推荐一个同步Mysql数据到Elasticsearch的工具
把Mysql的数据同步到Elasticsearch是个很常见的需求,但在Github里找到的同步工具用起来或多或少都有些别扭。
例如:某记录内容为"aaa|bbb|ccc",将其按|分割成数组同步到es,这样的简单任务都难以实现,再加上配置繁琐,文档语焉不详...
所以我写了个同步工具MysqlsMom:力求用最简单的配置完成复杂的同步任务。目前除了我所在的部门,也有越来越多的互联网公司在生产环境中使用该工具了。
欢迎各位大佬进行试用并提出意见,任何建议、鼓励、批评都受到欢迎。
github: https://github.com/m358807551/mysqlsmom
简介:同步 Mysql 数据到 elasticsearch 的工具;
QQ、微信:358807551
特点
- 纯 Python 编写;
- 支持基于 sql 语句的全量同步,基于 binlog 的增量同步,基于更新字段的增量同步三种同步方式;
- 全量更新只占用少量内存;支持通过sql语句同步数据;
- 增量更新自动断点续传;
- 取自 Mysql 的数据可经过一系列自定义函数的处理后再同步至 Elasticsearch;
- 能用非常简单的配置完成复杂的同步任务;
环境
- python2.7;
- 增量同步需开启 redis;
- 分析 binlog 的增量同步需要 Mysql 开启 binlog(binlog-format=row);
快速开始
全量同步MySql数据到es
clone 项目到本地;
安装依赖;
cd mysqlsmom
pip install -r requirements.txt默认支持 elasticsearch-2.4版本,支持其它版本请运行(将5.4换成需要的elasticsearch版本)
pip install --upgrade elasticsearch==5.4编辑 ./config/example_init.py,按注释提示修改配置;
# coding=utf-8 STREAM = "INIT"修改数据库连接
CONNECTION = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'passwd': ''
}修改elasticsearch节点
NODES = [{"host": "127.0.0.1", "port": 9200}] TASKS = [
{
"stream": {
"database": "test_db", # 在此数据库执行sql语句
"sql": "select * from person" # 将该sql语句选中的数据同步到 elasticsearch
},
"jobs": [
{
"actions": ["insert", "update"],
"pipeline": [
{"set_id": {"field": "id"}} # 默认设置 id字段的值 为elasticsearch中的文档id
],
"dest": {
"es": {
"action": "upsert",
"index": "test_index", # 设置 index
"type": "test", # 设置 type
"nodes": NODES
}
}
}
]
}
]运行
cd mysqlsmom
python mysqlsmom.py ./config/example_init.py等待同步完成即可;
分析 binlog 的增量同步
确保要增量同步的MySql数据库开启binlog,且开启redis(为了存储最后一次读到的binlog文件名及读到的位置。未来可能支持本地文件存储该信息。)
下载项目到本地,且安装好依赖后,编辑 ./config/example_init.py,按注释提示修改配置;
# coding=utf-8 STREAM = "BINLOG"
SERVER_ID = 99 # 确保每个用于binlog同步的配置文件的SERVER_ID不同;
SLAVE_UUID = name配置开启binlog权限的MySql连接
BINLOG_CONNECTION = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'passwd': ''
}配置es节点
NODES = [{"host": "127.0.0.1", "port": 9200}] TASKS = [
{
"stream": {
"database": "test_db", # [table]所在的数据库
"table": "person" # 监控该表的binlog
},
"jobs": [
{
"actions": ["insert", "update"],
"pipeline": [
{"only_fields": {"fields": ["id", "name", "age"]}}, # 只同步这些字段到es,注释掉该行则同步全部字段的值到es
