IO多路复用的理解/演变过程
目录
阻塞IO
服务端为了处理客户端的连接和请求的数据,写了如下代码。
-
listenfd = socket(); // 打开一个网络通信端口
-
bind(listenfd); // 绑定
-
listen(listenfd); // 监听
-
while(1) {
-
connfd = accept(listenfd); // 阻塞建立连接
-
int n = read(connfd, buf); // 阻塞读数据
-
doSomeThing(buf); // 利用读到的数据做些什么
-
close(connfd); // 关闭连接,循环等待下一个连接
-
}
这段代码会执行得磕磕绊绊,就像这样。

可以看到,服务端的线程阻塞在了两个地方,一个是 accept 函数,一个是 read 函数。
如果再把 read 函数的细节展开,我们会发现其阻塞在了两个阶段。
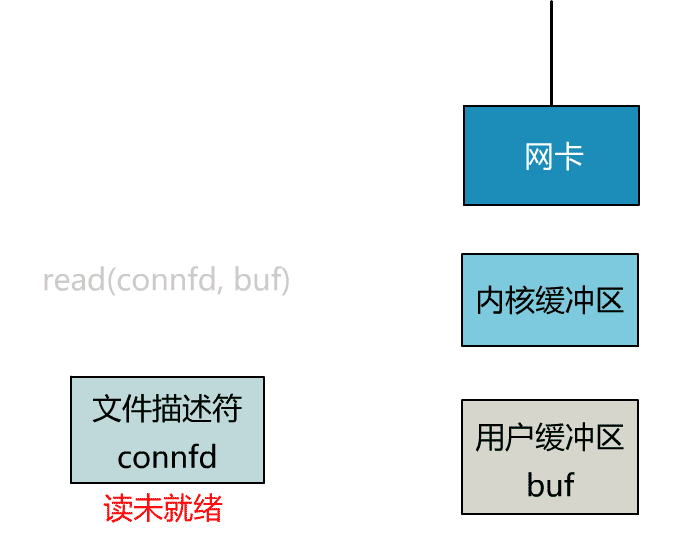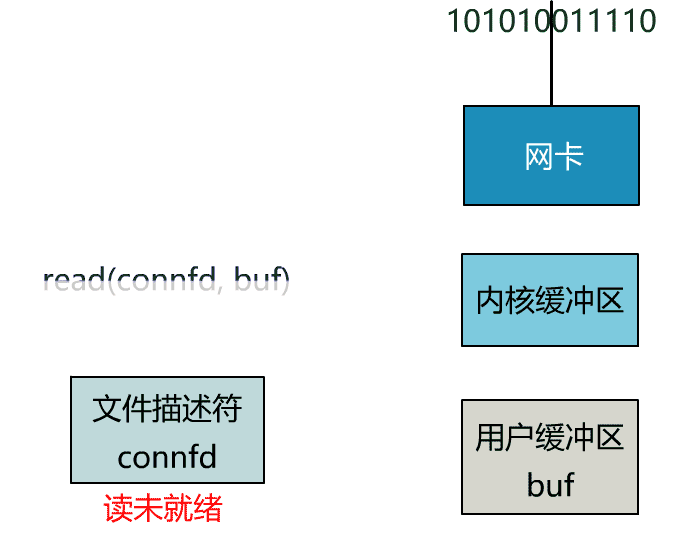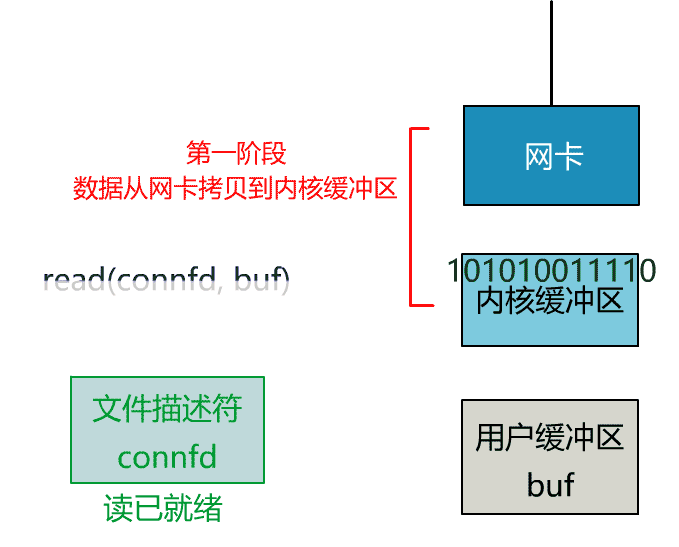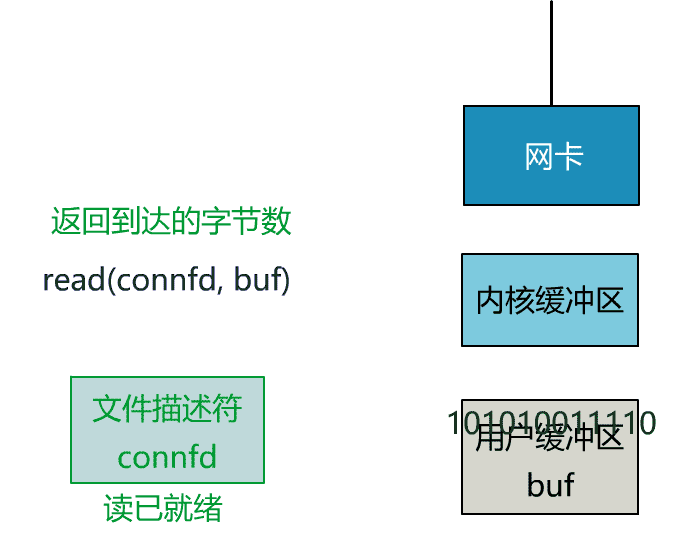
