InfluxDB的安装和简介
InfluxDB简介
InfluxDB是一个时间序列数据库,旨在处理高写入和查询负载。它是TICK堆栈的组成部分 。InfluxDB旨在用作涉及大量带时间戳数据的任何用例的后备存储,包括DevOps监控,应用程序指标,物联网传感器数据和实时分析。
功能特点
- 基于时间序列,支持与时间有关的相关函数(如最大,最小,求和等)
- 可度量性:你可以实时对大量数据进行计算
- 基于事件:它支持任意的事件数据基于事件:它支持任意的事件数据
主要特点
无结构(无模式):可以是任意数量的列
可拓展的
支持min, max, sum, count, mean, median 等一系列函数,方便统计支持min, max, sum, count, mean, median 等一系列函数,方便统计
原生的HTTP支持,内置HTTP API原生的HTTP支持,内置HTTP API
强大的类SQL语法强大的类SQL语法
自带管理界面,方便使用自带管理界面,方便使用
InfluxDB与传统数据库的比较
| InfluxDB的名词 | 传统数据库的概念 |
|---|---|
| database | 数据库 |
| measurement | 数据库的表 |
| points | 表里的一行数据 |
InfluxDB的独特的特性
point
Point相当于传统数据库里的一行数据,如下表所示:
| point属性 | 传统数据库中的概念 |
|---|---|
| time(时间戳) | 每个数据记录时间,是数据库中的主索引(会自动生成) |
| fields(字段、数据) | 各种记录值(没有索引的属性)也就是记录的值:温度, 湿度 |
| tags(标签) | 各种有索引的属性:地区,海拔 |
注意
在influxdb中,字段必须存在。因为字段是没有索引的。如果使用字段作为查询条件,会扫描符合查询条件的所有字段值,性能不及tag。类比一下,fields相当于SQL的没有索引的列。
tags是可选的,但是强烈建议你用上它,因为tag是有索引的,tags相当于SQL中的有索引的列。tag value只能是string类型。
series
相当于是 InfluxDB 中一些数据的集合,在同一个 database 中,retention policy、measurement、tag sets 完全相同的数据同属于一个 series,同一个 series 的数据在物理上会按照时间顺序排列存储在一起。
> select * from students
name: students
time score stuid value
---- ----- ----- -----
s123
s123
s123
s123
s123
s124
s125
> show series from students
key
---
students,stuid=s123
students,stuid=s124
students,stuid=s125
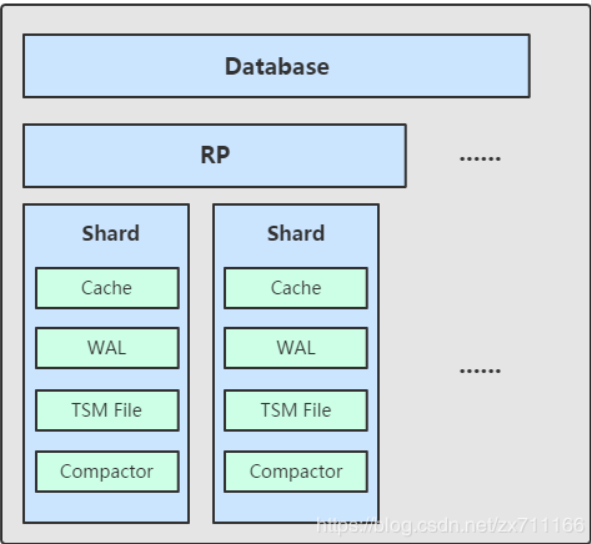
shard
shard 和 retention policy 相关联。每一个存储策略下会存在许多 shard,每一个 shard 存储一个指定时间段内的数据,并且不重复;
例如 7点-8点 的数据落入 shard0 中,8点-9点的数据则落入 shard1 中。
每一个 shard 都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm file。
组件
TSM 存储引擎主要由几个部分组成: cache、wal、tsm file、compactor。
Cache:cache 相当于是 LSM Tree 中的 memtabl。插入数据时,实际上是同时往 cache 与 wal 中写入数据,可以认为 cache 是 wal 文件中的数据在内存中的缓存。当 InfluxDB 启动时,会遍历所有的 wal 文件,重新构造 cache,这样即使系统出现故障,也不会导致数据的丢失。
