第四章:用Python对用户的评论数据进行情感倾向分析
本文可以学习到以下内容:
- 使用 pandas 中的 read_sql 读取 sqlite 中的数据
- 使用飞浆模型 senta_bilstm 对评论数据进行情感分析
- 使用飞浆模型 lac 对评论数据进行分词
- 使用 groupby+agg 方法统计评论主题中消极和积极用户分布
- 使用 value_counts 方法统计整体评论分布情况
- 使用 pyecharts 绘制柱状图、词云图
项目背景
1、用模型判断用户评论信息的情感态度,分析消极和积极的占比
2、用分词模型对评论内容进行切分,分析客户关注的重点
获取数据
import os
import pandas as pd
import numpy as np
from sqlalchemy import create_engine
# 数据库地址:数据库放在上一级目录下
db_path = os.path.join(os.path.dirname(os.getcwd()), "data.db")
engine_path = "sqlite:///" + db_path
# 创建数据库引擎
engine = create_engine(engine_path)
sql = """
select
a.user_id
,a.username
,a.age
,b.content
--,b.sentiment_value
,b.create_time
,b.subject
from
users as a
left join
comment as b
on a.user_id=b.user_id
"""
df = pd.read_sql(sql, engine)
df.sample(5)

数据解释:
user_id:用户id
username:用户名
age:年龄
content:评论内容
sentiment_value:情感值【0消极,1积极,-1未知】(用飞浆重写训练得到情感值)
create_time:评论时间
subject:评论主题
情感倾向
使用百度飞浆(paddlepaddle)模型库中的情感分析模型,将评论数据(content)转化为情感类别【积极1,消极0】
senta_bilstm 模型
一、window10+anaconda3的安装命令:
conda install paddlepaddle==2.2.1 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/
二、安装预训练模型应用工具 PaddleHub
pip install paddlehub==2.0.0
import paddlehub as hub
# 加载模型
senta = hub.Module(name="senta_bilstm")
# 评论数据列表
test_text = df["content"].tolist()
# 模型返回的结果
results = senta.sentiment_classify(texts=test_text, use_gpu=False, batch_size=1)
情感划分
将 negative_probs>=0.7 的定义为消极
# 将返回的结果转为 dataframe 数据,并拼接到原始数据中
results_df = pd.DataFrame(results)
df2 = pd.concat([df,results_df],axis=1)
