基于Apache Hudi和Debezium构建CDC入湖管道
从 Hudi v0.10.0 开始,我们很高兴地宣布推出适用于 Deltastreamer 的 Debezium 源,它提供从 Postgres 和 MySQL 数据库到数据湖的变更捕获数据 (CDC) 的摄取。有关详细信息请参阅原始 RFC
1. 背景

当想要对来自事务数据库(如 Postgres 或 MySQL)的数据执行分析时,通常需要通过称为更改数据捕获 CDC的过程将此数据引入数据仓库或数据湖等 OLAP 系统。 Debezium 是一种流行的工具,它使 CDC 变得简单,其提供了一种通过读取更改日志来捕获数据库中行级更改的方法,通过这种方式 Debezium 可以避免增加数据库上的 CPU 负载,并确保捕获包括删除在内的所有变更。
现在 Apache Hudi 提供了 Debezium 源连接器,CDC 引入数据湖比以往任何时候都更容易,因为它具有一些独特的差异化功能。 Hudi 可在数据湖上实现高效的更新、合并和删除事务。 Hudi 独特地提供了 Merge-On-Read 写入器,与使用 Spark 或 Flink 的典型数据湖写入器相比,该写入器可以显着降低摄取延迟。 最后,Apache Hudi 提供增量查询,因此在从数据库中捕获更改后可以在所有后续 ETL 管道中以增量方式处理这些更改下游。
2. 总体设计
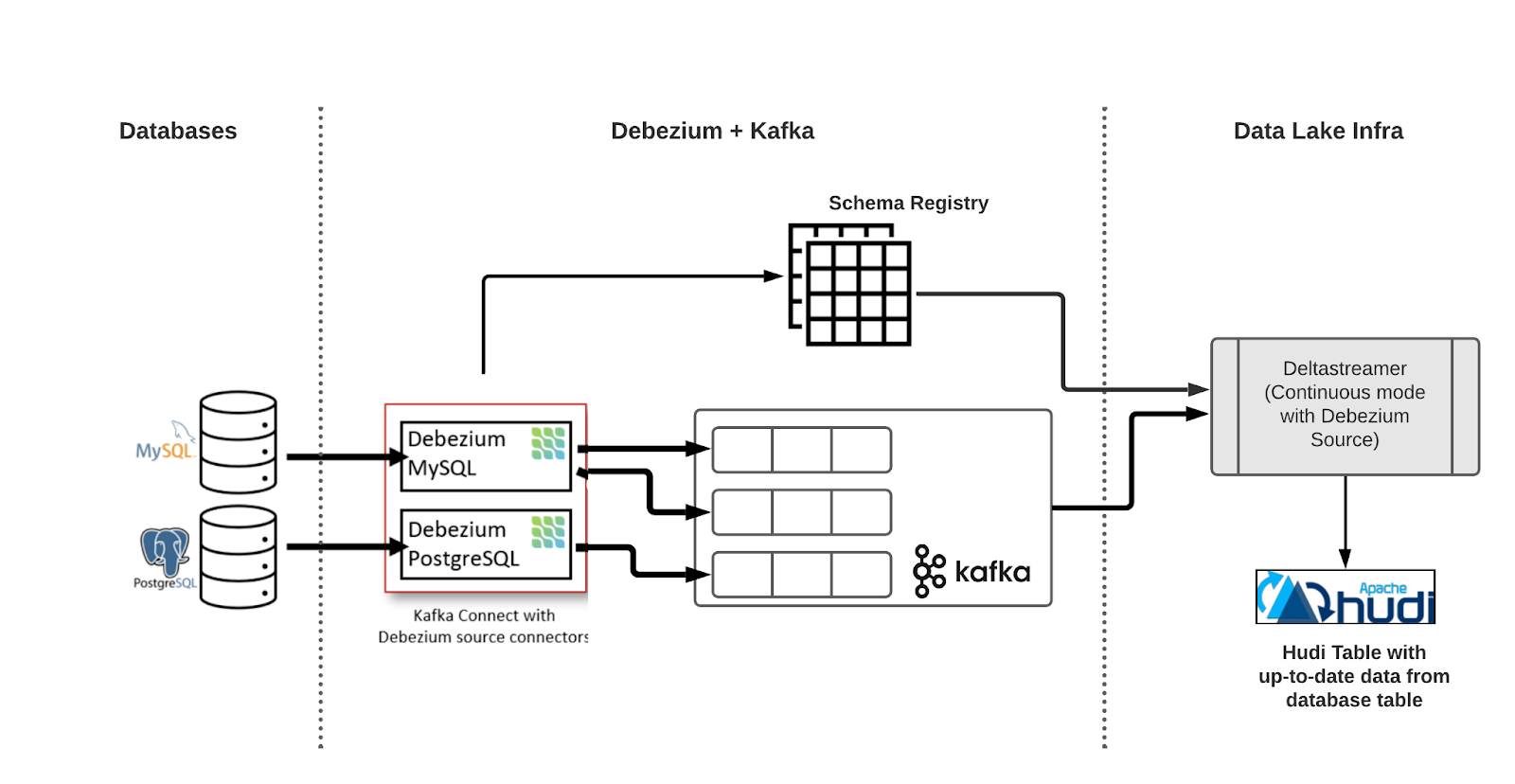
上面显示了使用 Apache Hudi 的端到端 CDC 摄取流的架构,第一个组件是 Debezium 部署,它由 Kafka 集群、schema registry(Confluent 或 Apicurio)和 Debezium 连接器组成,Debezium 连接器不断轮询数据库中的更改日志,并将每个数据库行的更改写入 AVRO 消息到每个表的专用 Kafka 主题。
第二个组件是 Hudi Deltastreamer,它为每个表从 Kafka 读取和处理传入的 Debezium 记录,并在云存储上的 Hudi 表中写入(更新)相应的行。
为了近乎实时地将数据库表中的数据提取到 Hudi 表中,我们实现了两个可插拔的 Deltastreamer 类。首先我们实现了一个 Debezium 源。 Deltastreamer 在连续模式下运行,源源不断地从给定表的 Kafka 主题中读取和处理 Avro 格式的 Debezium 更改记录,并将更新的记录写入目标 Hudi 表。 除了数据库表中的列之外,我们还摄取了一些由 Debezium 添加到目标 Hudi 表中的元字段,元字段帮助我们正确地合并更新和删除记录,使用Schema Registry表中的最新模式读取记录。
其次我们实现了一个自定义的 Debezium Payload,它控制了在更新或删除同一行时如何合并 Hudi 记录,当接收到现有行的新 Hudi 记录时,有效负载使用相应列的较高值(MySQL 中的 FILEID 和 POS 字段以及 Postgres 中的 LSN 字段)选择最新记录,在后一个事件是删除记录的情况下,有效负载实现确保从存储中硬删除记录。 删除记录使用 op 字段标识,该字段的值 d 表示删除。
3. Apache Hudi配置
在使用 Debezium 源连接器进行 CDC 摄取时,请务必考虑以下 Hudi 部署配置。
- 记录键 - 表的 Hudi 记录键应设置为上游数据库中表的主键。这可确保正确应用更新,因为记录键唯一地标识 Hudi 表中的一行。
- 源排序字段 - 对于更改日志记录的重复数据删除,源排序字段应设置为数据库上发生的更改事件的实际位置。 例如我们分别使用 MySQL 中的 FILEID 和 POS 字段以及 Postgres 数据库中的 LSN 字段来确保记录在原始数据库中以正确的出现顺序进行处理。
- 分区字段 - 不要将 Hudi 表的分区与与上游数据库相同的分区字段相匹配。当然也可以根据需要为 Hudi 表单独设置分区字段。
3.1 引导现有表
一个重要的用例可能是必须对现有数据库表进行 CDC 摄取。在流式传输更改之前我们可以通过两种方式获取现有数据库数据:
- 默认情况下,Debezium 在初始化时执行数据库的初始一致快照(由 config snapshot.mode 控制)。在初始快照之后它会继续从正确的位置流式传输更新以避免数据丢失。
- 虽然第一种方法很简单,但对于大型表,Debezium 引导初始快照可能需要很长时间。或者我们可以运行 Deltastreamer 作业,使用 JDBC 源直接从数据库引导表,这为用户定义和执行引导数据库表所需的更优化的 SQL 查询提供了更大的灵活性。引导作业成功完成后,将执行另一个 Deltastreamer 作业,处理来自 Debezium 的数据库更改日志,用户必须在 Deltastreamer 中使用检查点来确保第二个作业从正确的位置开始处理变更日志,以避免数据丢失。
3.2 例子
以下描述了使用 AWS RDS 实例 Postgres、基于 Kubernetes 的 Debezium 部署和在 Spark 集群上运行的 Hudi Deltastreamer 实施端到端 CDC 管道的步骤。
3.3 数据库
RDS 实例需要进行一些配置更改才能启用逻辑复制。
SET rds.logical_replication to 1 (instead of 0)
psql --host=<aws_rds_instance> --port=5432 --username=postgres --password -d <database_name>;
CREATE PUBLICATION <publication_name> FOR TABLE schema1.table1, schema1.table2;
ALTER TABLE schema1.table1 REPLICA IDENTITY FULL;
3.4 Debezium 连接器
Strimzi 是在 Kubernetes 集群上部署和管理 Kafka 连接器的推荐选项,或者可以选择使用 Confluent 托管的 Debezium 连接器。
kubectl create namespace kafka
kubectl create -f https://strimzi.io/install/latest?namespace=kafka -n kafka
kubectl -n kafka apply -f kafka-connector.yaml
kafka-connector.yaml 的示例如下所示:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: debezium-kafka-connect
annotations:
strimzi.io/use-connector-resources: "false"
spec:
image: debezium-kafka-connect:latest
replicas: 1
bootstrapServers: localhost:9092
config:
config.storage.replication.factor: 1
offset.storage.replication.factor: 1
status.storage.replication.factor: 1
可以使用以下包含 Postgres Debezium 连接器的 Dockerfile 构建 docker 映像 debezium-kafka-connect
FROM confluentinc/cp-kafka-connect:6.2.0 as cp
RUN confluent-hub install --no-prompt confluentinc/kafka-connect-avro-converter:6.2.0
FROM strimzi/kafka:0.18.0-kafka-2.5.0
USER root:root
RUN yum -y update
RUN yum -y install git
RUN yum -y install wget