{"set_id": {"field": "id"}} # 设置es中文档_id的值取自 id(或根据需要更改)字段
],
"dest": {
"es": {
"action": "upsert",
"index": "test_index", # 设置 index
"type": "test", # 设置 type
"nodes": NODES
}
}
}
]
}
]运行
cd mysqlsmom
python mysqlsmom.py ./config/example_binlog.py该进程会一直运行,实时同步新增和更改后的数据到elasticsearch;
注意:第一次运行该进程时不会同步MySql中已存在的数据,从第二次运行开始,将接着上次同步停止时的位置继续同步;
同步旧数据请看全量同步MySql数据到es;
基于更新时间的增量同步
若 Mysql 表中有类似 update_time 的时间字段,且在每次插入、更新数据后将该字段的值设置为操作时间,则可在不用开启 binlog 的情况下进行增量同步。
下载项目到本地,且安装好依赖后,编辑 ./config/example_cron.py,按注释提示修改配置;
# coding=utf-8 STREAM = "CRON"修改数据库连接
CONNECTION = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'passwd': ''
}redis存储上次同步时间等信息
REDIS = {
"host": "127.0.0.1",
"port": 6379,
"db": 0,
"password": "password", # 不需要密码则注释或删掉该行
}一次同步 BULK_SIZE 条数据到elasticsearch,不设置该配置项默认为1
BULK_SIZE = 1修改elasticsearch节点
NODES = [{"host": "127.0.0.1", "port": 9200}] TASKS = [
{
"stream": {
"database": "test_db", # 在此数据库执行sql语句
"sql": "select id, name from person where update_time >= ?", # 将该sql语句选中的数据同步到 elasticsearch
"seconds": 10, # 每隔 seconds 秒同步一次,
"init_time": "2018-08-15 18:05:47" # 只有第一次同步会加载
},
"jobs": [
{
"pipeline": [
{"set_id": {"field": "id"}} # 默认设置 id字段的值 为 es 中的文档id
],
"dest": {
"es": {
"action": "upsert",
"index": "test_index", # 设置 index
"type": "test" # 设置 type
}
}
}
]
}
]运行
cd mysqlsmom
python mysqlsmom.py ./config/example_cron.py
组织架构
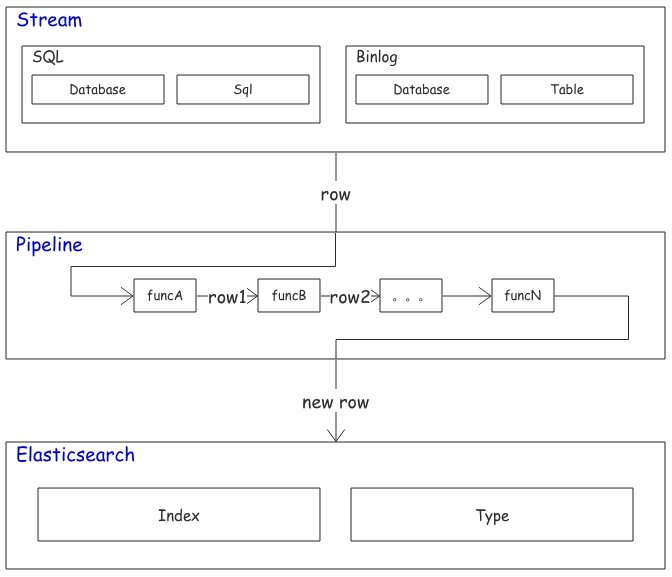
Mysqlsmom 使用实战
Mysqlsmom 的灵活性依赖于:
- 在 row_handlers.py 中添加自定义函数对取自Mysql的数据进行二次加工。
- 在 row_filters.py 中添加自定义函数决定是否要同步某一条数据。
- 在 config/ 目录下的任意配置文件应用上面的函数。
如果不了解 Python 也没关系,上述两个文件中自带的函数足以应付大多数种情况,遇到特殊的同步需求可以在 Github 发起 issue 或通过微信、QQ联系作者。
同步多张表
在一个配置文件中即可完成:
...
TASKS = [
# 同步表1
{
"stream": {
"database": "数据库名1",
"table": "表名1"
},
"jobs": [...]
}
# 同步表2
{
"stream": {
"database": "数据库名2",
"table": "表名2"
},
"jobs": [...]
}
]一个 Mysql Connection 对应一个配置文件。
一张表同步到多个索引
分为两种情况。
一种是把相同的数据同步到不同的索引,配置如下:
...
TASKS = [
{
"stream": {...},
"jobs": [
{
"actions": [...],
"pipeline": [...],
"dest": [
# 同步到索引1
{
"es": {"action": "upsert", "index": "索引1", "type": "类型1", "nodes": NODES},
},
# 同步到索引2
{
"es": {"action": "upsert", "index": "索引2", "type": "类型2", "nodes": NODES},
}
]
}
]
},
...