# 将 negative_probs>=0.7 的定义为消极
df2["new_sentiment_label"] = df2["negative_probs"].map(lambda x: 0 if x>=0.7 else 1)
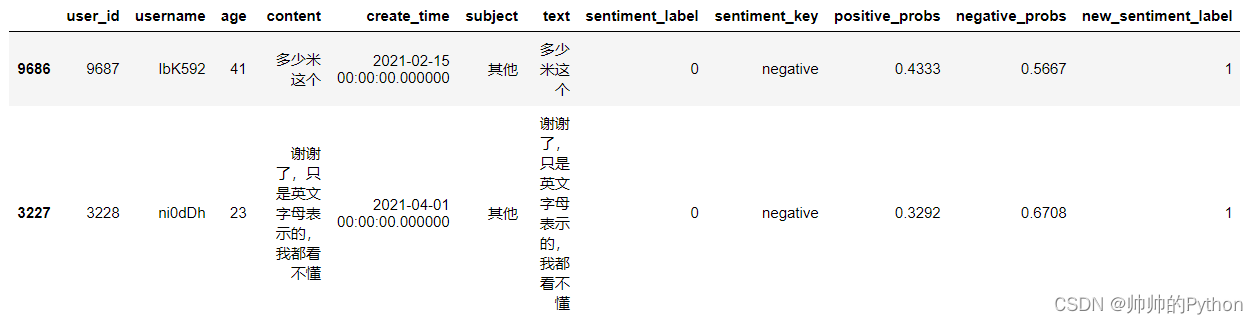
df2[df2["sentiment_label"]!=df2["new_sentiment_label"]].sample(2)
数据描述
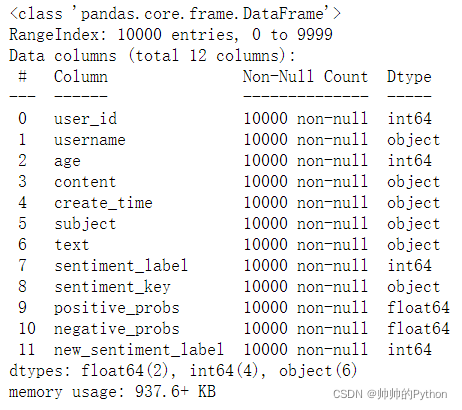
df2.info()
数据分析
总体评论倾向
(df2.new_sentiment_label.value_counts(normalize=True)).map(lambda x:"{:.2%}".format(x))

可以看到,大约 60% 的用户给出好评
评论分布
(df2.subject.value_counts(normalize=True)).map(lambda x:"{:.2%}".format(x))

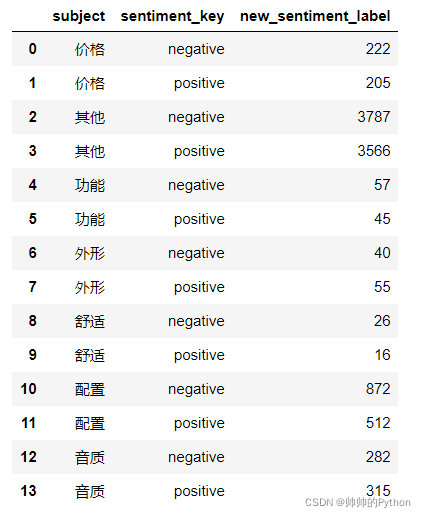
用户的评论内容多集中在配置、音质等主题上
各分布的情感倾向
df2.groupby(by=["subject","sentiment_key"],as_index=False).agg({"new_sentiment_label":"count"})
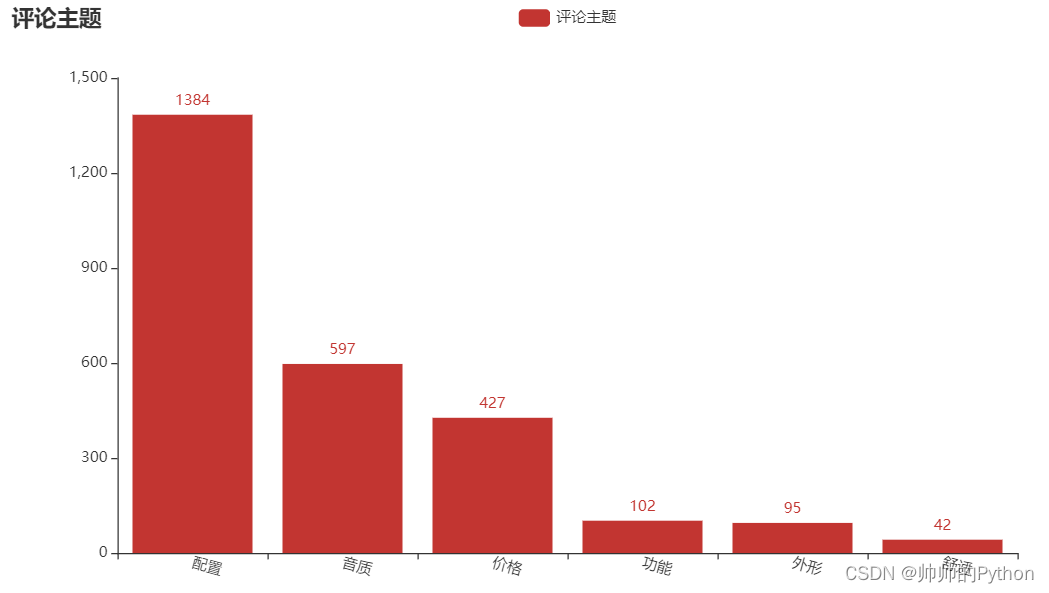
from pyecharts import options as opts
from pyecharts.charts import Bar
x_name = ['配置', '音质', '价格', '功能', '外形', '舒适']
y_value = [1384, 597, 427, 102, 95, 42]
c = (
Bar()
.add_xaxis(x_name)
.add_yaxis("评论分布",y_value)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title="评论分布"),
)
)
c.render_notebook()
评论分词
这里使用百度飞浆的LAC分词模型
import paddlehub as hub
# 加载模型
lac = hub.Module(name="lac")
test_text = df["content"].tolist()
# 模型分词结果
results = lac.cut(text=test_text, use_gpu=False, batch_size=1, return_tag=True)
# 将所有分词保存到一个列表中
result_word_list = []
for result in results:
result_word_list.extend(result["word"])
去除停用词
# 停用词数据
with open("./stop_words.txt","r",encoding="utf-8") as f:
# 用 strip 删除换行符 /n
stop_word_list = [s.strip() for s in f.readlines()]
# 统计每个词出现的次数
word_cloud_dict = {}