这就是传统的阻塞 IO。
整体流程如下图。

所以,如果这个连接的客户端一直不发数据,那么服务端线程将会一直阻塞在 read 函数上不返回,也无法接受其他客户端连接。
这肯定是不行的。
非阻塞 IO
为了解决上面的问题,其关键在于改造这个 read 函数。
有一种聪明的办法是,每次都创建一个新的进程或线程,去调用 read 函数,并做业务处理。
-
while(1) {
-
connfd = accept(listenfd); // 阻塞建立连接
-
pthread_create(doWork); // 创建一个新的线程
-
}
-
void doWork() {
-
int n = read(connfd, buf); // 阻塞读数据
-
doSomeThing(buf); // 利用读到的数据做些什么
-
close(connfd); // 关闭连接,循环等待下一个连接
-
}
这样,当给一个客户端建立好连接后,就可以立刻等待新的客户端连接,而不用阻塞在原客户端的 read 请求上。

不过,这不叫非阻塞 IO,只不过用了多线程的手段使得主线程没有卡在 read 函数上不往下走罢了。操作系统为我们提供的 read 函数仍然是阻塞的。
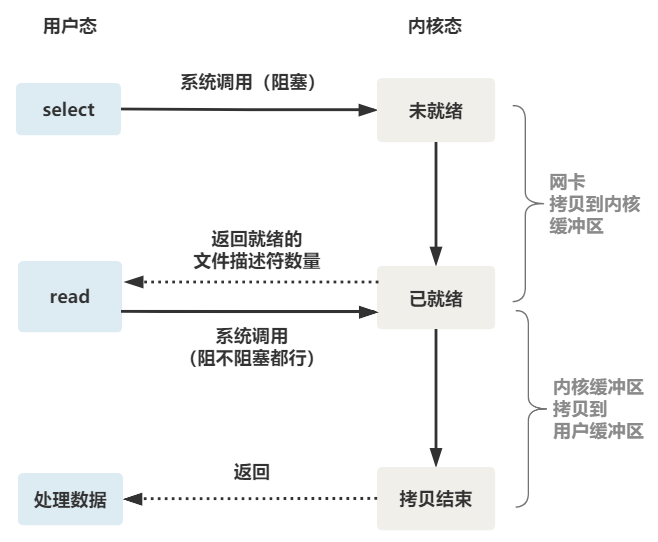
所以真正的非阻塞 IO,不能是通过我们用户层的小把戏,而是要恳请操作系统为我们提供一个非阻塞的 read 函数。
这个 read 函数的效果是,如果没有数据到达时(到达网卡并拷贝到了内核缓冲区),立刻返回一个错误值(-1),而不是阻塞地等待。
操作系统提供了这样的功能,只需要在调用 read 前,将文件描述符设置为非阻塞即可。
-
fcntl(connfd, F_SETFL, O_NONBLOCK);
-
int n = read(connfd, buffer) != SUCCESS);
这样,就需要用户线程循环调用 read,直到返回值不为 -1,再开始处理业务。
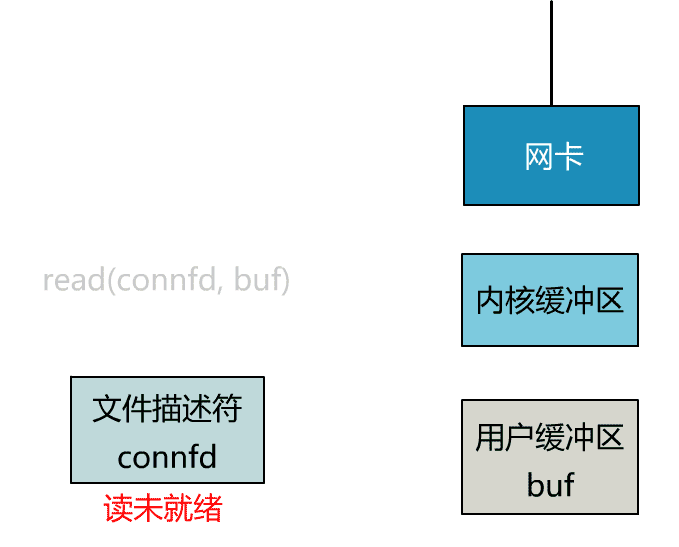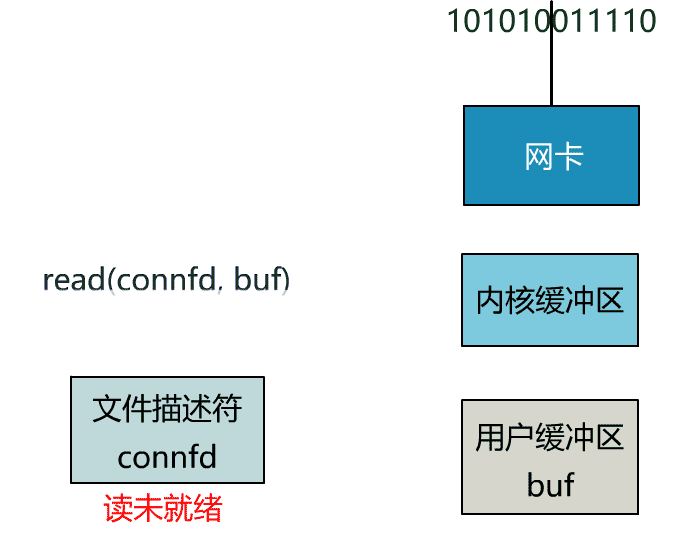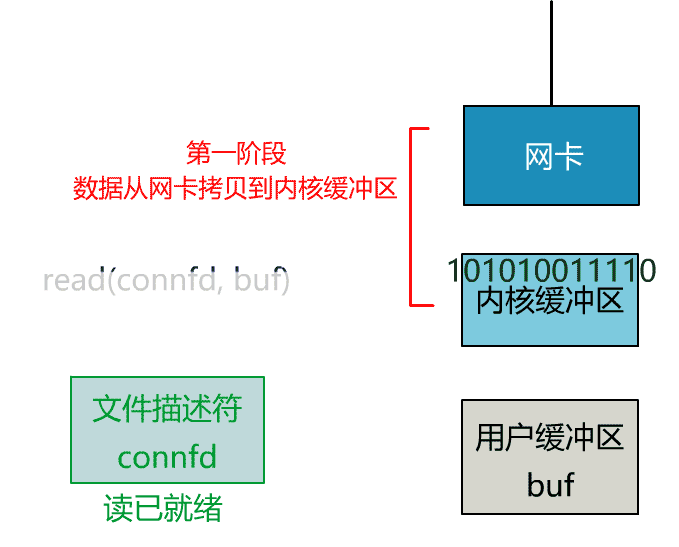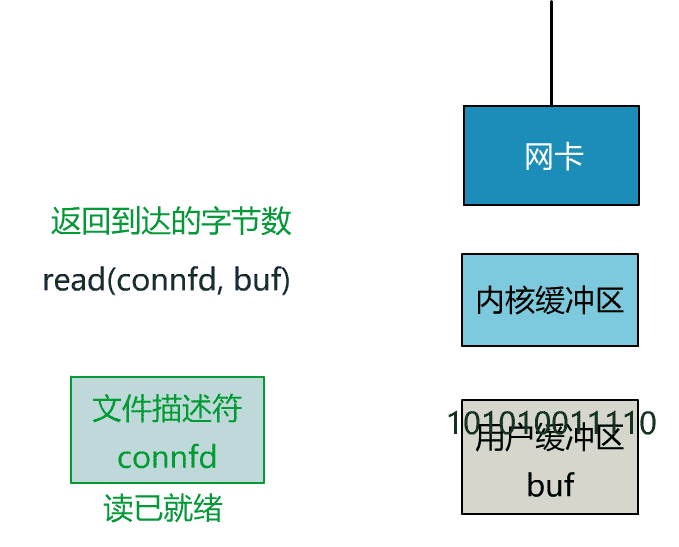
