.NET深入了解哈希表和Dictionary
引子
问题:给定一串数字{1,2,5,7,15,24,33,52},如何在时间复杂度为O(1)下,对数据进行CURD?
数组:我创建一个Length为53的数组,将元素插入相同下标处,是不是就可以实现查找复杂度O(1)了?但是添加修改元素时间复杂度为O(n)了。
链表:添加删除复杂度为O(1),但是查找时间复杂度为O(n)了。
身为.NETer肯定熟练使用Dictionary和HashSet,这两个容器的底层就是HashTable,所以带着对技术浓重的兴趣(面试),所以就从头到尾梳理一下!
理论
链地址法(拉链法)
回到问题本身,我们用数组可以实现查找复杂度为O(1),链表实现添加删除复杂度为O(1),如果我们将两个合起来,不就可以实现增删查都为O(1)了么?如何结合呢?
我们先定义一个数组,长度为7(敲黑板,思考下为什么选7?),将所有元素对7取余,这样所有元素都可以放在数组上了,如下图所示:
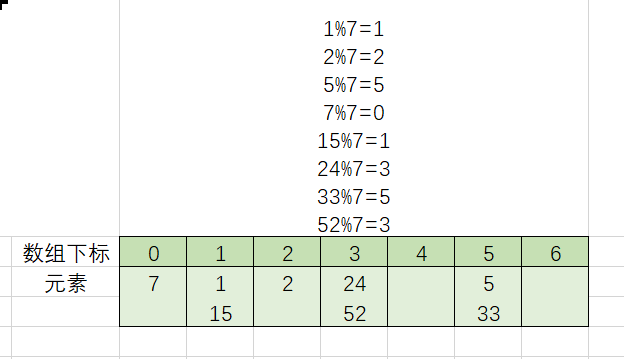
如上图,如果我们将数组中每个下标位置都放成一个链条,这样,复杂度不久降下去了么?
有问题么?没问题。真没问题么?有问题......
注意
插入元素是{0,7,14,21,28}怎么办?这样都落在下标为0的链条里,时间复杂度不又上去了?针对这种情况,隔壁Java将链表优化成了红黑书,我们.NET呢?往下看。
如果我的数组长度不是7,是2怎么办?所有数对2取余,不是1就是0,时间复杂度不又上去了?所以我们对数组长度应该取素数。
如果元素超级多或者特别少,我们的数组长度要固定么?就要动态长度
上边这种方法学名就叫拉链法!
开放地址法
上边我们聊过拉链法(为什么老想着裤子拉链......),拉链法是向下开辟新的空间,如果我们横向开辟空间呢?还是刚才的例子,我们这样搞一下试试。
线性探测法

我们插完7以后,在插24时,发现下标为2的地方有元素了,于是向后移动一位,发现有空位,于是就插进去了。
上边这种方法就是线性探测法!
二次聚集(堆积)
聪明的老鸟们,肯定疑惑啦,如果我们继续添加元素{x%11=4},{y%11=5},此时x,y元素都要往下标6插数据。这样就导致了原始哈希地址不同的元素要插入同一个地址。即添加同义词的冲突过程中又添加了非同义词的冲突。这就是二次聚集。
二次探测法
如果在线性探测法中,我们不依次寻找下一个呢?我们针对"下一个"采取{1 ^ 2,-1 ^ 2,2 ^ 2,-2 ^ 2....}(垃圾编辑器,次方样式乱了)这样的步长呢?真聪明!你已经知道二次探测法了!
这......这还能用么?不都乱了么?下标和元素对不上了呀!怎么去查找元素呢?
别急呀,家人们呐,我们按照这个思路查询就好了:
查找算法步骤
1. 给定待查找的关键字key,获取原始应该插入的下标index
2. 如果原始下标index处,元素为空,则所查找的元素不存在
3. 如果index处的元素等于key,则查找成功
4. 否则重复下述解决冲突的过程
* 按照处理冲突的方法,计算下一个地址nextIndex
* 若nextIndex为空,则查找元素不存在
* 若nextIndex等于关键词key,则查找成功
还有要注意的点么?必须有!
注意(敲重点啦)
- 数组长度必须大于给定元素的长度!
- 当数组元素快装满时,时间复杂度也是O(n)!
- 如果都装满了,就会一直循环找空位,我们应该进行扩容!