for w in result_word_list:
# 如果在停用词中就不统计
if w in stop_word_list:
continue
if w in word_cloud_dict.keys():
word_cloud_dict[w] = word_cloud_dict[w]+1
else:
word_cloud_dict[w] = 1
# 制作词云图的数据
word_cloud_data = sorted(word_cloud_dict.items(),key=lambda x:x[1],reverse=True)
绘制词云图
import pyecharts.options as opts
from pyecharts.charts import WordCloud
word_cloud = (
WordCloud()
.add(series_name="评论热词", data_pair=word_cloud_data, word_size_range=[6, 66])
.set_global_opts(
title_opts=opts.TitleOpts(
title="评论热词", title_textstyle_opts=opts.TextStyleOpts(font_size=23)
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
)
word_cloud.render_notebook()

结论
分析结束后,总结出以下结论:
- 目前耳机用户的好评在60%左右
- 客户反映最多的耳机配置、音质问题
源码地址
链接:https://pan.baidu.com/s/1cnjwcKPu_Ba0gr1n6wNI0A?pwd=l3i1
提取码:l3i1
第四章:用Python对用户的评论数据进行情感倾向分析的更多相关文章
- Python调用百度接口(情感倾向分析)和讯飞接口(语音识别、关键词提取)处理音频文件
本示例的过程是: 1. 音频转文本 2. 利用文本获取情感倾向分析结果 3. 利用文本获取关键词提取 首先是讯飞的语音识别模块.在这里可以找到非实时语音转写的相关文档以及 Python 示例.我略作了 ...
- 吴裕雄--天生自然python学习笔记:WEB数据抓取与分析
Web 数据抓取技术具有非常巨大的应用需求及价值, 用 Python 在网页上收集数据,不仅抓取数据的操作简单, 而且其数据分析功能也十分强大. 通过 Python 的时lib 组件中的 urlpar ...
- 《Python 学习手册4th》 第四章 介绍Python对象类型
''' 时间: 9月5日 - 9月30日 要求: 1. 书本内容总结归纳,整理在博客园笔记上传 2. 完成所有课后习题 注:“#” 后加的是备注内容(每天看42页内容,可以保证月底看完此书) ''' ...
- 第四章:Python基础の快速认识內置函数和操作实战
本課主題 內置函数介紹和操作实战 装饰器介紹和操作实战 本周作业 內置函数介紹和操作实战 返回Boolean值的內置函数 all( ): 接受一個可以被迭代的對象,如果函数裡所有為真,才會真:有一個是 ...
- 第十四章:Python の Web开发基础(一) HTML与CSS
本課主題 HTML 介绍 CSS 介绍 HTML 介绍 HTML 的头部份,重点: 定义HTML 的编码:<meta charset="UTF-8"/> 定义标题: & ...
