Lucene学习总结之六:Lucene打分公式的数学推导 2014-06-25 14:20 384人阅读 评论(0) 收藏
在进行Lucene的搜索过程解析之前,有必要单独的一张把Lucene score公式的推导,各部分的意义阐述一下。因为Lucene的搜索过程,很重要的一个步骤就是逐步的计算各部分的分数。
Lucene的打分公式非常复杂,如下:
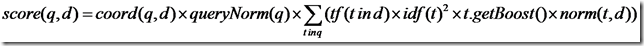
在推导之前,先逐个介绍每部分的意义:
- t:Term,这里的Term是指包含域信息的Term,也即title:hello和content:hello是不同的Term
- coord(q,d):一次搜索可能包含多个搜索词,而一篇文档中也可能包含多个搜索词,此项表示,当一篇文档中包含的搜索词越多,则此文档则打分越高。
- queryNorm(q):计算每个查询条目的方差和,此值并不影响排序,而仅仅使得不同的query之间的分数可以比较。其公式如下:
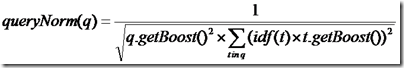
- tf(t in d):Term t在文档d中出现的词频
- idf(t):Term t在几篇文档中出现过
- norm(t, d):标准化因子,它包括三个参数:
- Document boost:此值越大,说明此文档越重要。
- Field boost:此域越大,说明此域越重要。
- lengthNorm(field) = (1.0 / Math.sqrt(numTerms)):一个域中包含的Term总数越多,也即文档越长,此值越小,文档越短,此值越大。

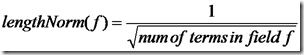
- 各类Boost值
- t.getBoost():查询语句中每个词的权重,可以在查询中设定某个词更加重要,common^4 hello
- d.getBoost():文档权重,在索引阶段写入nrm文件,表明某些文档比其他文档更重要。
- f.getBoost():域的权重,在索引阶段写入nrm文件,表明某些域比其他的域更重要。
以上在Lucene的文档中已经详细提到,并在很多文章中也被阐述过,如何调整上面的各部分,以影响文档的打分,请参考有关Lucene的问题(4):影响Lucene对文档打分的四种方式一文。
然而上面各部分为什么要这样计算在一起呢?这么复杂的公式是怎么得出来的呢?下面我们来推导。
首先,将以上各部分代入score(q, d)公式,将得到一个非常复杂的公式,让我们忽略所有的boost,因为这些属于人为的调整,也省略coord,这和公式所要表达的原理无关。得到下面的公式:

然后,有Lucene学习总结之一:全文检索的基本原理中的描述我们知道,Lucene的打分机制是采用向量空间模型的:
我们把文档看作一系列词(Term),每一个词(Term)都有一个权重(Term weight),不同的词(Term)根据自己在文档中的权重来影响文档相关性的打分计算。
于是我们把所有此文档中词(term)的权重(term weight) 看作一个向量。
Document = {term1, term2, …… ,term N}
Document Vector = {weight1, weight2, …… ,weight N}
同样我们把查询语句看作一个简单的文档,也用向量来表示。
Query = {term1, term 2, …… , term N}
Query Vector = {weight1, weight2, …… , weight N}
我们把所有搜索出的文档向量及查询向量放到一个N维空间中,每个词(term)是一维。

我们认为两个向量之间的夹角越小,相关性越大。
所以我们计算夹角的余弦值作为相关性的打分,夹角越小,余弦值越大,打分越高,相关性越大。
余弦公式如下:
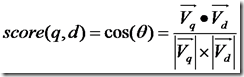
下面我们假设:
查询向量为Vq = <w(t1, q), w(t2, q), ……, w(tn, q)>
文档向量为Vd = <w(t1, d), w(t2, d), ……, w(tn, d)>
向量空间维数为n,是查询语句和文档的并集的长度,当某个Term不在查询语句中出现的时候,w(t, q)为零,当某个Term不在文档中出现的时候,w(t, d)为零。
w代表weight,计算公式一般为tf*idf。
我们首先计算余弦公式的分子部分,也即两个向量的点积:
Vq*Vd = w(t1, q)*w(t1, d) + w(t2, q)*w(t2, d) + …… + w(tn ,q)*w(tn, d)