cache 中的数据并不是无限增长的,有一个 maxSize 参数用于控制当 cache 中的数据占用多少内存后就会将数据写入 tsm 文件。如果不配置的话,默认上限为 25MB,每当 cache 中的数据达到阀值后,会将当前的 cache 进行一次快照,之后清空当前 cache 中的内容,再创建一个新的 wal 文件用于写入,剩下的 wal 文件最后会被删除,快照中的数据会经过排序写入一个新的 tsm 文件中。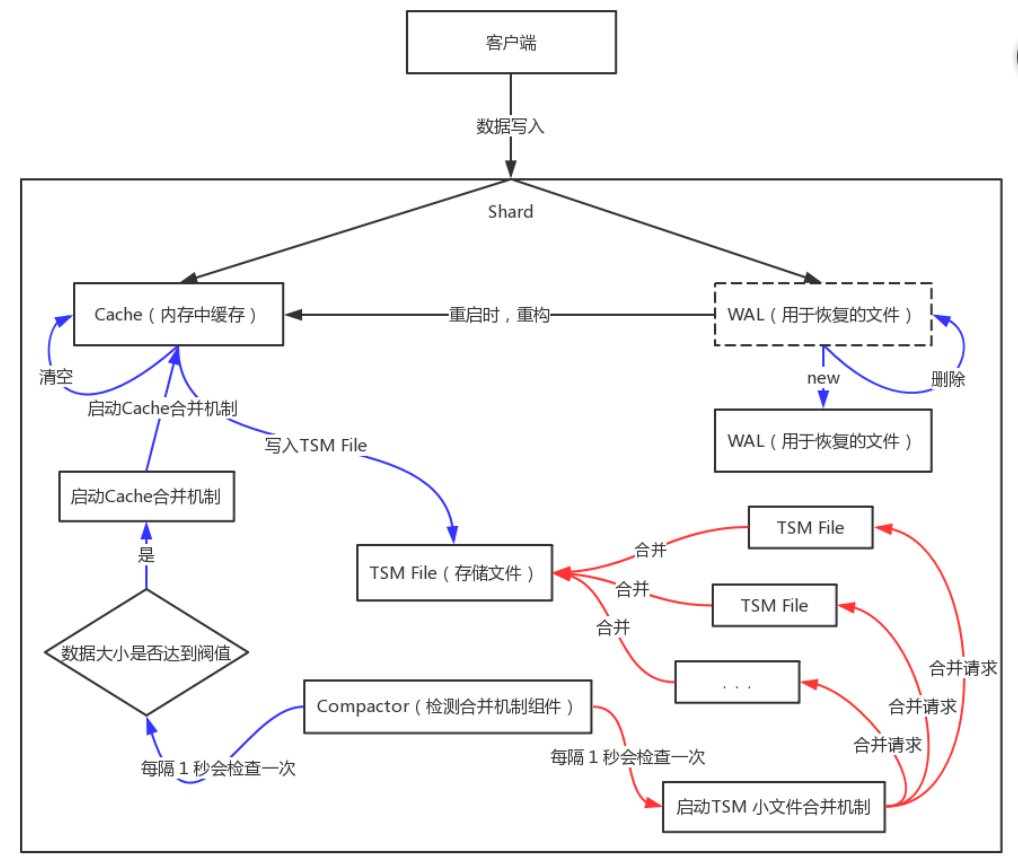
WAL:wal 文件的内容与内存中的 cache 相同,其作用就是为了持久化数据,当系统崩溃后可以通过 wal 文件恢复还没有写入到 tsm 文件中的数据。
TSM File:单个 tsm file 大小最大为 2GB,用于存放数据。
Compactor:compactor 组件在后台持续运行,每隔 1 秒会检查一次是否有需要压缩合并的数据。
主要进行两种操作
一种是 cache 中的数据大小达到阀值后,进行快照,之后转存到一个新的 tsm 文件中。
另外一种就是合并当前的 tsm 文件,将多个小的 tsm 文件合并成一个,使每一个文件尽量达到单个文件的最大大小,减少文件的数量,并且一些数据的删除操作也是在这个时候完成。
安装
环境: CentOS7.0_x64
InfluxDB版本:1.7.0
基础环境
yum install go
InfluxDB的安装
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.7.0.x86_64.rpm
rpm -ivh influxdb-1.2..x86_64.rpm
安装后产生的InfluxDB相关文件讲解
/usr/bin下文件
文件名 文件解析
influxd influxdb服务器
influx influxdb 命令行客户端
influx_inspect 查看工具
influx_stress 压力测试工具
influx_tsm 数据库转换工具(将数据库从b1或bz1格式转换为tsm1格式)
/var/lib/influxdb下文件夹(建完表和库的时候才会有)
| 文件夹 | 文件夹解析 |
|---|---|
| data | 存放最终存储的数据,文件以**.tsm**结尾 |
| meta | 存放数据库元数据 |
| wal | 存放预写日志文件 |
/etc/influxdb下文件
| 文件 | 文件解析 |
|---|---|
| influxdb.conf | influxdb数据库配置文件 |
启动服务
操作服务的相关命令
服务式启动命令
service influxdb start 服务式的其他命令
停止服务
service influxdb stop 重启服务
service influxdb restart 尝试重启服务
service influxdb try-restart 重新加载服务
service influxdb reload 强制重新加载服务
service influxdb force-reload 查看服务状态
service influxdb status
以非服务方式启动
cd /usr/bin;./influxd
服务启动查看是否正常
通过查看服务对应进程

InfluxDB默认使用以下网络端口:
- TCP端口
8086用于通过InfluxDB的HTTP API进行客户端 - 服务器通信 - TCP端口
8088用于RPC服务以进行备份和还原
除了上面的端口,InfluxDB还提供了多个可能需要自定义端口的插件。可以通过配置文件修改所有端口映射,配置文件位于/etc/influxdb/influxdb.conf默认安装位置。
InfluxDB 客户端命令行方式操作
InfluxDB数据库操作
客户端命令行方式操作
[root@localhost influxdb]# influx
Connected to http://localhost:8086 version 1.7.0
InfluxDB shell version: 1.7.
Enter an InfluxQL query
