MySQL必知必会(第4版)整理笔记
参考书籍:
BookName:《SQL必知必会(第4版)》
BookName:《Mysql必知必会(第4版)》
Author: Ben Forta
说明:本书学习笔记
1、了解SQL
1.1 数据库基础
1.1.1 数据库
数据库是一个以某种有组织的方式存储的数据集合,即保存有组织的数据的容器(通常是一个文件或一组文件)。
数据库软件应称为数据库管理系统(DBMS)。
1.1.2 表
表是一种结构化的文件,可用来存储某种特定类型的数据。
模式,关于数据库和表的布局及特性的信息。
1.1.3 列和数据类型
列,表中的一个字段,存储表中的某部分信息。
所有表都是由一个或多个列组成的。
数据类型,所允许的数据的类型。每个表列都有相应的数据类型,它限制(或允许)该列中存储的数据。
1.1.4 行
行,表中的一个记录。
表中的数据都是按行存储的,所保存的每个记录存储在自己的行内。
1.1.5 主键
主键,一列(或一组列),其值能够唯一标识表中每一行。
表中的任何列都可以作为主键,只要满足:
(1)任意两行都不具有相同的主键值;
(2)每一行都必须具有一个主键值;
(3)主键列中的值不允许修改或更新;
(4)主键值不能重用(如果某行从表中删除,它的主键不能赋给以后的新行)。
1.2 什么是SQL
SQL是Structured Query Language(结构化查询语言)的缩写。SQL是一种专门用来与数据库沟通的语言。
2、MySQL简介
数据所有的存储、检索、管理和处理实际上是由数据库软件——DBMS完成的。
MySQL是一种DBMS,即它是一种数据库软件。
DBMS可分为两类:一类为基于共享文件系统的DBMS,另一类为基于客户机——服务器的DBMS。
3、使用MySQL
3.1 连接
为了连接到MySQL,需要以下信息:
(1)主机名(计算机名),如果连接到本地MySQL服务器,为localhost;
(2)端口(如果使用默认端口3306之外的端口);
(3)一个合法的用户名;
(4)用户口令。
3.2 选择数据库
在最初连接到MySQL时,没有任何的数据库打开供使用,故在能执行任意数据库操作前,需要选择一个数据库,可使用USE关键字。

这里显示出的Database changed消息是mysql命令行实用程序在数据库选择成功后显示的。
必须先使用USE打开数据库,才能读取其中的数据。
3.3 了解数据库和表
数据库、表、列、用户、权限等的信息被存储在数据库和表中,可用MySQL的SHOW命令来显示这些信息。

