数据库引擎、索引、pymysql
一、数据库存储引擎
1、存储引擎
mysql中建立的库===>文件夹
库中建立的表===>文件
现实生活中我们用来存储数据的文件应该有不同的类型:比如存文本用txt类型,存表格用excel,存图片用png等。
数据库中的表也应该有不同的类型,表的类型不同,会对应mysql不同的存取机制,表类型又称为存储引擎。
存储引擎说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方
法。因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即存储和
操作此表的类型)。
在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的。而MySql
数据库提供了多种存储引擎。用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据
自己的需要编写自己的存储引擎。
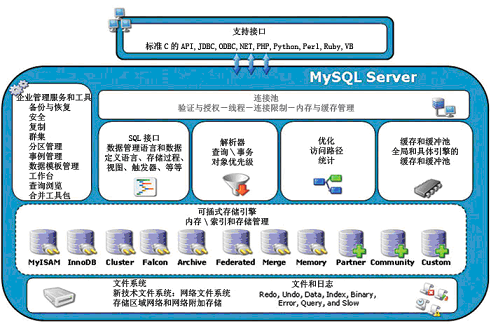
2、mysql支持的存储引擎
mysql> show engines\G; #查看所有支持的存储引擎
mysql> show variables like '%storage_engine%'; #查看正在使用的存储引擎
MySQL常用的存储引擎
MyISAM存储引擎
由于该存储引擎不支持事务、也不支持外键,所以访问速度较快。因此当对事务完整性没有要求并以访问为主的应用适合使用该存储引擎。
InnoDB存储引擎(主要使用)
由于该存储引擎在事务上具有优势,即支持具有提交、回滚及崩溃恢复能力等事务特性,所以比MyISAM存储引擎占用更多的磁盘空间。因此当需要频繁的更新、删除操作,同时还对事务的完整性要求较高,需要实现并发控制,建议选择。
MEMORY
MEMORY存储引擎存储数据的位置是内存,因此访问速度最快,但是安全上没有保障。适合于需要快速的访问或临时表。
BLACKHOLE
黑洞存储引擎,可以应用于主备复制中的分发主库。
3、使用存储引擎
方法1:建表时指定
mysql> create table innodb_t1(id int,name char)engine=innodb;
mysql> create table innodb_t2(id int)engine=innodb;
mysql> show create table innodb_t1;
mysql> show create table innodb_t2;
方法2:在配置文件中指定默认的存储引擎
/etc/my.cnf
[mysqld]
default-storage-engine=INNODB
innodb_file_per_table=1
查看
[root@egon db1]# cd /var/lib/mysql/db1/
[root@egon db1]# ls
db.opt innodb_t1.frm innodb_t1.ibd innodb_t2.frm innodb_t2.ibd
二、索引
1、索引简介
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。
索引优化应该是对查询性能优化最有效的手段了。
索引能够轻易将查询性能提高好几个数量级。
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
索引特点:创建与维护索引会消耗很多时间与磁盘空间,但查询速度大大提高!
2、索引语法
创建索引

--创建表时
--语法:
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE] INDEX | KEY
[索引名] (字段名[(长度)] [ASC |DESC])
); --------------------------------
--创建普通索引示例: CREATE TABLE emp1 (
id INT,
name VARCHAR(30) ,
resume VARCHAR(50),
INDEX index_emp_name (name)
--KEY index_dept_name (dept_name)
); --创建唯一索引示例: CREATE TABLE emp2 (
id INT,
name VARCHAR(30) ,
bank_num CHAR(18) UNIQUE ,
resume VARCHAR(50),
UNIQUE INDEX index_emp_name (name)
); --创建全文索引示例: CREATE TABLE emp3 (
id INT,
name VARCHAR(30) ,
resume VARCHAR(50),
FULLTEXT INDEX index_resume (resume)
); --创建多列索引示例: CREATE TABLE emp4 (
id INT,
name VARCHAR(30) ,
resume VARCHAR(50),
INDEX index_name_resume (name,resume)
);
---------------------------------
添加和删除索引
---添加索引
---CREATE在已存在的表上创建索引
CREATE [UNIQUE] INDEX 索引名
ON 表名 (字段名[(长度)] [ASC |DESC]) ;
---ALTER TABLE在已存在的表上创建索引
ALTER TABLE 表名 ADD [UNIQUE] INDEX
索引名 (字段名[(长度)] [ASC |DESC]) ;
CREATE INDEX index_emp_name on emp1(name);
ALTER TABLE emp2 ADD UNIQUE INDEX index_bank_num(band_num);
-- 删除索引
语法:DROP INDEX 索引名 on 表名