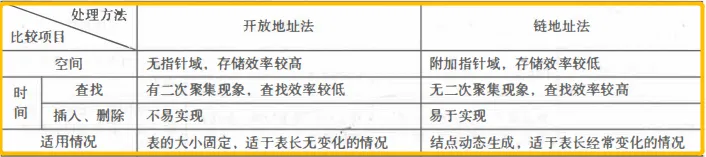
理论小结
接口设计
干活啦,干活啦,领导嫌查询效率太低,让设计一种CURD时间复杂度都为O(n)的数据结构。给了接口。接口如下:
internal interface IDictionary<TK, TV> : IEnumerable<KeyValuePair<TK, TV>>
{
TV this[TK key] { get; set; }
int Count { get; }
/// <summary>
/// 根据key判断元素是否存在
/// </summary>
/// <param name="key"></param>
/// <returns></returns>
bool ContainsKey(TK key);
/// <summary>
/// 添加元素
/// </summary>
/// <param name="key"></param>
/// <param name="value"></param>
void Add(TK key, TV value);
/// <summary>
/// 根据key移除元素
/// </summary>
/// <param name="key"></param>
void Remove(TK key);
/// <summary>
/// 清除
/// </summary>
void Clear();
}
.NET实现线性探测法
实现过程
1. 先来个对象,存储key和value
对象:KeyValuePair
internal class DictionaryKeyValuePair<TK, TV>
{
internal TK Key;
internal TV Value;
internal DictionaryKeyValuePair(TK key, TV value)
{
Key = key;
Value = value;
}
}
2. 来个类OpenAddressDictionary,继承IDictionary接口,就是我们的实现类
实现类:OpenAddressDictionary
/// <summary>
/// 使用线性探测法实现哈希表
/// </summary>
/// <typeparam name="TK"></typeparam>
/// <typeparam name="TV"></typeparam>
public class OpenAddressDictionary<TK, TV> : IDictionary<TK, TV>
{
//创建一个数组,用来存储元素
private DictionaryKeyValuePair<TK, TV>[] hashArray;
//记录已插入元素的数量
public int Count { get; private set; }
public OpenAddressDictionary(int capacity)
{
if (capacity < 0)
throw new ArgumentOutOfRangeException("初始值容量不能小于0");
hashArray = new DictionaryKeyValuePair<TK, TV>[capacity];
}
public TV this[TK key] {
get => throw new System.NotImplementedException();
set => throw new System.NotImplementedException();
}
public void Add(TK key, TV value)
{
throw new System.NotImplementedException();
}
public void Clear()
{
throw new System.NotImplementedException();
}
public System.Boolean ContainsKey(TK key)
{
throw new System.NotImplementedException();
}
public IEnumerator<KeyValuePair<TK, TV>> GetEnumerator()
{
throw new System.NotImplementedException();
}
public void Remove(TK key)
{
throw new System.NotImplementedException();
}
IEnumerator IEnumerable.GetEnumerator()
{
throw new System.NotImplementedException();
}
}
3.如何实现查找?跟着上文查找步骤就行
线性探测:查找
/// <summary>
/// 查找,按照上文线性探测查找步骤
/// </summary>
/// <param name="key"></param>
/// <returns></returns>
public bool ContainsKey(TK key)
{
//1.给定待查找的关键字key,获取原始应该插入的下标index
var hashCode = GetHash(key);
var index = hashCode % hashArray.Length;
//2.如果原始下标index处,元素为空,则所查找的元素不存在
if (hashArray[index] == null) return false;
var current = hashArray[index];//当前元素
/*这个点用来判断是否走了一整圈*/
var hitKey = current.Key;
//4.否则重复下述解决冲突的过程
while (current != null)
{
//3.如果index处的元素等于key,则查找成功
if (current.Key.Equals(key)) return true;
/*这个地方来修改获取下一个元素位置*/
index++;
/*到尾了,但是没有走完一圈*/
if (index == hashArray.Length)
index = 0;
current = hashArray[index];
/*走完一圈了,没找到*/
if (current != null && current.Key.Equals(hitKey)) break;
}
return false;
}
4. 添加
线性探测:添加
/// <summary>
/// 添加元素
/// </summary>
/// <param name="key"></param>
/// <param name="value"></param>
/// <exception cref="Exception"></exception>
public void Add(TK key, TV value)
{
Grow();
//1.获取原始插入位置
var hashCode = GetHash(key);
var index = hashCode % hashArray.Length;
//2.此位置为空,直接插入
if (hashArray[index] == null)
{
hashArray[index] = new DictionaryKeyValuePair<TK, TV>(key, value);
}
//3.坑被占了,去看看下一个
else
{
var current = hashArray[index];
/*这个点用来判断是否走了一整圈*/
var hitKey = current.Key;
while (current != null)
{
if (current.Key.Equals(key)) throw new Exception("重复key");
/*这个地方来修改获取下一个元素位置*/
index++;
/*到尾了,但是没有走完一圈*/
if (index == hashArray.Length)
index = 0;
current = hashArray[index];
/*走完一圈了,没找到空位*/
if (current != null && current.Key.Equals(hitKey)) throw new Exception("容器满了");
}
hashArray[index] = new DictionaryKeyValuePair<TK, TV>(key, value);
}
Count++;
}
/// <summary>
/// 扩容
/// </summary>
private void Grow()
{
/*这个地方判断使用多少扩容*/
if (hashArray.Length * 0.7 <= Count)
{
var orghashArray = hashArray.Length;
var currentArray = hashArray;
/*这个地方改变扩容大小的规则*/
hashArray = new DictionaryKeyValuePair<TK, TV>[hashArray.Length * 2];
for (var i = 0; i < orghashArray; i++)
{
var current = currentArray[i];
/*旧数组中存在元素,添加到新数组中,Add方法会对Count++,所以加入后要Count--*/
if (current != null)
{
Add(current.Key, current.Value);
Count--;
}
}
currentArray = null;
}
}
5. 删除
线性探测:删除
/// <summary>
/// 删除元素key