RUN wget https://repo1.maven.org/maven2/io/debezium/debezium-connector-postgres/1.6.1.Final/debezium-connector-postgres-1.6.1.Final-plugin.tar.gz
RUN tar xzf debezium-connector-postgres-1.6.1.Final-plugin.tar.gz
RUN mkdir -p /opt/kafka/plugins/debezium && mkdir -p /opt/kafka/plugins/avro/
RUN mv debezium-connector-postgres /opt/kafka/plugins/debezium/
COPY --from=cp /usr/share/confluent-hub-components/confluentinc-kafka-connect-avro-converter/lib /opt/kafka/plugins/avro/
USER 1001
一旦部署了 Strimzi 运算符和 Kafka 连接器,我们就可以启动 Debezium 连接器。
curl -X POST -H "Content-Type:application/json" -d @connect-source.json http://localhost:8083/connectors/
以下是设置 Debezium 连接器以生成两个表 table1 和 table2 的更改日志的配置示例。
connect-source.json 的内容如下
{
"name": "postgres-debezium-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "localhost",
"database.port": "5432",
"database.user": "postgres",
"database.password": "postgres",
"database.dbname": "database",
"plugin.name": "pgoutput",
"database.server.name": "postgres",
"table.include.list": "schema1.table1,schema1.table2",
"publication.autocreate.mode": "filtered",
"tombstones.on.delete":"false",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "<schema_registry_host>",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "<schema_registry_host>",
"slot.name": "pgslot"
}
}
3.5 Hudi Deltastreamer
接下来我们使用 Spark 运行 Hudi Deltastreamer,它将从 kafka 摄取 Debezium 变更日志并将它们写入 Hudi 表。 下面显示了一个这样的命令实例,它适用于 Postgres 数据库。 几个关键配置如下:
- 将源类设置为 PostgresDebeziumSource。
- 将有效负载类设置为 PostgresDebeziumAvroPayload。
- 为 Debezium Source 和 Kafka Source 配置模式注册表 URL。
- 将记录键设置为数据库表的主键。
- 将源排序字段 (dedup) 设置为 _event_lsn
spark-submit \\
--jars "/home/hadoop/hudi-utilities-bundle_2.12-0.10.0.jar,/usr/lib/spark/external/lib/spark-avro.jar" \\
--master yarn --deploy-mode client \\
