【Python爬虫案例】用Python爬取李子柒B站视频数据
一、视频数据结果
今天是2021.12.7号,前几天用python爬取了李子柒的油管评论并做了数据分析,可移步至:
https://www.cnblogs.com/mashukui/p/16220254.html
这次呢,用python爬虫爬了李子柒B站的所有视频数据。
先看下,最终爬取到的视频数据:
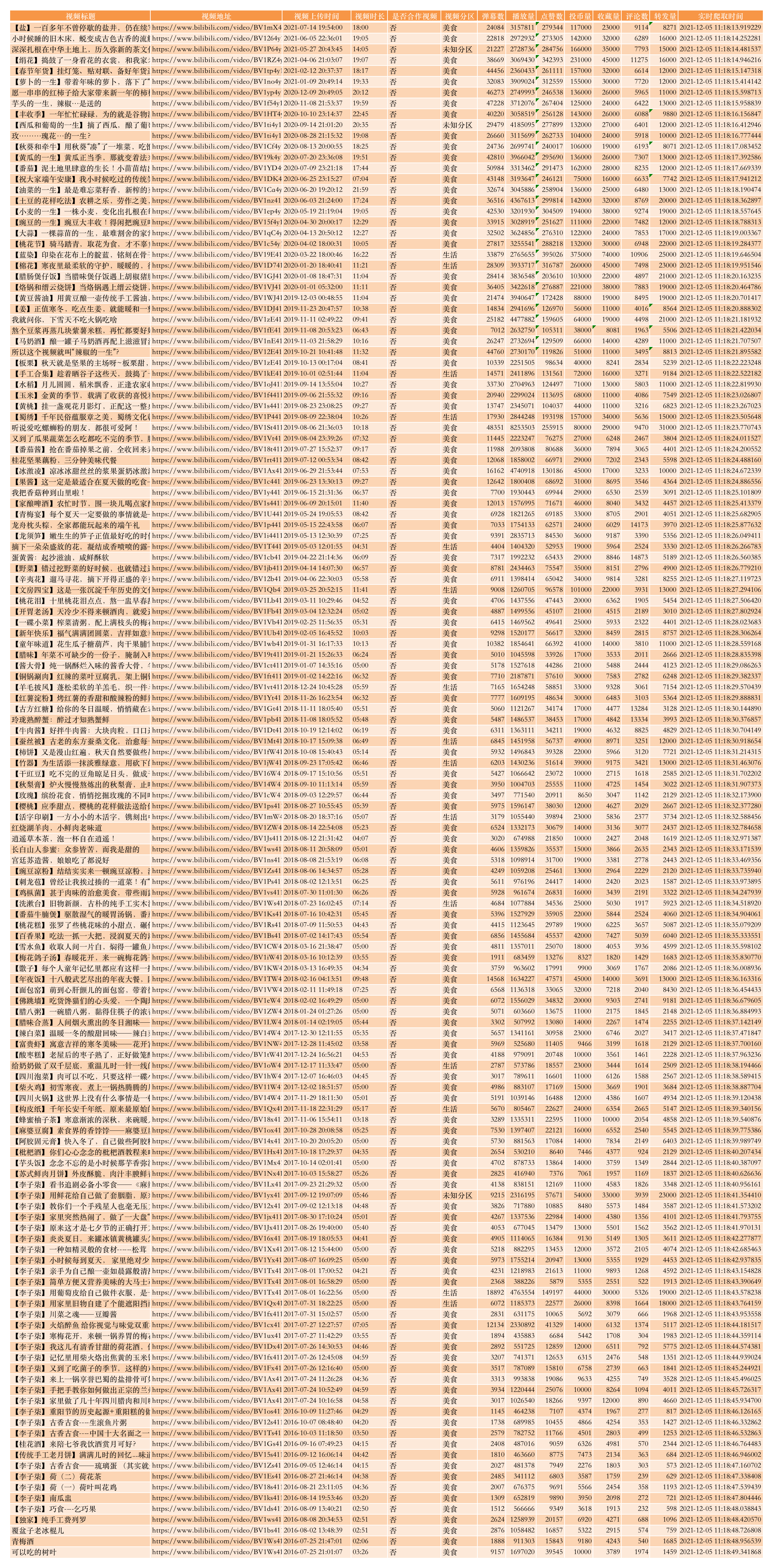
一共是142条视频数据(截至目前,李子柒在B站一共上传过142个视频)
每条数据包含的字段是:
视频标题,视频地址,视频上传时间,视频时长,是否合作视频,视频分区,弹幕数,播放量,点赞数,投币量,收藏量,评论数,转发量,实时爬取时间
基本上涵盖了视频的所有属性字段。
二、部分核心代码
这里,我分享下部分核心代码:
url_list = [] # 视频地址
title_list = [] # 视频标题
author_list = [] # UP主昵称
mid_list = [] # UP主UID
create_time_list = [] # 上传时间
play_count_list = [] # 播放数
length_list = [] # 视频时长
comment_count_list = [] # 评论数
is_union_list = [] # 是否合作视频
type_list = [] # 分区
danmu_count_list = [] # 弹幕数
for i in range(1, 10): # 前10页
url = 'https://api.bilibili.com/x/space/arc/search?mid=19577966&ps=30&tid=0&pn={}&keyword=&order=pubdate&jsonp=jsonp'.format(
str(i))
r = requests.get(url, headers=headers)
print(r.status_code) # 响应码200
json_data = r.json()
pprint(json_data)
video_list = json_data['data']['list']['vlist']
pprint(video_list)
for i in video_list:
bvid = i['bvid']
url = 'https://www.bilibili.com/video/' + bvid
url_list.append(url)
title = i['title']
title_list.append(title)
author = i['author']
author_list.append(author)
mid = i['mid']
mid_list.append(mid)
create_time = i['created']
create_time = trans_date(v_timestamp=create_time)
create_time_list.append(create_time)
play_count = i['play']
play_count_list.append(play_count)
length = i['length']
length_list.append(length)
comment = i['comment']
comment_count_list.append(comment)
is_union = '是' if i['is_union_video'] == 1 else '否'
is_union_list.append(is_union)
type_name = get_video_type(v_num=i['typeid'])
type_list.append(type_name)
danmu_count = i['video_review']
danmu_count_list.append(danmu_count)
其中,把url中的mid换成B站任意up主的对应mid,都可以进行爬取!!