这里我们注意到一个细节。
非阻塞的 read,指的是在数据到达前,即数据还未到达网卡,或者到达网卡但还没有拷贝到内核缓冲区之前,这个阶段是非阻塞的。
当数据已到达内核缓冲区,此时调用 read 函数仍然是阻塞的,需要等待数据从内核缓冲区拷贝到用户缓冲区,才能返回。
整体流程如下图
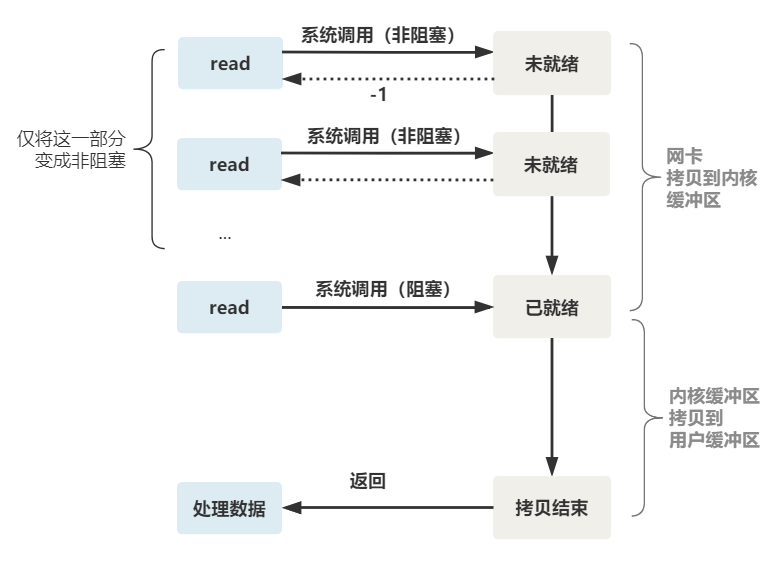
也就是说这不是真正意义上的非阻塞IO。
IO 多路复用
为每个客户端创建一个线程,服务器端的线程资源很容易被耗光。
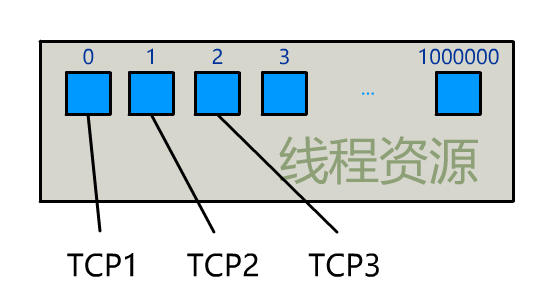
当然还有个聪明的办法,我们可以每 accept 一个客户端连接后,将这个文件描述符(connfd)放到一个数组里。
fdlist.add(connfd);
然后弄一个新的线程去不断遍历这个数组,调用每一个元素的非阻塞 read 方法。
-
while(1) {
-
for(fd <-- fdlist) {
-
if(read(fd) != -1) {
-
doSomeThing();
-
}
-
}
-
}
这样,我们就成功用一个线程处理了多个客户端连接。
你是不是觉得这有些多路复用的意思?