/// </summary>
/// <param name="key"></param>
/// <exception cref="Exception"></exception>
public void Remove(TK key)
{
//1.获取原始插入位置
var hashCode = GetHash(key);
var curIndex = hashCode % hashArray.Length;
//2.此位置为空,无法删除
if (hashArray[curIndex] == null) throw new Exception("未找到元素key");
var current = hashArray[curIndex];
/*这个点用来判断是否走了一整圈*/
var hitKey = current.Key;
#region 找到待删除元素
DictionaryKeyValuePair<TK, TV> target = null;
while (current != null)
{
if (current.Key.Equals(key))
{
target = current;
break;
}
/*这个地方来修改获取下一个元素位置*/
curIndex++;
/*到尾了,但是没有走完一圈*/
if (curIndex == hashArray.Length)
curIndex = 0;
current = hashArray[curIndex];
/*走完一圈了,没找到空位*/
if (current != null && current.Key.Equals(hitKey)) throw new Exception("No such item for given key");
}
if (target == null)
{
throw new Exception("未找到元素key");
}
#endregion
//删除,将当前位置置空
hashArray[curIndex] = null;
#region 之前讲过删除,造成元素丢失,所以在此处处理
curIndex++;
/*到尾了,但是没有走完一圈*/
if (curIndex == hashArray.Length)
curIndex = 0;
current = hashArray[curIndex];
//直到下一个为空的点,到空说明后边的还没有被线性探测插入污染
while (current != null)
{
//先删除
hashArray[curIndex] = null;
//重新插入
Add(current.Key, current.Value);
Count--;
curIndex++;
/*到尾了,但是没有走完一圈*/
if (curIndex == hashArray.Length)
curIndex = 0;
current = hashArray[curIndex];
}
#endregion
Count--;
Shrink();
}
/// <summary>
/// 减容
/// </summary>
private void Shrink()
{
/*这个地方判断元素在什么程度算少*/
if (Count <= hashArray.Length * 0.3 && hashArray.Length / 2 > 0)
{
var orghashArray = hashArray.Length;
var currentArray = hashArray;
/*这个地方改变扩容大小的规则*/
hashArray = new DictionaryKeyValuePair<TK, TV>[hashArray.Length / 2];
for (var i = 0; i < orghashArray; i++)
{
var current = currentArray[i];
/*旧数组中存在元素,添加到新数组中,Add方法会对Count++,所以加入后要Count--*/
if (current != null)
{
Add(current.Key, current.Value);
Count--;
}
}
currentArray = null;
}
}
最终代码
线性探测:最终代码
/// <summary>
/// 使用线性探测法实现哈希表
/// </summary>
/// <typeparam name="TK"></typeparam>
/// <typeparam name="TV"></typeparam>
public class OpenAddressDictionary<TK, TV> : IDictionary<TK, TV>
{
//创建一个数组,用来存储元素
private DictionaryKeyValuePair<TK, TV>[] hashArray;
//记录已插入元素的数量
public int Count { get; private set; }
public TV this[TK key]
{
get => GetValue(key);
set => SetValue(key, value);
}
public OpenAddressDictionary(int capacity)
{
if (capacity < 0)
throw new ArgumentOutOfRangeException("初始值容量不能小于0");
hashArray = new DictionaryKeyValuePair<TK, TV>[capacity];
}
/// <summary>
/// 清除最简单
/// </summary>
public void Clear()
{
if (Count > 0)
Array.Clear(hashArray, 0, hashArray.Length);
}
/// <summary>
/// 查找,按照上文线性探测查找步骤
/// </summary>
/// <param name="key"></param>
/// <returns></returns>
public bool ContainsKey(TK key)
{
//1.给定待查找的关键字key,获取原始应该插入的下标index
var hashCode = GetHash(key);
var index = hashCode % hashArray.Length;
//2.如果原始下标index处,元素为空,则所查找的元素不存在
if (hashArray[index] == null) return false;
var current = hashArray[index];//当前元素
/*这个点用来判断是否走了一整圈*/
var hitKey = current.Key;
//4.否则重复下述解决冲突的过程
while (current != null)
{
//3.如果index处的元素等于key,则查找成功
if (current.Key.Equals(key)) return true;
/*这个地方来修改获取下一个元素位置*/
index++;
/*到尾了,但是没有走完一圈*/
if (index == hashArray.Length)
index = 0;
current = hashArray[index];
/*走完一圈了,没找到*/
if (current != null && current.Key.Equals(hitKey)) break;
}
return false;
}
/// <summary>
/// 添加元素
/// </summary>
/// <param name="key"></param>
/// <param name="value"></param>
/// <exception cref="Exception"></exception>
public void Add(TK key, TV value)
{
Grow();
//1.获取原始插入位置
var hashCode = GetHash(key);
var index = hashCode % hashArray.Length;
//2.此位置为空,直接插入
if (hashArray[index] == null)
{
hashArray[index] = new DictionaryKeyValuePair<TK, TV>(key, value);
}
//3.坑被占了,去看看下一个
else
{
var current = hashArray[index];
/*这个点用来判断是否走了一整圈*/
var hitKey = current.Key;
while (current != null)
{
if (current.Key.Equals(key)) throw new Exception("重复key");
/*这个地方来修改获取下一个元素位置*/
index++;
/*到尾了,但是没有走完一圈*/
if (index == hashArray.Length)
index = 0;
current = hashArray[index];
/*走完一圈了,没找到空位*/
if (current != null && current.Key.Equals(hitKey)) throw new Exception("容器满了");
}
hashArray[index] = new DictionaryKeyValuePair<TK, TV>(key, value);
}
Count++;
}
/// <summary>
/// 删除元素key
/// </summary>
/// <param name="key"></param>
/// <exception cref="Exception"></exception>
