scrapy 动态网页处理——爬取鼠绘海贼王最新漫画
简介
scrapy是基于python的爬虫框架,易于学习与使用。本篇文章主要介绍如何使用scrapy爬取鼠绘漫画网海贼王最新一集的漫画。
源码参见:https://github.com/liudaolufei/crawl-comic
网站分析
鼠绘海贼王网站网址为:http://www.ishuhui.com/comics/anime/1
漫画链接无法直接从原始网页中得到,需要点击对应的话数,链接才会显示出来,如下图所示:
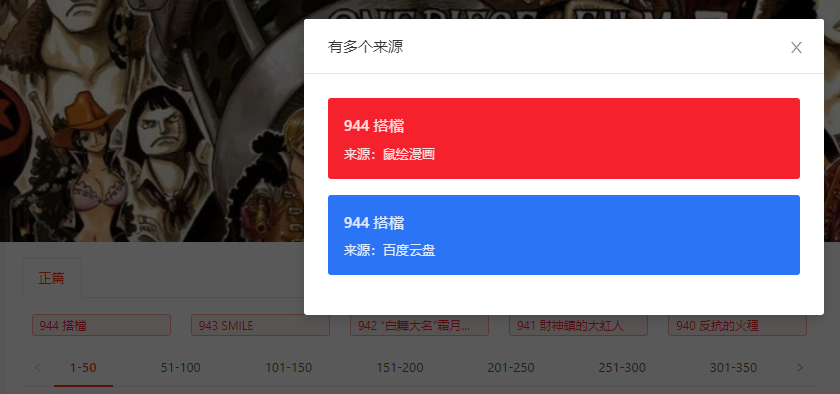
获取链接后即可获得海贼王漫画的网页地址,网页如下:

原始的网页没有漫画的图片链接,需要点击图中的“连页模式”,之后网页才会显示漫画的具体内容,此时的漫画内容也是动态加载的,随着窗口不断往下,图片会一张张加载出来。
工具
scrapy: 爬虫框架
splash: 动态网页处理
环境安装
scrapy安装
已安装anaconda,python3.7版本。
创建scrapy虚拟环境并激活
conda create -n scrapy
conda activate scrapy
使用pip安装scrapy以及用于与splash交互的scrapy-splash
pip install scrapy scrapy-splash
在使用scrapy的ImagePipeline的时候需要第三方库PIL,安装PIL
pip install pillow
splash安装
splash服务是通过docker启用的,所以要先安装docker,docker安装参见:https://docs.docker.com/install/
使用docker安装splash
docker pull scrapinghub/splash
启用splash服务
docker run -p : scrapinghub/splash
scrapy爬虫
生成scrapy项目并生成爬虫
scrapy startproject crawlComics
cd crawlComics
scrapy genspider shuhui http://www.ishuhui.com/anime/1
此时在spiders文件夹下有了shuhui.py,这是爬虫的基础模板。
修改基础设置(setting.py)
使用splash的设定
# Splash服务器地址
SPLASH_URL = 'http://localhost:8050'
# 开启Splash的两个下载中间件并调整HttpCompressionMiddleware的次序
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 727,
}
# 设置去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
user-agent
USER_AGENT = "Mozilla/5.0 (Platform; Encryption; OS-or-CPU; Language) AppleWebKit/AppleWebKitVersion (KHTML, like Gecko)"
使用ImagePipelines保存图片的相关设定
# 图片存储位置
IMAGES_STORE = "/home/luoheng/comics/"
# 启用ImagesPipeline来下载图片
ITEM_PIPELINES = {
'crawlComics.pipelines.RenameImagesPipeline': 500,
}
添加item
item是scrapy中传输数据的基本单位,可以简单的理解为字典。
scrapy的ImagePipelines是为下载图片专门设计的,它接受一个包含键值“image_urls”和“images”的item。ImagePipelines在得到item后,会自动根据image_urls中包含的链接下载对应的图片,并放置到上文设定的IMAGE_STORE中。
故为了使用ImagePipelines,在items.py中添加一个符合条件的item:
class ImageItem(scrapy.Item):
image_urls = scrapy.Field()
images = scrapy.Field()
# store picture names
image_names = scrapy.Field()
前两项是为了满足ImagePipelines的要求设置的,最后一项用于设置下载图片的名字,因为ImagePipelines默认使用hash值对图片进行命名,不具可读性。
实现爬虫
爬虫主要的工作流程
1. 在http://www.ishuhui.com/anime/1页面点击最新漫画按钮,返回响应结果
2. 从响应结果中获取海贼王最新漫画的具体网址
3. 在最新漫画的网址中点击“连页模式”,并将网页拉到最下方,以使所有图片的链接加载出来,返回响应结果
4. 从响应结果中获取图片的链接,使用ImagePipelines下载
导入item与splash
from scrapy_splash import SplashRequest
from ..items import ImageItem
SplashRequest用于与splash服务进行交互,在这里主要用了splash的“execute”功能,它接受的几个参数如下:
SplashRequest(url, callback=self.parse, endpoint="execute", args={"lua_source": lua_script})
url是原始网址,callback是回调函数,即处理返回的response的函数,endpoint指明使用的功能,这里使用的是“execute”,即执行脚本的功能,最后一个args用于指定用于执行的脚本,这里的脚本是用lua语言写成的,在Python中以字符串形式存在。
点击最新漫画
click_latest_comic = """
