python之爬虫二
10正则表达式
正则表达式(regular expression)是一种字符串匹配模式或者规则,它可以用来检索、替换那些符合特定规则的文本。正则表达式几乎适用于所有编程语言,无论是前端语言 JavaScript,还是诸如许多后端语言,比如 Python、Java、C# 等,这些语言都提供了相应的函数、模块来支持正则表达式,比如 Python 的 re 模块就提供了正则表达式的常用方法。
在使用 Python 编写爬虫的过程中,re 模块通常做为一种解析方法来使用。通过审查网页元素来获取网页的大体结构,然后使用解析模块来提取你想要的网页信息,最终实现数据的抓取。本节对正则表达式基本语法做简单讲解。
注意:学习本节知识之前,您应该已经掌握了正则表达式的使用方法。
正则表达式元字符
下表列出了常用的正则表达式元字符:
1) 元字符
|
正则表表达式元字符 |
|
|
元字符 |
匹配内容 |
|
. |
匹配除换行符以外的任意字符 |
|
\w |
匹配所有普通字符(数字、字母或下划线) |
|
\s |
匹配任意的空白符 |
|
\d |
匹配数字 |
|
\n |
匹配一个换行符 |
|
\t |
匹配一个制表符 |
|
\b |
匹配一个单词的结尾 |
|
^ |
匹配字符串的开始位置 |
|
$ |
匹配字符串的结尾位置 |
|
\W |
匹配非字母或数字或下划线 |
|
\D |
匹配非数字 |
|
\S |
匹配非空白符 |
|
a|b |
匹配字符 a 或字符 b |
|
() |
正则表达式分组所用符号,匹配括号内的表达式,表示一个组。 |
|
[...] |
匹配字符组中的字符 |
|
[^...] |
匹配除了字符组中字符的所有字符 |
2) 量词
|
正则表达式量词 |
|
|
量词 |
用法说明 |
|
* |
重复零次或者更多次 |
|
+ |
重复一次或者更多次 |
|
? |
重复0次或者一次 |
|
{n} |
重复n次 |
|
{n,} |
重复n次或者更多次 |
|
{n,m} |
重复n到m次 |
3) 字符组
有时也会出现各种字符组成的字符组,这在正则表达式中使用[]表示,如下所示:
|
正则表达式字符组 |
|||
|
正则 |
待匹配字符 |
匹配结果 |
说明 |
|
[0123456789] |
8 |
True |
在一个字符组里枚举所有字符,字符组里的任意一个字符 |
|
[0123456789] |
a |
False |
由于字符组中没有 "a" 字符,所以不能匹配。 |
|
[0-9] |
7 |
True |
也可以用-表示范围,[0-9] 就和 [0123456789] 是一个意思。 |
|
[a-z] |
s |
True |
同样的如果要匹配所有的小写字母,直接用 [a-z] 就可以表示。 |
|
[A-Z] |
B |
True |
[A-Z] 就表示所有的大写字母。 |
|
[0-9a-fA-F] |
e |
True |
可以匹配数字,大小写形式的 a~f,用来验证十六进制字符。 |
贪婪模式非贪婪模式
正则表达式默认为贪婪匹配,也就是尽可能多的向后匹配字符,比如 {n,m} 表示匹配前面的内容出现 n 到 m 次(n 小于 m),在贪婪模式下,首先以匹配 m 次为目标,而在非贪婪模式是尽可能少的向后匹配内容,也就是说匹配 n 次即可。
贪婪模式转换为非贪婪模式的方法很简单,在元字符后添加“?”即可实现,如下所示:
|
非贪婪模式 |
|
|
元字符(贪婪模式) |
非贪婪模式 |
|
* |
*? |
|
+ |
+? |
|
? |
?? |
|
{n,m} |
{n,m}? |
正则表达式转义
如果使用正则表达式匹配特殊字符时,则需要在字符前加\表示转意。常见的特殊字符如下:
* + ? ^ $ [] () {} | \
11re模块使用
在 Python 爬虫过程中,实现网页元素解析的方法有很多,正则解析只是其中之一,常见的还有 BeautifulSoup 和 lxml,它们都支持网页 HTML 元素的解析操作。本节重点讲解如何使用 re 正则解析模块实现网页信息的提取。
注意:在学习本节知识之前,您应该基本掌握了 Python re 模块的常用方法。
re模块常用方法
1) re.compile()
该方法用来生成正则表达式对象,其语法格式如下:
regex=re.compile(pattern,flags=0)
参数说明:
- pattern:正则表达式对象。
- flags:代表功能标志位,扩展正则表达式的匹配。
2) re.findall()
根据正则表达式匹配目标字符串内容。
re.findall(pattern,string,flags=0)
该函数的返回值是匹配到的内容列表,如果正则表达式有子组,则只能获取到子组对应的内容。参数说明如下:
- pattern:正则表达式对象。
- string:目标字符串
- flags:代表功能标志位,扩展正则表达式的匹配。
3) regex.findall()
该函数根据正则表达式对象匹配目标字符串内容。其语法格式如下:
regex.findall(string,pos,endpos)
参数说明:
- string 目标字符串。
- pos 截取目标字符串的开始匹配位置。
- endpos 截取目标字符串的结束匹配位置。
4) re.split()
该函数使用正则表达式匹配内容,切割目标字符串。返回值是切割后的内容列表。参数说明:
re.split(pattern,string,flags = 0)
参数说明:
- pattern:正则表达式。
- string:目标字符串。
- flags:功能标志位,扩展正则表达式的匹配。
5) re.sub
该函数使用一个字符串替换正则表达式匹配到的内容。返回值是替换后的字符串。其语法格式如下:
re.sub(pattern,replace,string,max,flags = 0)
其参数说明:
- pattern:正则表达式。
- replace:替换的字符串。
- string:目标字符串。
- max:最多替换几处,默认替换全部,
- flags:功能标志位,扩展正则表达式的匹配。
5) re.search()
匹配目标字符串第一个符合的内容,返回值为匹配的对象。语法格式如下:
re.search(pattern,string,flags=0)
参数说明:
- pattern:正则表达式
- string:目标字符串
flags功能标志位
功能标志位的作用是扩展正则表达的匹配功能。常用的 flag 如下所示:
|
flag功能标志位 |
|
|
缩写元字符 |
说明 |
|
A |
元字符只能匹配 ASCII码。 |
|
I |
匹配忽略字母大小写。 |
|
S |
使得.元字符可以匹配换行符。 |
|
M |
使 ^ $ 可以匹配每一行的开头和结尾位置。 |
注意:可以同时使用福多个功能标志位,比如 flags=re.I|re.S。
下面使用贪婪和非贪婪两种模式来匹配 HTML 元素,分别,如下所示:
- import re
- html="""
- <div><p>www.biancheng.net</p></div>
- <div><p>编程帮</p></div>
- """
- #贪婪匹配,re.S可以匹配换行符
- #创建正则表达式对象
- pattern=re.compile('<div><p>.*</p></div>',re.S)
- #匹配HTMLX元素,提取信息
- re_list=pattern.findall(html)
- print(re_list)
- #非贪婪模式匹配,re.S可以匹配换行符
- pattern=re.compile('<div><p>.*?</p></div>',re.S)
- re_list=pattern.findall(html)
- print(re_list)
输出结果:
['<div><p>www.biancheng.net</p></div>\n<div><p>编程帮</p></div>']
['<div><p>www.biancheng.net</p></div>', '<div><p>编程帮</p></div>']
从上述输出结果可以得出非贪婪模式比适合提取 HTML 信息。
正则表达式分组
通过正则表达式分组可以从匹配的信息中提取出想要的信息。示例演示:
- #正则表达式分组
- website="编程帮 www.biancheng.net"
- #提取所有信息
- #注意此时正则表达式的 "." 需要转义因此使用 \.
