schema文件及XML文件的DOM和Sax解析
schema文件
<?xml version="1.0" encoding="UTF-8"?>
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/book"
xmlns:book="http://www.example.org/book"
elementFormDefault="qualified">
<!--创建books根元素-->
<element name="books">
<complexType>
<sequence>
<element name="book" maxOccurs="unbounded" minOccurs="1">
<complexType>
<sequence>
<element name="name" type="string"/>
<element name="author" type="string" maxOccurs="2"/>
<element name="price" type="decimal"/>
<element name="date" type="date"/>
<element name="pageNumbers" type="int" minOccurs="0" maxOccurs="2"/>
</sequence>
<attribute name="id" type="ID" use="required"/>
<attribute name="name" type="string"/>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
<?xml version="1.0" encoding="UTF-8"?>
<books xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.example.org/book"
xmlns:book="http://www.example.org/book"
xsi:schemaLocation="http://www.example.org/book book.xsd">
<book:book id="CSN001" name="图书1">
<book:name></book:name>
<book:author>图书作者1</book:author>
<book:author>图书作者</book:author>
<book:price>66.6</book:price>
<book:date>1966-10-22</book:date>
<book:pageNumbers>1</book:pageNumbers>
</book:book>
</books>
xml解析
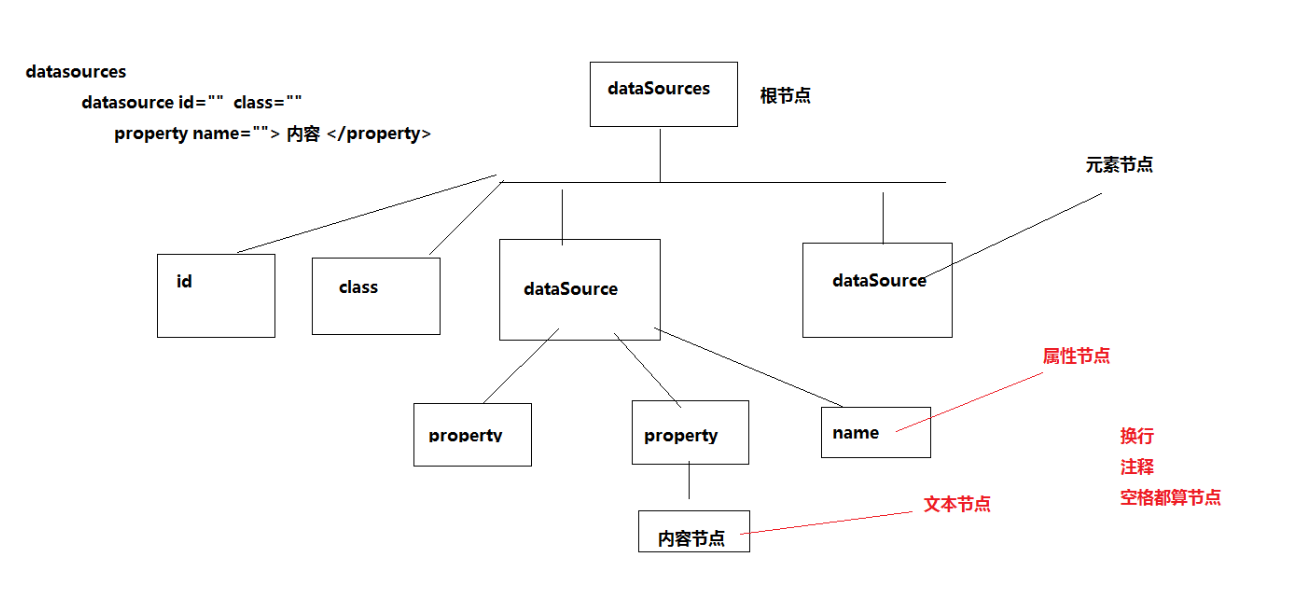
<?xml version="1.0" encoding="UTF-8"?>
<dataSources>
<!-- 定义MySQL数据源 -->
<dataSource id="mysql" class="xxx.xxx.xx">
<property name="driverClassName">com.mysql.jdbc.Driver</property>
<property name="url">jdbc:mysql://127.0.0.1:3306/userdb</property>
<property name="username">root</property>
<property name="password">123</property>
</dataSource> <!-- 定义Oracle的数据源 -->
<dataSource id="oracle" class="xxx.xxx.xx">
<property name="driverClassName">com.oracle.jdbc.OracleDriver</property>
<property name="url">jdbc:oracle:thin:@127.0.0.1:1521:ORCL</property>
<property name="username">scott</property>
<property name="password">tiger</property>
</dataSource>
</dataSources>
package com.demo.dom; import java.io.InputStream; import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory; import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList; /**
* 使用DOM解析XML文件
*
* 把XML文件转换后为流程在把流在内存中构建一个DOM模型,使用对应API操作DOM树
*
* @author Administrator
*
*/
public class DOMParser { public static void main(String[] args) {
long start = System.nanoTime();
try {
// 创建一个文档构建工厂对象
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
// 通过工厂对象创建一个文档构建对象
DocumentBuilder documentBuilder = builderFactory.newDocumentBuilder();
// 吧XML转换为输入流操作
InputStream inputStream = DOMParser.class.getClassLoader().getResourceAsStream("datasource.xml");
// 通过文档构建对象构建一个文档对象
Document document = documentBuilder.parse(inputStream);
// 获取文档中的根元素
Element rootElement = document.getDocumentElement();
// 获取根元素先所有dataSource子节点
NodeList nodeList = rootElement.getChildNodes(); for (int i = 0; i < nodeList.getLength(); i++) {
/**
* 3: 换行节点->文本节点 8: 注释节点 1: 元素节点
*/
Node node = nodeList.item(i);
// 判断元素节点才操作
if (Node.ELEMENT_NODE == node.getNodeType()) {
// 读取属性节点的值
String clazz = node.getAttributes().getNamedItem("class").getNodeValue();
