ip代理池的爬虫编写、验证和维护
打算法比赛有点累,比赛之余写点小项目来提升一下工程能力、顺便陶冶一下情操
本来是想买一个服务器写个博客或者是弄个什么翻墙的东西
最后刷知乎看到有一个很有意思的项目,就是维护一个「高可用低延迟的高匿IP代理池」
于是就想自己把这个项目写一次,其中有些更改,有些没有实现
(数据结构作业要写广义表,写项目时发现还没写 :)
原知乎链接:https://www.zhihu.com/question/47464143 (作者:resolvewang)
原项目github链接:https://github.com/SpiderClub/haipproxy
在此感谢原作者 resolvewang
本项目链接:https://github.com/TangliziGit/proxypool
项目早已在服务器上运行,这篇随笔就是未完待续吧
咕咕咕,鸽了
大体思路
- 用爬虫爬下网络上的免费代理ip
- 对爬取的代理ip进行验证,过滤掉一些不可用、低速的、有网页跳转的代理
- 编写调度器,对各个网站定时爬取、验证免费代理;并对数据库中以爬取的代理进行验证
- 写一个web api,提供数据库中已有的代理ip
大体框架
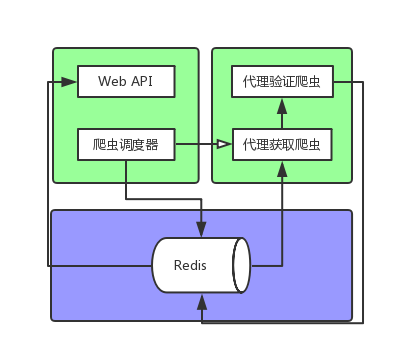
(我就只是想画个图而已 -_-)
项目第一阶段目录:
proxypool/
├── booter.py
├── dump.rdb
├── place.txt
├── proxypool
│ ├── __init__.py
│ ├── items.py
│ ├── logger.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── rules.py
│ ├── settings.py
│ ├── spiders
│ │ ├── base_spider.py
│ │ ├── common_spider.py
│ │ ├── __init__.py
│ │ └── __pycache__
│ ├── task_queue.py
│ ├── user_agent.py
│ └── validators
│ ├── baidu_validator.py
│ ├── base_validator.py
│ ├── __init__.py
│ ├── __pycache__
│ └── zhihu_validator.py
├── __pycache__
├── scheduler.py
├── scrapy.cfg
└── testip.py
7 directories, 24 files
// wc -l `find . -name "*.py"`
5 ./booter.py
119 ./proxypool/middlewares.py
5 ./proxypool/spiders/common_spider.py
67 ./proxypool/spiders/base_spider.py
9 ./proxypool/spiders/__init__.py
7 ./proxypool/logger.py
91 ./proxypool/settings.py
11 ./proxypool/user_agent.py
86 ./proxypool/rules.py
57 ./proxypool/task_queue.py
7 ./proxypool/validators/zhihu_validator.py
7 ./proxypool/validators/baidu_validator.py
56 ./proxypool/validators/base_validator.py
5 ./proxypool/validators/__init__.py
55 ./proxypool/pipelines.py
21 ./proxypool/items.py
0 ./proxypool/__init__.py
59 ./scheduler.py
667 total
细节描述
爬虫部分
数据流向
RedisTaskQueue获取链接
Spider发出请求
RandomUserAgentMiddware换UA
通过规则解析response
送至RedisRawProxyPipeline,未处理数据存入数据库
- 爬取规则的编写
很多免费代理网站的结构都很相似,基本上就是这样的(取自西刺代理):
<tr class="odd">
<td class="country"><img src="http://fs.xicidaili.com/images/flag/cn.png" alt="Cn" /></td>
<td>223.240.209.18</td>
<td>18118</td>
<td>安徽合肥</td>
<td class="country">高匿</td>
<td>HTTP</td>
<td>1分钟</td>
<td>不到1分钟</td>
</tr>
<tr class="">
<td class="country"><img src="http://fs.xicidaili.com/images/flag/cn.png" alt="Cn" /></td>
<td>183.23.73.49</td>
<td>61234</td>
<td>广东东莞</td>
<td class="country">高匿</td>
<td>HTTPS</td>
<td>1小时</td>
<td>不到1分钟</td>
</tr>
...
通过编写爬取规则,我们就可以很方便爬取多个网站:
RULES = {
"xici" : {
"parser_type": "page",
"prefix": "//tr",
"detail": "td/text()",
...