DROP INDEX index_emp_name on emp1;
DROP INDEX bank_num on emp2;
3、索引测试实验
--创建表
create table Indexdb.t1(id int,name varchar(20)); --存储过程 delimiter $$
create procedure autoinsert()
BEGIN
declare i int default 1;
while(i<500000)do
insert into Indexdb.t1 values(i,'yuan');
set i=i+1;
end while;
END$$ delimiter ; --调用函数
call autoinsert(); -- 花费时间比较:
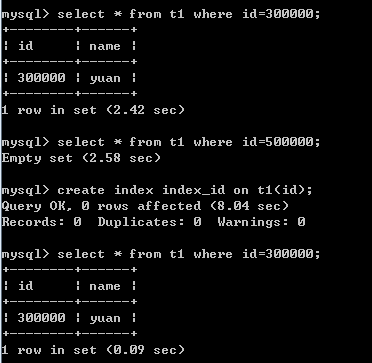
-- 创建索引前
select * from Indexdb.t1 where id=300000;--2.42s
-- 添加索引
create index index_id on Indexdb.t1(id);
-- 创建索引后
select * from Indexdb.t1 where id=300000;--0.09s
三、pymysql
pymysql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同。
一、下载安装:
pip3 install pymysql
二、使用
1、执行SQL
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql # 创建连接
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1')
# 创建游标
cursor = conn.cursor() # 执行SQL,并返回收影响行数
effect_row = cursor.execute("update hosts set host = '1.1.1.2'") # 执行SQL,并返回受影响行数
#effect_row = cursor.execute("update hosts set host = '1.1.1.2' where nid > %s", (1,)) # 执行SQL,并返回受影响行数
#effect_row = cursor.executemany("insert into hosts(host,color_id)values(%s,%s)", [("1.1.1.11",1),("1.1.1.11",2)]) # 提交,不然无法保存新建或者修改的数据
conn.commit() # 关闭游标
cursor.close()
# 关闭连接
conn.close()
2、获取新创建数据自增ID
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1')
cursor = conn.cursor()
cursor.executemany("insert into hosts(host,color_id)values(%s,%s)", [("1.1.1.11",1),("1.1.1.11",2)])
conn.commit()
cursor.close()
conn.close() # 获取最新自增ID
new_id = cursor.lastrowid
3、获取查询数据
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1')
cursor = conn.cursor()
cursor.execute("select * from hosts") # 获取第一行数据
row_1 = cursor.fetchone() # 获取前n行数据
# row_2 = cursor.fetchmany(3)
# 获取所有数据
# row_3 = cursor.fetchall() conn.commit()
cursor.close()
conn.close()
注:在fetch数据时按照顺序进行,可以使用cursor.scroll(num,mode)来移动游标位置,如:
- cursor.scroll(1,mode='relative') # 相对当前位置移动
- cursor.scroll(2,mode='absolute') # 相对绝对位置移动
4、fetch数据类型
关于默认获取的数据是元祖类型,如果想要或者字典类型的数据,即:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1') # 游标设置为字典类型
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
r = cursor.execute("call p1()") result = cursor.fetchone() conn.commit()
cursor.close()
conn.close()
数据库引擎、索引、pymysql的更多相关文章
- SQL Server 索引优化-----数据库引擎优化顾问
本文将根据“数据库引擎优化顾问”(DTA)来发现无用或缺失的索引. 要使用“数据库引擎优化顾问”,首先需要对数据库负载进行监控,为数据库负载分析准备数据.从SSMS的工具中,打开SQL Server ...
- mysql 数据库引擎
一.数据库引擎 数据库引擎是用于存储.处理和保护数据的核心服务.利用数据库引擎可控制访问权限并快速处理事务,从而满足企业内大多数需要处理大量数据的应用程序的要求. 使用数据库引擎创建用于联机事务处理或 ...
- MySQL数据库引擎介绍、区别、创建和性能测试的深入分析
本篇文章是对MySQL数据库引擎介绍.区别.创建和性能测试进行了详细的分析介绍,需要的朋友参考下 数据库引擎介绍 MySQL数据库引擎取决于MySQL在安装的时候是如何被编译的.要添加一个新的引擎 ...