- pattern_1=re.compile('\w+\s+\w+\.\w+\.\w+')
- print(pattern_1.findall(website))
- #提取匹配信息的第一项
- pattern_2=re.compile('(\w+)\s+\w+\.\w+\.\w+')
- print(pattern_2.findall(website))
- #有两个及以上的()则以元组形式显示
- pattern_3=re.compile('(\w+)\s+(\w+\.\w+\.\w+)')
- print(pattern_3.findall(website))
输出结果:
['编程帮 www.biancheng.net']
['编程帮']
[('编程帮', 'www.biancheng.net')]
正则表达式分组是提取信息的常用方式。当需要哪个特定信息的时候,就可以通过分组(也就是加括号)的方式获得。
网页信息提取
实战演练:从下面的 HTML 代码中使用 re 模块提取出两部影片的名称和主演信息。
- html="""
- <div class="movie-item-info">
- <p class="name">
- <a title="你好,李焕英">你好,李焕英</a>
- </p>
- <p class="star">
- 主演:贾玲,张小斐,沈腾
- </p>
- </div>
- <div class="movie-item-info">
- <p class="name">
- <a title="刺杀,小说家">刺杀,小说家</a>
- </p>
- <p class="star">
- 主演:雷佳音,杨幂,董子健,于和伟
- </p>
- </div>
- """
- # 寻找HTML规律,书写正则表达式,使用正则表达式分组提取信息
- pattern=re.compile(r'<div.*?<a title="(.*?)".*?star">(.*?)</p.*?div>',re.S)
- r_list=pattern.findall(html)
- print(r_list)
- # 整理数据格式并输出
- if r_list:
- for r_info in r_list:
- print("影片名称:",r_info[0])
- print("影片主演:",r_info[1].strip())
- print(20*"*")
输出结果如下:
[('你好,李焕英', '\n主演:贾玲,张小斐,沈腾\n'), ('刺杀,小说家', '\n主演:雷佳音,杨幂,董子健,于和伟\n')]
影片名称: 你好,李焕英
影片主演: 主演:贾玲,张小斐,沈腾
********************
影片名称: 刺杀,小说家
影片主演: 主演:雷佳音,杨幂,董子健,于和伟
********************
12csv模块
CSV 文件又称为逗号分隔值文件,是一种通用的、相对简单的文件格式,用以存储表格数据,包括数字或者字符。CSV 是电子表格和数据库中最常见的输入、输出文件格式,可参考《CSV介绍》。
通过爬虫将数据抓取的下来,然后把数据保存在文件,或者数据库中,这个过程称为数据的持久化存储。本节介绍 Python 内置模块 CSV 的读写操作。
CSV文件写入
1) csv.writer()
csv 模块中的 writer 类可用于读写序列化的数据,其语法格式如下:
writer(csvfile, dialect='excel', **fmtparams)
参数说明:
- csvfile:必须是支持迭代(Iterator)的对象,可以是文件(file)对象或者列表(list)对象。
- dialect:编码风格,默认为 excel 的风格,也就是使用逗号,分隔。
- fmtparam:格式化参数,用来覆盖之前 dialect 对象指定的编码风格。
示例如下:
- import csv
- # 操作文件对象时,需要添加newline参数逐行写入,否则会出现空行现象
- with open('eggs.csv', 'w', newline='') as csvfile:
- # delimiter 指定分隔符,默认为逗号,这里指定为空格
- # quotechar 表示引用符
- # writerow 单行写入,列表格式传入数据
- spamwriter = csv.writer(csvfile, delimiter=' ',quotechar='|')
- spamwriter.writerow(['www.biancheng.net'] * 5 + ['how are you'])
- spamwriter.writerow(['hello world', 'web site', 'www.biancheng.net'])
eggs.csv 文件内容如下:
www.biancheng.net www.biancheng.net www.biancheng.net www.biancheng.net www.biancheng.net |how are you|
|hello world| |web site| www.biancheng.net
其中,quotechar 是引用符,当一段话中出现分隔符的时候,用引用符将这句话括起来,以能排除歧义。
如果想同时写入多行数据,需要使用 writerrows() 方法,代码如下所示:
- import csv
- with open('aggs.csv', 'w', newline='') as f:
- writer = csv.writer(f)
- # 注意传入数据的格式为列表元组格式
- writer.writerows([('hello','world'), ('I','love','you')])
aggs.csv文件内容:
hello,world
I,love,you
2) csv.DictWriter()
当然也可使用 DictWriter 类以字典的形式读写数据,使用示例如下:
- import csv
- with open('names.csv', 'w', newline='') as csvfile:
- #构建字段名称,也就是key
- fieldnames = ['first_name', 'last_name']
- writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
- # 写入字段名,当做表头
- writer.writeheader()
- # 多行写入
- writer.writerows([{'first_name': 'Baked', 'last_name': 'Beans'},{'first_name': 'Lovely', 'last_name': 'Spam'}])
- # 单行写入
- writer.writerow({'first_name': 'Wonderful', 'last_name': 'Spam'})
name.csv 文件内容,如下所示:
first_name,last_name
Baked,Beans
Lovely,Spam
Wonderful,Spam
CSV文件读取
1) csv,reader()
csv 模块中的 reader 类和 DictReader 类用于读取文件中的数据,其中 reader() 语法格式如下:
csv.reader(csvfile, dialect='excel', **fmtparams)
应用示例如下:
- import csv
- with open('eggs.csv', 'r', newline='') as csvfile:
- spamreader = csv.reader(csvfile, delimiter=' ', quotechar='|')
- for row in spamreader:
- print(', '.join(row))
输出结果:
www.biancheng.net, www.biancheng.net, www.biancheng.net, www.biancheng.net, www.biancheng.net, how are you
hello world, web site, www.biancheng.net
2) csv.DictReader()
应用示例如下:
- import csv
- with open('names.csv', newline='') as csvfile:
- reader = csv.DictReader(csvfile)
- for row in reader:
- print(row['first_name'], row['last_name'])
输出结果:
Baked Beans
Lovely Spam
Wonderful Spam
13实战
本节使用 Python 爬虫抓取猫眼电影网 TOP100 排行榜(https://maoyan.com/board/4)影片信息,包括电影名称、上映时间、主演信息。
在开始编写程序之前,首先要确定页面类型(静态页面或动态页面),其次找出页面的 url 规律,最后通过分析网页元素结构来确定正则表达式,从而提取网页信息。
确定页面类型
点击右键查看页面源码,确定要抓取的数据是否存在于页面内。通过浏览得知要抓取的信息全部存在于源码内,因此该页面输属于静态页面。如下所示:
- <div class="movie-item-info">
- <p class="name"><a href="/films/1200486" title="我不是药神" data-act="boarditem-click" data-val="{movieId:1200486}">我不是药神</a></p>
- <p class="star">
- 主演:徐峥,周一围,王传君
- </p>
- <p class="releasetime">上映时间:2018-07-05</p> </div>
确定url规律
想要确定 url 规律,需要您多浏览几个页面,然后才可以总结出 url 规律,如下所示:
第一页:https://maoyan.com/board/4?offset=0
第二页:https://maoyan.com/board/4?offset=10
第三页:https://maoyan.com/board/4?offset=20
...
