Hadoop 完全分布式部署(三节点)
用来测试,我在VMware下用Centos7搭起一个三节点的Hadoop完全分布式集群。其中NameNode和DataNode在同一台机器上,如果有条件建议大家把NameNode单独放在一台机器上,因为NameNode是集群的核心承载压力是很大的。hadoop版本:Hadoop-2.7.4;
|
hadoopo1 |
hadoopo2 |
hadoopo3 |
| Namenode | ResourceManage | SecondaryNamenode |
| Datanode | Datanode | Datanode |
| NodeManage | NodeManage | NodeManage |
一、准备环境
- 准备三台节点(机器),要求:yum源挂载成功、网络设置可用(ip在同一网段,连接Xshell)、已安装Oracle8.0及以上版本JDK;
hadoop-2.7.4.tar.gz,hadoop2.x安装包;
二、部署集群
- 创建Hadoop用户(三节点);
su - root
useradd hadoop
passwd hadoop - 在Hadoop用户家目录下创建安装目录(三节点);
mkdir /home/hadoop/install (安装目录)
mkdir /home/hadoop/soft (存放安装包) - 解压hadoop安装包,通过Xshell等工具将安装包上传到~/soft目录中(hadoop01节点);
tar –zxvf /home/hadoop/soft/hadoop-2.7.4.tar.gz -C /home/hadoop/install/
三、修改配置文件(hadoop01节点)
- cd到hadoop配置文件目录;
su - hadoop
cd /home/hadoop/install/hadoop-2.7.4/etc/hadoop - core-site.xml设置
vim core-site.xml
//在<configuration> 之间添加如下配置<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
<!-- hadoop01:主机名,:端口 -->
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property> - hadoop-env.sh,JDK配置;
vim hadoop-env.sh
//修改等号后面的值
//使用echo $JAVA_HOME 查看JDK安装路径
export JAVA_HOME=/usr/local/jdk - HDFS相关配置;
vim hdfs-site.xml
//在<configuration> 之间添加如下配置<!-- secondaryNamenode地址 -->
<property>
<name>dfs.secondary.http.address</name>
<value>hadoop03:</value>
</property> <!-- 数据块冗余份数-->
<property>
<name>dfs.replication</name>
<value></value>
</property> <!-- edtis文件存放地址-->
<property>
<name>dfs.namenode.edits.dir</name>
<value>/data/hadoop/namenode/name</value>
</property> <!-- datanode数据目录存放地址-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/datanode/data</value>
</property> <!-- checkpoint数据目录存放地址-->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/data/hadoop/namenode/namesecondary</value>
</property> - mapred-env.sh
vim mapred-env.sh
//修改export JAVA_HOME=/usr/local/jdk - MR相关配置
vim mapred-env.sh
//修改export JAVA_HOME=/usr/local/jdkcp mapred-site.xml.template ./mapred-site.xml
vim mapred-site.xml
//在<configuration> 之间添加如下配置<!-- 集群调度框架为YARN-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> <!-- 注意:"hadoop01"替换为NameNode所在主机名-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:</value>
</property> - YARN相关配置;
vim yarn-site.xml
//在<configuration> 之间添加如下配置<!--resourcemanager主机名 -->
<!-- 注意:"hadoop02"替换为resourcemanager所在主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop02</value>
</property> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop02:</value>
</property> <property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value></value>
</property> <!--nodemanager最多分配cpu虚拟核心个数 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value></value>
</property> <!--nodemanager最多内存大小 -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value></value>
</property> <!--作业调度过程中 作业单个内存最少内存大小 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value></value>
</property> <!--作业调度过程中 作业单个最多的cpu分配 -->
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value></value>
</property> - 启动脚本配置;
在调用脚本的过程中,start-dfs.sh和start-yarn.sh会使用该脚本进行datanode和ndoemanager的启动。
vim slaves
//将三台主机名写入后保存hadoop01
hadoop02
hadoop03
四、创建数据目录
- 创建Datanode节点数据目录(三节点);
su – root
mkdir -p /data/hadoop/tmp
mkdir -p /data/hadoop/datanode/data
chown hadoop:hadoop -R /data/hadoop - 创建Namenode节点数据目录(hadoop01节点);
su – root
mkdir -p /data/hadoop/tmp
mkdir -p /data/hadoop/namenode/name
mkdir -p /data/hadoop/datanode/data
mkdir -p /data/hadoop/namenode/namesecondary
chown hadoop:hadoop -R /data/hadoop
五、配置hadoop环境变量(三节点)
su – root
vim /etc/profile
//在文件末尾添加如下设置
//最后更新环境变量(root/hadoop)
source /etc/profile
HADOOP_HOME=/home/hadoop/install/hadoop-2.7.