SHOW DATABASES; 返回可用数据库的一个列表。
SHOW TABLES; 返回当前选择的数据库可用表的列表 。
SHOW COLUMNS FROM test_demo; SHOW COLUNNS要求给出一个表名,它对每个字段返回一行,行中包含字段名、数据类型、是否允许NULL、健信息
、默认值以及其他信息(如字段名的auto_increment)。
SHOW STATUS; 用于显示广泛的服务器状态信息。
SHOW CREATE DATABASE; 用来显示创建特定数据库。
SHOW CREATE TABLE; 用来显示创建特定表。
SHOW GRANTS; 用来显示授权用户(所有用户或特定用户)的安全权限。
SHOW ERRORS;和SHOW WARNINGS; 用来显示服务器错误或警告信息。
4、检索数据
补充:(1)多条SQL语句必须以分号(;)分隔。
(2)SQL语句不区分大小写,一般建议所有SQL关键字使用大写,而对所有列和表明使用小写。
(3)在处理SQL语句时, 其中所有空格都被忽略;SQL语句可以在上一行给出,也可以分成许多行。
4.1 SELECT语句
SELECT语句,它的作用是从一个或多个表中检索信息。
为了使用SELECT检索表数据,必须至少给出两条信息——想选择什么,以及从什么地方选择。
4.2 检索单个列
SELECT prod_name FROM products;
所需的列名在SELECT关键字之后给出,FROM关键字指出从其中检索数据的表名。
4.3 检索多个列
在SELECT关键字后给出多个列名,列名之间必须以逗号分隔。
SELECT prod_id, prod_name, prod_price FROM products;
指定3个列名。
4.4 检索所有列
在实际列名的位置使用星号(*)通配符,SELECT语句可以检索所有的列而不必逐个列出他们。
SELECT * FROM products;
虽然使用通配符可能会使人省事不用明确列出所需列,但检索不需要的列通常会降低检索和应用程序的性能。
4.5 检索不同的行
SELECT vend_id FROM products;
vend_id 为其他与products相关联的表的主键,但为products的某列。
SELECT DISTINCT vend_id FROM products;
DISTINCT筛选重复数据。使用DISTINCT关键字,它必须直接放在列名的前面。DISTINCT关键字应用于所有列而不仅仅是前置它的列。
4.6 限制结果
DISTINCT筛选重复数据。使用DISTINCT关键字,它必须直接放在列名的前面。DISTINCT关键字应用于所有列而不仅仅是前置它的列。
4.6 限制结果
为了返回第一行或前几行,可使用LIMIT字句。
SELECT prod_name FROM products LIMIT 5; --LIMIT 5 指示MySQL返回不多于5行。
SELECT prod_name FROM products LIMIT 5,5; --LIMIT 5,5 指示MySQL返回从行5开始的5行。第一个数为开始位置,第二个数为要检索的行数。
其他写法:SELECT prod_name FROM products LIMIT 4 OFFSET 3; --从行3开始取4行,同LIMIT 3,4。
4.7 使用完全限定的表名
表名可以是完全限定的。
SELECT products.prod_name FROM crashcourse.products; --products为表名,crashcourse为数据库名。
5、排序检索数据
5.1 排序数据
关系数据库设计理论认为,如果不明确规定排序顺序,则不应该假定检索出的数据的顺序有意义。
子句,SQL语句由子句构成,有些子句是必须的,而有的是可选的;一个子句通常由一个关键字和所提供的数据组成。
使用ORDER BY 子句明确地排序SELECT检索出来的数据。
SELECT prod_name FROM products ORDER BY prod_name; --指示MySQL对prod_name列以字母顺序排序数据。
提示:用非检索的列排序数据是完全合法的。
5.2 按多个列排序
为了按多个列排序,只要指定列名,列名之间用逗号分开即可。
SELECT prod_id, prod_name, prod_price
FROM products
ORDER BY prod_price, prod_name; --先按prod_price排序,后按prod_name排序(当prod_price唯一时,prod_name忽略排序)
5.3 指定排序方向
数据排序默认为生序排序,为进行降序排序,必须指定DESC关键字。
SELECT prod_id, prod_price, prod_name
FROM products
ORDER BY prod_price DESC;
提示:(1)DESC 关键字只应用到直接位于其前面的列名;
(2)如果想在多个列上进行降序排列,必须对每个列指定DESC关键字;
(3)与DESC相反的关键字是ASC,在升序排序时可以指定它。
其他:在给出ORDER BY子句时,应该保证它位于FROM子句之后。如果使用LIMIT,它必须位于ORDER BY之后。
6、过滤数据
使用SELECT语句的WHERE子句指定搜索条件
6.1 使用WHERE子句
只检索所需数据需要指定搜索条件(search criteria),搜索条件也称为过滤条件(filter condition)。
在WHERE语句中,数据根据WHERE子句中指定的搜索条件进行过滤。
SELECT prod_name, prod_price
FROM products
WHERE prod_price=2.50;
其他:在同时使用ORDER BY 和WHERE子句时,应该让ORDER BY位于WHERE之后。
6.2 WHERE子句操作符
说明:<> 不等于, != 不等于,BETWEEN 在指定的两个值之间
6.2.1 检查单个值(<, >, =, <=,>=)
6.2.2 不匹配检查(!= 和<>)
6.2.3 范围值检查
在使用BETWEEN时,必须指定两个值,所需范围的低端值和高端值,这两个值必须用AND关键字分隔。
SELECT prod_name, prod_price
FROM products
WHERE prod_price BETWEEN 5 AND 10;
6.2.4 空值检查
在创建表时,表设计人员可以指定其中的列是否可以不包含值。在一个列不包含值时,称为包含空值NULL。
WHERE子句IS NULL检查具有NULL值的列。
SELECT prod_name
FROM products
WHERE prod_price IS NULL;
7、数据过滤
7.1 组合WHERE子句
为了进行更强的过滤,MySQL允许给出多个WHERE子句以AND字句的方式或OR子句的方式使用。
7.1.1 AND操作符
用来指示检索满足所有给定条件的行。
7.1.2 OR操作符
指示检索匹配任一条件的行。
7.1.3 计算次序
SQL在处理OR操作符前,优先处理AND操作符。
使用圆括号明确地分组相应的操作符。
7.2 IN操作符
IN操作符用来指定条件范围,范围中的每个条件都可以进行匹配。IN取的合法值是由逗号分隔的清单,全都括在圆括号中。
SELECT prod_name, prod_price
FROM products
WHRER vend_id IN (1002,1003)
ORDER BY prod_name;
7.3 NOT操作符
WHERE子句中的NOT操作符有且只有一个功能,那就是否定它之后所跟的任何条件。
8、用通配符进行过滤
使用LIKE操作符进行通配搜索,以便对数据进行复杂过滤。
8.1 LIKE操作符
8.1.1 百分号(%)通配符
在搜索串中,%表示任何字符出现任意次数。
SELECT prod_id, prod_name
FROM products
WHERE prod_name LIKE 'jet%';
其他:(1)'%jet%'首尾 、 'je%t'中间
(2)%代表搜索模式中给定位置的0个、1个或多个字符。
(3)不能匹配NULL
8.1.2 下划线(_)通配符
下划线只匹配单个字符。
9、用正则表达式进行搜索
9.1 正则表达式介绍
正则表达式的作用是匹配文本,将一个模式(正则表达式)与一个文本串进行比较。
9.2 使用MySQL正则表达式
MySQL仅支持多数正则表达式实现的一个很小的子集。、
9.2.1 基本字符匹配
SELECT prod_name
FROM products
WHERE prod_name REGEXP '1000'
ORDER BY prod_name;
它告诉MySQL,REGEXP后所跟的东西作为正则表达式处理。
“.”是正则表达式语言中一个特殊的字符,它表示匹配任意一个字符。
MySQL中的正则表达式匹配不区分大小写,为了区分大小写,可使用BINARY关键字,如WHERE prod_name REGEXP BINARY 'JetPacl .000'
9.2.2 进行OR匹配
为搜索两个串之一,使用‘|’,它为正则表达式的OR操作符,表示匹配其中之一。
SELECT prod_name
FROM products
WHERE prod_name REGEXP '1000|2000'
ORDER BY prod_name;
9.2.3 匹配几个字符之一
使用一组用‘[ ] ’括起来的字符,匹配其中任意单一字符。
SELECT prod_name
FROM products
WHERE prod_name REGEXP '[123] Ton'
ORDER BY prod_name;
在集合的开始处放置一个‘^’,可否定一个字符集。
9.2.4 匹配范围
集合可用来定义要匹配的一个或多个字符。简化使用‘—’,例如 [123456]等同于[1-6]
9.2.5 匹配特殊字符
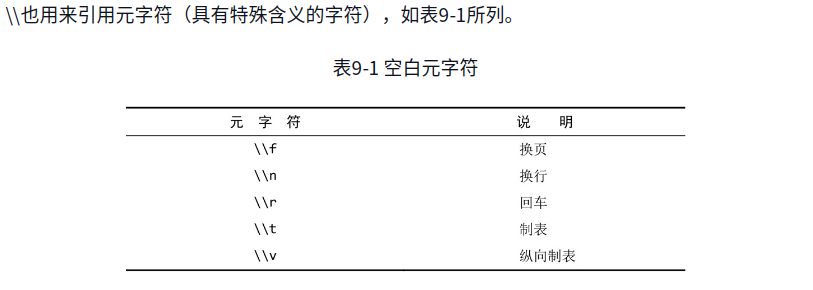
正则表达式内具有特殊意义的所有字符都必须转义‘\\’