> 显示数据库
> show databases
name: databases
name
----
_internal 新建数据库
> create database testdb
> show databases
name: databases
name
----
_internal
testdb 删除数据库
> drop database testdb
> show databases
name: databases
name
----
_internal 使用数据库 > create database testdb
> use testdb
Using database testdb
InfluxDB 数据表操作
在InfluxDB当中,并没有表(table)这个概念,取而代之的是measurement,measurement的功能与传统数据库中的表一致,因此我们也可以将measurement称为InfluxDB中的表。
显示所有表
show measurement
新建表
InfluxDB中没有显示的创建表的语句,只能通过insert数据的房还是来建立新表。
其中 disk_free 就是表名,hostname 是索引(tag),value=xx 是记录值(field),记录值可以有多个,系统自带追加时间戳。
> insert disk_free,hostname=server01 value=442221834240i
> select * from disk_free
name: disk_free
time hostname value
---- -------- -----
server01
或者添加数据时,自己写入时间戳(写入相同时间戳、相同tags,对原有数据进行update操作)
> insert disk_free,hostname=server01 value=442221834240i
> select * from disk_free
name: disk_free
time hostname value
---- -------- -----
server01
server01
删除表
> drop measurement disk_free
数据保存策略(Retention Policies)
InfluxDB 是没有提供直接删除数据记录的方法,但是提供数据保存策略,主要用于指定数据保留时间,超过指定时间,就删除这部分数据。
查看当前数据库Retention Policies
name:名称,此示例名称为 default。
duration:持续时间,0代表无限制。
shardGroupDuration:shardGroup的存储时间,shardGroup是InfluxDB的一个基本储存结构,应该大于这个时间的数据在查询效率上应该有所降低。
replicaN:全称是replication,副本个数。
default:是否是默认策略。
> show retention policies on testdb
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s true
创建新的Retention Policies
rp_name:策略名。
db_name:具体的数据库名。
3w:保存3周,3周之前的数据将被删除,influxdb 具备各种事件参数,持续时间必须至少为1小时;比如:h(小时)、d(天)、w(星期)。
replication 1:副本个数,一般为1即可。
default:设置为默认策略。
create retention policy "rp_name" on "db_name" duration 3w replication default
修改Retention Policies
alter retention policy "rp_name" on "db_name" duration 30d default 删除Retention Policies
drop retention policy "rp_name" on "db_name"
连续查询(Continuous Queries)