]另一种是把同一个表产生的数据经过不同的 pipeline 同步到不同的索引:
...
TASKS = [
{
"stream": {...},
"jobs": [
{
"actions": {...},
"pipeline": [...], # 对数据经过一系列处理
"dest": {"es": {"index": "索引1", ...}} # 同步到索引1
},
{
"actions": {...},
"pipeline": [...], # 与上面的pipeline不同
"dest": {"es": {"index": "索引2", ...}} # 同步到索引2
}
]
}
]- TASKS 中的每一项对应一张要同步的表。
- jobs 中的每一项对应对一条记录的一种处理方式。
- dest 中的每一项对应一个es索引类型。
只同步某些字段
对每条来自 Mysql 的 记录的处理都在 pipeline 中进行处理。
"pipeline": [
{"only_fields": {"fields": ["id", "name"]}}, # 只同步 id 和 name字段
{"set_id": {"field": "id"}} # 然后设置 id 字段为es中文档的_id
]字段重命名
对于 Mysql 中的字段名和 elasticsearch 中的域名不一致的情况:
"pipeline": [
# 将name重命名为name1,age 重命名为age1
{"replace_fields": {"name": ["name1"], "age": ["age1"]}},
{"set_id": {"field": "id"}}
]pipeline 会依次执行处理函数,上面的例子等价于:
"pipeline": [
# 先重命名 name 为 name1
{"replace_fields": {"name": ["name1"]}},
# 再重命名 age 为 age1
{"replace_fields": {"age": ["age1"]}},
{"set_id": {"field": "id"}}
]还有一种特殊情形,es 中两个字段存相同的数据,但是分词方式不同。
例如 name_default 的分析器为 default,name_raw 设置为不分词,需要将 name 的值同时同步到这两个域:
"pipeline": [
{"replace_fields": {"name": ["name_default", "name_raw"]}},
{"set_id": {"field": "id"}}
]当然上述问题有一个更好的解决方案,在 es 的 mappings 中配置 name 字段的 fields 属性即可,这超出了本文档的内容。
切分字符串为数组
有时 Mysql 存储字符串类似:"aaa|bbb|ccc",希望转化成数组: ["aaa", "bbb", "ccc"] 再进行同步
"pipeline": [
# tags 存储类似"aaa|bbb|ccc"的字符串,将 tags 字段的值按符号 `|` 切分成数组
{"split": {"field": "tags", "flag": "|"}},
{"set_id": {"field": "id"}}
] 同步删除文档
只有 binlog 同步 能实现删除 elasticsearch 中的文档,配置如下:
TASKS = [
{
"stream": {
"database": "test_db",
"table": "person"
},
"jobs": [
# 插入、更新
{
"actions": ["insert", "update"],
"pipeline": [
{"set_id": {"field": "id"}} # 设置 id 字段的值为 es 中文档 _id
],
"dest": {
"es": {
"action": "upsert",
...
}
}
},
# 重点在这里,配置删除
{
"actions": ["delete"], # 当读取到 binlog 中该表的删除操作时
"pipeline": [{"set_id": {"field": "id"}}], # 要删除的文档 _id
"dest": {
"es": {
"action": "delete", # 在 es 中执行删除操作
... # 与上面的 index 和 type 相同
}
}
}
]
},
...
]更多示例正在更新
常见问题
为什么我的增量同步不及时?
连接本地数据库增量同步不及时
该情况暂未收到过反馈,如能复现请联系作者。
连接线上数据库发现增量同步不及时
2.1 推荐使用内网IP连接数据库。连接线上数据库(如开启在阿里、腾讯服务器上的Mysql)时,推荐使用内网IP地址,因为外网IP会受到带宽等限制导致获取binlog数据速度受限,最终可能造成同步延时。
待改进
- 据部分用户反馈,全量同步百万级以上的数据性能不佳。
未完待续
文档近期会较频繁更新,任何问题、建议都收到欢迎,请在issues留言,会在24小时内回复;或联系QQ、微信: 358807551;
原文地址:https://elasticsearch.cn/article/756
推荐一个同步Mysql数据到Elasticsearch的工具的更多相关文章
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
- Elasticsearch--Logstash定时同步MySQL数据到Elasticsearch
新地址体验:http://www.zhouhong.icu/post/139 一.Logstash介绍 Logstash是elastic技术栈中的一个技术.它是一个数据采集引擎,可以从数据库采集数据到 ...