第n页:https://maoyan.com/board/4?offset=(n-1)*10
确定正则表达式
通过分析网页元素结构来确定正则表达式,如下所示:
- <div class="movie-item-info">
- <p class="name"><a href="/films/1200486" title="我不是药神" data-act="boarditem-click" data-val="{movieId:1200486}">我不是药神</a></p>
- <p class="star">
- 主演:徐峥,周一围,王传君
- </p>
- <p class="releasetime">上映时间:2018-07-05</p></div>
使用 Chrome 开发者调试工具来精准定位要抓取信息的元素结构。之所以这样做,是因为这能避免正则表达式的冗余,提高编写正则表达式的速度。正则表达式如下所示:
<div class="movie-item-info">.*?title="(.*?)".*?class="star">(.*?)</p>.*?releasetime">(.*?)</p>
编写正则表达式时将需要提取的信息使用(.*?)代替,而不需要的内容(包括元素标签)使用.*?代替。
编写爬虫程序
下面使用面向对象的方法编写爬虫程序,主要编写四个函数,分别是请求函数、解析函数、保存数据函数、主函数。
- from urllib import request
- import re
- import time
- import random
- import csv
- from ua_info import ua_list
- # 定义一个爬虫类
- class MaoyanSpider(object):
- # 初始化
- # 定义初始页面url
- def __init__(self):
- self.url = 'https://maoyan.com/board/4?offset={}'
- # 请求函数
- def get_html(self,url):
- headers = {'User-Agent':random.choice(ua_list)}
- req = request.Request(url=url,headers=headers)
- res = request.urlopen(req)
- html = res.read().decode()
- # 直接调用解析函数
- self.parse_html(html)
- # 解析函数
- def parse_html(self,html):
- # 正则表达式
- re_bds = '<div class="movie-item-info">.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?class="releasetime">(.*?)</p>'
- # 生成正则表达式对象
- pattern = re.compile(re_bds,re.S)
- # r_list: [('我不是药神','徐峥,周一围,王传君','2018-07-05'),...] 列表元组
- r_list = pattern.findall(html)
- self.save_html(r_list)
- # 保存数据函数,使用python内置csv模块
- def save_html(self,r_list):
- #生成文件对象
- with open('maoyan.csv','a',newline='',encoding="utf-8") as f:
- #生成csv操作对象
- writer = csv.writer(f)
- #整理数据
- for r in r_list:
- name = r[0].strip()
- star = r[1].strip()[3:]
- # 上映时间:2018-07-05
- # 切片截取时间
- time = r[2].strip()[5:15]
- L = [name,star,time]
- # 写入csv文件
- writer.writerow(L)
- print(name,time,star)
- # 主函数
- def run(self):
- #抓取第一页数据
- for offset in range(0,11,10):
- url = self.url.format(offset)
- self.get_html(url)
- #生成1-2之间的浮点数
- time.sleep(random.uniform(1,2))
- # 以脚本方式启动
- if __name__ == '__main__':
- #捕捉异常错误
- try:
- spider = MaoyanSpider()
- spider.run()
- except Exception as e:
- print("错误:",e)
输出结果:
我不是药神 2018-07-05 徐峥,周一围,王传君
肖申克的救赎 1994-09-10 蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿
绿皮书 2019-03-01 维果·莫腾森,马赫沙拉·阿里,琳达·卡德里尼
海上钢琴师 2019-11-15 蒂姆·罗斯,比尔·努恩,克兰伦斯·威廉姆斯三世
小偷家族 2018-08-03 中川雅也,安藤樱,松冈茉优
霸王别姬 1993-07-26 张国荣,张丰毅,巩俐
哪吒之魔童降世 2019-07-26 吕艳婷,囧森瑟夫,瀚墨
美丽人生 2020-01-03 罗伯托·贝尼尼,朱斯蒂诺·杜拉诺,赛尔乔·比尼·布斯特里克
这个杀手不太冷 1994-09-14 让·雷诺,加里·奥德曼,娜塔莉·波特曼
盗梦空间 2010-09-01 莱昂纳多·迪卡普里奥,渡边谦,约瑟夫·高登-莱维特
14pymasql应用
Python 连接并操作 MySQL 数据库,主要通过 Pymysql 模块实现。本节讲解如何将抓取的数据存储至 MySQL 数据库。
提示:在学习本节知识之前,您已经掌握了 SQL 语言的基本语法。可参考《MySQL教程》
创建存储数据表
首先您应该确定您的计算机上已经安装了 MySQL 数据库,然后再进行如下操作:
# 1. 连接到mysql数据库
mysql -h127.0.0.1 -uroot -p123456
# 2. 建库
create database maoyandb charset utf8;
# 3. 切换数据库
use maoyandb;
# 4. 创建数据表
create table filmtab(
name varchar(100),
star varchar(400),
time varchar(30)
);
Pymysql基本使用
1) 连接数据库
- db = pymysql.connect('localhost','root','123456','maoyandb')
参数说明:
- localhost:本地 MySQL 服务端地址,也可以是远程数据库的 IP 地址。
- root:连接数据所使用的用户名。
- password:连接数据库使用的密码,本机 MySQL 服务端密码“123456”。
- db:连接的数据库名称。
2) 创建cursor对象
cursor = db.cursor()
3) 执行sql命令
execute() 方法用来执行 SQL 语句。如下所示:
- #第一种方法:编写sql语句,使用占位符传入相应数据
- sql = "insert into filmtab values('%s','%s','%s')" % ('刺杀,小说家','雷佳音','2021')
- cursor.excute(sql)
- 第二种方法:编写sql语句,使用列表传参方式
- sql = 'insert into filmtab values(%s,%s,%s)'
- cursor.execute(sql,['刺杀,小说家','雷佳音','2021'])
4) 提交数据
db.commit()
5) 关闭数据库
cursor.close()
db.close()
完整的代码如下所示:
- # -*-coding:utf-8-*-
- import pymysql
- #创建对象
- db = pymysql.connect('localhost','root','123456','maoyandb')
- cursor = db.cursor()
- # sql语句执性,单行插入
- info_list = ['刺杀,小说家','雷佳音,杨幂','2021-2-12']
- sql = 'insert into movieinfo values(%s,%s,%s)'
- #列表传参
- cursor.execute(sql,info_list)
- db.commit()
- # 关闭
- cursor.close()
- db.close()
查询数据结果,如下所示:
mysql> select * from movieinfo;
+-------------+-------------------+-----------+
| name | star | time |
+-------------+-------------------+-----------+
| 刺杀,小说家 | 雷佳音,杨幂 | 2021-2-12 |
+-------------+-------------------+-----------+
1 rows in set (0.01 sec)