String id = node.getAttributes().getNamedItem("id").getNodeValue();
System.out.println("class="+clazz);
System.out.println("id="+id);
// 获取元子节点
NodeList datasourceNodes = node.getChildNodes();
for (int j = 0; j < datasourceNodes.getLength(); j++) {
Node dataSourceNode = datasourceNodes.item(j); if (Node.ELEMENT_NODE == dataSourceNode.getNodeType()) {
// 获取属性的值
String nameValue = dataSourceNode.getAttributes().getNamedItem("name").getNodeValue();
String contentValue = dataSourceNode.getTextContent();
System.out.println(nameValue+"="+contentValue);
}
}
}
} } catch (Exception e) {
e.printStackTrace();
} long end = System.nanoTime();
System.out.println(end - start);
} }
package com.demo.sax; import java.io.InputStream; import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory; import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler; import com.demo.dom.DOMParser; /**
* Sax解析
*
* @author Administrator
*
*/
public class SaxParserDemo {
public static void main(String[] args) {
long start = System.nanoTime();
// 创建一个Sax工厂对象->工厂设计
SAXParserFactory factory = SAXParserFactory.newInstance();
try {
// 创建解析器
SAXParser saxParser = factory.newSAXParser();
// 吧XML转换为输入流操作
InputStream inputStream = DOMParser.class.getClassLoader().getResourceAsStream("datasource.xml");
saxParser.parse(inputStream, new DefaultHandler() {
//解析开始标题文档
public void startDocument() throws SAXException {
System.out.println("<?xml version= 1.0 encoding= utf-8 ?>");
}
//解析节点
@Override
public void startElement(String uri, String localName,
String qName, Attributes attributes) throws SAXException {
System.out.print("<"+qName+" ");
for (int i = 0; i < attributes.getLength(); i++) {
System.out.print(attributes.getQName(i)+"="+attributes.getValue(i)+" ");
}
System.out.print(">");
} @Override
//解析结束
public void endElement(String uri, String localName, String qName)
throws SAXException {
System.out.print("</"+qName+">");
} @Override
//解析内容
public void characters(char[] ch, int start, int length)
throws SAXException {
String string = new String(ch, start, length);
System.out.print(string);
} });
} catch (Exception e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println(end - start);
} /**
* 定义默认处理的内部类
* @author Administrator
*
*/
private static class XMLHanlder extends DefaultHandler { @Override
public void startDocument() throws SAXException {
System.out.println("解析开始");
} @Override
public void startElement(String uri, String localName, String qName, Attributes attributes)
throws SAXException {
System.out.println("开始解析元素"+qName);
System.out.println(attributes.getValue("id"));
System.out.println(attributes.getValue("class"));
} @Override
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.println("解析结束");
} @Override
public void characters(char[] ch, int start, int length) throws SAXException {
System.out.println("解析内容");
System.out.println(new String(ch,start, length));
} }
}
schema文件及XML文件的DOM和Sax解析的更多相关文章
- XML - 十分钟了解XML结构以及DOM和SAX解析方式
引言 NOKIA 有句著名的广告语:"科技以人为本".不论什么技术都是为了满足人的生产生活须要而产生的.详细到小小的一个手机.里面蕴含的技术也是浩如烟海.是几千年来人类科技的结晶, ...
