唱吧基于 MaxCompute 的大数据之路
使用 MaxCompute之前,唱吧使用自建体系来存储处理各端收集来的日志数据,包括请求访问记录、埋点数据、服务器业务数据等。初期这套基于开源组件的体系有力支撑了数据统计、业务报表、风控等业务需求。但随着每天处理数据量的增长,积累的历史数据越来越多,来自其他部门同事的需求越来越复杂,自建体系逐渐暴露出了能力上的短板。同时期,唱吧开始尝试阿里云提供的ECS、OSS等云服务,大数据部门也开始使用 MaxCompute来弥补自建体系的不足。
在内部ELK实现的基础上,从自建机房向MaxCompute进行数据同步工作是比较简单的,实践中我们主要采取两种方式:一是利用阿里云提供的datahub组件,直接对接logstash;二是把待同步数据落地到文件,然后使用tunnel命令行工具上传至MaxCompute的对应表中。
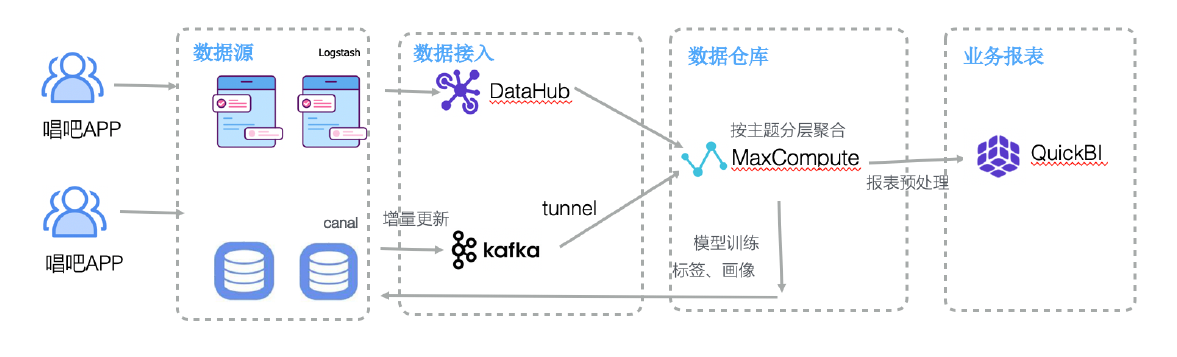
数据进入MaxCompute后,我们按照数据的主题和使用场景构造了三层结构:原始数据层ODS、中间数据层MDS、报表数据层DM。ODS层中保存直接同步的数据,在此基础上加工整理到的原始表,例如增量同步的原mysql表,经过风控清洗的访问日志表等。MDS层存放原始层数据聚合、抽象加工过的结果,这一层的数据表更可读、读取计算时更经济,一般情况下要求其他部门的同事使用这一层的数据。DM层是处理理的最终结果,支持QuickBI直接读取进行报表展示,同时也支持同步回自建机房,供其他业务使用。
目前除了某些对实时要求比较高的场景还使用自建体系外,MaxCompute承担了唱吧全部的离线计算工作。每天有近千个任务定时运行,处理TB级别的数据,生成上百个数据报表在QuickBI进行展示。可视化的管理理界面和基于SQL的计算方式大大降低了使用门槛,提升了效率。除此之外,推荐和风控业务也都利用了MaxCompute的计算能力,实现了对需求的快速跟进和迭代。MaxCompute云服务和自建体系的结合,让我们能充分满足业务需求,在效率成本和灵活性上取得了很好的平衡。
下一步,对于MaxCompute我们有几个方向上的计划:
一是利用机器学习能力,进一步挖掘数据的价值。
二是对那些历史比较久的冷数据,利用MaxCompute的外表功能,定期转移至OSS等服务中,保证可读的基础上降低成本。
三是评估阿里云的实时计算服务,作为自建体系的补充。
本文作者:马星显 (唱吧大数据负责人)
本文为云栖社区原创内容,未经允许不得转载。
唱吧基于 MaxCompute 的大数据之路的更多相关文章
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- 高速基于echarts的大数据可视化
[Author]: kwu 高速基于echarts的大数据可视化,echarts纯粹的js实现的图表工具.高速开发的过程例如以下: 1.引入echarts的依赖js库 <script type= ...