public void Remove(TK key)
{
//1.获取原始插入位置
var hashCode = GetHash(key);
var curIndex = hashCode % hashArray.Length;
//2.此位置为空,无法删除
if (hashArray[curIndex] == null) throw new Exception("未找到元素key");
var current = hashArray[curIndex];
/*这个点用来判断是否走了一整圈*/
var hitKey = current.Key;
#region 找到待删除元素
DictionaryKeyValuePair<TK, TV> target = null;
while (current != null)
{
if (current.Key.Equals(key))
{
target = current;
break;
}
/*这个地方来修改获取下一个元素位置*/
curIndex++;
/*到尾了,但是没有走完一圈*/
if (curIndex == hashArray.Length)
curIndex = 0;
current = hashArray[curIndex];
/*走完一圈了,没找到空位*/
if (current != null && current.Key.Equals(hitKey)) throw new Exception("No such item for given key");
}
if (target == null)
{
throw new Exception("未找到元素key");
}
#endregion
//删除,将当前位置置空
hashArray[curIndex] = null;
#region 之前讲过删除,造成元素丢失,所以在此处处理
curIndex++;
/*到尾了,但是没有走完一圈*/
if (curIndex == hashArray.Length)
curIndex = 0;
current = hashArray[curIndex];
//直到下一个为空的点,到空说明后边的还没有被线性探测插入污染
while (current != null)
{
//先删除
hashArray[curIndex] = null;
//重新插入
Add(current.Key, current.Value);
Count--;
curIndex++;
/*到尾了,但是没有走完一圈*/
if (curIndex == hashArray.Length)
curIndex = 0;
current = hashArray[curIndex];
}
#endregion
Count--;
Shrink();
}
/// <summary>
/// 扩容
/// </summary>
private void Grow()
{
/*这个地方判断使用多少扩容*/
if (hashArray.Length * 0.7 <= Count)
{
var orghashArray = hashArray.Length;
var currentArray = hashArray;
/*这个地方改变扩容大小的规则*/
hashArray = new DictionaryKeyValuePair<TK, TV>[hashArray.Length * 2];
for (var i = 0; i < orghashArray; i++)
{
var current = currentArray[i];
/*旧数组中存在元素,添加到新数组中,Add方法会对Count++,所以加入后要Count--*/
if (current != null)
{
Add(current.Key, current.Value);
Count--;
}
}
currentArray = null;
}
}
/// <summary>
/// 减容
/// </summary>
private void Shrink()
{
/*这个地方判断元素在什么程度算少*/
if (Count <= hashArray.Length * 0.3 && hashArray.Length / 2 > 0)
{
var orghashArray = hashArray.Length;
var currentArray = hashArray;
/*这个地方改变扩容大小的规则*/
hashArray = new DictionaryKeyValuePair<TK, TV>[hashArray.Length / 2];
for (var i = 0; i < orghashArray; i++)
{
var current = currentArray[i];
/*旧数组中存在元素,添加到新数组中,Add方法会对Count++,所以加入后要Count--*/
if (current != null)
{
Add(current.Key, current.Value);
Count--;
}
}
currentArray = null;
}
}
private void SetValue(TK key, TV value)
{
var index = GetHash(key) % hashArray.Length;
if (hashArray[index] == null)
{
Add(key, value);
}
else
{
var current = hashArray[index];
var hitKey = current.Key;
while (current != null)
{
if (current.Key.Equals(key))
{
Remove(key);
Add(key, value);
return;
}
index++;
//wrap around
if (index == hashArray.Length)
index = 0;
current = hashArray[index];
//reached original hit again
if (current != null && current.Key.Equals(hitKey)) throw new Exception("Item not found");
}
}
throw new Exception("Item not found");
}
private TV GetValue(TK key)
{
var index = GetHash(key) % hashArray.Length;
if (hashArray[index] == null) throw new Exception("Item not found");
var current = hashArray[index];
var hitKey = current.Key;
while (current != null)
{
if (current.Key.Equals(key)) return current.Value;
index++;
//wrap around
if (index == hashArray.Length)
index = 0;
current = hashArray[index];
//reached original hit again
if (current != null && current.Key.Equals(hitKey)) throw new Exception("Item not found");
}
throw new Exception("Item not found");
}
private int GetHash(TK key)
{
return Math.Abs(key.GetHashCode());
}
IEnumerator IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
//迭代器就不写了,想了解看我博客容器栏目
public IEnumerator<KeyValuePair<TK, TV>> GetEnumerator()
{
throw new System.NotImplementedException();
}
}
internal class DictionaryKeyValuePair<TK, TV>
{
internal TK Key;
internal TV Value;
internal DictionaryKeyValuePair(TK key, TV value)
{
Key = key;
Value = value;
}
}
.NET实现拉链法
实现过程
回想一下,上边的拉链法,每个下标位置放置的是一个链条,所以我们先实现一个双向链表
1. 实现一个双向链表
拉链法:构建双向链表
internal class DLinkedNode<T>
{
public T Data;
public DLinkedNode<T> Next;
public DLinkedNode<T> Previous;
public DLinkedNode(T data)
{
Data = data;
}
}
2. 创建一个拉链法实体类
拉链法:实现类
/// <summary>
/// 拉链法:实现类
/// </summary>
/// <typeparam name="TK"></typeparam>
/// <typeparam name="TV"></typeparam>
internal class SeparateChainingDictionary<TK, TV>:IDictionary<TK, TV>
{
//构建一个数组,数组每个节点都是链表
private DLinkedNode<KeyValuePair<TK, TV>>[] hashArray;