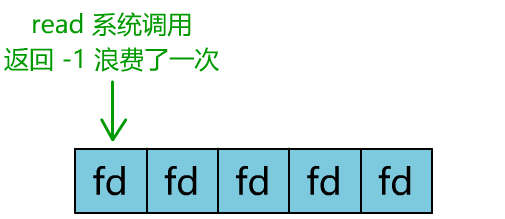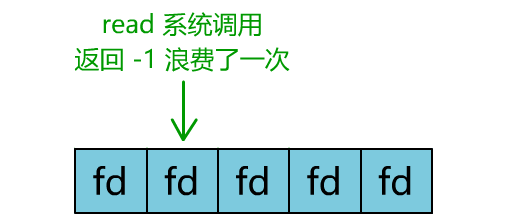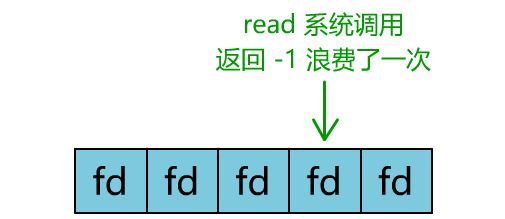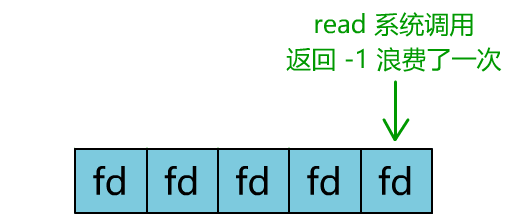
但这和我们用多线程去将阻塞 IO 改造成看起来是非阻塞 IO 一样,这种遍历方式也只是我们用户自己想出的小把戏,每次遍历遇到 read 返回 -1 时仍然是一次浪费资源的系统调用。
所以,还是得恳请操作系统老大,提供给我们一个有这样效果的函数,我们将一批文件描述符通过一次系统调用传给内核,由内核层去遍历(而不是在用户态调用,再陷入到内核态中去遍历),才能真正解决这个问题。
select
select 是操作系统提供的系统调用函数,通过它,我们可以把一个文件描述符的数组发给操作系统, 让操作系统去遍历,确定哪个文件描述符可以读写, 然后告诉我们去处理:
select系统调用的函数定义如下。
-
int select(
-
int nfds,
-
fd_set *readfds,
-
fd_set *writefds,
-
fd_set *exceptfds,
-
struct timeval *timeout);
-
// nfds:监控的文件描述符集里最大文件描述符加1
-
// readfds:监控有读数据到达文件描述符集合,传入传出参数
-
// writefds:监控写数据到达文件描述符集合,传入传出参数
-
// exceptfds:监控异常发生达文件描述符集合, 传入传出参数
-
// timeout:定时阻塞监控时间,3种情况
-
// 1.NULL,永远等下去
-
// 2.设置timeval,等待固定时间
-
// 3.设置timeval里时间均为0,检查描述字后立即返回,轮询
服务端代码,这样来写。
首先一个线程不断接受客户端连接,并把 socket 文件描述符放到一个 list 里。
-
while(1) {
-
connfd = accept(listenfd);
-
fcntl(connfd, F_SETFL, O_NONBLOCK);
-
fdlist.add(connfd);
-
}
然后,另一个线程不再自己遍历,而是调用 select,将这批文件描述符 list 交给操作系统去遍历。
-
while(1) {
-
// 把一堆文件描述符 list 传给 select 函数
-
// 有已就绪的文件描述符就返回,nready 表示有多少个就绪的
-
nready = select(list);
-
...