function main(splash)
# 打开网页
splash:go(splash.args.url)
# 等待网页加载
splash:wait(2)
# 点击最新漫画(由class ant-tag-red识别)
splash:runjs("document.getElementsByClassName('ant-tag-red')[0].click()")
# 等待网页加载
splash:wait(0.1)
# 返回网页结果
return splash:html()
end
"""
# 返回点击最新漫画后的响应结果
yield SplashRequest(url, callback=self.show_all, endpoint="execute", args={"lua_source": click_latest_comic})
打开具体网址,并加载所有漫画图片
show_all_pictures = """
function main(splash)
# 打开网页
splash:go(splash.args.url)
# 等待网页加载
splash:wait(2)
# 点击连页模式(由class z-page识别)
splash:runjs("document.getElementsByClassName('z-page')[0].click()")
# 等待网页加载
splash:wait(0.1)
# 将网页拉到最下方,使所有图片的链接加载出来
splash:runjs("window.scrollTo(0, document.body.scrollHeight)")
# 等待网页加载
splash:wait(0.1)
# 返回响应结果
return splash:html()
end
""" def show_all(self, response):
# 获取漫画具体网址
target = response.css(".m-comics-num-link").xpath("@url").extract_first()
# target是相对网址,它的前缀是http://www.hanhuazu.cc
new_url = "http://www.hanhuazu.cc" + target
# 返回已经加载了所有图片链接的网页
yield SplashRequest(new_url, endpoint="execute", args={"lua_source": show_all_pictures})
使用ImageItem保存图片链接并传送给ImagePipelines下载
def parse(self, response):
# 所有图片
comics = response.css("div img")
# src属性中保存所有图片链接,alt属性保存图片名字
comics_picture, comics_name = comics.xpath("@src").extract(), comics.xpath("@alt").extract()
# 构建ImageItem并返回给ImagePipelines
images = ImageItem()
# 保存图片链接
images["image_urls"] = comics_picture
# 保存图片链接与图片名字的映射,用于下载图片的命名
images["image_names"] = dict(zip(comics_picture, comics_name))
# 返回后,ImagePipelines会自动下载图片
return images
修改ImagePipelines,覆盖默认命名
class RenameImagesPipeline(ImagesPipeline):
"""to rename the images properly""" def process_item(self, item, spider):
# add names
self.item_names = item["image_names"]
info = self.spiderinfo
requests = arg_to_iter(self.get_media_requests(item, info))
dlist = [self._process_request(r, info) for r in requests]
dfd = DeferredList(dlist, consumeErrors=1)
return dfd.addCallback(self.item_completed, item, info) def file_path(self, request, response=None, info=None):
return self.item_names[request.url]
ImagesPipeline的file_path用于计算图片的命名,但是由于图片名字保存在item的image_names属性中,而file_path并不直接接受item参数,所以需要将item["image_names"]保存到self.item_names中,如此file_path才可访问到名字。
因此将ImagesPipeline的process_item方法的代码完整复制过来,并在最前面将image_names保存到self.item_names当中,在file_path方法中只用简单调用self.item_names[request.url]即可获取图片名字。
运行爬虫
scrapy crawl shuhui
完成后,在comics文件夹中可以看到爬取的图片。
总结
以爬取鼠绘海贼王漫画为例,本文简单介绍了使用scrapy+splash处理动态网页的方法。
scrapy 动态网页处理——爬取鼠绘海贼王最新漫画的更多相关文章
- 【python3】爬取鼠绘汉化的海贼王漫画
特别说明: 因为早些时候鼠绘的接口调整,之前的代码已经不能用了. 正好最近在学习scrapy,于是重新写了一个,项目放在github https://github.com/TurboWay/ishu ...
