在页面上,我们要控制元素的位置,比如:写作文一样,开头的两个字会空两个格子(这是在学校语文作文一样),其后就不会空出来,还有,一段文字后面跟着一张图,它们距离太近,不好看,我们要移 ...
- 网页抓取解析,使用JQuery选择器进行网页解析
最近开发一个小功能,数据库中一个基础表的数据从另一个网站采集. 因为网站的数据不定时更新,需要更新后自动采集最新的内容. 怎么判断更新数据没有? 好在网站有一个更新日志提示的地方,只需要对比本地保留的 ...
- 为什么排版引擎解析 CSS 选择器时一定要从右往左解析?
首先我们要看一下选择器的「解析」是在何时进行的. 主要参考这篇「 How browsers work」(http://taligarsiel.com/Projects/howbrowserswork1 ...
- 30个最常用css选择器解析(zz)
你也许已经掌握了id.class.后台选择器这些基本的css选择器.但这远远不是css的全部.下面向大家系统的解析css中30个最常用的选择器,包括我们最头痛的浏览器兼容性问题.掌握了它们,才能真正领 ...
- 30个最常用css选择器解析
转自:http://www.cnblogs.com/yiyuanke/archive/2011/10/22/CSS.html 你也许已经掌握了id.class.后台选择器这些基本的css选择器.但这远 ...
- 看这一篇就够了,css选择器知识汇总
对大多技术人员来说都比较熟悉CSS选择器,举一例子来说,假设给一个p标签增加一个类(class),可是执行后该class中的有些属性并没有起作用.通过Firebug查看,发现没有起作用的属性被覆盖了, ...
- 浏览器如何解析css选择器?
浏览器会『从右往左』解析CSS选择器. 我们知道DOM Tree与Style Rules合成为 Render Tree,实际上是需要将Style Rules附着到DOM Tree上, 因此需要根据选择 ...
- 第四篇、CSS选择器
<html> <head> <meta charset="UTF-8"> <title>CSS选择器</title> & ...
随机推荐
- 点读系列《jmeter官方用户手册》
官网:http://jmeter.apache.org/usermanual/ 说明:十八元件.十九属性.二十函数,涉及清单内容暂未仔细阅读,个人觉得一是仅供使用参考,二是适合单独写文章来解读 一.让 ...
- 转 Jmeter参数化--Post请求的Post body 参数化
2018年01月22日 15:40:58 java2013liu 阅读数:2361收起 个人分类: Jemter 一.使用body data设置参数: 1,首先,使用Fiddler录制post请求 ...
- java爬取猫咪上的图片
首先是对知识点归纳 1.用到获取网页源代码,分析图片地址,发现图片的地址都是按编号排列的,所以想到用循环获取 2.保存图片要用到流操作和文件操作,对两部分知识进行了复习巩固 3.保存后的图片有一部分是 ...
- update 后没有加where条件解决办法
MySQL 误操作后数据恢复(update,delete忘加where条件) 在数据库日常维护中,开发人员是最让人头痛的,很多时候都会由于SQL语句写的有问题导致服务器出问题,导致资源耗尽.最危险的操 ...
- 40th 要掀桌子么 还是尬坐吧
今日学习精华: 面向对象编程里面有一句 非常经典的描述:-----通过类实例化一个对象,通过对象调方法----- 注意:对象调用的 方法 ,即 函数一定要有 参数 def ...
- spring boot 项目的创建
一. 进入https://start.spring.io 快速创建项目 二. 利用eclipse sts插件创建项目 1. 安装sts插件 进入https://spring.io/tools3/sts ...
- synchronized(this) 与 synchronized(class) 理解
1.概念 synchronized 是 Java 中的关键字,是利用锁的机制来实现同步的. 锁机制有如下两种特性: 互斥性:即在同一时间只允许一个线程持有某个对象锁,通过这种特性来实现多线程中的协调机 ...
- 分布式项目spring 配置文件的约束
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.spr ...
- 实战:基于 Spring 的应用配置如何迁移至阿里云应用配置管理 ACM
最近遇到一些开发者朋友,准备将原有的Java Spring的应用配置迁移到 阿里云应用配置管理 ACM 中.迁移过程中,遇到不少有趣的问题.本文将通过一个简单的样例来还原迁移过程中遇到的问题和相关解决 ...
- 最长上升子序列(LIS)问题
最长上升子序列(LIS)问题 此处我们只讨论严格单调递增的子序列求法. 前面O(n2)的算法我们省略掉,直接进入O(nlgn)算法. 方法一:dp + 树状数组 定义dp[i]:末尾数字是i时最长上升 ...