}
}
然后就可以类似这样做请求:
[x.xpath(rule["detail"]) for x in response.xpath(rule["prefix"])]
设计RedisTaskQueue类,让爬虫从中取得要爬取的网站
为啥不让爬虫自己从数据库里取任务呢?
呃 这个本来是为了多进程做的考虑,但是发现scrapy的Spider已经满足时间上的需求了
考虑到以后可能需要这个类来让调度器调度爬虫,于是就留下来了设计基本爬虫BaseSpider
主要是以后用来做爬虫种类的拓展,比如这个网页可能会用js做个动态加载
后续就要考虑到编写JsSpider(BaseSpider)
目前只有一个爬虫CommonSpider(BaseSpider),用来爬普通网页(普通网页或json)Scrapy框架方面
RawProxyUrlItem, ProxyUrlItem
RandomUserAgentMiddleware, TimerMiddleware
RedisRawProxyPipeline, RedisProxyPipeline
验证部分
数据流向
RedisProxyQueue获取ip
Spider发出验证请求
TimerMiddleware开始计时
TimerMiddleware结束计时
通过规则验证response
验证通过,送至RedisRawProxyPipeline,验证后ip存入数据库
验证规则
与爬取规则相同,我们可选许多网站来做验证(每个代理对各网站有不同的效率)
为了方便管理,写验证规则
为什么要验证?
一是为了保证代理速度
二是为了保证不会存在“调包”的情况(中间人偷偷改了回复)代理记分方式
简单的用请求时间来作为分数,存入Redis的有序集合
数据库部分
| 数据项 | 描述 |
|---|---|
| ProxyPool:RAW_IPPOOL | 集合 存储未验证ip |
| ProxyPool:IPPOOL | 有序集合 存储验证通过ip 按分数排序 |
| ProxyPool:TASK_QUEUE | 调度器暂时存入请求链接 |
调度器部分
这部分未完待续
仅仅写了获取爬虫和验证爬虫的简单启动
下一步是根据爬取规则的时间间隔来调度
WebAPI部分
这部分根本还没写
不过这是项目里最简单的东西
准备适当时间入一个服务器,用Flask简单写一写就好了
总结要点
- 在项目里专门写一个配置文件,用以配置工程内所有信息,避免hardcode
- 未来可能需要更多相似的类时,编写基类是必须的,考虑到方便编写和复用性
- 给类中添加某一功能时,如果项目较复杂,写Mixin合适一点
- 若对大量(或后续可能大量)的网站做爬取时,最好抽象出爬取规则,便于处理添加更多爬取网站、更改爬取数据顺序等
- 验证代理ip,考虑代理速度和中间人“调包”的可能
- 使用无表的数据库(such as Redis)时,为了结构清晰,将键值写成"XXX:A:B"的形式
实现细节&需要注意的
- 每一个scrapy.Spider里可以自定义设置
- 比如设置pipeline, middleware, DOWNLOAD_DELAY
custom_settings = {
'DOWNLOAD_TIMEOUT': 1,
'CONCURRENT_REQUESTS': 50,
'CONCURRENT_REQUESTS_PER_DOMAIN': 50,
'RETRY_ENABLED': False,
'DOWNLOADER_MIDDLEWARES': {
'proxypool.middlewares.TimerMiddleware': 500,
},
'ITEM_PIPELINES': {
'proxypool.pipelines.RedisProxyPipeline': 200,
}
}
- Python取数据库的数据后,要看看是不是byte类型
- scrapy.Request包括errback, dont_filter等很有用的参数
- scrapy通过CrawlerProcess方法不能重复启动爬虫,如有需要,用多进程即可
**未完待续**
ip代理池的爬虫编写、验证和维护的更多相关文章
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
- 免费IP代理池定时维护,封装通用爬虫工具类每次随机更新IP代理池跟UserAgent池,并制作简易流量爬虫
前言 我们之前的爬虫都是模拟成浏览器后直接爬取,并没有动态设置IP代理以及UserAgent标识,本文记录免费IP代理池定时维护,封装通用爬虫工具类每次随机更新IP代理池跟UserAgent池,并制作 ...
- IP代理池之验证是否有效
IP代理池之验证是否有效 把proxy pool项目跑起来,但也不知道这些ip怎么用,爬虫的时候是否用代理去爬取,下面通过一个例子来看看. 代码如下: import requests PROXY_PO ...
- 反爬虫之搭建IP代理池
反爬虫之搭建IP代理池 听说你又被封 ip 了,你要学会伪装好自己,这次说说伪装你的头部.可惜加了header请求头,加了cookie 还是被限制爬取了.这时就得祭出IP代理池!!! 下面就是requ ...