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer /home/hadoop/hudi-packages/hudi-utilities-bundle_2.12-0.10.0-SNAPSHOT.jar \\
--table-type COPY_ON_WRITE --op UPSERT \\
--target-base-path s3://bucket_name/path/for/hudi_table1 \\
--target-table hudi_table1 --continuous \\
--min-sync-interval-seconds 60 \\
--source-class org.apache.hudi.utilities.sources.debezium.PostgresDebeziumSource \\
--source-ordering-field _event_lsn \\
--payload-class org.apache.hudi.common.model.debezium.PostgresDebeziumAvroPayload \\
--hoodie-conf schema.registry.url=https://localhost:8081 \\
--hoodie-conf hoodie.deltastreamer.schemaprovider.registry.url=https://localhost:8081/subjects/postgres.schema1.table1-value/versions/latest \\
--hoodie-conf hoodie.deltastreamer.source.kafka.value.deserializer.class=io.confluent.kafka.serializers.KafkaAvroDeserializer \\
--hoodie-conf hoodie.deltastreamer.source.kafka.topic=postgres.schema1.table1 \\
--hoodie-conf auto.offset.reset=earliest \\
--hoodie-conf hoodie.datasource.write.recordkey.field=”database_primary_key” \\
--hoodie-conf hoodie.datasource.write.partitionpath.field=partition_key \\
--enable-hive-sync \\
--hoodie-conf hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.MultiPartKeysValueExtractor \\
--hoodie-conf hoodie.datasource.write.hive_style_partitioning=true \\
--hoodie-conf hoodie.datasource.hive_sync.database=default \\
--hoodie-conf hoodie.datasource.hive_sync.table=hudi_table1 \\
--hoodie-conf hoodie.datasource.hive_sync.partition_fields=partition_key
4. 总结
这篇文章介绍了用于 Hudi Deltastreamer 的 Debezium 源,以将 Debezium 更改日志提取到 Hudi 表中。 现在可以将数据库数据提取到数据湖中,以提供一种经济高效的方式来存储和分析数据库数据。
请关注此 JIRA 以了解有关此新功能的更多信息。
基于Apache Hudi和Debezium构建CDC入湖管道的更多相关文章
- 基于 Apache Hudi 和DBT 构建开放的Lakehouse
本博客的重点展示如何利用增量数据处理和执行字段级更新来构建一个开放式 Lakehouse. 我们很高兴地宣布,用户现在可以使用 Apache Hudi + dbt 来构建开放Lakehouse. 在深 ...