还有一种效率较高的方法,使用 executemany() 可以同时插入多条数据。示例如下:
- db = pymysql.connect('localhost','root','123456','maoyandb',charset='utf8')
- cursor = db.cursor()
- # sql语句执性,列表元组
- info_list = [('我不是药神','徐峥','2018-07-05'),('你好,李焕英','贾玲','2021-02-12')]
- sql = 'insert into movieinfo values(%s,%s,%s)'
- cursor.executemany(sql,info_list)
- db.commit()
- # 关闭
- cursor.close()
- db.close()
查询插入结果,如下所示:
mysql> select * from movieinfo;
+-------------+-------------------+------------+
| name | star | time |
+-------------+-------------------+------------+
| 我不是药神 | 徐峥 | 2018-07-05 |
| 你好,李焕英 | 贾玲 | 2021-02-12 |
+-------------+-------------------+------------+
2 rows in set (0.01 sec)
修改爬虫程序
下面修改上一节《Python爬虫抓取猫眼电影排行榜》中的爬虫程序,将抓取下来的数据存储到 MySQL 数据库。如下所示:
- # coding=gbk
- from urllib import request
- import re
- import time
- import random
- from ua_info import ua_list
- import pymysql
- class MaoyanSpider(object):
- def __init__(self):
- #初始化属性对象
- self.url = 'https://maoyan.com/board/4?offset={}'
- #数据库连接对象
- self.db = pymysql.connect(
- 'localhost','root','123456','maoyandb',charset='utf8')
- #创建游标对象
- self.cursor = self.db.cursor()
- def get_html(self,url):
- headers = {'User-Agent':random.choice(ua_list)}
- req = request.Request(url=url,headers=headers)
- res = request.urlopen(req)
- html = res.read().decode()
- # 直接解析
- self.parse_html(html)
- def parse_html(self,html):
- re_bds = '<div class="movie-item-info">.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?class="releasetime">(.*?)</p>'
- pattern = re.compile(re_bds,re.S)
- r_list = pattern.findall(html)
- self.save_html(r_list)
- def save_html(self, r_list):
- L = []
- sql = 'insert into movieinfo values(%s,%s,%s)'
- # 整理数据
- for r in r_list:
- t = (
- r[0].strip(),
- r[1].strip()[3:],
- r[2].strip()[5:15]
- )
- L.append(t)
- print(L)
- # 一次性插入多条数据 L:[(),(),()]
- try:
- self.cursor.executemany(sql,L)
- # 将数据提交数据库
- self.db.commit()
- except:
- # 发生错误则回滚
- self.db.rollback()
- def run(self):
- for offset in range(0,11,10):
- url = self.url.format(offset)
- self.get_html(url)
- time.sleep(random.uniform(1,3))
- # 断开游标与数据库连接
- self.cursor.close()
- self.db.close()
- if __name__ == '__main__':
- start=time.time()
- spider = MaoyanSpider()
- spider.run()
- end=time.time()
- print("执行时间:%.2f" % (end-start))
数据库查询存储结果,如下所示:
mysql> select * from movieinfo;
+----------------+----------------------------------------------------------+------------+
| name | star | time |
+----------------+----------------------------------------------------------+------------+
| 我不是药神 | 徐峥,周一围,王传君 | 2018-07-05 |
| 肖申克的救赎 | 蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿 | 1994-09-10 |
| 绿皮书 | 维果·莫腾森,马赫沙拉·阿里,琳达·卡德里尼 | 2019-03-01 |
| 海上钢琴师 | 蒂姆·罗斯,比尔·努恩,克兰伦斯·威廉姆斯三世 | 2019-11-15 |
| 小偷家族 | 中川雅也,安藤樱,松冈茉优 | 2018-08-03 |
| 霸王别姬 | 张国荣,张丰毅,巩俐 | 1993-07-26 |
| 哪吒之魔童降世 | 吕艳婷,囧森瑟夫,瀚墨 | 2019-07-26 |
| 美丽人生 | 罗伯托·贝尼尼,朱斯蒂诺·杜拉诺,赛尔乔·比尼·布斯特里克 | 2020-01-03 |
| 这个杀手不太冷 | 让·雷诺,加里·奥德曼,娜塔莉·波特曼 | 1994-09-14 |
| 盗梦空间 | 莱昂纳多·迪卡普里奥,渡边谦,约瑟夫·高登-莱维特 | 2010-09-01 |
+----------------+----------------------------------------------------------+------------+
10 rows in set (0.01 sec)
16抓多级页面
前面讲解的爬虫案例都是单级页面数据抓取,但有些时候,只抓取一个单级页面是无法完成数据提取的。本节讲解如何使用爬虫抓取多级页面的数据。
在爬虫的过程中,多级页面抓取是经常遇见的。下面以抓取二级页面为例,对每级页面的作用进行说明:
- 一级页面提供了获取二级页面的访问链接。
- 二级页面作为详情页用来提取所需数据。
一级页面以<a>标签的形式链接到二级页面,只有在二级页面才可以提取到所需数据。
多级页面分析
下面以电影天堂(点击访问) 2020 新片精品为案例进行讲解,将每部影片的名称,以及下载链接抓取下来。首先点击“更多”进入一级页面,如下图所示:
图1:Python爬虫多级页面抓取
1) 寻找url规律
通过简单分析可以得知一级与二级页面均为静态页面,接下来分析 url 规律,通过点击第 1 页,第 2 页 ...,其规律如下:
第1页 :https://www.dytt8.net/html/gndy/dyzz/list_23_1.html
第2页 :https://www.dytt8.net/html/gndy/dyzz/list_23_2.html
第n页 :https://www.dytt8.net/html/gndy/dyzz/list_23_n.html
2) 确定正则表达式
通过元素审查可知一级页面的元素结构如下:
图2:页面元素分析
其正则表达式如下:
<table width="100%".*?<td width="5%".*?<a href="(.*?)".*?ulink">.*?</table>
点击二级页面进入详情页,通过开发者工具分析想要数据的网页元素,即电影名称,和下载链接,其正则表达式如下:
<div class="title_all"><h1><font color=#07519a>(.*?)</font></h1></div>.*?<div><a href="(.*?)">.*?</a>
爬虫增量抓取
爬虫是一种效率很低的程序,非常消耗计算机资源。对于聚焦爬虫程序而言,需要每天对特定的网站进行数据抓取,如果每次都去抓取之前已经抓取过的数据,就会白白消耗了时间和资源。而增量爬虫是指通过监测网站更新的情况,只抓取最新数据的一种方式,这样就大大降低了资源的消耗。