- [爬虫]一个易用的IP代理池
一个易用的IP代理池 - stand 写爬虫时常常会遇到各种反爬虫手段, 封 IP 就是比较常见的反爬策略 遇到这种情况就需要用到代理 IP, 好用的代理通常需要花钱买, 而免费的代理经常容易失效, ...
- 静听网+python爬虫+多线程+多进程+构建IP代理池
目标网站:静听网 网站url:http://www.audio699.com/ 目标文件:所有在线听的音频文件 附:我有个喜好就是听有声书,然而很多软件都是付费才能听,免费在线网站虽然能听,但是禁ip ...
- 记一次企业级爬虫系统升级改造(六):基于Redis实现免费的IP代理池
前言: 首先表示抱歉,春节后一直较忙,未及时更新该系列文章. 近期,由于监控的站源越来越多,就偶有站源做了反爬机制,造成我们的SupportYun系统小爬虫服务时常被封IP,不能进行数据采集. 这时候 ...
- Python爬虫之ip代理池
可能在学习爬虫的时候,遇到很多的反爬的手段,封ip 就是其中之一. 对于封IP的网站.需要很多的代理IP,去买代理IP,对于初学者觉得没有必要,每个卖代理IP的网站有的提供了免费IP,可是又很少,写了 ...
- python爬虫实战(三)--------搜狗微信文章(IP代理池和用户代理池设定----scrapy)
在学习scrapy爬虫框架中,肯定会涉及到IP代理池和User-Agent池的设定,规避网站的反爬. 这两天在看一个关于搜狗微信文章爬取的视频,里面有讲到ip代理池和用户代理池,在此结合自身的所了解的 ...
随机推荐
- HTML5与CSS3权威指南之CSS3学习记录
title: HTML5与CSS3权威指南之CSS3学习记录 toc: true date: 2018-10-14 00:06:09 学习资料--<HTML5与CSS3权威指南>(第3版) ...
- 简易Servlet计算器1.0
编写一个简易的Servlet计算器,暂时仅能实现 + - * / % 五种运算 jsp界面: <%@ page language="java" contentType=&qu ...
- 【转】IIS初始化(预加载),解决第一次访问慢,程序池被回收问题
原地址:http://www.debugrun.com/a/mpyWXwg.html 读在最前面: 1.本文以IIS8,Windows Server 2012R2做为案例 2.IIS8 运行在 Win ...
- Swift学习笔记(8):闭包
目录: 基本语法 尾随闭包 值捕获 自动闭包 闭包是自包含的函数代码块,闭包采取如下三种形式之一: ・全局函数是一个有名字但不会捕获任何值的闭包 ・嵌套函数是一个有名字并可以捕获其封闭函数域内值的闭包 ...
- 解决局域网内无法IP访问IIS已发布的网站
在IIS上发布的网站,本地可以访问,但是局域网内其他电脑却访问不了,原来是防火墙的问题,关闭它就可以访问了. 上面是我的简单操作 后来又百度了一下,发现有个更详细的操作:http://jingyan. ...
- Android 优雅的让Fragment监听返回键
Activity可以很容易的得到物理返回键的监听事件,而Fragment却不能.假设FragmentActivity有三个Fragment,一般安卓用户期望点击返回键会一层层返回到FragmentAc ...
- hiho 1572 - set.upper_bound,排序树
链接 小Hi家的阳台上摆着一排N个空花盆,编号1~N.从第一天开始,小Hi每天会选择其中一个还空着花盆,栽种一株月季花,直到N个花盆都栽种满月季. 我们知道小Hi每天选择的花盆的编号依次是A1, A2 ...
- 使用 vue + thinkjs 开发博客程序记录
一入冬懒癌发作,给自己找点事干.之前博客程序写过几次,php 的写过两次,nodejs 用 ThinkJS 写过,随着 ThinkJS 版本从1.x 升级到 2.x 之前的博客程序也做过升级.但是因为 ...
- 洛谷 P1702 突击考试
P1702 突击考试 题目描述 一日,老师决定进行一次突击考试.已知每个学生都有一个考试能力等级,教室里一共有N个课桌,按照顺序排成一列,每张课桌可以坐两个人,第i张课桌坐的两个人的能力等级为(A[i ...
- oracle树操作(select .. start with .. connect by .. prior)
oracle中的递归查询能够使用:select .. start with .. connect by .. prior 以下将会讲述oracle中树形查询的经常使用方式.仅仅涉及到一张表. star ...