Sql性能优化梳理
前言
先简单梳理下Mysql的基本概念,然后分创建时和查询时这两个阶段的优化展开。
1.0 基本概念简述
1.1 逻辑架构
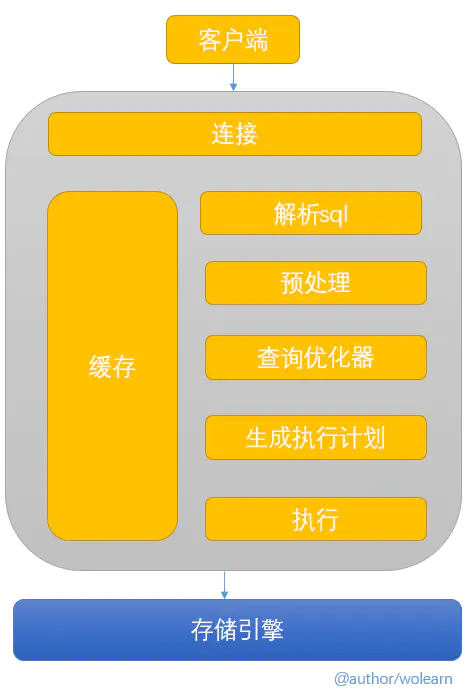
第一层:客户端通过连接服务,将要执行的sql指令传输过来
第二层:服务器解析并优化sql,生成最终的执行计划并执行
第三层:存储引擎,负责数据的储存和提取
1.2 锁
数据库通过锁机制来解决并发场景-共享锁(读锁)和排他锁(写锁)。读锁是不阻塞的,多个客户端可以在同一时刻读取同一个资源。写锁是排他的,并且会阻塞其他的读锁和写锁。简单提下乐观锁和悲观锁。
- 乐观锁,通常用于数据竞争不激烈的场景,多读少写,通过版本号和时间戳实现。
- 悲观锁,通常用于数据竞争激烈的场景,每次操作都会锁定数据。
要锁定数据需要一定的锁策略来配合。
- 表锁,锁定整张表,开销最小,但是会加剧锁竞争。
- 行锁,锁定行级别,开销最大,但是可以最大程度的支持并发。
但是MySql的存储引擎的真实实现不是简单的行级锁,一般都是实现了多版本并发控制(MVCC)。MVCC是行级锁的变种,多数情况下避免了加锁操作,开销更低。MVCC是通过保存数据的某个时间点快照实现的。
1.3 事务
事务保证一组原子性的操作,要么全部成功,要么全部失败。一旦失败,回滚之前的所有操作。MySql采用自动提交,如果不是显式的开启一个事务,则每个查询都作为一个事务。
隔离级别控制了一个事务中的修改,哪些在事务内和事务间是可见的。四种常见的隔离级别:
- 未提交读(Read UnCommitted),事务中的修改,即使没提交对其他事务也是可见的。事务可能读取未提交的数据,造成脏读。
- 提交读(Read Committed),一个事务开始时,只能看见已提交的事务所做的修改。事务未提交之前,所做的修改对其他事务是不可见的。也叫不可重复读,同一个事务多次读取同样记录可能不同。
- 可重复读(RepeatTable Read),同一个事务中多次读取同样的记录结果时结果相同。
- 可串行化(Serializable),最高隔离级别,强制事务串行执行。
1.4 存储引擎
InnoDB引擎,最重要,使用最广泛的存储引擎。被用来设计处理大量短期事务,具有高性能和自动奔溃恢复的特性。
MyISAM引擎,不支持事务和行级锁,奔溃后无法安全恢复。
2.0 创建时优化
2.1 Schema和数据类型优化
整数
TinyInt,SmallInt,MediumInt,Int,BigInt 使用的存储8,16,24,32,64位存储空间。使用Unsigned表示不允许负数,可以使正数的上线提高一倍。
实数
Float,Double , 支持近似的浮点运算。
Decimal,用于存储精确的小数。
字符串
VarChar,存储变长的字符串。需要1或2个额外的字节记录字符串的长度。
Char,定长,适合存储固定长度的字符串,如MD5值。
Blob,Text 为了存储很大的数据而设计的。分别采用二进制和字符的方式。
时间类型
DateTime,保存大范围的值,占8个字节。
TimeStamp,推荐,与UNIX时间戳相同,占4个字节。
优化建议点
- 尽量使用对应的数据类型。比如,不要用字符串类型保存时间,用整型保存IP。
- 选择更小的数据类型。能用TinyInt不用Int。
- 标识列(identifier column),建议使用整型,不推荐字符串类型,占用更多空间,而且计算速度比整型慢。
- 不推荐ORM系统自动生成的Schema,通常具有不注重数据类型,使用很大的VarChar类型,索引利用不合理等问题。
- 真实场景混用范式和反范式。冗余高查询效率高,插入更新效率低;冗余低插入更新效率高,查询效率低。
- 创建完全的独立的汇总表\缓存表,定时生成数据,用于用户耗时时间长的操作。对于精确度要求高的汇总操作,可以采用 历史结果+最新记录的结果 来达到快速查询的目的。
- 数据迁移,表升级的过程中可以使用影子表的方式,通过修改原表的表名,达到保存历史数据,同时不影响新表使用的目的。
2.2 索引
索引包含一个或多个列的值。MySql只能高效的利用索引的最左前缀列。索引的优势:
- 减少查询扫描的数据量
- 避免排序和零时表
- 将随机IO变为顺序IO (顺序IO的效率高于随机IO)
B-Tree
使用最多的索引类型。采用B-Tree数据结构来存储数据(每个叶子节点都包含指向下一个叶子节点的指针,从而方便叶子节点的遍历)。B-Tree索引适用于全键值,键值范围,键前缀查找,支持排序。
B-Tree索引限制:
- 如果不是按照索引的最左列开始查询,则无法使用索引。
- 不能跳过索引中的列。如果使用第一列和第三列索引,则只能使用第一列索引。
- 如果查询中有个范围查询,则其右边的所有列都无法使用索引优化查询。
哈希索引
只有精确匹配索引的所有列,查询才有效。存储引擎会对所有的索引列计算一个哈希码,哈希索引将所有的哈希码存储在索引中,并保存指向每个数据行的指针。
哈希索引限制:
- 无法用于排序
- 不支持部分匹配
- 只支持等值查询如=,IN(),不支持 < >
优化建议点
- 注意每种索引的适用范围和适用限制。
- 索引的列如果是表达式的一部分或者是函数的参数,则失效。
- 针对特别长的字符串,可以使用前缀索引,根据索引的选择性选择合适的前缀长度。
- 使用多列索引的时候,可以通过 AND 和 OR 语法连接。
- 重复索引没必要,如(A,B)和(A)重复。
- 索引在where条件查询和group by语法查询的时候特别有效。
- 将范围查询放在条件查询的最后,防止范围查询导致的右边索引失效的问题。
- 索引最好不要选择过长的字符串,而且索引列也不宜为null。
3.0 查询时优化
3.1 查询质量的三个重要指标
- 响应时间 (服务时间,排队时间)
- 扫描的行
- 返回的行
3.2 查询优化点
1、避免查询无关的列,如使用Select * 返回所有的列。
2、避免查询无关的行
3、切分查询。将一个对服务器压力较大的任务,分解到一个较长的时间中,并分多次执行。如要删除一万条数据,可以分10次执行,每次执行完成后暂停一段时间,再继续执行。过程中可以释放服务器资源给其他任务。
4、分解关联查询。将多表关联查询的一次查询,分解成对单表的多次查询。可以减少锁竞争,查询本身的查询效率也比较高。因为MySql的连接和断开都是轻量级的操作,不会由于查询拆分为多次,造成效率问题。
5、注意count的操作只能统计不为null的列,所以统计总的行数使用count(*)。
6、group by 按照标识列分组效率高,分组结果不宜出行分组列之外的列。
7、关联查询延迟关联,可以根据查询条件先缩小各自要查询的范围,再关联。
8、Limit分页优化。可以根据索引覆盖扫描,再根据索引列关联自身查询其他列。如
SELECT
id,
NAME,
age
WHERE
student s1
INNER JOIN (
SELECT
id
FROM
student
ORDER BY
age
LIMIT 50,5
) AS s2 ON s1.id = s2.id
Union查询默认去重,如果不是业务必须,建议使用效率更高的Union All
9、条件中的字段类型和表结构类型不一致,mysql会自动加转换函数,导致索引作为函数中的参数失效。
10、like查询前面部分未输入,以%开头无法命中索引。
11、补充2个5.7版本的新特性:
(1) generated column,就是数据库中这一列由其他列计算而得
CREATE TABLE triangle (sidea DOUBLE, sideb DOUBLE, area DOUBLE AS (sidea * sideb / 2));
insert into triangle(sidea, sideb) values(3, 4);
select * from triangle;
+-------+-------+------+
| sidea | sideb | area |
+-------+-------+------+
| 3 | 4 | 6 |
+-------+-------+------+
(2) 支持JSON格式数据,并提供相关内置函数
CREATE TABLE json_test (name JSON);
INSERT INTO json_test VALUES('{"name1": "value1", "name2": "value2"}');
SELECT * FROM json_test WHERE JSON_CONTAINS(name, '$.name1');
作者:wolearn
链接:https://juejin.im/post/59b11ba151882538cb1ecbd0
Sql性能优化梳理的更多相关文章
- SQL性能优化常见措施(Lock wait timeout exceeded)
SQL性能优化常见措施 目 录 1.mysql中explain命令使用 2.mysql中mysqldumpslow的使用 3.mysql中修改my.ini配置文件记录日志 4.mysql中如何加索引 ...