对于本节案例来说,电影天堂网站每天都会更新内容,因此编写一个增量抓取的爬虫程序是非常合适的。
那么要如何判断爬虫程序是否已抓取过二级页面的 url 呢?其实,当您第一次运行爬虫程序时,爬虫会将所有的 url 抓取下来,然后将这些 url 放入数据库中。为了提高数据库的查询效率,您可以为每一个 url 生成专属的“指纹”。当网站更新后,第二次运行爬虫程序时,程序只会对数据库中不存在的指纹进行抓取。
程序代码实现
1) 建库建表
将抓取的数据的存放至 MySQL 数据库,需要先进行建库建表操作。注意,这里需要将 url 指纹单独存放在一张表中,如下所示:
- create database movieskydb charset utf8;
- use movieskydb;
- create table request_finger(
- finger char(60)
- )charset=utf8;
- create table movieinfo(
- moviename varchar(300),
- downloadaddr varchar(600)
- )charset=utf8;
2) url指纹生成
您可以使用 Python 内置模块 md5 来生成加密“指纹”,如下所示。
- #导入模块
- from hashlib import md5
- #待加密的url
- url="https://www.dytt8.net/html/gndy/dyzz/20210226/61131.html"
- # 生成MD5对象
- secret = md5()
- # 加密url
- secret.update(url.encode())
- # 提取十六进制的加密串
- finger = secret.hexdigest()
- print(finger)
输出结果:
2d5e46ee52756e8ae59c9ba42230b883
3) 程序完整代码
- # -*- coding: utf-8 -*-
- from urllib import request
- import re
- import time
- import random
- import pymysql
- from hashlib import md5
- from ua_info import ua_list
- import sys
- class MovieSkySpider(object):
- def __init__(self):
- self.url = 'https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html'
- self.db = pymysql.connect(
- 'localhost','root','123456','movieskydb',
- charset='utf8'
- )
- self.cursor = self.db.cursor()
- # 1.请求函数
- def get_html(self, url):
- headers = {'User-Agent': random.choice(ua_list)}
- req = request.Request(url=url, headers=headers)
- res = request.urlopen(req)
- # 本网站使用gb2312的编码格式
- html = res.read().decode('gb2312', 'ignore')
- return html
- # 2.正则解析函数
- def re_func(self,re_bds,html):
- pattern = re.compile(re_bds,re.S)
- r_list = pattern.findall(html)
- return r_list
- # 3.提取数据函数
- def parse_html(self,one_url):
- # 调用请求函数,获取一级页面
- one_html = self.get_html(one_url)
- re_bds = '<table width="100%".*?<td width="5%".*?<a href="(.*?)".*?ulink">.*?</table>'
- # 获取二级页面链接
- # link_list: ['/html//html/gndy/dyzz/20210226/61131.html','/html/xxx','','']
- link_list = self.re_func(re_bds,one_html)
- for link in link_list:
- # 判断是否需要爬取此链接
- # 1.获取指纹
- # 拼接二级页面url
- two_url = 'https://www.dytt8.net' + link
- s = md5()
- #加密url,需要是字节串
- s.update(two_url.encode())
- # 生成指纹,获取十六进制加密字符串,
- finger = s.hexdigest()
- # 2.通过函数判断指纹在数据库中是否存在
- if self.is_hold_on(finger):
- # 抓取二级页面数据
- self.save_html(two_url)
- time.sleep(random.randint(1,2))
- # 抓取后,把想用的url专属指纹存入数据库
- ins = 'insert into request_finger values (%s)'
- self.cursor.execute(ins,[finger])
- self.db.commit()
- else:
- sys.exit('更新完成')
- # 4.判断链接是否已经抓取过
- def is_hold_on(self,finger):
- # 查询数据库
- sql='select finger from request_finger where finger=%s'
- # execute()函数返回值为受影响的行数(即0或者非0)
- r = self.cursor.execute(sql,[finger])
- # 如果为0表示没有抓取过
- if not r:
- return True
- # 5.解析二级页面,获取数据(名称与下载链接)
- def save_html(self,two_url):
- two_html = self.get_html(two_url)
- re_bds = '<div class="title_all"><h1><font color=#07519a>(.*?)</font></h1> \
- </div>.*?<a.*?href="(.*?)".*?>.*?style="/a>'
- # film_list: [('name','downloadlink'),(),(),()]
- film_list = self.re_func(re_bds,two_html)
- print(film_list)
- # 插入数据库
- sql = 'insert into movieinfo values(%s,%s)'
- #L = list(film_list[0])
- self.cursor.executemany(sql,film_list)
- self.db.commit()
- #主函数
- def run(self):
- # 二级页面后四页的正则表达式略有不同,需要重新分析
- for i in range(1,4):
- url = self.url.format(i)
- self.parse_html(url)
- if __name__ == '__main__':
- spider = MovieSkySpider()
- spider.run()
若要查询数据库存储数据,执行以下命令即可:
- mysql> select * from movieinfo\G
输出如下,如下图所示:
图3:MySQL数据库存储数据
在二级页面提取数据时要注意该页面的类型。该网站在二级页面使用了两种类型的网页结构,另外一种页面结构的正则表达式如下所示:
<div class="title_all"><h1><font color=#07519a>(.*?)</font></h1></div>.*?<td style="WORD-WRAP.*?>.*?>(.*?)</a>
若要抓取此类页面的数据,需要更换二级页面正则表达式
17requests第三库使用
Python 提供了多个用来编写爬虫程序的库,除了前面已经介绍的 urllib 库之外,还有一个很重的 Requests 库,这个库的宗旨是“让 HTTP 服务于人类”。
Requests 是 Python 的第三方库,它的安装非常简便,如下所示:
python -m pip install requests
Requests 库是在 urllib 的基础上开发而来,它使用 Python 语言编写,并且采用了 Apache2 Licensed(一种开源协议)的 HTTP 库。与 urllib 相比,Requests 更加方便、快捷,因此在编写爬虫程序时 Requests 库使用较多。
常用请求方法
1) requests.get()
该方法用于 GET 请求,表示向网站发起请求,获取页面响应对象。语法如下:
res = requests.get(url,headers=headers,params,timeout)
参数说明如下:
- url:要抓取的 url 地址。
- headers:用于包装请求头信息。