其中,把url中的mid换成B站任意up主的对应mid,都可以进行爬取!!
其中,把url中的mid换成B站任意up主的对应mid,都可以进行爬取!!
三、同步讲解视频
代码逐行讲解:
https://www.zhihu.com/zvideo/1451862342237229056
四、获取python源码文件
爱学习的小伙伴,想获取完整python代码文件,关注我的微信公众号"老男孩的平凡之路",后台回复关键字"李子柒B站爬虫",即可获取完整python源码及数据!
我是马哥,全网累计粉丝上万,欢迎一起交流python技术。
各平台搜索“马哥python说”:知乎、哔哩哔哩、小红书、新浪微博。
【Python爬虫案例】用Python爬取李子柒B站视频数据的更多相关文章
- Python爬虫+可视化教学:爬取分析宠物猫咪交易数据
前言 各位,七夕快到了,想好要送什么礼物了吗? 昨天有朋友私信我,问我能用Python分析下网上小猫咪的数据,是想要送一只给女朋友,当做礼物. Python从零基础入门到实战系统教程.源码.视频 网上 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- Python爬虫:通过关键字爬取百度图片
使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一.搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界 ...
随机推荐
- Ls 命令执行什么功能? 可以带哪些参数,有什么区别?
ls 执行的功能: 列出指定目录中的目录,以及文件哪些参数以及区别: a 所有文件 l 详细信息,包括大小字节数,可读可写可执行的权限等
- JDBC 中如何进行事务处理?
Connection 提供了事务处理的方法,通过调用 setAutoCommit(false)可以设置 手动提交事务:当事务完成后用 commit()显式提交事务:如果在事务处理过程中 发生异常则通过 ...
- java中的函数式接口
是什么?? 有且只有一个抽象方法的接口 场景: 适用于函数式编程场景(使用lambda表达式编程)的接口,函数式接口可以适用于lambda使用的接口. 只有确保接口中有且只有一个抽象方法,java中的 ...
- Java 中的 LinkedList 是单向链表还是双向链表?
是双向链表,你可以检查 JDK 的源码.在 Eclipse,你可以使用快捷键 Ctrl + T, 直接在编辑器中打开该类.
- 什么是多线程环境下的伪共享(false sharing)?
伪共享是多线程系统(每个处理器有自己的局部缓存)中一个众所周知的性能问 题.伪共享发生在不同处理器的上的线程对变量的修改依赖于相同的缓存行,如 下图所示: 伪共享问题很难被发现,因为线程可能访问完全不 ...
- Eclipse 从SVN检出项目之《文件夹 “” 已不存在 》
1.eclipse 从svn检出项目 报文件夹不存在, 参考博客 https://blog.csdn.net/wenbsu/article/details/80965680 2.You need to ...
- Clickhouse-alter 对副本表修改表结构报元数据错误
[应用场景] 对分片副本表的列进行 alter 操作 [问题复现] [解决办法] 检查该分片所有副本表的表结构和 zk 上存储的 column 信息保持一致,检查本地的表结构 sql 文件 /data ...
- 用vue开发一个猫眼电影web app
前言:之前一直在学习原生的javascript,但是无奈功力太浅,学了很长时候也只能写一些简单的小demo,知道遇见了vue,一切都变了,他的双向绑定和组件化思想让我迅速的爱上了他,可是光学不练是没有 ...
- node-webkit文档翻译#package.json
title: node-webkit文档翻译#package.json date: 2013-12-07 21:38:25 tags: node-webkit 基本示例 { "main&qu ...
- HTML5相关文章和资源
Polyfills HTML5 Cross Browser Polyfills canvas HTML5 JS实现毛玻璃效果(高斯模糊) 高斯模糊的算法Canvas 内部元素添加事件处理 应用场景 P ...