InfluxDB 的连续查询是在数据库中自动定时启动的一组语句,语句中必须包含 select 关键字 和 group by time() 关键字。
InfluxDB 会将查询结果放在指定的数据表中。
目的:使用连续查询是最优的降低采样率的方式,连续查询和存储策略搭配使用将会大大降低 InfluxDB 的系统占用量。而且使用连续查询后,数据会存放到指定的数据表中,这样就为以后统计不同精度的数据提供了方便。
新建连续查询
CREATE CONTINUOUS QUERY <cq_name> ON <database_name>
[RESAMPLE [EVERY <interval>] [FOR <interval>]]
BEGIN SELECT <function>(<stuff>)[,<function>(<stuff>)] INTO <different_measurement>
FROM <current_measurement> [WHERE <stuff>] GROUP BY time(<interval>)[,<stuff>]
END
样例
CREATE CONTINUOUS QUERY wj_30m ON testdb BEGIN SELECT mean(connected_clients), MEDIAN(connected_clients), MAX(connected_clients), MIN(connected_clients) INTO redis_clients_30m FROM redis_clients GROUP BY ip,port,time(30m) END
在 testdb 库中新建了一个名为 wj_30m 的连续查询,每三十分钟取一个 connected_clients 字段的平均值、中位值、最大值、最小值 redis_clients_30m 表中。使用的数据保留策略都是default。
不同 database 样例:
CREATE CONTINUOUS QUERY wj_30m ON testdb_30 BEGIN SELECT mean(connected_clients), MEDIAN(connected_clients), MAX(connected_clients), MIN(connected_clients) INTO testdb_30.autogen.redis_clients_30m FROM testdb.autogen.redis_clients GROUP BY ip,port,time(30m) END
显示所有已存在的连续查询
show continuous queries 删除Continuous Queries
drop continuous query <cq_name> on <database_name>
InfluxDB的安装和简介的更多相关文章
- InfluxDB学习之InfluxDB的安装和简介
最近用到了 InfluxDB,在此记录下学习过程,同时也希望能够帮助到其他学习的同学. 本文主要介绍InfluxDB的功能特点以及influxDB的安装过程.更多InfluxDB详细教程请看:Infl ...
- 第二百九十一节,RabbitMQ多设备消息队列-安装与简介
RabbitMQ多设备消息队列-安装与简介 RabbitMQ简介 解释RabbitMQ,就不得不提到AMQP(Advanced Message Queuing Protocol)协议. AMQP协议是 ...
- (转)阿里 RocketMQ 安装与简介
原文:阿里 RocketMQ 安装与简介 一.简介 官方简介: l RocketMQ是一款分布式.队列模型的消息中间件,具有以下特点: l 能够保证严格的消息顺序 l 提供丰富的消息拉取模式 l ...
- [Go] 时序数据库influxdb的安装
日志类的数据时候存储在时序数据库中,下面就是时序数据库influxdb的安装 curl -sL https://repos.influxdata.com/influxdb.key | apt-key ...