把w的公式代入,则为
Vq*Vd = tf(t1, q)*idf(t1, q)*tf(t1, d)*idf(t1, d) + tf(t2, q)*idf(t2, q)*tf(t2, d)*idf(t2, d) + …… + tf(tn ,q)*idf(tn, q)*tf(tn, d)*idf(tn, d)
在这里有三点需要指出:
- 由于是点积,则此处的t1, t2, ……, tn只有查询语句和文档的并集有非零值,只在查询语句出现的或只在文档中出现的Term的项的值为零。
- 在查询的时候,很少有人会在查询语句中输入同样的词,因而可以假设tf(t, q)都为1
- idf是指Term在多少篇文档中出现过,其中也包括查询语句这篇小文档,因而idf(t, q)和idf(t, d)其实是一样的,是索引中的文档总数加一,当索引中的文档总数足够大的时候,查询语句这篇小文档可以忽略,因而可以假设idf(t, q) = idf(t, d) = idf(t)
基于上述三点,点积公式为:
Vq*Vd = tf(t1, d) * idf(t1) * idf(t1) + tf(t2, d) * idf(t2) * idf(t2) + …… + tf(tn, d) * idf(tn) * idf(tn)
所以余弦公式变为:
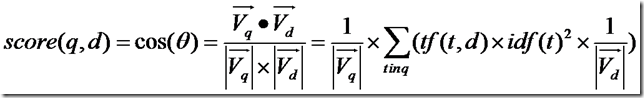
下面要推导的就是查询语句的长度了。
由上面的讨论,查询语句中tf都为1,idf都忽略查询语句这篇小文档,得到如下公式
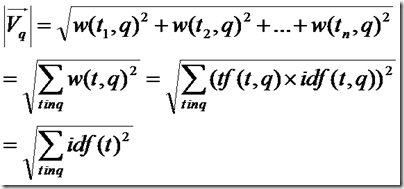
所以余弦公式变为:

下面推导的就是文档的长度了,本来文档长度的公式应该如下:
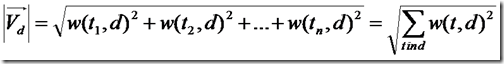
这里需要讨论的是,为什么在打分过程中,需要除以文档的长度呢?
因为在索引中,不同的文档长度不一样,很显然,对于任意一个term,在长的文档中的tf要大的多,因而分数也越高,这样对小的文档不公平,举一个极端的例子,在一篇1000万个词的鸿篇巨著中,"lucene"这个词出现了11次,而在一篇12个词的短小文档中,"lucene"这个词出现了10次,如果不考虑长度在内,当然鸿篇巨著应该分数更高,然而显然这篇小文档才是真正关注"lucene"的。
然而如果按照标准的余弦计算公式,完全消除文档长度的影响,则又对长文档不公平(毕竟它是包含了更多的信息),偏向于首先返回短小的文档的,这样在实际应用中使得搜索结果很难看。
所以在Lucene中,Similarity的lengthNorm接口是开放出来,用户可以根据自己应用的需要,改写lengthNorm的计算公式。比如我想做一个经济学论文的搜索系统,经过一定时间的调研,发现大多数的经济学论文的长度在8000到10000词,因而lengthNorm的公式应该是一个倒抛物线型的,8000到 10000词的论文分数最高,更短或更长的分数都应该偏低,方能够返回给用户最好的数据。
在默认状况下,Lucene采用DefaultSimilarity,认为在计算文档的向量长度的时候,每个Term的权重就不再考虑在内了,而是全部为一。
而从Term的定义我们可以知道,Term是包含域信息的,也即title:hello和content:hello是不同的Term,也即一个Term只可能在文档中的一个域中出现。
所以文档长度的公式为:
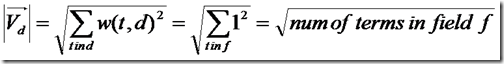
代入余弦公式:
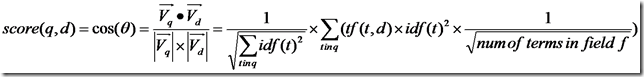
再加上各种boost和coord,则可得出Lucene的打分计算公式。
Lucene学习总结之六:Lucene打分公式的数学推导 2014-06-25 14:20 384人阅读 评论(0) 收藏的更多相关文章
- Lucene学习总结之五:Lucene段合并(merge)过程分析 2014-06-25 14:20 537人阅读 评论(0) 收藏
一.段合并过程总论 IndexWriter中与段合并有关的成员变量有: HashSet<SegmentInfo> mergingSegments = new HashSet<Segm ...
- Lucene学习总结之四:Lucene索引过程分析 2014-06-25 14:18 884人阅读 评论(0) 收藏
对于Lucene的索引过程,除了将词(Term)写入倒排表并最终写入Lucene的索引文件外,还包括分词(Analyzer)和合并段(merge segments)的过程,本次不包括这两部分,将在以后 ...