- SQL性能优化案例分析
这段时间做一个SQL性能优化的案例分析, 整理了一下过往的案例,发现一个比较有意思的,拿出来给大家分享. 这个项目是我在项目开展2期的时候才加入的, 之前一期是个金融内部信息门户, 里面有个功能是收集 ...
- SQL性能优化
引言: 以前在面试的过程中,总有面试官问道:你做过sql性能优化吗?对此,我的答复是没有.一次没有不是自己的错误,两次也不是,但如果是多次呢?今天痛下决心,把有关sql性能优化的相关知识总结一下,以便 ...
- 如何进行正确的SQL性能优化
在SQL查询中,为了提高查询的效率,我们常常采取一些措施对查询语句进行SQL性能优化.本文我们总结了一些优化措施,接下来我们就一一介绍. 1.查询的模糊匹配 尽量避免在一个复杂查询里面使用 LIKE ...
- SQL Select count(*)和Count(1)的区别和执行方式及SQL性能优化
SQL性能优化:http://www.cnblogs.com/CareySon/category/360333.html Select count(*)和Count(1)的区别和执行方式 在SQL S ...
- 如何进行SQL性能优化
在SQL查询中,为了提高查询的效率,我们常常采取一些措施对查询语句进行SQL性能优化.本文我们总结了一些优化措施,接下来我们就一一介绍. 1.查询的模糊匹配 尽量避免在一个复杂查询里面使用 LIKE ...
- 关于SQL性能优化的十条经验
1.查询的模糊匹配 尽量避免在一个复杂查询里面使用 LIKE '%parm1%'—— 红色标识位置的百分号会导致相关列的索引无法使用,最好不要用. 解决办法: 其实只需要对该脚本略做改进,查询速度便会 ...
- ORACLE数据库学习之SQL性能优化详解
Oracle sql 性能优化调整 ...
- 我对SQL性能优化的看法,对我的文章有提议的欢迎评论!
影响你的查询速度的原因是什么? 网速不给力,不稳定. 服务器内存不够,或者SQL 被分配的内存不够. sql语句设计不合理 没有相应的索引,索引不合理 表数据过大没有有效的分区设计 数据库设计太2,存 ...
随机推荐
- SpringCloud Netflix Zuul
网关的概念 服务A.B都是暴露出来,供外部直接调用的, 有时候需要对请求进行过滤.校验,比如检验用户是否已登陆,可以写在暴露出来的每个服务中,但要在多个服务中写相同的代码,太繁琐,可以提出来,放在网关 ...
- JS高级---案例:验证用户输入的是不是邮箱
案例:验证用户输入的是不是邮箱 <!DOCTYPE html> <html lang="en"> <head> <meta charset ...
- 2019-08-15 纪中NOIP模拟B组
T1 [JZOJ3455] 库特的向量 题目描述 从前在一个美好的校园里,有一只(棵)可爱的弯枝理树.她内敛而羞涩,一副弱气的样子让人一看就想好好疼爱她.仅仅在她身边,就有许多女孩子想和她BH,比如铃 ...
- 小匠第二周期打卡笔记-Task03
一.过拟合欠拟合及其解决方案 知识点记录 模型选择.过拟合和欠拟合: 训练误差和泛化误差: 训练误差 :模型在训练数据集上表现出的误差, 泛化误差 : 模型在任意一个测试数据样本上表现出的误差的期望, ...
- Sql Server:创建用户并指定该用户只能看指定的视图,除此之外的都不让查看
1,在sql server中选择好要操作的数据库 2,--当前数据库创建角色 exec sp_addrole 'seeview' --创建了一个数据库角色,名称为:[seeview] 3,- ...
- Wannafly Camp 2020 Day 2C 纳新一百的石子游戏
为什么为了这么个简单题发博客呢? 因为我又因为位运算运算符优先级的问题血了 #include <bits/stdc++.h> using namespace std; #define in ...
- spring boot使用freemarker模版整合spring Data JPA
目录结构 第一步:在pom.xml文件中添加依赖 <!--模板依赖--> <dependency> <groupId>org.springframework.boo ...
- 【Redis运行状态下切换RDB备份至AOF备份】
"redis持久化方式有哪些?又有何区别? rdb:基于快照的持久化,速度更快,一般用作备份,主从复制也是依赖于rdb持久化功能. aof:以追加的方式记录redis操作日志的文件,可最大程 ...
- 剑指offer 面试题. 剪绳子
题目描述 给你一根长度为n的绳子,请把绳子剪成整数长的m段(m.n都是整数,n>1并且m>1),每段绳子的长度记为k[0],k[1],...,k[m].请问k[0]xk[1]x...xk[ ...
- Tomcat 端口配置,及原理详解
1 tomcat 文件配置详细说明 tomcat服务器需配置三个端口才能启动,安装时默认启用了这三个端口,当要运行多个tomcat服务时需要修改这三个端口,不能相同.端口配置路径为tomcat\ co ...