9.2.6 匹配字符类

9.2.7 匹配多个实例

9.2.8 定位符

SELECT prod_name
FROM products
WHERE prod_name REGEXP '^[0-9\\.]'
ORDER BY prod_name;

10、创建计算字段
10.1 计算字段
字段(field)与列的意思相同。
10.2 拼接字段
拼接(concatenate),将值联结到一起构成单个值。
SELECT Concat(vend_name , ' (' , RTrim(vend_country) , ')' ) AS vend_title
FROM vendors
ORDER BY vend_name;
Concat()需要一个或多个指定的串,各个串之间用逗号分隔。
RTrim()函数去掉值右边的所有空格。LTrim()函数去掉值左边的所有空格、Trim()去掉左右两边的空格。
AS 关键字赋予别名使计算字段存储,从而被应用。
10.3 执行算术计算

用圆括号可以区分优先顺序。
11、使用数据处理函数
11.1 函数
11.2 使用函数
11.2.1 文本处理函数

Soundex是一个将任何文本串转换为描述其语音表示的字母数字模式的算法,使其能对串进行发音比较而不是字母比较。
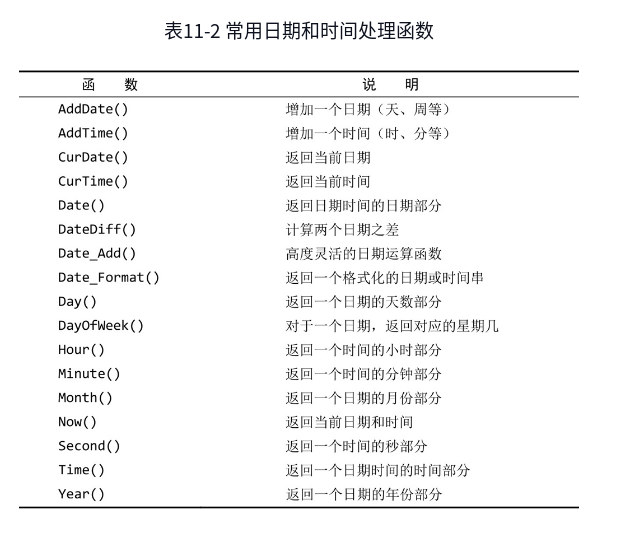
11.2.2 日期和时间处理函数
11.2.3 数值处理函数

12、汇总数据
12.1 聚集函数

COUNT()函数如果指定列名,则指定列的值为空的行被COUNT()函数忽略,但如果COUNT()函数中用的是星号(*),则不忽略。
AVG()、MAX()、MIN()、SUM()函数忽略列值为NULL的行。
12.2 聚集不同值
12.3 组合聚集函数
13、分组数据
13.1 分组数据
分组允许把数据分为多个逻辑组,以便能对每个组进行聚集计算
13.2 创建分组
SELECT vend_id, COUNT(*) AS num_prods
FROM products
GROUP BY vend_id;
GROUP BY子句指示MySQL按vend_id排序并分组数据;
GROUP BY 子句出现在WHERE子句之后,ORDER BY子句之前。
13.3 过滤分组
HAVING过滤分组,规定包括哪些分组,排除哪些分组。
WHERE 和 HAVING 类似,但是WHERE 过滤行,HAVING 过滤分组。
SELECT cust_id, COUNT(*) AS orders
FROM orders
GROUP BY cust_id
HAVING COUNT(*)>=2;
13.4 分组和排序