- params:请求时携带的查询字符串参数。
- timeout:超时时间,超过时间会抛出异常。
具体使用示例如下:
- import requests
- url = 'http://baidu.com'
- response = requests.get(url)
- print(response)
输出结果:
<Response [200]>
获取带查询字符串参数的响应对象,如下所示:
- import requests
- data = {
- 'name': '编程帮',
- 'url': "www.biancheng.net"
- }
- response = requests.get('http://httpbin.org/get', params=data)
- #直接拼接参数也可以
- #response = requests.get(http://httpbin.org/get?name=gemey&age=22)
- #调用响应对象text属性,获取文本信息
- print(response.text)
输出结果:
{
"args": {
"name": "\u7f16\u7a0b\u5e2e",
"url": "www.biancheng.net"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.23.0",
"X-Amzn-Trace-Id": "Root=1-60420026-236f9205646b68706d0fafa7"
},
"origin": "121.17.25.194",
"url": "http://httpbin.org/get?name=\u7f16\u7a0b\u5e2e&url=www.biancheng.net"
}
2) requests.post()
该方法用于 POST 请求,先由用户向目标 url 提交数据,然后服务器返回一个 HttpResponse 响应对象,语法如下:
response=requests.post(url,data={请求体的字典})
示例如下所示:
- import requests
- #百度翻译
- url = 'https://fanyi.baidu.com'
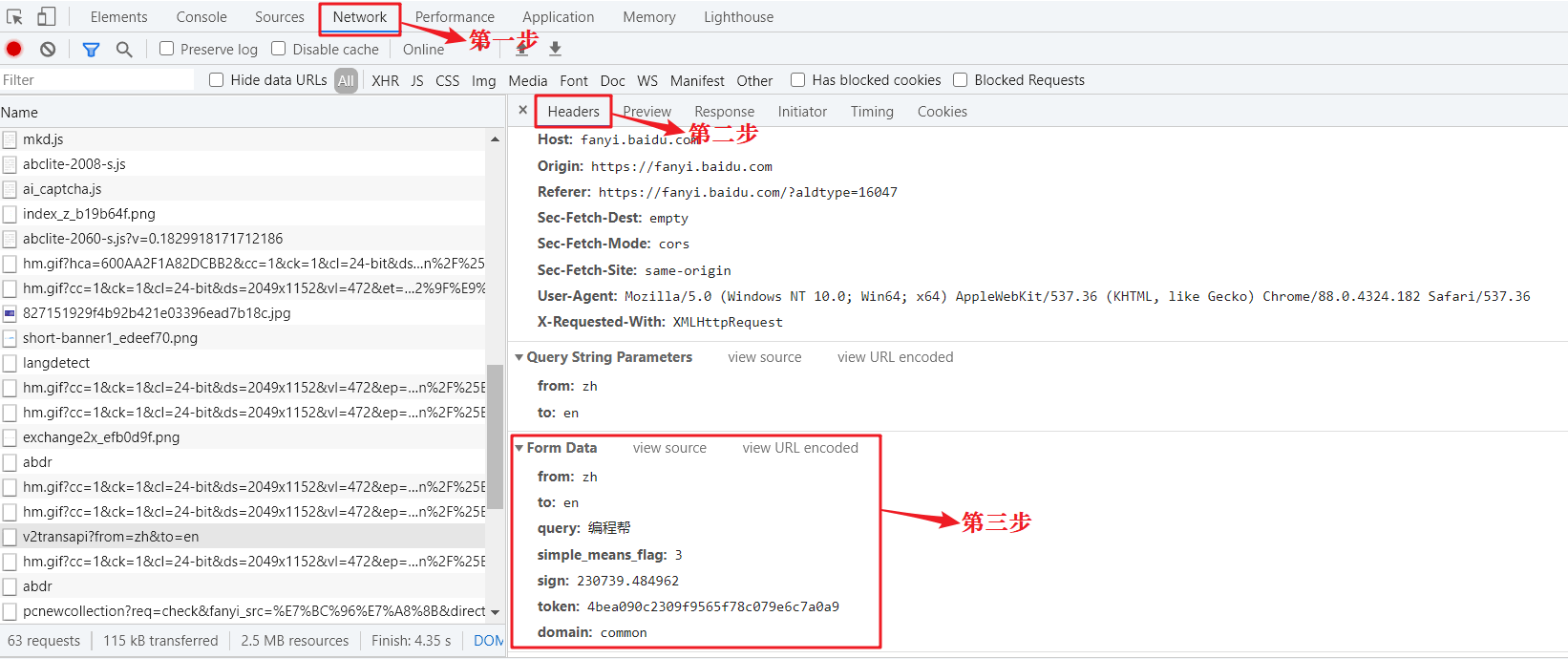
- #post请求体携带的参数,可通过开发者调试工具查看
- #查看步骤:NetWork选项->Headers选项->Form Data
- data = {'from': 'zh',
- 'to': 'en',
- 'query': '编程帮www.biancheng.net你好'
- }
- response = requests.post(url, data=data)
- print(response)
输出结果:
<Response [200]>
查看 Form Data 的步骤,如下图所示:
图1:Chrome开发者调试工具(点击看高清图)
{kind=link}
对象属性
当我们使用 Requests 模块向一个 URL 发起请求后会返回一个 HttpResponse 响应对象,该对象具有以下常用属性:
|
HttpResponse响应对象属性 |
|
|
常用属性 |
说明 |
|
encoding |
查看或者指定响应字符编码 |
|
status_code |
返回HTTP响应码 |
|
url |
查看请求的 url 地址 |
|
headers |
查看请求头信息 |
|
cookies |
查看cookies 信息 |
|
text |
以字符串形式输出 |
|
content |
以字节流形式输出,若要保存下载图片需使用该属性。 |
使用示例如下所示:
- import requests
- response = requests.get('http://www.baidu.com')
- print(response.encoding)
- response.encoding="utf-8" #更改为utf-8编码
- print(response.status_code) # 打印状态码
- print(response.url) # 打印请求url
- print(response.headers) # 打印头信息
- print(response.cookies) # 打印cookie信息
- print(response.text) #以字符串形式打印网页源码
- print(response.content) #以字节流形式打印
输出结果:
#编码格式
ISO-8859-1
#响应码
200
#url地址
http://www.baidu.com/
#请求头信息
{'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Mon, 08 Mar 2021 05:19:33 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:27:29 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
#查看cookies信息
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
...内容过长,此处省略后两项输出
Requests库应用
示例应用:使用 Requsets 库下载百度图片。
首先打开百度图片(https://image.baidu.com/),并在输入框搜索 “python logo”,然后使用 Chrome 开发者工具查看第一张图片的源地址,即 data-imgurl 所对应的 url 地址,如下所示:
data-imgurl="https://ss2.bdstatic.com/70cFvnSh_Q1YnxGkpoWK1HF6hhy/it/u=38785274,1357847304&fm=26&gp=0.jpg"
可以将上述 url 粘贴至浏览器地址栏进行验证。当我们确定图片地址后,就可以使用 requests 库进行编码了:
- import requests
- url = 'https://ss2.bdstatic.com/70cFvnSh_Q1YnxGkpoWK1HF6hhy/it/u=38785274,1357847304&fm=26&gp=0.jpg'
- #简单定义浏览器ua信息
- headers = {'User-Agent':'Mozilla/4.0'}
- #读取图片需要使用content属性
- html = requests.get(url=url,headers=headers).content
- #以二进制的方式下载图片
- with open('C:/Users/Administrator/Desktop/image/python_logo.jpg','wb') as f:
- f.write(html)
最后,您会在桌面文件夹中找到已经下载好的图片,如下所示:
图2:Requests库简单应用
17爬取网络图片
本节编写一个快速下载照片的程序,通过百度图片下载您想要的前 60 张图片,并将其保存至相应的目录。本节实战案例是上一节《Python Request库安装和使用》图片下载案例的延伸。
分析url规律
打开百度图片翻页版(点击访问),该翻页版网址要妥善保留。其 url 规律如下:
第一页:https://image.baidu.com/search/flip?tn=baiduimage&word=python&pn=0
第二页:https://image.baidu.com/search/flip?tn=baiduimage&word=python&pn=20
第三页:https://image.baidu.com/search/flip?tn=baiduimage&word=python&pn=40
第n页:https://image.baidu.com/search/flip?tn=baiduimage&word=python&pn=20*(n-1)
百度为了限制爬虫,将原来的翻页版变为了“瀑布流”浏览形式,也就是通过滚动滑轮自动加载图片,此种方式在一定程度上限制了爬虫程序。
写正则表达式
通过上一节可以得知每一张图片有一个源地址如下所示:
data-imgurl="图片源地址"
复制图片源地址,并检查网页源代码,使用 Ctrl+F 搜索该地址,如下图所示:
图1:检查网页结构(点击看高清图)
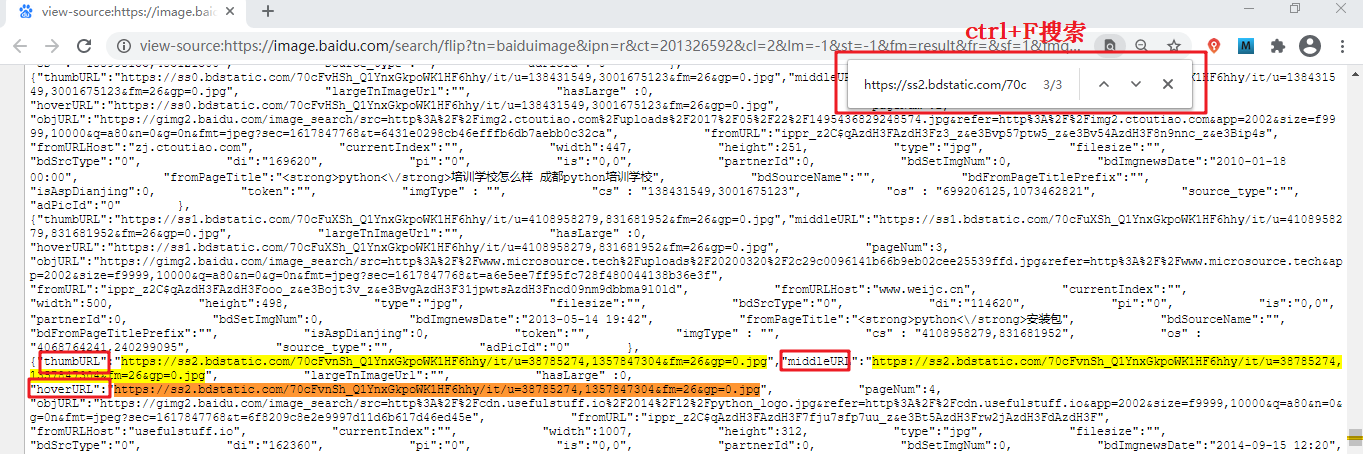{kind=link}
使用上述方式依次检查几张图片,您会发现每张图片源地址,有如下三种匹配结果:
"thumbURL":"https://ss2.bdstatic.com/70cFvnSh_Q1YnxGkpoWK1HF6hhy/it/u=38785274,1357847304&fm=26&gp=0.jpg"
"middleURL":"https://ss2.bdstatic.com/70cFvnSh_Q1YnxGkpoWK1HF6hhy/it/u=38785274,1357847304&fm=26&gp=0.jpg"
"hoverURL":"https://ss2.bdstatic.com/70cFvnSh_Q1YnxGkpoWK1HF6hhy/it/u=38785274,1357847304&fm=26&gp=0.jpg"
任选其一,写出图片源地址正则表达式,如下所示:
re_bds='"hoverURL":"(.*?)"'