-
}
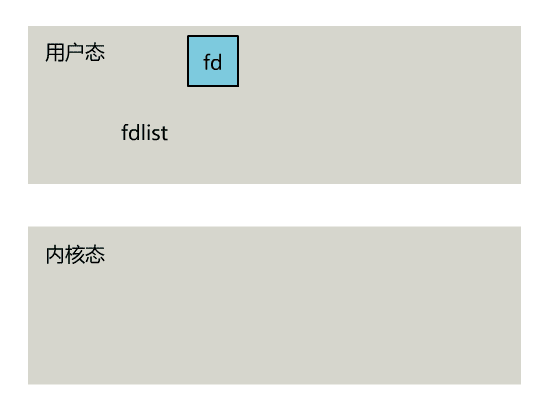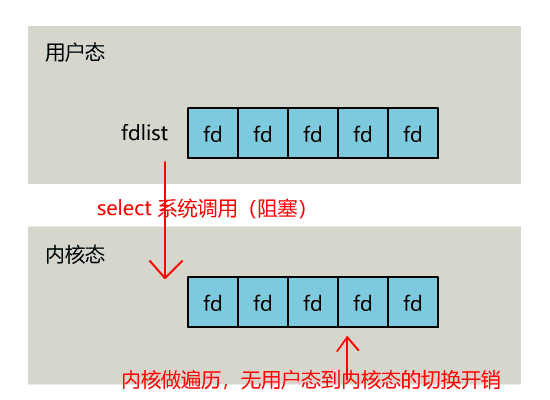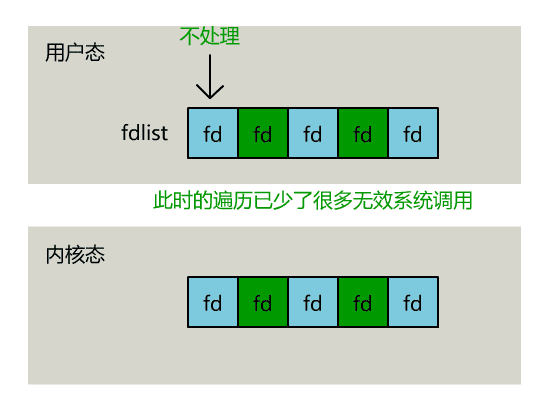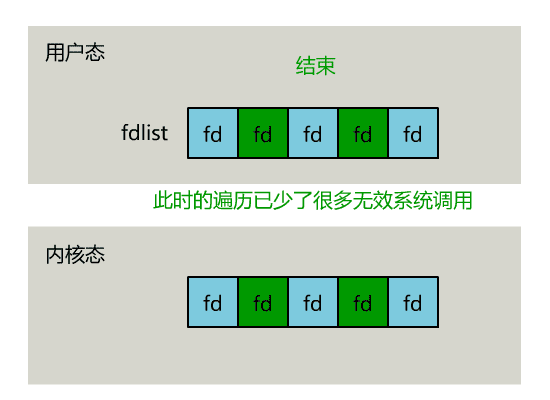
不过,当 select 函数返回后,用户依然需要遍历刚刚提交给操作系统的 list。
只不过,操作系统会将准备就绪的文件描述符做上标识,用户层将不会再有无意义的系统调用开销。
-
while(1) {
-
nready = select(list);
-
// 用户层依然要遍历,只不过少了很多无效的系统调用
-
for(fd <-- fdlist) {
-
if(fd != -1) {
-
// 只读已就绪的文件描述符
-
read(fd, buf);
-
// 总共只有 nready 个已就绪描述符,不用过多遍历
-
if(--nready == 0) break;
-
}
-
}
-
}
可以看出几个细节:
- select 调用需要传入 fd 数组,需要拷贝一份到内核,高并发场景下这样的拷贝消耗的资源是惊人的。(可优化为不复制)
- select 在内核层仍然是通过遍历的方式检查文件描述符的就绪状态,是个同步过程,只不过无系统调用切换上下文的开销。(内核层可优化为异步事件通知)
- select 仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历。(可优化为只返回给用户就绪的文件描述符,无需用户做无效的遍历)
整个 select 的流程图如下。
可以看到,这种方式,既做到了一个线程处理多个客户端连接(文件描述符),又减少了系统调用的开销(多个文件描述符只有一次 select 的系统调用 + n 次就绪状态的文件描述符的 read 系统调用)。
epoll
epoll 是最终的大 boss,它解决了 select 和 poll 的一些问题。
还记得上面说的 select 的三个细节么?epoll 主要就是针对这三点进行了改进。
- 内核中保存一份文件描述符集合,无需用户每次都重新传入,只需告诉内核修改的部分即可。
- 内核不再通过轮询的方式找到就绪的文件描述符,而是通过异步 IO 事件唤醒。
- 内核仅会将有 IO 事件的文件描述符返回给用户,用户也无需遍历整个文件描述符集合。
使用起来,其内部原理就像如下一般丝滑。

总结一下。
一切的开始,都起源于这个 read 函数是操作系统提供的,而且是阻塞的,我们叫它 阻塞 IO。
为了破这个局,程序员在用户态通过多线程来防止主线程卡死。