//已使用数组下标个数
private int filledBuckets;
public SeparateChainingDictionary(int capacity) {
if (capacity < 0)
throw new ArgumentOutOfRangeException("初始值容量不能小于0");
hashArray = new DLinkedNode<KeyValuePair<TK, TV>>[capacity];
}
public TV this[TK key] {
get => throw new NotImplementedException();
set => throw new NotImplementedException();
}
public int Count => throw new NotImplementedException();
public void Add(TK key, TV value)
{
throw new NotImplementedException();
}
public void Clear()
{
throw new NotImplementedException();
}
public bool ContainsKey(TK key)
{
throw new NotImplementedException();
}
public void Remove(TK key)
{
throw new NotImplementedException();
}
public IEnumerator<KeyValuePair<TK, TV>> GetEnumerator()
{
throw new NotImplementedException();
}
IEnumerator IEnumerable.GetEnumerator()
{
throw new NotImplementedException();
}
}
3. 拉链法:查找
拉链法:查找
/// <summary>
/// 查找
/// </summary>
/// <param name="key"></param>
/// <returns></returns>
public bool ContainsKey(TK key)
{
/*1.获取原始下标*/
var index = Math.Abs(key.GetHashCode()) % hashArray.Length;
/*2.为空即无*/
if (hashArray[index] == null) return false;
var current = hashArray[index];
/*3.遍历链表*/
while (current != null)
{
if (current.Data.Key.Equals(key)) return true;
current = current.Next;
}
return false;
}
4. 拉链法:添加
拉链法:添加
/// <summary>
/// 添加
/// </summary>
/// <param name="key"></param>
/// <param name="value"></param>
/// <exception cref="Exception"></exception>
public void Add(TK key, TV value)
{
Grow();
var index = Math.Abs(key.GetHashCode()) % hashArray.Length;
if (hashArray[index] == null)
{
hashArray[index] = new DLinkedNode<KeyValuePair<TK, TV>>(new KeyValuePair<TK, TV>(key, value));
filledBuckets++;
}
else
{
var current = hashArray[index];
while (current != null && current.Next != null)
{
/*此处可以判断是重复修改,还是抛异常*/
if (current.Data.Key.Equals(key)) throw new Exception("重复key");
current = current.Next;
}
if (current.Data.Key.Equals(key)) throw new Exception("重复key");
current.Next = new DLinkedNode<KeyValuePair<TK, TV>>(new KeyValuePair<TK, TV>(key, value));
}
Count++;
}
/// <summary>
/// 扩容
/// </summary>
private void Grow()
{
if (filledBuckets >= hashArray.Length * 0.7)
{
filledBuckets = 0;
var newBucketSize = hashArray.Length * 2;
var biggerArray = new DLinkedNode<KeyValuePair<TK, TV>>[newBucketSize];
for (var i = 0; i < hashArray.Length; i++)
{
var item = hashArray[i];
if (item != null)
{
var current = item;
while (current != null)
{
var next = current.Next;
var newIndex = Math.Abs(current.Data.Key.GetHashCode()) % newBucketSize;
if (biggerArray[newIndex] == null)
{
filledBuckets++;
biggerArray[newIndex] = current;
}
var bItem = biggerArray[newIndex];
while(bItem.Next != null)
bItem = bItem.Next;
bItem.Next = current;
current = next;
}
}
}
hashArray = biggerArray;
}
}
5. 拉链法:删除
拉链法:删除
public void Remove(TK key)
{
var index = Math.Abs(key.GetHashCode()) % hashArray.Length;
if (hashArray[index] == null) throw new Exception("未找到key");
var current = hashArray[index];
/*查找待删除元素*/
DLinkedNode<KeyValuePair<TK, TV>> item = null;
while (current != null)
{
if (current.Data.Key.Equals(key))
{
item = current;
break;
}
current = current.Next;
}
if (item == null)
{
throw new Exception("未找到key");
}
/*删除*/
if (item.Next == null)
item = null;
else
{
item.Previous = item.Next;
item.Next.Previous =item.Previous ;
item = null;
}
if (hashArray[index] == null)
{
filledBuckets--;
}
Count--;
Shrink();
}
private void Shrink()
{
/*是否减容*/
if (Math.Abs(filledBuckets - hashArray.Length * 0.3) < 0.1 && hashArray.Length / 2 > 0)
{
filledBuckets = 0;
var newBucketSize = hashArray.Length / 2;
var smallerArray = new DLinkedNode<KeyValuePair<TK, TV>>[newBucketSize];
for (var i = 0; i < hashArray.Length; i++)
{
var item = hashArray[i];
if (item != null)
{
var current = item;
/*找到新的存储点*/
while (current != null)
{
var next = current.Next;
var newIndex = Math.Abs(current.Data.Key.GetHashCode()) % newBucketSize;
if (smallerArray[newIndex] == null)
{
filledBuckets++;
smallerArray[newIndex] = current;
}
var newItem = smallerArray[newIndex];
while(newItem.Next != null)
newItem = newItem.Next;
newItem.Next = current;
current = next;
}
}
}
hashArray = smallerArray;
}
}
最终代码
拉链法:最终代码
internal class DLinkedNode<T>
{
public T Data;