- 尚硅谷Docker---docker安装及简介
尚硅谷Docker---docker安装及简介 一.总结 一句话总结: docker就相当于是一个极微型的linux系统,独立 1.使用Docker的步骤? 1).安装Docker 2).去Docke ...
- 1.Cobaltstrike 安装与简介
1.Cobaltstrike 安装与简介 一.简介 Cobalt Strike是一款美国Red Team开发的渗透测试神器,常被业界人内称为CS.自去年起, Cobaltstrike升级到3.0版本, ...
- InfluxDB安装和简介
InfluxDB是一个当下比较流行的时序数据库,InfluxDB使用 Go 语言编写,无需外部依赖,安装配置非常方便,适合构建大型分布式系统的监控系统. 一.InfluxDB 简介 InfluxDB ...
- Spark学习(一) -- Spark安装及简介
标签(空格分隔): Spark 学习中的知识点:函数式编程.泛型编程.面向对象.并行编程. 任何工具的产生都会涉及这几个问题: 现实问题是什么? 理论模型的提出. 工程实现. 思考: 数据规模达到一台 ...
- 阿里 RocketMQ 安装与简介
一.简介 官方简介: l RocketMQ是一款分布式.队列模型的消息中间件,具有以下特点: l 能够保证严格的消息顺序 l 提供丰富的消息拉取模式 l 高效的订阅者水平扩展能力 l 实时的 ...
随机推荐
- Java获取properties配置文件信息
调用方法:String url = PropertiesUtil.getProperty("url"); public class PropertiesUtil { public ...
- 暑假集训test-8-29
今天瓜成一坨了. 瓜的说不出话来. 直接退役算了我. T1 傻逼题,但是我傻逼地敲了一个线段树合并,然后把空间炸了,只剩20分, 直接dfs维护子树大小,子树中最大最小值即可统计答案. //Achen ...
- NX二次开发-创建直线(起点-向量方向-长度)UF_CURVE_create_line
NX9+VS2012 #include <uf.h> #include <uf_curve.h> #include <uf_csys.h> #include < ...
- Core Text 入门
本文所涉及的代码你可以在这里下载到 https://github.com/kejinlu/CTTest,包含两个项目,一个Mac的NSTextView的测试项目,一个iOS的Core Text的测试项 ...
- 秦曾昌人工智能课程---5、KNN和朴素贝叶斯
秦曾昌人工智能课程---5.KNN和朴素贝叶斯 一.总结 一句话总结: 拟合和概率:构建机器学习模型,一般有拟合和概率两种方式 轻学无用:一定要保证学有所用,要深入学习,比如之前做的安卓,一定要学通, ...
- [转]如何升级gcc版本
首先需要准备需要材料:gcc4.4.2版需要安装gmp4.2.0+和mpfr2.3.0+,到GMP的网站(http://gmplib.org/)上下载gmp-4.3.1.tar.gz 和mprf的网站 ...
- git相关操作。
之前只会用图形端的GIT中,命令行的比较陌生,整理下,供自己以后参考 关键的名词: 工作区:工作区 Index / Stage:暂存区 仓库:仓库区(或本地仓库) 远程控制:远程仓库 到项目目录下gi ...
- HDU1285-确定比赛名次-拓扑排序板子题
有N个比赛队(1<=N<=500),编号依次为1,2,3,....,N进行比赛,比赛结束后,裁判委员会要将所有参赛队伍从前往后依次排名,但现在裁判委员会不能直接获得每个队的比赛成绩,只知道 ...
- centos 根目录扩容
添加一块磁盘 参考上一篇博文VMware Workstation 添加磁盘 挂载目录(centos) 查看当前磁盘挂载情况 [root@node1 ~]# fdisk -l Disk /dev/sda ...
- Xtrabackup 热备
Xtrabackup介绍Xtrabackup是由percona开源的免费数据库热备份软件,它能对InnoDB数据库和XtraDB存储引擎的数据库非阻塞地备份(对于MyISAM的备份同样需要加表锁):m ...