- scrapy之360图片爬取
#今日目标 **scrapy之360图片爬取** 今天要爬取的是360美女图片,首先分析页面得知网页是动态加载,故需要先找到网页链接规律, 然后调用ImagesPipeline类实现图片爬取 *代码实 ...
- 基于selenium+phantomJS的动态网站全站爬取
由于需要在公司的内网进行神经网络建模试验(https://www.cnblogs.com/NosenLiu/articles/9463886.html),为了更方便的在内网环境下快速的查阅资料,构建深 ...
- 爬虫---selenium动态网页数据抓取
动态网页数据抓取 什么是AJAX: AJAX(Asynchronouse JavaScript And XML)异步JavaScript和XML.过在后台与服务器进行少量数据交换,Ajax 可以使网页 ...
- Scrapy爬虫框架之爬取校花网图片
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
- 使用for或while循环来处理处理不确定页数的网页数据爬取
本文转载自以下网站: Python For 和 While 循环爬取不确定页数的网页 https://www.makcyun.top/web_scraping_withpython16.html 需 ...
- 关于js渲染网页时爬取数据的思路和全过程(附源码)
于js渲染网页时爬取数据的思路 首先可以先去用requests库访问url来测试一下能不能拿到数据,如果能拿到那么就是一个普通的网页,如果出现403类的错误代码可以在requests.get()方法里 ...
- 基于scrapy框架输入关键字爬取有关贴吧帖子
基于scrapy框架输入关键字爬取有关贴吧帖子 站点分析 首先进入一个贴吧,要想达到输入关键词爬取爬取指定贴吧,必然需要利用搜索引擎 点进看到有四种搜索方式,分别试一次,观察url变化 我们得知: 搜 ...
- Python实训day07pm【Selenium操作网页、爬取数据-下载歌曲】
练习1-爬取歌曲列表 任务:通过两个案例,练习使用Selenium操作网页.爬取数据.使用无头模式,爬取网易云的内容. ''' 任务:通过两个案例,练习使用Selenium操作网页.爬取数据. 使用无 ...
随机推荐
- open-ldap schema (2)
schema介绍及用途 schema 是OpenLDAP 软件的重要组成部分,主要用于控制目录树中各种条目所拥有的对象类以及各种属性的定义,并通过自身内部规范机制限定目录树条目所遵循的逻辑结构以及定义 ...
- 在vue项目中引用element-ui时 让el-input 获取焦点的方法
在制作项目的时候遇到一个需求,点击一个按钮弹出一个input输入框,并让输入框获得焦点,项目中引用了ElementUI 在网上查找了很多方法,但是在实际使用中发现了一个问题无论是使用$ref获取inp ...
- workspace 配置
1.新建workspace 在配置好相关信息前,请勿引入工程代码,避免环境不完整的情况下编译进入长时间等待 2.设置工作窗体结构 建议使用Java模式开发窗体设置 3. 编码 工程全部采用UTF-8编 ...
- Disruptor使用
Disruptor作者,介绍Disruptor能每秒处理600万订单.这是一个可怕的数字. disruptor之所以那么快,是因为内部采用环形队列和无锁设计.使用cas来进行并发控制.通过获取可用下标 ...
- Atomic operations on the x86 processors
On the Intel type of x86 processors including AMD, increasingly there are more CPU cores or processo ...
- FZU Problem 2082 过路费
Problem 2082 过路费 Accept: 875 Submit: 2839Time Limit: 1000 mSec Memory Limit : 32768 KB Problem ...
- hdu 2883 kebab(时间区间压缩 && dinic)
kebab Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Subm ...
- Java类集综合练习——信息管理(增、删、改、查)
一.实现功能——模拟学生选课功能 1.选择课程 2.修改所选课程 二.实现功能——模拟学生信息管理功能 1.添加学生信息 2.修改学生信息 二.主要代码(在同一个包里) 1.课程类 public cl ...
- luogu3366 【模板】 最小生成树 Prim
题目大意 给出一个无向图,求出最小生成树,如果该图不连通,则输出orz. 概念 对于一个无向图,要求选出一些边,使得图上的每一个节点互相连通,且边权和最小.选出的边与节点形成的子图必然是颗树,这棵树叫 ...
- EOJ 2822 内存显示
一个 int 类型变量或 double 类型变量在连续几个字节的内存中存放.读取数值时,当数值中包含小数点时类型为 double,否则类型为 int.将读入的数值存放在 int 类型变量或 doubl ...