13.5 SELECT子句顺序

14、 使用子查询
14.1 子查询
SQL允许创建子查询(subquery),即嵌套在其他查询中的查询。
14.2 利用子查询进行过滤
14.3 作为计算字段使用子查询
15、联接表
15.1 联结
15.1.1 关系表
外键(foreign key)外键为某个表中的一列,它包含另外一个表的主键,定义了两个表之间的关系
15.1.2 为什么要使用联结
联结,一种机制,用来在一条SELECT语句中关联表。
15.2 创建联结
SELECT vend_name, prod_name, prod_price
FROM vendors, products
WHERE vendors.vend_id = products.vend_id
ORDER BY vend_name, prod_name;
15.2.1 WHERE子句的重要性
15.2.2 内部联结
等值联结(equijoin),它基于两个表之间的相等测试。
其他语法:
SELECT vend_name, prod_name, prod_price
FROM vendors INNER JOIN products
ON vendors.vend_id=products.vend_id;
这两个表之间的关系是FROM子句的组成部分,以INNER JOIN指定。
15.2.3 联结多个表
每个联结关系用AND拼接
16、创建高级联结
16.1 使用表别名
别名除了用于列名和计算字段外,SQL还允许给表名起别名。
16.2 使用不同类型的联结
16.2.1 自联结
SELECT p1,prod_id, p1.prod_name
FROM products AS p1, products AS p2
WHERE p1.vend_id=p2.vend_id
AND p2.prod_id = 'DTNTR';
16.2.2 自然联结
自然联结排除多次出现,使每个列只返回一次。
一般是通过对表使用通配符(SELECT *),对所有其他表的列使用明确的子集来完成。
16.2.3 外部联结
SELECT customers.cust_id, orders.order_num
FROM customers LEFT OUTER JOIN orders
ON customers.cust_id=orders.cust_id;
在使用OUTER JOIN语法时,必须使用RIGHT或LEFT关键字指定包括其所有行的表(RIGHT指出的是OUTER JOIN右边的表,LEFT指出的是OUTER JOIN左边的表)
16.3 使用带聚集函数的联结
17、组合查询
利用UNION操作符将多条SELECT语句组合成一个结果集
17.1 组合查询
MySQL允许执行多个查询,并将结果作为单个查询结果集返回。这些组合查询称为并(union)或复合查询(compound query)
两种情况下需要使用组合查询:
(1)在单个查询中从不同的表返回类似结构的数据
(2)对单个表执行多个查询,按单个查询返回数据
17.2 创建组合查询
在各条语句之间放上关键字UNION
SELECT vend_id, prod_id, prod_price
FROM products
WHERE prod_price <=5
UNION
SELECT vend_id,prod_id,prod_price
FROM products
WHERE vend_id IN (1001,1002)
OEDER BY vend_id, prod_price;
如果想返回所有匹配行,可使用UNION ALL而不是UNION
在用UNION组合查询时,只能使用一条ORDER BY子句,它必须出现在最后一条SELECT语句之后
18、全文本搜索
18.1 理解全文本搜索
使用全文本搜索时,MySQL不需要分别查看每个行,不需要分别分析和处理每个词。MySQL创建指定列中各词的一个索引,搜索可以针对这些词进行。这样,MySQL可以
快速有效地决定哪些词匹配(哪些行包含它们),哪些词不匹配,它们匹配的频率,等等。
18.2 使用全文本搜索
18.2.1 启用全文本搜索支持
CREATE TABLE productnotes
(
note_id int NOT NULL AUTO_INCREMENT,
prod_id char(10) NOT NULL,
note_date datetime NOT NULL,
note_text text NULL,
PRIMARY KEY(note_id),
FULLTEXT(note_text)
) ENGINE=MyISAM;
CREATE TABLE语句定义表productnotes并列出它所包含的列。
为了进行全文搜索,MySQL根据子句FULLTEXT(note_text)的指示对它进行索引。FULLTEXT索引单个列,也可以指定多个列。
在定义之后,MySQL自动维护该索引,即在增加、更新或删除行时,索引随之自动更新。
18.2.2 进行全文本搜索
在索引之后,使用两个函数Match()和Against()执行全文本搜索,其中Match()指定被搜索的列,Against()指定要使用的搜索表达式。
SELECT note_text
FROM productnotes
WHERE Match(note_text) Against('rabbit');
18.2.3 使用查询扩展
查询扩展用来设法放宽所返回的全文本搜索结果的范围。
SELECT note_text
FROM productnotes
WHERE Match(note_text) Against('anvils' WITH QUERY EXPANSION)
18.2.4 布尔全文搜索
SELECT note_text
FROM productnotes
WHERE Match(note_text) Against('heavy -rope*' IN BOOLEAN MODE);
-rope*明确指示MySQL排除包含rope*的行。