public DLinkedNode<T> Next;
public DLinkedNode<T> Previous;
public DLinkedNode(T data)
{
Data = data;
}
}
internal class SeparateChainingDictionary<TK, TV> : IDictionary<TK, TV>
{
//构建一个数组,数组每个节点都是链表
private DLinkedNode<KeyValuePair<TK, TV>>[] hashArray;
//已使用数组下标个数
private int filledBuckets;
public SeparateChainingDictionary(int capacity)
{
if (capacity < 0)
throw new ArgumentOutOfRangeException("初始值容量不能小于0");
hashArray = new DLinkedNode<KeyValuePair<TK, TV>>[capacity];
}
public TV this[TK key]
{
get => throw new NotImplementedException();
set => throw new NotImplementedException();
}
public int Count { get; private set; }
/// <summary>
/// 添加
/// </summary>
/// <param name="key"></param>
/// <param name="value"></param>
/// <exception cref="Exception"></exception>
public void Add(TK key, TV value)
{
Grow();
var index = Math.Abs(key.GetHashCode()) % hashArray.Length;
if (hashArray[index] == null)
{
hashArray[index] = new DLinkedNode<KeyValuePair<TK, TV>>(new KeyValuePair<TK, TV>(key, value));
filledBuckets++;
}
else
{
var current = hashArray[index];
while (current != null && current.Next != null)
{
/*此处可以判断是重复修改,还是抛异常*/
if (current.Data.Key.Equals(key)) throw new Exception("重复key");
current = current.Next;
}
if (current.Data.Key.Equals(key)) throw new Exception("重复key");
current.Next = new DLinkedNode<KeyValuePair<TK, TV>>(new KeyValuePair<TK, TV>(key, value));
}
Count++;
}
/// <summary>
/// 扩容
/// </summary>
private void Grow()
{
if (filledBuckets >= hashArray.Length * 0.7)
{
filledBuckets = 0;
var newBucketSize = hashArray.Length * 2;
var biggerArray = new DLinkedNode<KeyValuePair<TK, TV>>[newBucketSize];
for (var i = 0; i < hashArray.Length; i++)
{
var item = hashArray[i];
if (item != null)
{
var current = item;
while (current != null)
{
var next = current.Next;
var newIndex = Math.Abs(current.Data.Key.GetHashCode()) % newBucketSize;
if (biggerArray[newIndex] == null)
{
filledBuckets++;
biggerArray[newIndex] = current;
}
var bItem = biggerArray[newIndex];
while(bItem.Next != null)
bItem = bItem.Next;
bItem.Next = current;
current = next;
}
}
}
hashArray = biggerArray;
}
}
public void Clear()
{
throw new NotImplementedException();
}
/// <summary>
/// 查找
/// </summary>
/// <param name="key"></param>
/// <returns></returns>
public bool ContainsKey(TK key)
{
/*1.获取原始下标*/
var index = Math.Abs(key.GetHashCode()) % hashArray.Length;
/*2.为空即无*/
if (hashArray[index] == null) return false;
var current = hashArray[index];
/*3.遍历链表*/
while (current != null)
{
if (current.Data.Key.Equals(key)) return true;
current = current.Next;
}
return false;
}
public void Remove(TK key)
{
var index = Math.Abs(key.GetHashCode()) % hashArray.Length;
if (hashArray[index] == null) throw new Exception("未找到key");
var current = hashArray[index];
/*查找待删除元素*/
DLinkedNode<KeyValuePair<TK, TV>> item = null;
while (current != null)
{
if (current.Data.Key.Equals(key))
{
item = current;
break;
}
current = current.Next;
}
if (item == null)
{
throw new Exception("未找到key");
}
/*删除*/
if (item.Next == null)
item = null;
else
{
item.Previous = item.Next;
item.Next.Previous =item.Previous ;
item = null;
}
if (hashArray[index] == null)
{
filledBuckets--;
}
Count--;
Shrink();
}
private void Shrink()
{
/*是否减容*/
if (Math.Abs(filledBuckets - hashArray.Length * 0.3) < 0.1 && hashArray.Length / 2 > 0)
{
filledBuckets = 0;
var newBucketSize = hashArray.Length / 2;
var smallerArray = new DLinkedNode<KeyValuePair<TK, TV>>[newBucketSize];
for (var i = 0; i < hashArray.Length; i++)
{
var item = hashArray[i];
if (item != null)
{
var current = item;
/*找到新的存储点*/
while (current != null)
{
var next = current.Next;
var newIndex = Math.Abs(current.Data.Key.GetHashCode()) % newBucketSize;
if (smallerArray[newIndex] == null)
{
filledBuckets++;
smallerArray[newIndex] = current;
}
var newItem = smallerArray[newIndex];
while(newItem.Next != null)
newItem = newItem.Next;
newItem.Next = current;
current = next;
}
}
}
hashArray = smallerArray;
}
}
public IEnumerator<KeyValuePair<TK, TV>> GetEnumerator()
{
throw new NotImplementedException();
}
IEnumerator IEnumerable.GetEnumerator()
{
throw new NotImplementedException();
}
}
Dictionary源码分析
模拟实现:一个Dictionary,存储数据{1,'a'},{'4','b'},{5,'c'}
1. 创建一个单链表,用来存储K-V