- JavaEE实战——XML文档DOM、SAX、STAX解析方式详解
原 JavaEE实战--XML文档DOM.SAX.STAX解析方式详解 2016年06月22日 23:10:35 李春春_ 阅读数:3445 标签: DOMSAXSTAXJAXPXML Pull 更多 ...
- LINQ to XML 从逗号分隔值 (CSV) 文件生成 XML 文件
参考:http://msdn.microsoft.com/zh-cn/library/bb387090.aspx 本示例演示如何使用 语言集成查询 (LINQ) 和 LINQ to XML 从逗号分隔 ...
- web端自动化——Python读取txt文件、csv文件、xml文件
1.读取txt文件 txt文件是我们经常操作的文件类型,Python提供了以下几种读取txt文件的方式. 1)read(): 读取整个文件. 2)readline(): 读取一行数据. 3)readl ...
- 关于跨域策略文件crossdomain.xml文件
下载flexpaper源码修改后做成swf阅读器,要加入待阅读的swf文件,可以在flex里调用js的方法来获取swf文件的路径的方法,在js只专注获取路径就行,等着flex来调用:但这里会遇到一个问 ...
- iOS开发中XML的DOM和SAX解析方法
一.介绍 dom是w3c指定的一套规范标准,核心是按树形结构处理数据,dom解析器读入xml文件并在内存中建立一个结构一模一样的“树”,这树各节点和xml各标记对应,通过操纵此“树”来处理xml中的文 ...
- Java SE之XML<二>XML DOM与SAX解析
[文档整理系列] Java SE之XML<二>XML DOM与SAX解析 XML编程:CRUD(Create Read Update Delete) XML解析的两种常见方式: DOM(D ...
- java基础71 XML解析中的【DOM和SAX解析工具】相关知识点(网页知识)
本文知识点(目录):本文下面的“实例及附录”全是DOM解析的相关内容 1.xml解析的含义 2.XML的解析方式 3.xml的解析工具 4.XML的解析原理 5.实例 6 ...
- Java文件操作①——XML文件的读取
一.邂逅XML 文件种类是丰富多彩的,XML作为众多文件类型的一种,经常被用于数据存储和传输.所以XML在现今应用程序中是非常流行的.本文主要讲Java解析和生成XML.用于不同平台.不同设备间的数据 ...
随机推荐
- ATL and MFC String Conversion Macros
ATL 7.0介绍了一些新的转换类和宏,为现有的宏提供了重要的改进.新的字符串转换类和名称宏的形式是:C 源类型 2[C] 目标类型[EX]其中:•源类型和目标类型描述如下表.• [C]是目标类型必须 ...
- layui动态修改select的选中项
layui动态修改select的选中项:(在layUI下给select设置默认选项) 例: $("select[name='result']").val(11); //重新渲染表单 ...
- crm需求分析步骤
# CRM开发顺序# 需求分析# 思维导图# 业务场景分析#-------------------------------------## 原型图(Demo)# Axure#------------- ...
- baidu练习/html/css
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- WoSign全球可信网站安全认证签章安装指南
您购买了WoSign SSL证书后,将免费获得一个能直观地显示贵网站的认证信息的可信网站安全认证标识,能大大增强用户的在线信任,促成更多在线交易.所以,建议您在安装成功SSL证书后马上在网站的首页和其 ...
- nodejs+express搭建服务器
1.Express 是一个简洁而灵活的 node.js Web应用框架, 提供了一系列强大特性帮助你创建各种 Web 应用,和丰富的 HTTP 工具. 使用 Express 可以快速地搭建一个完整功能 ...
- [luogu3195 HNOI2008] 玩具装箱TOY (斜率优化dp)
题目描述 P教授要去看奥运,但是他舍不下他的玩具,于是他决定把所有的玩具运到北京.他使用自己的压缩器进行压缩,其可以将任意物品变成一堆,再放到一种特殊的一维容器中.P教授有编号为1...N的N件玩具, ...
- Python 绘图与可视化 matplotlib(下)
详细的参考链接:更详细的:https://www.cnblogs.com/zhizhan/p/5615947.html 图像.子图.坐标轴以及记号 Matplotlib中图像的意思是打开的整个画图窗口 ...
- 【codeforces 505D】Mr. Kitayuta's Technology
[题目链接]:http://codeforces.com/problemset/problem/505/D [题意] 让你构造一张有向图; n个点; 以及所要求的m对联通关系(xi,yi) 即要求这张 ...
- Windows系统环境变量、JAVA环境变量配置以及JVM加载过程
一:用户变量和系统变量的区别 右击我的电脑.属性.高级系统设置.环境变量. 对话框的上面为Administrator的用户变量,对话框的下面为系统变量.我们所说的环境变量一般指系统环境变量,对所有用户 ...