19、插入数据
利用SQL的INSERT语句将数据插入表中
19.1 数据插入
INSERT用来插入(或添加)行到数据库,使用的使用方式:
(1)插入完整的行
(2)插入行的一部分
(3)插入多行
(4)插入某些查询的结果
19.2 插入完整的行
INSERT要求指定表名和被插入到新行中的值。
INSERT INTO customers(
cust_addr,
cust_city
)
VALUES(
NULL,
'Pep E'
);
19.3 插入多个行
使用多条INSERT语句,每条语句用一个分号结束。
19.4 插入检索出的数据
INSERT INTO customers(列名1)
SELECT 列名1
FROM other_customers;
20、更新和删除数据
20.1 更新数据
可采用两种方式使用UPDATE:(1)更新表中特定的行;(2)更新表中所有行
基本的UPDATE语句由3部分组成:(1)要更新的表;(2)列名和它们的新值;(3)确定要更新行的过滤条件。
UPDATE customers
SET cust_email='example@qq.com',
cust_name='enheng'
WHERE cust_id=1005;
SET命令用来将新值赋给被更新的列。
更新多个列时,只需要使用单个SET命令,每个‘列=值’对之间用逗号分隔
删除某个列的值,可设置它为NULL。
20.2 删除数据
可采用两种方式使用DELETE:(1)删除表中特定的行;(2)删除表中所有行
DELETE FROM customers
WHERE cust_id=10006;
DELETE删除整行而不是删除列。
如果想从表中删除所有行,不要使用DELETE,可使用TRUNCATE TABLE语句。
21、创建和操纵表
21.1 创建表
为了利用CREATE TABLE 创建表,必须给出下列信息:
(1)新表的名字,关键字CREATE TABLE之后给出
(2)表列的名字和定义,用逗号分隔
CREATE TABLE productnotes
(
note_id int NOT NULL AUTO_INCREMENT,
prod_id char(10) NOT NULL DEFAULT 1,
note_date datetime NOT NULL,
note_text text NULL,
PRIMARY KEY(note_id),
FULLTEXT(note_text)
) ENGINE=InnoDB;
每列的定义以列名(它在表中是唯一的)开始,后跟列的数据类型。
表的主键可以在创建表时用PRIMARY KEY关键字指定。
主键只能使用不允许NULL值的列。
AUTO_INCREMENT告诉MySQL,本列每增加一行时自动增量,每个表只允许有一个这样的列,而且它必须被索引。
SELECT_last_instert_id(),此语句返回最后一个AUTO_INCREMENT值。
默认值用列定义中的DEFAULT关键字指定。
ENGINE指定数据库引擎
21.2 更新表
使用ALTER TABLE更改表结构,必须给出下面的信息:
(1)在ALTER TABLE之后给出要更改的表名(该表必须存在)
(2)所做更改的列表
ALTER TABLE vendors
ADD vend_phone CHAR(20); --添加列必须明确其数据类型
删除添加的列
ALTER TABLE vendors
DROP COLUMN vend_phone;
21.3 删除表
DROP TABLE customers2;
执行这条语句将永久删除该表。
21.4 重命名表
RENAME TABLE customers2 TO customers;
22、使用视图
22.1 视图
视图是虚拟的表,与包含数据的表不一样,视图只包含使用时动态检索数据的查询
使用联结:
SELECT cust_name, cust_contact
FROM customers, oders, orderitems
WHERE customers.cust_id = orders.cust_id
ADD orderitems.order_num=orders.order_num
ADD prod_id ='TNT2'
使用视图:
SELECT cust_name, cust_contact
FROM productcustomers
WHERE prod_id ='TNT2'
productcustomers是整个查询包装成的虚拟表,是一个视图,它不包含表中应该有的任何列或数据,它包含的是一个SQL查询。
22.1.1 为什么使用视图
22.1.2 视图的规则和限制
(1)视图必须唯一命名
(2)对于可以创建的视图数目没有限制
(3)为了创建视图,必须具有足够的访问权限
(4)视图可以嵌套
(5)ORDER BY能使用
(6)视图不能索引,也不能有关联的触发器或默认值
(7)视图可以和表一起使用
22.2 使用视图
视图的创建:
(1)视图用CREATE VIEW语句来创建
(2)使用SHOW CREATE VIEW viewname; 来查看创建视图
(3)用DROP删除视图,其语法为DROP VIEW viewname;
(4)更新视图时,可以先用DROP再用CREATE,也可以直接用CREATE OR REPLACE VIEW
22.2.1 利用视图简化复杂的联结
CREATE VIEW productcustomers AS
SELECT cust_name, cust_contact,prod_id
FROM customers, orders, orderitems
WHERE customers.cust_id = orders.cust_id
AND orderitems.order_num = orders.order_num;
创建一个productcustomers的视图,联结3个表。
22.2.2 用视图重新格式化检索出的数据
22.2.3 用视图过滤不想要的数据
22.2.4 使用视图与计算字段
22.2.5 更新视图
视图通常是可更新的,更新一个视图将更新其基表。
如果视图定义中以下操作,则不能进行视图的更新:
(1)分组(使用GROUP BY 和 HAVING)
(2)联结
(3)子查询
(4)并(UNION)
(5)函数聚集(MAX()、Count()等)
(6)DISTINCT(去重)
(7)导出(计算)列
23、使用存储过程
23.1 存储过程
存储过程简单来说,就是为以后的使用而保存的一条或多条MySQL语句的集合。