- 软工之词频统计器及基于sketch在大数据下的词频统计设计
目录 摘要 算法关键 红黑树 稳定排序 代码框架 .h文件: .cpp文件 频率统计器的实现 接口设计与实现 接口设计 核心功能词频统计器流程 效果 单元测试 性能分析 性能分析图 问题发现 解决方案 ...
- 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
这个很简单,在集群机器里,选择就是了,本来自带就有Impala的. 扩展博客 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
- 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
不多说,直接上干货! Impala和Hive的关系(详解) 扩展博客 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解) 参考 horton ...
- 海胜专访--MaxCompute 与大数据查询引擎的技术和故事
摘要:在2019大数据技术公开课第一季<技术人生专访>中,阿里巴巴云计算平台高级技术专家苑海胜为大家分享了<MaxCompute 与大数据查询引擎的技术和故事>,主要介绍了Ma ...
- 基于Hadoop的大数据平台实施记——整体架构设计[转]
http://blog.csdn.net/jacktan/article/details/9200979 大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底 ...
- 基于Hadoop的大数据平台实施记——整体架构设计
大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底是否适用于您的组织,至少在互联网上已经被吹嘘成无所不能的超级战舰.好像一夜之间我们就从互联网时代跳跃进了大 ...
- 胖子哥的大数据之路(10)- 基于Hive构建数据仓库实例
一.引言 基于Hive+Hadoop模式构建数据仓库,是大数据时代的一个不错的选择,本文以郑商所每日交易行情数据为案例,探讨数据Hive数据导入的操作实例. 二.源数据-每日行情数据 三.建表脚本 C ...
随机推荐
- TKmybatis的框架介绍和原理分析及Mybatis新特性演示
tkmybatis是在mybatis框架的基础上提供了很多工具,让开发更加高效,下面来看看这个框架的基本使用,后面会对相关源码进行分析,感兴趣的同学可以看一下,挺不错的一个工具 实现对员工表的增删改查 ...
- 使用CEfSharp之旅(4)cefsharp 调用F12
原文:使用CEfSharp之旅(4)cefsharp 调用F12 版权声明:本文为博主原创文章,未经博主允许不得转载.可点击关注博主 ,不明白的进群191065815 我的群里问 https://bl ...
- spark jdk8 单词统计示例
在github上有spark-java8 实例地址: https://github.com/ypriverol/spark-java8 https://github.com/ihr/java8-spa ...
- 2019-8-31-dotnet-特性-DynamicallyInvokable-是用来做什么的
title author date CreateTime categories dotnet 特性 DynamicallyInvokable 是用来做什么的 lindexi 2019-08-31 16 ...
- Matlab AlexNet 识别花
1. 首先,你要又并行计算的工具箱,在插件选项里面找到,安装即可 2. 下载训练的数据集,采用matlab演示的材料即可 https://matlabacademy-content.mathworks ...
- HNOI2018思记
4-13 顺顺利利到了湖南.晚上认真研读cf毒瘤题题解,未果. 发现这里含铁丰富的高温多雨式红土地.以及窗户特别深,总有一圈小阳台的房子,门楣深邃如瞳. 看了一波miaom的ZJOI游记,思考了一下解 ...
- Java怎样对一个属性设置set或get方法的快捷键
具体步骤如下: 首页,在testApp.java 类中定义属性,例如:public Sting name; 其次,Alt+Shift+S, 选择Generate Getters and Setter ...
- xml中的<if>和截取字符串
<#if (envPollute=='1')>√</#if><#if (envPollute=='0')>√</#if>${as_title?subst ...
- log4j的使用及与mybatis应用
log4j 输出级别 fatal(致命信息)>error(错误信息)>warn(警告信息)>info(普通信息)>debug(调试信息)>all(所有) log4j.pr ...
- PKU--3211 Washing Clothes(01背包)
题目http://poj.org/problem?id=3211 分析:两个人洗衣服,可以同时洗,但是只能同时洗一种颜色. 要时间最短,那么每一种颜色的清洗时间最短. 转换为,两个人洗同一种颜色的衣服 ...