- 基于Apache Hudi 的CDC数据入湖
作者:李少锋 文章目录: 一.CDC背景介绍 二.CDC数据入湖 三.Hudi核心设计 四.Hudi未来规划 1. CDC背景介绍 首先我们介绍什么是CDC?CDC的全称是Change data Ca ...
- 基于Apache Hudi在Google云构建数据湖平台
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品.多年来数据以多种方式存储在计算机中, ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...
- 字节跳动基于Apache Hudi构建EB级数据湖实践
来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动推荐系统中EB级数据量实践的分享. 接下来将分为场景需求.设计选型.功能支持.性能调优.未来展望五部分介绍Hudi在字节跳动推荐系统中的 ...
- 基于Apache Hudi构建分析型数据湖
为了有机地发展业务,每个组织都在迅速采用分析. 在分析过程的帮助下,产品团队正在接收来自用户的反馈,并能够以更快的速度交付新功能. 通过分析提供的对用户的更深入了解,营销团队能够调整他们的活动以针对特 ...
- Uber基于Apache Hudi构建PB级数据湖实践
1. 引言 从确保准确预计到达时间到预测最佳交通路线,在Uber平台上提供安全.无缝的运输和交付体验需要可靠.高性能的大规模数据存储和分析.2016年,Uber开发了增量处理框架Apache Hudi ...
随机推荐
- kkFileView对接svn服务完成文件在线预览功能
1.需求: 之前在公司内部搭建了svn服务器,给部门存放文档.视频,做成了一个文档服务器来用,随着视频文件太大,每次下载太慢 需要把文件在线打开查看 2.解决: kkFileView https:// ...
- kubernetes允许master调度
1,让 Master 也当作 Node 使用 (1)如果想让 Pod 也能调度到在 Master(本样例即 localhost.localdomain)上,可以执行如下命令使其作为一个工作节点: 注意 ...
- 6月25日 Django 分页 cookie、session
cookie Cookie的由来 大家都知道HTTP协议是无状态的. 无状态的意思是每次请求都是独立的,它的执行情况和结果与前面的请求和之后的请求都无直接关系,它不会受前面的请求响应情况直接影响,也不 ...
- SpringCloudAlibaba 微服务讲解(一)微服务介绍
微服务介绍 1.1 系统架构的演变 随若互联网的发展,网站应用的规模也在不断的扩大,逬而导致系统架构也在不断的进行变化.从互联 网早起到现在,系统架构大体经历了下面几个过程:单体应用架构一蟻直应用架构 ...
- 抖音网页版高清视频抓取教程selenium
废话不多说,直接上代码 from selenium import webdriver from selenium.webdriver import ChromeOptions import time ...
- bzoj5315/luoguP4517 [JSOI2018]防御网络(仙人掌,dp)
bzoj5315/luoguP4517 防御网络(仙人掌,dp) bzoj Luogu 题目描述略(太长了) 题解时间 本题和斯坦纳树无关. 题面保证了是一个仙人掌...? 但这个环之间甚至交点都没有 ...
- 《前端运维》三、Docker--2其他
一.制作DockerFile docker的镜像类似于用一层一层的文件组成.inspect命令可以查看镜像或容器的的信息,其中Layers就是镜像的层文件,只读不能修改,基于镜像创建的容器会共享这些层 ...
- 【技术干货】华为云FusionInsight MRS的自研超级调度器Superior Scheduler
Superior Scheduler是一个专门为Hadoop YARN分布式资源管理系统设计的调度引擎,是针对企业客户融合资源池,多租户的业务诉求而设计的高性能企业级调度器. Superior Sch ...
- python3 使用mongo数据库
0让服务器端开启服务 sudo mongod --port 27017 --dbpath /data/db --logpath /data/log --logappend --fork --auth ...
- javascript的比较运算符
JavaScript一共提供了8个比较运算符: > 大于运算符 < 小于运算符 <= 小于等于运算符 >= 大于等于运算符 == 相等运算符 === 严格相等运算符 != 不相 ...