- 【WPF学习】第六十四章 构建基本的用户控件
创建一个简单用户控件是开始自定义控件的好方法.本章主要介绍创建一个基本的颜色拾取器.接下来分析如何将这个控件分解成功能更强大的基于模板的控件. 创建基本的颜色拾取器很容易.然而,创建自定义颜色拾取器仍 ...
- 【Learning Python】【第四章】Python代码结构(一)
这一章的主旨在于介绍python的代码结构 缩进 在很多的编程语言中,一般{}用于控制代码块,比如以下的一段C代码 if(var <= 10) { printf("....." ...
- Python爬取新浪微博评论数据,写入csv文件中
因为新浪微博网页版爬虫比较困难,故采取用手机网页端爬取的方式 操作步骤如下: 1. 网页版登陆新浪微博 2.打开m.weibo.cn 3.查找自己感兴趣的话题,获取对应的数据接口链接 4.获取cook ...
- [Python学习笔记][第四章Python字符串]
2016/1/28学习内容 第四章 Python字符串与正则表达式之字符串 编码规则 UTF-8 以1个字节表示英语字符(兼容ASCII),以3个字节表示中文及其他语言,UTF-8对全世界所有国家需要 ...
- python全栈开发中级班全程笔记(第二模块、第四章)(常用模块导入)
python全栈开发笔记第二模块 第四章 :常用模块(第二部分) 一.os 模块的 详解 1.os.getcwd() :得到当前工作目录,即当前python解释器所在目录路径 impor ...
随机推荐
- exgcd & 线性同余方程
前置芝士 裴蜀定理 同余的性质 exgcd exgcd即扩展欧几里得定理,常用来求解\(ax + by = gcd(a,b)\)的可行解问题 推导过程: 考虑我们有: \(ax + by = gc ...
- MongoDB Compass的安装及使用图文说明(非常详细)
1.下载 MongoDB Compass 预编译二进制包下载地址:https://www.mongodb.com/try/download/compass 2.安装 MongoDB Compass 的 ...
- day14-异常处理
异常处理 1.基本介绍 SpringMVC 通过 HandlerExceptionResolver 处理程序的异常,包括 Handler映射.数据绑定以及目标方法执行时发生的异常 有两种方案来进行异常 ...
- ClickHouse exception, code: 62, host: hadoop102, port: 8123; Code: 62, e.displayText() = DB::Exception: Syntax error: failed at position 183 (end of query):
报错 ClickHouse exception, code: 62, host: hadoop102, port: 8123; Code: 62, e.displayText() = DB::Exce ...
- [POI2014]HOT-Hotels 加强版
长链剖分优化 \(dp\) 模板 不过这 \(dp\) 真毒 \(\text{Code}\) #include <cstdio> #define RE register #define I ...
- JZOJ 2483. 【GDKOI 2021提高组DAY1】回文(palindrome)
题目 求区间最长回文串长度 \(1 \le n\le 5 \times 10^5\) 题解 比较妙的做法,主要是在询问部分 预处理出以某位为中心回文半径长 \(p_i\),马拉车和二分+哈希均可 然后 ...
- .Net6 Html.Action无法使用(ViewComponents)
接触了 net core的小伙伴们 已经发现 @html.Action()方法 官方已经不提供支持了,转而使用 ViewComponents替代了,同时也增加了TagHelper. 1.如果想用以前的 ...
- .Net 6 使用Log4Net
1.首先引入Log4Net的 Nuget包 第一个就是 2.复制所需配置文件(文件中包含写入文本日志和数据库日志, 自行根据注释选择所需) 取名 log4net.Config <?xml ...
- 基于C++的OpenGL 05 之坐标系统
1. 引言 本文基于C++语言,描述OpenGL的坐标系统 前置知识可参考: 基于C++的OpenGL 04 之变换 - 当时明月在曾照彩云归 - 博客园 (cnblogs.com) 笔者这里不过多描 ...
- LeetCode-1606 找到处理请求最多的服务器
来源:力扣(LeetCode)链接:https://leetcode-cn.com/problems/find-servers-that-handled-most-number-of-requests ...