PATH=$PATH:$HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
六、配置SSH互信(三节点)
- 将三台节点ip添加到Hosts文件中;su – root
vim /etc/hosts
//加入三台节点的ip映射192.168.1.10 hadoop01
192.168.1.11 hadoop02
192.168.1.12 hadoop03
- 在hadoop用户下,生成密钥对(三节点);
su – hadoop
ssh-keygen
- 查看密钥,并将公钥发给三个个节点;
cd /home/hadoop/.ssh/
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop01
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop02
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop03
七、分发hadoop安装目录(hadoop01)
scp –r ~/install hadoop@hadoop02:~/install
scp –r ~/install hadoop@hadoop03:~/install
八、格式化并且启动HDFS(重点)
- 在hadoop用户下,namenode节点上;
su – hadoop
hdfs namenode -format
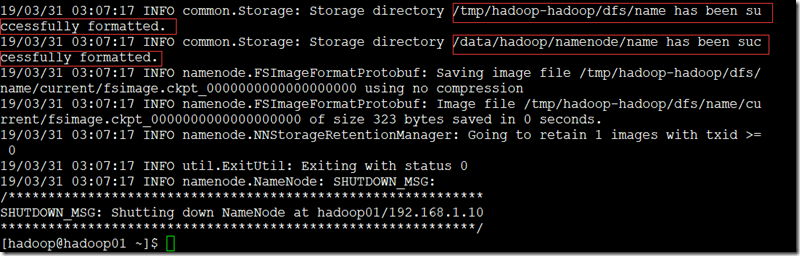
九、启动集群
- 启动HDFS(hadoop01上);
su – hadoop
start-dfs.sh - 启动YARN(hadoop02上);
su – hadoop
start-yarn.sh - 查看进程(jps);

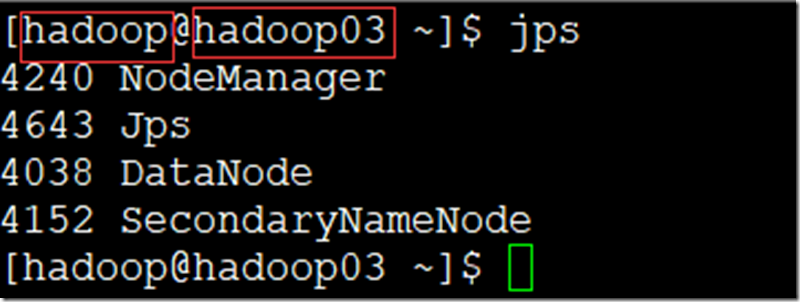
- 管理页面
进入HDFS管理页面:http://192.168.1.10:50070,查看DataNode节点信息;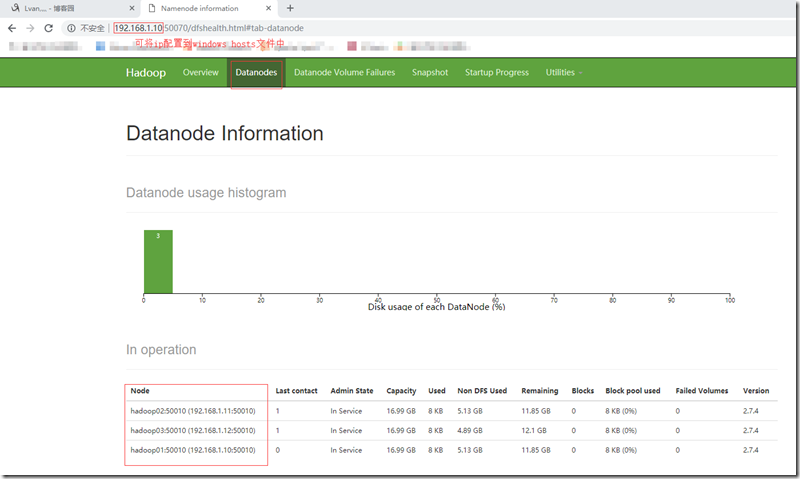
查看yarn框架管理:http://192.168.1.11:8088,查看NodeManager节点;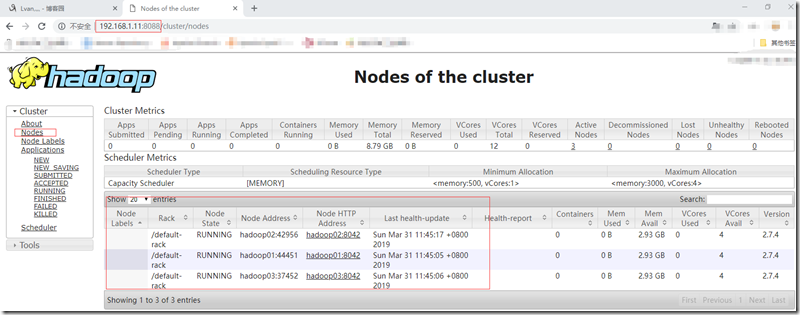
十、关闭集群
- 停止HDFS服务(hadoop01上)
stop-dfs.sh - 停止Yarn服务(hadoop02上)
stop-yarn.sh
Hadoop 完全分布式部署(三节点)的更多相关文章
- ubuntu下hadoop完全分布式部署
三台机器分别命名为: hadoop-master ip:192.168.0.25 hadoop-slave1 ip:192.168.0.26 hadoop-slave2 ip:192.168.0.27 ...