private struct Entry
{
public uint hashCode;
//值为-1,表示是该链条最后一个节点
//值小于-1,表示已经被删除的自由节点
public int next;
public TKey key; // Key of entry
public TValue value; // Value of entry
}
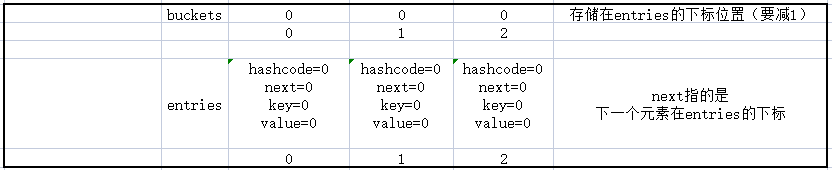
2. 创建一个数组当桶,还有一个链表数组(核心就这两个数组)
private int[]? _buckets;
private Entry[]? _entries;
3. 模拟实现插入{1,'a'},{'4','b'},{5,'c'}
初始化
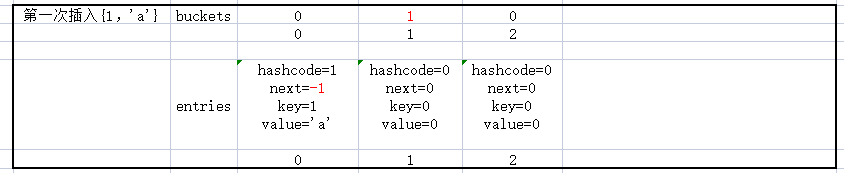
第一次插入{1,'a'}
第二次插入{'4','b'}
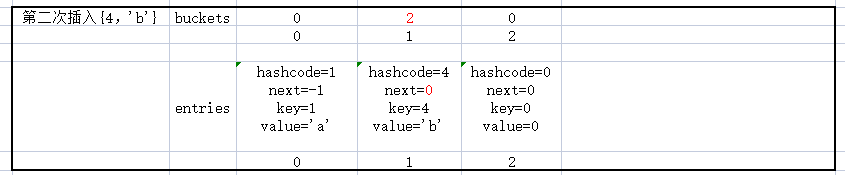
第三次插入{5,'c'}
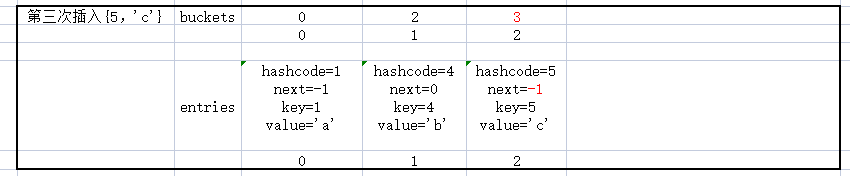
仔细看一下这三个数据的插入,及数据的变化,应该可以理解_buckets和_entries的关系
4.删除
上边再讲哈希表,包括我们自己实现的代码中,删除一个节点后,都要重新计算后边的位置。如何解决这个问题呢?我们可以使用Entry的next,来表示是否已经删除,小于0就表示是自由节点。
关于删除就这样几个变量:
private int _freeList;//最后一个删除的Entry下标
private int _freeCount;//当前已删除,但是还未重新使用的节点数量
private const int StartOfFreeList = -3;//帮助寻找自由节点的一个常量
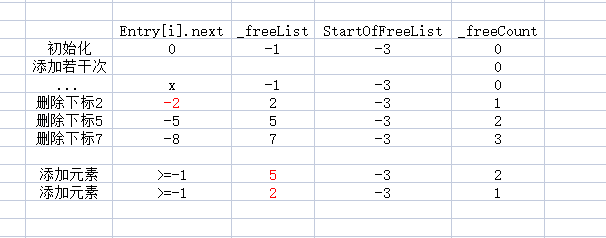
看一下StartOfFreeList和_freeList和Entry.next如何寻找自由节点
- 删除时:Entry[i].next=上一层中的StartOfFreeList-_freeList
- 添加&&_freeCount>0:_freeList=StartOfFreeList - entries[_freeList].next
请看图理解:
源码:简化版(debug理解)
源码:简化版可直接运行
public static void Main(string[] args)
{
Dictionary<int, char> dic = new Dictionary<int, char>();
dic.TryInsert(1, 'a');
dic.TryInsert(4, 'b');
dic.TryInsert(5, 'c');
dic.Remove(4);
dic.Remove(5);
dic.TryInsert(0, 'd');
dic.TryInsert(1, 'e');
}
public class Dictionary<TKey, TValue>
{
private int[]? _buckets;
private Entry[]? _entries;
private int _count;
private int _freeList;
private int _freeCount;
private int _version;
private const int StartOfFreeList = -3;
public Dictionary()
{
/*初始值为素数,这里就不动态了,获取素数可以使用埃及筛选法*/
Initialize(7);
}
private int Initialize(int capacity)
{
int size = capacity;
int[] buckets = new int[size];
Entry[] entries = new Entry[size];
_freeList = -1;
_buckets = buckets;
_entries = entries;
return size;
}
public bool TryInsert(TKey key, TValue value)
{
Entry[]? entries = _entries;
uint hashCode = (uint)key.GetHashCode();
uint collisionCount = 0;
ref int bucket = ref GetBucket(hashCode);
int i = bucket - 1; // Value in _buckets is 1-based
if (typeof(TKey).IsValueType)
{
while (true)
{
if ((uint)i >= (uint)entries.Length)
{
break;
}
if (entries[i].hashCode == hashCode && EqualityComparer<TKey>.Default.Equals(entries[i].key, key))
{
entries[i].value = value;
return true;
}
i = entries[i].next;
collisionCount++;
if (collisionCount > (uint)entries.Length)
{
throw new Exception("");
}
}
}
int index;
if (_freeCount > 0)
{
index = _freeList;
// Debug.Assert((StartOfFreeList - entries[_freeList].next) >= -1, "shouldn't overflow because `next` cannot underflow");
_freeList = StartOfFreeList - entries[_freeList].next;
_freeCount--;
}
else
{
int count = _count;
if (count == entries.Length)
{
//Resize();
bucket = ref GetBucket(hashCode);
}
index = count;
_count = count + 1;
entries = _entries;
}
ref Entry entry = ref entries![index];
entry.hashCode = hashCode;
entry.next = bucket - 1; // Value in _buckets is 1-based
entry.key = key;
entry.value = value; // Value in _buckets is 1-based
bucket = index + 1;
_version++;
return true;
}
public bool Remove(TKey key)
{
if (key == null) return false;
if (_buckets != null)
{
uint collisionCount = 0;
uint hashCode = (uint)key.GetHashCode();
ref int bucket = ref GetBucket(hashCode);
Entry[]? entries = _entries;
int last = -1;
int i = bucket - 1; // Value in buckets is 1-based
while (i >= 0)
{
ref Entry entry = ref entries[i];
if (entry.hashCode == hashCode && EqualityComparer<TKey>.Default.Equals(entry.key, key))
{
if (last < 0)
{
bucket = entry.next + 1;
}
else
{
entries[last].next = entry.next;
}
entry.next = StartOfFreeList - _freeList;
entry.key = default!;
entry.value = default!;
_freeList = i;
_freeCount++;
return true;
}
last = i;
i = entry.next;
collisionCount++;
if (collisionCount > (uint)entries.Length)
{
}
}
}
return false;
}
private ref int GetBucket(uint hashCode)
{
int[] buckets = _buckets!;
return ref buckets[hashCode % (uint)buckets.Length];
}
private struct Entry
{
public uint hashCode;
//值为-1,表示是该链条最后一个节点
public int next;
public TKey key; // Key of entry
public TValue value; // Value of entry
}
.NET深入了解哈希表和Dictionary的更多相关文章
- Swift4 基本数据类型(范围型, Stride型, 数组, 字符串, 哈希表)
创建: 2018/02/28 完成: 2018/03/04 更新: 2018/05/03 给主要标题加上英语, 方便页内搜索 [任务表]TODO 范围型(Range)与Stride型 与范围运算符相 ...