- 实战ELK(6)使用logstash同步mysql数据到ElasticSearch
一.准备 1.mysql 我这里准备了个数据库mysqlEs,表User 结构如下 添加几条记录 2.创建elasticsearch索引 curl -XPUT 'localhost:9200/user ...
- 同步mysql数据到ElasticSearch的最佳实践
Elasticsearch是一个实时的分布式搜索和分析引擎.它可以帮助你用前所未有的速度去处理大规模数据.ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全 ...
- Centos8 部署 ElasticSearch 集群并搭建 ELK,基于Logstash同步MySQL数据到ElasticSearch
Centos8安装Docker 1.更新一下yum [root@VM-24-9-centos ~]# yum -y update 2.安装containerd.io # centos8默认使用podm ...
- 【记录】ELK之logstash同步mysql数据到Elasticsearch ,配置文件详解
本文出处:https://my.oschina.net/xiaowangqiongyou/blog/1812708#comments 截取部分内容以便学习 input { jdbc { # mysql ...
- Logstash 安装及简单实用(同步MySql数据到Elasticsearch)(Windows)
Logstash是一款轻量级的日志搜集处理框架,可以方便的把分散的.多样化的日志搜集起来,并进行自定义的处理,然后传输到指定的位置,比如某个服务器或者文件 Windows环境: 1.下载logstas ...
- logstash6.5.4同步mysql数据到elasticsearch 6.4.1
下载logstash-6.5.4 ZIP解压和es 放到es根目录下 下载mysql jdbc的驱动 mysql-connector-java-8.0.12 放在任意目录下 以下方式采用动态模板,还有 ...
- Canal——增量同步MySQL数据到ElasticSearch
1.准备 1.1.组件 JDK:1.8版本及以上: ElasticSearch:6.x版本,目前貌似不支持7.x版本: Kibana:6.x版本: Canal.deployer:1 ...
随机推荐
- Rockchip平台TP驱动详解【转】
本文转载自:http://blog.csdn.net/encourage2011/article/details/51679332 本文描述在RK3126平台上添加一个新的TP驱动(gslx680驱动 ...
- hdu 2222(AC自动机模版题)
Keywords Search Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others ...
- Struts2 中 result type=”json” 的参数解释
转自:http://wangquanhpu.iteye.com/blog/1461750 1, ignoreHierarchy 参数:表示是否忽略等级,也就是继承关系,比如:TestAction 继承 ...
- leetcode数组相关
目录 4寻找两个有序数组的中位数 11盛最多水的容器,42接雨水 15三数之和,16最接近的三数之和,18四数之和 26/80删除排序数组中的重复项, 27移除元素 31下一个排列 53最大子序和 5 ...
- PCB LDI 实现周期自动更新 实现思路
一.基本思路整理如下: 二.封周期启动程序C#代码(部份代码) /// <summary> /// 单个生产型号 更新周期 /// </summary> /// <par ...
- Win10 计算机管理 打不开应急办法
最近Win10重置以后,计算机管理打不开了,经过一番尝试,通过以下命令在cmd下面可以直接打开 compmgmt 或者compmgmt.msc打开 在次特做一个记录,以备急用
- [Luogu2324]八数码难题
抱歉...我可能真的做搜索上瘾了... 还是IDA*,自己看看就好了... 注意一下搜索顺序 #include<cstdio> #include<queue> #include ...
- mybatis 传map参数
第一步在你的mapper写上: List<WeixinUserLocationList> findweixinUserLocations(@Param("params" ...
- [2月1号] 努比亚全机型ROM贴 最全最新NubiaUI5.0 ROOT 极速体验
前言 感谢在开发过程中mandfx和dgtl198312予以的帮助!本帖将整理所有Nubia手机的最新刷机包,还有少数机型未制作刷机包,需要的机油可以联系我制作recovery以及刷机包加群23722 ...
- 开源作品-PHP写的Redis管理工具(单文件绿色版)-SuRedisAdmin_PHP_1_0
前言:项目开发用到了Redis,但是在调试Redis数据的时候,没有一款通用的可视化管理工具.在网络找了一些,但是感觉功能上都不尽人意,于是决定抽出一点时间,开发一个用起来顺手的Redis管理工具.秉 ...