编写程序代码
下面使用 Requests 库的相应方法和属性编写程序代码,最终实现一个快速下载照片的小程序。
- # -*- coding:utf8 -*-
- import requests
- import re
- from urllib import parse
- import os
- class BaiduImageSpider(object):
- def __init__(self):
- self.url = 'https://image.baidu.com/search/flip?tn=baiduimage&word={}'
- self.headers = {'User-Agent':'Mozilla/4.0'}
- # 获取图片
- def get_image(self,url,word):
- #使用 requests模块得到响应对象
- res= requests.get(url,headers=self.headers)
- # 更改编码格式
- res.encoding="utf-8"
- # 得到html网页
- html=res.text
- print(html)
- #正则解析
- pattern = re.compile('"hoverURL":"(.*?)"',re.S)
- img_link_list = pattern.findall(html)
- #存储图片的url链接
- print(img_link_list)
- # 创建目录,用于保存图片
- directory = 'C:/Users/Administrator/Desktop/image/{}/'.format(word)
- # 如果目录不存在则创建,此方法常用
- if not os.path.exists(directory):
- os.makedirs(directory)
- #添加计数
- i = 1
- for img_link in img_link_list:
- filename = '{}{}_{}.jpg'.format(directory, word, i)
- self.save_image(img_link,filename)
- i += 1
- #下载图片
- def save_image(self,img_link,filename):
- html = requests.get(url=img_link,headers=self.headers).content
- with open(filename,'wb') as f:
- f.write(html)
- print(filename,'下载成功')
- # 入口函数
- def run(self):
- word = input("您想要谁的照片?")
- word_parse = parse.quote(word)
- url = self.url.format(word_parse)
- self.get_image(url,word)
- if __name__ == '__main__':
- spider = BaiduImageSpider()
- spider.run()
程序执行结果如下图:
图2:程序执行图
目录文件下载图如下所示:
图3:程序执行结果
18requests库常用操作
Requests 库中定义了七个常用的请求方法,这些方法各自有着不同的作用,在这些请求方法中 requests.get() 与 requests.post() 方法最为常用。请求方法如下所示:
|
常用请求方法 |
|
|
方法 |
说明 |
|
requests.request() |
构造一个请求对象,该方法是实现以下各个方法的基础。 |
|
requests.get() |
获取HTML网页的主要方法,对应于 HTTP 的 GET 方法。 |
|
requests.head() |
获取HTML网页头信息的方法,对应于 HTTP 的 HEAD 方法。 |
|
requests.post() |
获取 HTML 网页提交 POST请求方法,对应于 HTTP 的 POST。 |
|
requests.put() |
获取HTML网页提交PUT请求方法,对应于 HTTP 的 PUT。 |
|
requests.patch() |
获取HTML网页提交局部修改请求,对应于 HTTP 的 PATCH。 |
|
requests.delete() |
获取HTML页面提交删除请求,对应于 HTTP 的 DELETE。 |
上述方法都提供了相同的参数,其中某些参数已经使用过,比如headers和params,前者用来构造请求头,后者用来构建查询字符串。这些参数对于编写爬虫程序有着至关重要的作用。本节对其他常用参数做重点介绍。
SSL认证-verify参数
SSL 证书是数字证书的一种,类似于驾驶证、护照和营业执照。因为配置在服务器上,也称为 SSL 服务器证书。SSL 证书遵守 SSL 协议,由受信任的数字证书颁发机构 CA(电子认证服务)颁发。 SSL 具有服务器身份验证和数据传输加密功能。
verify参数的作用是检查 SSL 证书认证,参数的默认值为 True,如果设置为 False 则表示不检查 SSL证书,此参数适用于没有经过 CA 机构认证的 HTTPS 类型的网站。其使用格式如下:
- response = requests.get(
- url=url,
- params=params,
- headers=headers,
- verify=False
- )
代理IP-proxies参数
一些网站为了限制爬虫从而设置了很多反爬策略,其中一项就是针对 IP 地址设置的。比如,访问网站超过规定次数导致流量异常,或者某个时间段内频繁地更换浏览器访问,存在上述行为的 IP 极有可能被网站封杀掉。
代理 IP 就是解决上述问题的,它突破了 IP 地址的访问限制,隐藏了本地网络的真实 IP,而使用第三方 IP 代替自己去访问网站。
1) 代理IP池
通过构建代理 IP 池可以让你编写的爬虫程序更加稳定,从 IP 池中随机选择一个 IP 去访问网站,而不使用固定的真实 IP。总之将爬虫程序伪装的越像人,它就越不容易被网站封杀。当然代理 IP 也不是完全不能被察觉,通过端口探测技等术识仍然可以辨别。其实爬虫与反爬虫永远相互斗争的,就看谁的技术更加厉害。
2) proxies参数
Requests 提供了一个代理 IP 参数proxies,该参数的语法结构如下:
proxies = {
'协议类型(http/https)':'协议类型://IP地址:端口号'
}
下面构建了两个协议版本的代理 IP,示例如下:
proxies = {
'http':'http://IP:端口号',
'https':'https://IP:端口号'
}
3) 代理IP使用
下面通过简单演示如何使用proxies参数,示例如下:
- import requests
-
- url = 'http://httpbin.org/get'
- headers = {
- 'User-Agent':'Mozilla/5.0'
- }
- # 网上找的免费代理ip
- proxies = {
- 'http':'http://191.231.62.142:8000',
- 'https':'https://191.231.62.142:8000'
- }
- html = requests.get(url,proxies=proxies,headers=headers,timeout=5).text
- print(html)
输出结果:
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Cache-Control": "max-age=259200",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0",
"X-Amzn-Trace-Id": "Root=1-605073b0-4f54db1b2d2cfc0c074a1193"
},
# 注意此处显示两个IP,第一个是你自己的真实IP,另外一个是对外展示的IP
"origin": "121.17.25.194, 191.235.72.144",
"url": "http://httpbin.org/get"
}
由于上述示例使用的是免费代理 IP,因此其质量、稳定性较差,可能会随时失效。如果想构建一个稳定的代理 IP 池,就需要花费成本。
4) 付费代理IP
网上有许多提供代理 IP 服务的网 站,比如快代理、代理精灵、齐云代理等。这些网站也提供了相关文档说明,以及 API 接口,爬虫程序通过访问 API 接口,就可以构建自己的代理 IP 池。
付费代理 IP 按照资源类型可划分为:开发代理、私密代理、隧道代理、独享代理,其中最常使用的是开放代理与私密代理。
开放代理:开放代理是从公网收集的代理服务器,具有 IP 数量大,使用成本低的特点,全年超过 80% 的时间都能有 3000 个以上的代理 IP 可供提取使用。
私密代理:私密代理是基于云主机构建的高品质代理服务器,为您提供高速、可信赖的网络代理服务。私密代理每天可用 IP 数量超过 20 万个,可用率在 95 %以上,1 次可提取 IP 数量超过 700 个,可以为爬虫业务提供强大的助力。
付费代理的收费标准根据 IP 使用的时间长短,以及 IP 的质量高低,从几元到几百元不等。89 免费代理(http://www.89ip.cn/)是一个专门提供免费代理 IP 的网站,不过想找到一个质量较高的免费代理好比大海捞针。
用户认证-auth参数
Requests 提供了一个auth参数,该参数的支持用户认证功能,也就是适合那些需要验证用户名、密码的网站。auth 的参数形式是一个元组,其格式如下:
auth = ('username','password')
其使用示例如下所示:
- class xxxSpider(object):
- def __init__(self):
- self.url = 'http://code.tarena.com.cn/AIDCode/aid1906/13Redis/'
- # 网站使用的用户名,密码
- self.auth = ('c语言中文网','c.biancheng.net')
-
- def get_headers(self):
- headers = {'User-Agent':"Mozilla/5.0"}
- return headers
-
- def get_html(self,url):
- res = requests.get(url,headers=self.get_headers(),auth=self.auth)
- html = res.content
- return html
- ...