23.2 为什么要使用存储过程
23.3 使用存储过程
23.3.1 执行存储过程
MySQL称存储过程的执行为调用。CALL接受存储过程的名字以及需要传递给它的任意参数。
CALL productpricing(@pricelow,
@pricehigh,
@priceaverage);
23.3.2 创建存储过程
CREATE PROCEDURE productpricing()
BEGIN
SELECT Avg(prod_price) AS priceaverage
FROM products;
END;
存储过程名为productpricing,用CREATE PROCEDURE productpricing()语句定义。
如果存储过程接受参数,它们将在()中列举出来。
BEGIN和END语句用来限定存储过程体。
过程体本身是一个简单的SELECT语句。
DELIMITER//告诉命令行使用程序使用//作为新的语句结束分隔符,恢复可使用DELIMITER ; 。
DELIMITER //
CREATE PROCEDURE productpricing()
BEGIN
SELECT Avg(prod_price) AS priceaverage
FROM products;
END//
DELIMITER ;
23.3.3 删除存储过程
存储过程在创建之后,被保存在服务器上以供使用,直至被删除。
删除存储过程,可使用语句:
DROP PROCEDURE productpricing IF EXISTS;
注意: CALL productpricing()时需要有()符号, 删除时后面没有(),只给出存储过程名。
23.2.4 使用参数
CREATE PROCEDURE productpricing(
OUT pl DECIMAL(8,2),
OUT ph DECIMAL(8,2),
OUT pa DECIMAL(8,2)
)
BEGIN
SELECT Min(prod_price)
INTO pl
FROM products;
SELECT Max(prod_price)
INTO ph
FROM products;
SELECT Avg(prod_price)
INTO pa
FORM products;
END;
这个存储过程接受3个参数,每个参数必须具有指定的类型,DECIMAL(8,2)十进制。
关键字OUT指出相应的参数用来从存储过程中传出一个值(返回给调用者)。
MySQL支持IN(传递给存储过程)、OUT(从存储过程传出)和 INOUT(对存储过程传入和传出)类型的参数。
为此调用这个存储过程,必须指定3个变量名。
CALL productpricing(@pricelow,
@pricehigh,
@priceaverage);
@后面的名字,它们是存储过程将保存结果的3个变量的名字
所有MySQL变量都必须以@开始
为了获得3个值,可使用语句:SELECT @priceaverage, @pricelow, @priceheigh;
23.2.5 建立智能存储过程
23.2.6 检查存储过程
SHOW CREATE PROCEDURE productpricing; --显示创建一个存储过程。
SHOW PROCEDURE STATUS; --获得包括何时、由谁创建等详细信息的存储过程列表。
24、使用游标
24.1 游标
游标(cursor)是一个存储在MySQL服务器上的数据库查询,它不是一条SELECT语句,而是被该语句检索出来的结果集。在存储了游标之后,应用程序
可以根据需要滚动或浏览其中的数据。
24.2 使用游标
24.2.1 创建游标
CREATE PROCEDURE processorders()
BEGIN
DECLARE ordernumbers CURSOR
FOR
SELECT order_num FROM orders;
END;
DECLARE命名游标,并定义相应的SELECT语句,根据需要带WHERE和其他字句。
24.2.2 打开和关闭游标
OPEN ordernumbers;
CLOSE ordernumbers;
24.2.3 使用游标数据
在一个游标被打开后,可以使用FETCH语句分别访问它的每一行,FETCH指定检索什么数据(所需的列),检索出来的数据存储在什么地方。它还向前移动游标中
的内部行指针,使下一条FETCH语句检索下一行(不重复读取同一行)
25、触发器
25.1 触发器
触发器是MySQL响应以下任意语句而自动执行的一条MySQL语句(或位于BEGIN和END语句之间的一组语句):DELETE、INSERT、UPDATE
25.2 创建触发器
创建触发器时,需要给出4条信息:
(1)唯一的触发器名
(2)触发器关联的表
(3)触发器应该响应的活动(DELETE、INSERT、UPDATE)
(4)触发器何时执行(处理之前或之后)
触发器用CREATE TRIGGER语句创建。
CREATE TRIGGER newproduct AFTER INSERT ON products
FOR EACH ROW SELECT 'Product added';
BEFORE和AFTER决定之前或之后,FOR EACH ROW 定义对每个插入行执行。
注意:(1)只有表才支持触发器,视图不支持(临时表也不支持)
(2)触发器按每个表每个事件每次地定义,每个表每个事件每次只允许一个触发器,每个表只支持6次(DELETE、INSERT、UPDATE之前之后)。
25.3 删除触发器
触发器不能更新或覆盖,为了修改一个触发器,必须先删除它,然后再重新创建。
DROP TRIGGER newproduct;
25.4 使用触发器
25.4.1 INSERT触发器
INSERT触发器在INSERT语句执行之前或之后执行
(1)在INSERT触发器代码内,可引用一个名为NEW的虚拟表,访问被插入的行
(2)在BEFORE INSERT触发器中,NEW中的值也可以被更新(允许更改被插入的值)
(3)对于AUTO_INCREMENT列,NEW在INSERT执行之前包含0,在INSERT执行之后包含新的自动生成值。
CREATE TRIGGER neworder AFTER INSERT ON orders
FOR EACH ROW SELECT NEW.order num;
25.4.2 DELETE触发器
DELETE触发器在DELETE语句执行之前或之后执行