- Hadoop 完全分布式部署
完全分布式部署Hadoop 分析: 1)准备3台客户机(关闭防火墙.静态ip.主机名称) 2)安装jdk 3)配置环境变量 4)安装hadoop 5)配置环境变量 6)安装ssh 7)集群时间同步 7 ...
- 【Hadoop 分布式部署 三:基于Hadoop 2.x 伪分布式部署进行修改配置文件】
1.规划好哪些服务运行在那个服务器上 需要配置的配置文件 2. 修改配置文件,设置服务运行机器节点 首先在 hadoop-senior 的这台主机上 进行 解压 hadoop2.5 按照 ...
- hadoop完全分布式部署
1.我们先看看一台节点的hdfs的信息:(已经安装了hadoop的虚拟机:安装hadoophttps://www.cnblogs.com/lyx666/p/12335360.html) start-d ...
- Hadoop伪分布式部署
一.Hadoop组件依赖关系: 步骤 1)关闭防火墙和禁用SELinux 切换到root用户 关闭防火墙:service iptables stop Linux下开启/关闭防火墙的两种方法 1.永久性 ...
- ubuntu hadoop伪分布式部署
环境 ubuntu hadoop2.8.1 java1.8 1.配置java1.8 2.配置ssh免密登录 3.hadoop配置 环境变量 配置hadoop环境文件hadoop-env.sh core ...
- Hadoop+HBase分布式部署
test 版本选择
- hadoop(七)集群配置同步(hadoop完全分布式四)|9
前置配置:rsync远程同步|xsync集群分发(hadoop完全分布式准备三)|9 1. 分布式集群分配原则 部署分配原则 说明Namenode和secondarynamenode占用内存较大,建议 ...
- zabbix分布式部署和主机自动发现
1.分布式部署原理 1.1Zabbix分布式部署的原理 传统的部署架构,是server直接监控所有的主机,全部主机的数据都是有server自己来采集和处理,server端的压力比较大,当监控主机数量很 ...
随机推荐
- jquery源码解析:proxy,access,swap,isArraylike详解
jQuery的工具方法,其实就是静态方法,源码里面就是通过extend方法,把这些工具方法添加给jQuery构造函数的. jQuery.extend({ ...... guid: 1, //唯一标识符 ...
- redis 3.0 集群__监控警报工具(sentinel)
参考文档 http://redis.readthedocs.org/en/latest/topic/sentinel.html 因为目前还处于开发阶段,就先不研究了,待续
- UIViewContentMode-
图片很小,frame很大 图片很大,frame很小 UIViewContentModeScaleToFill, UIViewContentModeScaleAspectFit, UIViewConte ...
- P2046 [NOI2010]海拔 平面图转对偶图(最小割-》最短路)
$ \color{#0066ff}{ 题目描述 }$ YT市是一个规划良好的城市,城市被东西向和南北向的主干道划分为n×n个区域.简单起见,可以将YT市看作 一个正方形,每一个区域也可看作一个正方形. ...
- leetcode-824-Goat Latin(字符串的处理)
题目描述: A sentence S is given, composed of words separated by spaces. Each word consists of lowercase ...
- 编译安装php-5.3.27报错:make: *** [sapi/fpm/php-fpm] 错误 1
安装PHP的时候make报错:make: *** [sapi/fpm/php-fpm] Error 1 原因:Centos6.8之后已经将iconv库加进来了,如果再安装libiconv库相当于重复一 ...
- python爬虫之urllib库(一)
python爬虫之urllib库(一) urllib库 urllib库是python提供的一种用于操作URL的模块,python2中是urllib和urllib2两个库文件,python3中整合在了u ...
- archlinux安装tftp
1. 安装 [guo@archlinux ~]$ sudo pacman -S tftp-hpa 2. 启用 [guo@archlinux ~]$ systemctl start tftpd.se ...
- Jenkins 发布平台 MSB4064: The "Retries" parameter is not supported & error MSB4063: The "Copy" task could not be initialized
____________________________________________________________________________________________________ ...
- 文献综述十四:基于Oracle11g的超市进销存管理系统设计与实现
一.基本信息 标题:基于Oracle11g的超市进销存管理系统设计与实现 时间:2016 出版源:技术创新 文件分类:对数据库的研究 二.研究背景 为超市设计开发的超市管理系统,采用的是 VC+ Or ...