- Lucene学习总结之一:全文检索的基本原理 2014-06-25 14:11 666人阅读 评论(0) 收藏
一.总论 根据http://lucene.apache.org/java/docs/index.html 定义: Lucene 是一个高效的,基于Java 的全文检索库. 所以在了解Lucene之前要 ...
- Lucene学习总结之三:Lucene的索引文件格式(1) 2014-06-25 14:15 1124人阅读 评论(0) 收藏
Lucene的索引里面存了些什么,如何存放的,也即Lucene的索引文件格式,是读懂Lucene源代码的一把钥匙. 当我们真正进入到Lucene源代码之中的时候,我们会发现: Lucene的索引过程, ...
- Lucene学习总结之二:Lucene的总体架构 2014-06-25 14:12 622人阅读 评论(0) 收藏
Lucene总的来说是: 一个高效的,可扩展的,全文检索库. 全部用Java实现,无须配置. 仅支持纯文本文件的索引(Indexing)和搜索(Search). 不负责由其他格式的文件抽取纯文本文件, ...
- 使用Broadcast实现android组件之间的通信 分类: android 学习笔记 2015-07-09 14:16 110人阅读 评论(0) 收藏
android组件之间的通信有多种实现方式,Broadcast就是其中一种.在activity和fragment之间的通信,broadcast用的更多本文以一个activity为例. 效果如图: 布局 ...
- 给EditText的drawableRight属性的图片设置点击事件 分类: 学习笔记 android 2015-07-06 13:20 134人阅读 评论(0) 收藏
这个方法是通用的,不仅仅适用于EditText,也适用于TextView.AutoCompleteTextView等控件. Google官方API并没有给出一个直接的方法用来设置右边图片的点击事件,所 ...
- ubuntu权限管理常用命令 分类: linux ubuntu 学习笔记 2015-07-05 14:15 77人阅读 评论(0) 收藏
1.chmod 第一种方式 chomd [{ugoa}{+-=}{rwx}] [文件或者目录] u 代表该文件所属用户 g 代表该文件所属用户组 o 代表访客 a 代表所有用户 +-=分别表示增加权限 ...
- linux中echo的用法 分类: 学习笔记 linux ubuntu 2015-07-14 14:27 21人阅读 评论(0) 收藏
1.echo命令我们常用的选项有两个,一个是-n,表示输出之后不换行,另外一个是-e,表示对于转义字符按相应的方式处理,如果不加-e那么对于转义字符会按普通字符处理. 2.echo输出时的转义字符 \ ...
随机推荐
- UICollectionView 集合视图 的使用
直接上代码: // // RootViewController.m // // #import "RootViewController.h" #import "Colle ...
- 从头认识Spring-2.3 注解装配-@autowired(4)-required(1)
这一章节我们来具体讨论一下@autowired里面的參数required. 1.domain(重点) 蛋糕类: package com.raylee.my_new_spring.my_new_spri ...
- 4个开源的Gmail替代品
资料来源 https://opensource.com/alternatives/gmail 本文是对原文翻译,在调试 privmx 时么有成功,这些代码大多用于 php5 ,对PHP7 不兼容. 相 ...
- js06--利用js给数组去重
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/stri ...
- 1.3 Quick Start中 Step 8: Use Kafka Streams to process data官网剖析(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Step 8: Use Kafka Streams to process data ...
- 使用Vue脚手架(vue-cli)从零搭建一个vue项目(包含vue项目结构展示)
注:在搭建项目之前,请先安装一些全局的工具(如:node,vue-cli等) node安装:去node官网(https://nodejs.org/en/)下载并安装node即可,安装node以后就可以 ...
- numpy_basic2
# 六.numpy的常用函数 1. 读取文件 逻辑上可被解释为二维数组的文本文件: 数据项1<分隔符>数据项2<分隔符>...<分隔符>数据项n numpy.loa ...
- 如何在同一台机器上安装多个MySQL的实例(转)
最近由于工作的需要,需要在同一台机器上搭建两个MySQL的实例,(注:已经存在了一个3306的MySQL的实例). 先说下,什么是mysql的多实例,简单的来说就是一台机器上安装了多个mysql的服务 ...
- Arch Linux下配置Samba
本文记录笔者配置Samba的过程,供用于自用. sudo pacman -S samba sudo vim /etc/samba/smb.conf 添加以下内容 [global] dns pro ...
- Android 继承framelayout,实现ScrollView 和 HorizontalScrollView 的效果
有些项目,需要让控件或者布局进行水平和垂直同时能拖拽,当然,ScrollView 和 HorizontalScrollView 的结合写法是一种写法.但是,这么写用户体验效果不佳,会有迟钝感,因此推荐 ...