(1)在DELETE触发器代码内,可以引用一个名为OLD的虚拟表,访问被删除的行
(2)OLD中的值全部都是只读的,不能更新
CREATE TRIGGER deleteorder BEFORE DELETE ON orders
FOR EACH ROW
BEGIN
INSERT INTO archive_orders(order_num, order_date, cust_id)
VALUES(OLD.order_num, OLD.order_date,OLD.cust_id);
ENG;
25.4.3 UPDATE触发器
UPDATE触发器在UPDATE语句执行之前或之后执行
(1)在UPDATE触发器代码中,可以引用一个名为OLD的虚拟表访问以前(UPDATE语句前)的值,引用一个名为NEW的虚拟表访问新更新的值
(2)在BEFORE UPDATE触发器中,NEW中的值可能也被更新(允许更改将要用于UPDATE语句中的值)
(3)OLD中的值全都是只读的,不能更新
CREATE TRIGGER updatevendor BEFORE UPDATE ON vendors
FOR EACH ROW SET NEW.vend_state=Upper(NEW.vend_state);
26、管理事物处理
26.1 事物处理
并非所有的引擎都支持事物处理。
事物处理是一种机制,用来管理必须成批执行的MySQL操作,以保证数据库不包含不完整的操作结果。利用事物处理,可以保证一组操作不会中途停止,它们或
者作为整体执行,或者完全不执行(除非明确指示)。如果没有错误发生,整组语句提交给(写道)数据库表。如果发生错误,则进行回退(撤销)以恢复数据库到
某个已知且安全的状态。
事物(transaction)指一组SQL语句
回退(rollback)指撤销指定SQL语句的过程
提交(commit)指将未存储的SQL语句结果写入数据库表
保留点(savepoint)指事物处理中设置的临时占位符(place-holder),你可以对它发布回退(与回退整个事物处理不同)
26.2 控制事物处理
管理事物处理的关键在于将SQL语句组分解为逻辑快,并明确规定数据何时应该回退,何时不应该回退
MySQL使用语句标识事物的开始:
START TRANSACTION
26.2.1 使用ROLLBACK
MySQL的ROLLBACK命令用来回退(撤销)语句
SELECT * FROM ordertotals; --验证该表不为空
START TRANSACTION; --开始一个事物
DELETE FROM ordertotals; --删除所有行
SELECT * FROM ordertotals; --检查是否空
ROLLBACK; --回退开始的所有事物
SELECT * FROM ordertotals; --验证不为空
注意:不能回退CREATER或DROP,SELECT语句
26.2.2 使用COMMIT
事物处理模块中,提交不会隐含地进行。为了明确的提交,使用COMMIT语句。
START TRANSACTION;
DELETE FROM orderitems WHERE order_num=20010;
DELETE FROM orders WHERE order_num=20010;
COMMIT;
提示:最后的COMMIT语句仅在不出错时写出更改。
26.2.3 使用保留点
为了支持回退部分事物处理,必须能在事物处理快中合适的位置放置占位符,当需要回退时,可以回退到某个占位符
创建保留点
SAVEPOINT delete1; --每个保留点都取标识它的唯一名字
为了回退到保留点
ROLLBACK TO delete1;
26.2.4 更改默认的提交行为
指示MySQL不自动提交更改,需要使用以下语句:
SET autocommit=0; --autocommit标志决定是否自动提交更改
27、安全管理
27.1 访问控制
27.2 管理用户
MySQL用户账号和信息存储在名为mysql的MySQL数据库中。
获取所有用户账号列表时
USE mysql;
SELECT user FROM user;
mysql数据库有一个名为user的表,它包含所有用户账号。user表有一个名为user的列,它存储用户登陆名。
27.2.1 创建用户账号
创建一个新用户账号,使用CREATE USER语句
CREATE USER ben IDENTIFIED BY 'p@$$wOrd';
为重新命名一个用户账号,使用RENAME USER语句
RENAME USER ben TO bforta;
27.2.2 删除用户账号
删除一个用户账号(以及相关的权限),使用DROP USER语句
DROP USER bforta;
27.2.3 设置访问权限
新创建的用户账号没有访问权限,它们能登陆mysql,但不能看到数据,不能执行任何操作数据库操作
为看到赋予用户账号的权限,使用SHOW GRANTS FOR
SHOW GRANTS FOR bforta;
为设置权限,使用GRANT语句,至少给出以下信息:
(1)要授予的权限
(2)被授予访问权限的数据库或表
(3)用户名
GRANT的用法:
GRANT SELECT ON crashcourse.* TO bforta; --此GRANT允许用户在crashcourse.*(crashcourse数据库的所有表)上使用SELECT
SHOW GRANTS反映这个更改:
SHOW GRANTS FOR bforta;
GRANT的反操作为REVOKE,用它来撤销特定的权限。
GRANT和REVOKE可在几个层次上控制访问权限:
(1)整个服务器,使用GRANT ALL和REVOKE ALL
(2)整个数据库,使用ON database.*
(3)特定的表,使用ON database.table
(4)特定的列
(5)特定的存储过程
授予权限时,可通过列出个权限并用逗号分隔,将多条GRANT语句串在一起
GRANT SELECT,INSERT ON crashcourse.* TO bforta
27.2.4 更改口令
更改用户口令,可使用SET PASSWORD语句
SELECT PASSWORD FOR bforta=Password('n3w p@$$wOrd'); --新口令必须传递到Password()函数进行加密
其他
SET PASSWORD =Password('n3w p@$$wOrd'); --在不指定用户名时,SET PASSWORD更新当前登陆用户的口令
27.2.5 权限表