后来操作系统发现这个需求比较大,于是在操作系统层面提供了非阻塞的 read 函数,这样程序员就可以在一个线程内完成多个文件描述符的读取,这就是 非阻塞 IO。
但多个文件描述符的读取就需要遍历,当高并发场景越来越多时,用户态遍历的文件描述符也越来越多,相当于在 while 循环里进行了越来越多的系统调用。
后来操作系统又发现这个场景需求量较大,于是又在操作系统层面提供了这样的遍历文件描述符的机制,这就是 IO 多路复用。
多路复用有三个函数,最开始是 select,然后又发明了 poll 解决了 select 文件描述符的限制,然后又发明了 epoll 解决 select 的三个不足。
所以,IO 模型的演进,其实就是时代的变化,倒逼着操作系统将更多的功能加到自己的内核而已。
如果你建立了这样的思维,很容易发现网上的一些错误。
比如好多文章说,多路复用之所以效率高,是因为用一个线程就可以监控多个文件描述符。
这显然是知其然而不知其所以然,多路复用产生的效果,完全可以由用户态去遍历文件描述符并调用其非阻塞的 read 函数实现。而多路复用快的原因在于,操作系统提供了这样的系统调用,使得原来的 while 循环里多次系统调用,变成了一次系统调用 + 内核层遍历这些文件描述符。
就好比我们平时写业务代码,把原来 while 循环里调 http 接口进行批量,改成了让对方提供一个批量添加的 http 接口,然后我们一次 rpc 请求就完成了批量添加。
IO多路复用的理解/演变过程的更多相关文章
- IO多路复用的理解
最近看了<后台开发核心技术与应用实践>有关select.poll和epoll部分以及相关的一些博客,学习了这三个函数的使用方法和区别,写一个易理解的总结. IO多路复用 之前程序中使用的I ...
- IO多路复用,同步,异步,阻塞和非阻塞 区别
一.什么是socket?什么是I/O操作? 我们都知道unix(like)世界里,一切皆文件,而文件是什么呢?文件就是一串二进制流而已,不管socket,还是FIFO.管道.终端,对我们来说,一切都是 ...
- IO多路复用之select,poll,epoll个人理解
在看这三个东西之前,先从宏观的角度去看一下,他们的上一个范畴(阻塞IO和非阻塞IO和IO多路复用) 阻塞IO:套接口阻塞(connect的过程是阻塞的).套接口都是阻塞的. 应用程序进程-----re ...
- Python:通过一个小案例深入理解IO多路复用
通过一个小案例深入理解IO多路复用 假如我们现在有这样一个普通的需求,写一个简单的爬虫来爬取校花网的主页 import requests import time start = time.time() ...