- 降龙十八掌之一:(亢龙有悔)SQL Server Profiler和数据库引擎优化顾问
简介 说到Sql的[性能工具]真是强大,SQL Server Profiler的中文意思是SQL Server事件探查,这个到底是做什么用的呢?我们都知道探查的意思大多是和监视有关,其实这个SQL S ...
- [转]MySQL数据库引擎介绍、区别、创建和性能测试的深入分析
本篇文章是对MySQL数据库引擎介绍.区别.创建和性能测试进行了详细的分析介绍,需要的朋友参考下 数据库引擎介绍 MySQL数据库引擎取决于MySQL在安装的时候是如何被编译的.要添加一个新的引擎 ...
- [转]MySQL数据库引擎
经常用MySQL数据库,但是,你在用的时候注意过没有,数据库的存储引擎,可能有注意但是并不清楚什么意思,可能根本没注意过这个问题,使用了默认的数据库引擎,当然我之前属于后者,后来成了前者,然后就有了这 ...
- MySQL的数据库引擎的类型及区别
MySQL的数据库引擎的类型 你能用的数据库引擎取决于mysql在安装的时候是如何被编译的.要添加一个新的引擎,就必须重新编译MYSQL.在缺省情况下,MYSQL支持三个引擎:ISAM.MYISAM和 ...
- (转)MySQL数据库引擎ISAM MyISAM HEAP InnoDB的区别
转自:http://blog.csdn.net/nightelve/article/details/16895917 MySQL数据库引擎取决于MySQL在安装的时候是如何被编译的.要添加一个新的引擎 ...
- (转) mysql数据库引擎:MyISAM和InnoDB(性能优化)
转自 http://yuwensan126.iteye.com/blog/1138022 Mysql 数据库中,最常用的两种引擎是innordb和myisam.Innordb的功能要比myiasm强大 ...
- MySQL 数据库 引擎
MySQL数 据库引擎取决于MySQL在安装的时候是如何被编译的.要添加一个新的引擎,就必须重新编译MYSQL.在缺省情况下,MYSQL支持三个引 擎:ISAM.MYISAM和HEAP.另外两种类型I ...
随机推荐
- Java序列化与反序列化学习(二):序列化接口说明
一.序列化类实现Serializable接口 Serializable接口没有方法,更像是个标记.有了这个标记的Class就能被序列化机制处理. ObjectOutputStream只能对Serial ...
- PHP特性整合(PHP5.X到PHP7.1.x)
Buid-in web server内置了一个简单的Web服务器 把当前目录作为Root Document只需要这条命令即可: php -S localhost:3300 也可以指定其它路径 php ...
- Archive for required library xx cannot be read or is not a valid ZIP file
原因:maven下载的jar包有问题,导致maven编译的时候出错 解决方法:找到jar包所在的文件路径,在网上重新下载个相同版本的jar包,问题解决
- 结构体sockadrr、sockaddr_in、in_addr的定义
/* Internet address. */typedef uint32_t in_addr_t;struct in_addr { in_addr_t s_addr; }; typed ...
- SonarQube代码质量管理平台安装与配置
1.安装说明 操作用户:root 软件下载目录:/root/opt 无root权限时,放到自定义目录即可 ================ 2.预置条件 1.需要JDK1.6+支持: 2.需要Mysq ...
- 简单的SpringCloud 熔断Hystrix
pom配置 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId> ...
- nginx 403 forbidden 二种原因
nginx 403 forbidden 二种原因 引起nginx 403 forbidden有二种原因,一是缺少索引文件,二权限问题.今天又遇到 了,顺便总结一下. 1,缺少index.html或者i ...
- HashTable类
HashTable类不紧可以像Vector类一样动态的存储一系列的对象,而且对存储的每一个对象(称为值)都安排另一个对象(称为关键字)与它相关联. 用做关键字的类必须覆盖Object.hashCode ...
- mac os下android 通过battery-historian进行电量分析
简单介绍下如何用battery-historian进行电量分析,因为battery-hostorian是基于go语言的框架,所以需要安装go 1.安装go 2.配置go环境变量到.bash_profi ...
- Nucleus PLUS简单介绍
近些年来,随着嵌入式系统飞速的发展,嵌入式实时操作系统广泛地应用在制造工业.过程控制.通讯.仪器仪表.汽车.船舶.航空航天.军事.装备.消费类产 品等方面.今天嵌入式系统带来的工业年产值超过了1万亿美 ...