- 索引器、哈希表Hashtabl、字典Dictionary(转)
一.索引器 索引器类似于属性,不同之处在于它们的get访问器采用参数.要声明类或结构上的索引器,使用this关键字. 示例: 索引器示例代码 /// <summary> /// 存储星 ...
- C#中哈希表(HashTable)的用法详解以及和Dictionary比较
1. 哈希表(HashTable)简述 在.NET Framework中,Hashtable是System.Collections命名空间提供的一个容器,用于处理和表现类似keyvalue的键值对, ...
- [译]聊聊C#中的泛型的使用(新手勿入) Seaching TreeVIew WPF 可编辑树Ztree的使用(包括对后台数据库的增删改查) 字段和属性的区别 C# 遍历Dictionary并修改其中的Value 学习笔记——异步 程序员常说的「哈希表」是个什么鬼?
[译]聊聊C#中的泛型的使用(新手勿入) 写在前面 今天忙里偷闲在浏览外文的时候看到一篇讲C#中泛型的使用的文章,因此加上本人的理解以及四级没过的英语水平斗胆给大伙进行了翻译,当然在翻译的过程中发 ...
- 从Dictionary源码看哈希表
一.基本概念 哈希:哈希是一种查找算法,在关键字和元素的存储地址之间建立一个确定的对应关系,每个关键字对应唯一的存储地址,这些存储地址构成了有限.连续的存储地址. 哈希函数:在关键字和元素的存储地址之 ...
- python数据结构与算法——哈希表
哈希表 学习笔记 参考翻译自:<复杂性思考> 及对应的online版本:http://greenteapress.com/complexity/html/thinkcomplexity00 ...
- 哈希表--HashSet<T>
.Net3.5之后出现了HashSet<T>,硬翻译过来就是“哈希集合”,跟“哈希”两字挂钩说明这种集合的内部实现用到了哈希算法,用Reflector工具就可以发现,HashSet< ...
- C#中哈希表与List的比较
简单概念 在c#中,List是顺序线性表(非链表),用一组地址连续的存储单元依次存储数据元素的线性结构. 哈希表也叫散列表,是一种通过把关键码值映射到表中一个位置来访问记录的数据结构.c#中的哈希表有 ...
- 哈希,哈希表,哈希Map
数组: 数组存储区间是连续的,占用内存严重,故空间复杂的很大.但数组的二分查找时间复杂度小,为O(1):数组的特点是:寻址容易,插入和删除困难: 链表: 链表存储区间离散,占用内存比较宽松,故空间复杂 ...
- HashMap/HashSet,hashCode,哈希表
hash code.equals和“==”三者的关系 1) 对象相等则hashCode一定相等: 2) hashCode相等对象未必相等. == 是比较地址是否相等,JAVA中声明变量都是引用嘛,不同 ...
随机推荐
- Html飞机大战(五):主角登场(英雄类编辑)
好家伙, 遇到了一些非常奇怪的bug index.html:179 Uncaught TypeError: Failed to execute 'drawImage' on 'CanvasRender ...
- 第三十七篇:JS基础(this)
好家伙, 解析器(浏览器)在调用函数是每次都会响函数内部传递进一个隐含的参数, 这个隐含参数就是this,this指向的是一个对象,由浏览器传过来 这个对象我们成为函数执行的上下文对象 根据函数的调用 ...
- Python 爬取网站数据
一.使用request库实现批量下载HTML 二.使用BeautifulSoup库实现html解析 官网:https://beautifulsoup.readthedocs.io/zh_CN/v4.4 ...
- class 中的 构造方法、static代码块、私有/公有/静态/实例属性、继承 ( extends、constructor、super()、static、super.prop、#prop、get、set )
part 1 /** * << class 中的 static 代码块与 super.prop 的使用 * * - ...
- 刨析一下C++构造析构函数能不能声明为虚函数的背后机理?
以下内容为本人的著作,如需要转载,请声明原文链接微信公众号「englyf」https://www.cnblogs.com/englyf/p/16631774.html 先说结论: 构造函数不能声明为虚 ...
- Android平台摄像头/屏幕/外部数据采集及RTMP推送接口设计描述
好多开发者提到,为什么大牛直播SDK的Android平台RTMP推送接口怎么这么多?不像一些开源或者商业RTMP推送一样,就几个接口,简单明了. 不解释,以Android平台RTMP推送模块常用接口, ...
- Java 多线程:基础
Java 多线程:基础 作者:Grey 原文地址: 博客园:Java 多线程:基础 CSDN:Java 多线程:基础 顺序.并行与并发 顺序(sequential)用于表示多个操作『依次』处理.比如把 ...
- 在UniApp的H5项目中,生成二维码和扫描二维码的操作处理
在我们基于UniApp的H5项目中,需要生成一些二维码进行展示,另外也需要让用户可以扫码进行一定的快捷操作,本篇随笔介绍一下二维码的生成处理和基于H5的扫码进行操作.二维码的生成,使用了JS文件wea ...
- day03-2无异常退出
多用户即时通讯系统03 4.编码实现02 4.3功能实现-无异常退出系统 4.3.1思路分析 上述代码运行时,在客户端选择退出系统的时候,可以发现程序并没有停止运行,原因是: 退出时,程序将循环标志l ...
- 我的 Kafka 旅程 - broker
broker在kafka的服务端运行,一台服务器相当于一个broker:每个broker下可以有多个topic,每个topic可以有多个partition,在producer端可以对消息进行分区,每个 ...