- 一文彻底理解IO多路复用
在讲解IO多路复用之前,我们需要预习一下文件以及文件描述符. 什么是文件 程序员使用I/O最终都逃不过文件. 因为这篇同属于高性能.高并发系列,讲到高性能.高并发就离不开Linux/Unix,因此这里 ...
- 深入理解计算机操作系统——12章:多进程,IO多路复用
三种并行的应用程序: 1. 基于进程的并发编程: 2. 基于IO多路复用的并发: 3. 基于线程的并发编程: 12.1 基于进程的并发编程 进程的优劣: (1)进程间共享文件表,但不共享用户地址空间, ...
- IO多路复用?我所理解的IO模式
1:IO的过程 当我们调用系统函数read时,一般会经历两个阶段: 1:等待数据准备(waiting for the data be ready) 2:将数组从内核拷贝到进程(从内核态到用户态)(co ...
- IO多路复用之select总结
1.基本概念 IO多路复用是指内核一旦发现进程指定的一个或者多个IO条件准备读取,它就通知该进程.IO多路复用适用如下场合: (1)当客户处理多个描述字时(一般是交互式输入和网络套接口),必须使用I/ ...
- 【知乎网】Linux IO 多路复用 是什么意思?
提问一: Linux IO多路复用有 epoll, poll, select,知道epoll性能比其他几者要好.也在网上查了一下这几者的区别,表示没有弄明白. IO多路复用是什么意思,在实际的应用中是 ...
随机推荐
- Spring 16: SM(Spring + MyBatis) 注解式事务 与 声明式事务
Spring事务处理方式 方式1:注解式事务 使用@Transactional注解完成事务控制,此注解可添加到类上,则对类中所有方法执行事务的设定,注解添加到方法上,则对该方法执行事务处理 @Tran ...
- 第九十九篇:JS闭包
好家伙,总是要来的,去面对那些晦涩难懂的原理,它就在那里,等着我去搞定它 首先我要去补充一些最基本的概念, 1.什么是内存? 新华字典永远的神, 但这个解释显然不够 去看看百度百科: 内存: CP ...
- Linux虚拟机报错grub rescue解决步骤
/boot 分区内核文件丢失 实验准备 1) 准备:rm -rf /boot/* 2) 系统启动报错截图 修复步骤 重启显示logo时 按 Esc,选择从光驱启动 或者关机再选择打开电源时进入固件 移 ...
- 富莱尔ERP
微型版本 按年付费模式 980包含5个用户,后续每增加一个用户加298元. 适合创业型企业,想尝试用下ERP软件解决打送货单问题,客户自动生成账单,自动统计业务员每月业绩功能. 试用账号:wxadmi ...
- Vim使用技巧(持续更新)
好记性不如烂笔头,在这里记录一些Vim使用技巧 vim配置 "拷贝同步到系统剪切板" set clipboard=unnamed "显示行号" set nu & ...
- 跟羽夏学 Ghidra ——调试
写在前面 此系列是本人一个字一个字码出来的,包括示例和实验截图.本人非计算机专业,可能对本教程涉及的事物没有了解的足够深入,如有错误,欢迎批评指正. 如有好的建议,欢迎反馈.码字不易,如果本篇文章 ...
- 一门能让你五分钟学会的语言-Brainfuck
看到标题,不出意外的话,你肯定开始骂我了:**标题党,什么编程语言五分钟就能学会? 其实我本来也是不相信的,但是学过了才知道这是真的. 1.Brainfuck 看到这个小标题,不要误会,我没有骂人. ...
- MinIO Server配置指南
MinIO server在默认情况下会将所有配置信息存到 ${HOME}/.minio/config.json 文件中. 以下部分提供每个字段的详细说明以及如何自定义它们. 配置目录 默认的配置目录是 ...
- docker相关总结
Docker 的相关使用记录 一.安装docker linux环境使用yum命令安装docker 第一步:确保自己的虚拟机没有安装过docker,如果安装过的需要将原先的docker进行卸载,命令如下 ...
- 详解平衡二叉树(AVL tree)平衡操作(图+代码)
* 左左就右旋,右右就左旋 #include<bits/stdc++.h> using namespace std; typedef long long ll; const int max ...