28、数据类型




MySQL必知必会(第4版)整理笔记的更多相关文章
- 读书笔记汇总 - SQL必知必会(第4版)
本系列记录并分享学习SQL的过程,主要内容为SQL的基础概念及练习过程. 书目信息 中文名:<SQL必知必会(第4版)> 英文名:<Sams Teach Yourself SQL i ...
- 学习《SQL必知必会(第4版)》中文PDF+英文PDF+代码++福达BenForta(作者)
不管是数据分析还是Web程序开发,都会接触到数据库,SQL语法简洁,使用方式灵活,功能强大,已经成为当今程序员不可或缺的技能. 推荐学习<SQL必知必会(第4版)>,内容丰富,文字简洁明快 ...
- 《MySQL 必知必会》读书总结
这是 <MySQL 必知必会> 的读书总结.也是自己整理的常用操作的参考手册. 使用 MySQL 连接到 MySQL shell>mysql -u root -p Enter pas ...
- mysql学习--mysql必知必会1
例如以下为mysql必知必会第九章開始: 正則表達式用于匹配特殊的字符集合.mysql通过where子句对正則表達式提供初步的支持. keywordregexp用来表示后面跟的东西作为正則表達式 ...
- 《MySQL必知必会》[01] 基本查询
<MySQL必知必会>(点击查看详情) 1.写在前面的话 这本书是一本MySQL的经典入门书籍,小小的一本,也受到众多网友推荐.之前自己学习的时候是啃的清华大学出版社的计算机系列教材< ...
- mysql必知必会系列(一)
mysql必知必会系列是本人在读<mysql必知必会>中的笔记,方便自己以后查看. MySQL. Oracle以及Microsoft SQL Server等数据库是基于客户机-服务器的数据 ...
- 《mysql必知必会》读书笔记--存储过程的使用
以前对mysql的认识与应用只是停留在增删改查的阶段,最近正好在学习mysql相关内容,看了一本书叫做<MySQL必知必会>,看了之后对MySQL的高级用法有了一定的了解.以下内容只当读书 ...
- mysql必知必会
春节放假没事,找了本电子书mysql必知必会敲了下.用的工具是有道笔记的markdown文档类型. 下面是根据大纲已经敲完的章节,可复制到有道笔记的查看,更美观. # 第一章 了解SQL## 什么是S ...
- 《MySQL必知必会》整理
目录 第1章 了解数据库 1.1 数据库基础 1.1.1 什么是数据库 1.1.2 表 1.1.3 列和数据类型 1.1.4 行 1.1.5 主键 1.2 什么是SQL 第2章 MySQL简介 2.1 ...
随机推荐
- KafkaUtils.createDirectStream报错Cannot resolve symbol createDirectStream
一开以为是自己导包导错了,但是对比了一下之前的程序发现并没有错, import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtil ...
- window snmp
https://blog.csdn.net/weixin_30367543/article/details/99923014 https://jingyan.baidu.com/article/e3c ...
- Wannafly Camp 2020 Day 2K 破忒头的匿名信 - AC自动机,dp
给定字典和文章,每个单词有价值,求写文章的最小价值 标准的 AC 自动机 dp,设 \(f[i]\) 表示写 \(s[1..i]\) 的最小价值,建立AC自动机后根据 trans 边暴力转移即可 建了 ...
- Wannafly Camp 2020 Day 6F 图与三角形 - 图论
把黑边视为无边,那么答案之和每个点的度数有关 #include <bits/stdc++.h> using namespace std; #define int long long int ...
- (转)预估大数据量下UV的方法
在实际应用中,我们经常碰到这种情况,即要统计某个对象或者事件独立出现的次数.对于较小的数据量,这很容易解决,我们可以首先在内存中对序列进行排序,然后扫描有序序列统计独立元素数目.其中排序时间复杂度为O ...
- JS高级---浅拷贝
浅拷贝 拷贝就是复制, 就相当于把一个对象中的所有的内容, 复制一份给另一个对象, 直接复制, 或者说, 就是把一个对象的地址给了另一个对象, 他们指向相同, 两个对象之间有共同的属性或者方法, ...
- wpf 移动动画
private void moveTo(Point deskPoint, Control ell, double space) //deskPoint: 控件要移动到的位置 , ell :你要移动的空 ...
- actiBPM插件的办法
1.下载actiBPM到本地 从IDEA官网下载actiBPM.jar包 IDEA官网:https://plugins.jetbrains.com/ 官网搜索actiBPM 2.从本地安装actiBP ...
- linux异常
常见报错语句 Command not found; - 找不到命令(敲入的命令有误或者该命令还没安装) No Such file or directory; - 找不到输入的文件或者目录
- matplotlib 做图通过弹出窗口展示 spyder
tools =>preferences=>Ipython console=>Graphics Graphics backend 中Backend 由Inline改为 Automati ...