如果想更多地了解关于 Requests 库的参数,可以参考官方文档:https://requests.readthedocs.io/zh_CN/latest/
19Proxy SwitchyOmega
Proxy SwitchyOmega 是一款非常优秀的浏览器插件,适用于 Chrome 和 Firefox,它可以轻松快捷地管理和切换 IP 代理。
下载安装插件
Proxy SwitchyOmega 下载安装非常简单,除了通过 Chrome 应用商店安装之外,还可以直接访问官方网站下载相应的版本,网址为:https://proxy-switchyomega.com/download/,下载完成后,插件会被自动安装到浏览器扩展程序中,如下所示:
图1:Proxy SwitchyOmega
安装完成后,将管理工具固定在浏览器地址栏的右侧,以方便后续使用。如下图所示:
图2:固定扩展程序
简单使用说明
下面对该扩展程序做简单的使用说明。点击右上角刚刚安装的扩展程序,在弹出的会话框中点击“选项”,进入 SwitchyOmega 主界面, 如下所示:
图3:SwitchyOmega 界面
1) 新建情景模式
SwitchyOmega 自带 proxy(代理模式) 与 auto switch(自动切换模式),除此之外,你也可以自定义情景模式。如上图 2 所示,点击“新建情景模式” 会弹出如下会话框:
图4:新建情景模式
按照图 3 进行相关操作,输入自定义的情景模式名称,并选择“代理服务器”类型,最后点击“创建”按钮。
2) 配置代理服务器
创建完成后,在弹出的会话框内完成代理服务器参数配置,如下图所示:
图5:代理服务器配置
配置完成后切记要点击“应用选项”,否则配置不能生效。
注意:在配置代理服务前,您应该拥有一个代理 IP,否则不能配置成功。SwitchyOmega 插件只帮助管理代理 IP,不提供代理 IP 服务器。
3) 应用代理服务器
最后一步:启动配置好的代理服务器,其流程如下图所示:
图5:启用代理服务器
上图所示,“直接连接”是不使用任何代理,直接访问网页;“系统代理”则是使用当前计算机的 Internet 代理设置,而 "auto switch" 是根据自定义的列表规则,自动切换 IP 访问网站,从而避免手动切换代理 IP 的麻烦。
4) 验证代理 IP
按照上述步骤配置完成后,您就可以使用代理服务器去访问网站了。接下来,通过查询本机 IP 验证是否正在使用代理 IP,如下所示:
图 6:查询本机IP
此时本机的真实 IP 已经隐藏起来,当我们通过谷歌浏览器访问任何网站时,都不会留下真实的 IP 信息。如果想取消代理服务,可以直接点击“系统代理”或者“直接连接”,两者任选其一即可实现取消,当然您也可直接关闭拓展程序。
python之爬虫二的更多相关文章
- python简单爬虫(二)
上一篇简单的实现了获取url返回的内容,在这一篇就要第返回的内容进行提取,并将结果保存到html中. 一 . 需求: 抓取主页面:百度百科Python词条 https://baike.baidu. ...
- 【Python网络爬虫二】使用urllib2抓去网页内容
在Python中通过导入urllib2组件,来完成网页的抓取工作.在python3.x中被改为urllib.request. 爬取具体的过程类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求 ...
- Python网络爬虫(二)
Urllib库之解析链接 Urllib库里有一个parse这个模块,定义了处理URL的标准接口,实现 URL 各部分的抽取,合并以及链接转换.它支持如下协议的 URL 处理:file.ftp.goph ...
- python网络爬虫之自动化测试工具selenium[二]
目录 前言 一.获取今日头条的评论信息(request请求获取json) 1.分析数据 2.获取数据 二.获取今日头条的评论信息(selenium请求获取) 1.分析数据 2.获取数据 房源案例(仅供 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- python 网络爬虫(二) BFS不断抓URL并放到文件中
上一篇的python 网络爬虫(一) 简单demo 还不能叫爬虫,只能说基础吧,因为它没有自动化抓链接的功能. 本篇追加如下功能: [1]广度优先搜索不断抓URL,直到队列为空 [2]把所有的URL写 ...
- python入门(二十讲):爬虫
什么是爬虫? 按照一定的规则,自动地抓取万维网信息的程序或脚本. 爬虫目的: 从网上爬取出来大量你想获取类型的数据,然后用来分析大量数据的类似点或者其他信息来对你所进行的工作提供帮助. 为什么选择py ...
- python 网络爬虫(二)
一.编写第一个网络爬虫 为了抓取网站,我们需要下载含有感兴趣的网页,该过程一般被称为爬取(crawling).爬取一个网站有多种方法,而选择哪种方法更加合适,则取决于目标网站的结构. 首先探讨如何安全 ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
随机推荐
- eclipse静态资源保存不重启(热部署静态资源/html)
简单的来说就是windows->Prefrence->搜索 build automatically 并勾选就可以 不同的版本设置选项可能略微不同,其实比较简单但是新手可能不好找,所以帮到的 ...
- 针对“RuntimeError: each element in list of batch should be of equal size” 问题解决
第一次运行代码出现了这个问题: 这个问题的出现主要来源于DataLoader类中的collate.py文件造成的问题,由于每个batch里的长度不一致,因此导致出现了该问题. 通过百度方法和查看源码去 ...
- aop的一些方注释介绍
//定义切入点 @Pointcut("execution(void com.itheima.dao.BookDao.update())") private void pt2(){} ...
- Charles4.5.1抓取HTTPS请求
Charles下载以后发现 抓取http请求是成功的: 抓取https请求是失败的: 按照失败提示设置即可: 1.点击 Help -> SSL Proxying -> install ch ...
- STL练习-简单计算器
读入一个只包含 +, -, *, / 的非负整数计算表达式,计算该表达式的值. Input 测试输入包含若干测试用例,每个测试用例占一行,每行不超过200个字符,整数和运算符之间用一个空格分隔.没有非 ...
- winIO介绍
WinIO程序库允许在32位的Windows应用程序中直接对I/O端口和物理内存进行存取操作.通过使用一种内核模式的设备驱动器和其它几种底层编程技巧,它绕过了Windows系统的保护机制. 因为需要加 ...
- Deepin20安装pip3和Pydev插件
1. 安装jdk(见前面) 2. 安装eclipse(见前面) 3. Deepin20里已经有python3.7.3和python2.7.16,我们可以直接使用3.7.3,也是默认的python3.还 ...
- 安装DevExpress VCL,使用时报错 某单元文件找不到的解决办法
1.新建一个工程做为测试 2.点击projecct-->options 3. 4. 5.在上4图上的红框内加入packages文件 dxCoreRS27;dxGDIPlusRS27;dxComn ...
- 关于UPD章节学习的一些感想
课程看到了UDP, 首先了解UDP的原理模型. 服务端,首先是实例QUdpSocket,也就是UDP套接字,然后,需要绑定.绑定一个任意IP地址,分为IPV4和IPV6.自行选择课程中讲解时绑定的是I ...
- java 转换指定文件夹文件编码工具
import java.io.*; public class test { public static void main(String[] args) { printFiles(new File(& ...