大曝光!从RabbitMQ平滑迁移至Kafka架构设计方案!
历史原因,公司存在多个 MQ 同时使用的问题,我们中间件团队在去年下半年开始支持对 Kafka 和 Rabbit 能力的进行封装,初步能够完全支撑业务团队使用。
鉴于在之前已经基本完全实施 Kafka 管控平台、以及 Kafka 集群迁移管控,我们基本可以认为团队对于 Kafka 的把控能力初具规模。
因此,考虑到以下几点原因,我们决定对 RabbitMQ 不再做维护和支持。
原因
使用混乱和维护困难
基于我们的数据统计和分析发现,基本上没有服务使用我们自己封装的 RabbitMQ 能力,用到的基本上是spring-amqp或者原生的Rabbit 使用方式,存在使用混乱,方式不统一的问题,对于排查问题方面存在更多的问题。
另外考虑到对于 MQ 能力支持要做双份,Kafka 和 Rabbit 都要支持相同的功能,对于人力资源方面存在浪费,当然也由于本身目前没有对 RabbitMQ 非常精通的同学,所以对于维护能力这方面存在担忧。
分区容错问题
RabbitMQ 集群对于网络分区的容错性不高,根据调查发现,系统中 RabbitMQ 高可用方案使用镜像队列,而当 RabbitMQ 出现网络分区时,不同分区里的节点会认为不属于自身所在分区的节点都已经挂了,对于队列、交换器、绑定的操作仅对当前分区有效。
而且,如果原集群中配置了镜像队列,而这个镜像队列又牵涉两个或者更多个网络分区中的节点时,每一个网络分区中都会出现一个 master 节点,对于各个网络分区,此队列都是相互独立的。
在默认的情况下,架构本身存在脑裂的风险,在 3.1 版本下是无法自动恢复的,之后的版本才会自动探测网络分区,人工介入存在数据丢失的风险。
性能瓶颈
镜像队列解决了 Rabbit 高可用的问题,但是并不能增加负载和性能,线上曾经出现过 RabbitMQ 在高流量下的性能问题,就是因为队列由单个节点承载流量,在高并发情况在集群中单个节点存在性能瓶颈。
即便我们目前大部分场景下 MQ 流量不高,但是一旦出现问题,将成为整个系统的性能瓶颈。
另外我们对 Rabbit 做了一些性能方面的测试:
测试集群一共有 4 台磁盘节点,其中每台 16 核,如果我们不做 Sharding,单队列最高 TPS 在 5K 左右,如果是内存节点,官方可以给出的处理极限为 50K/s,如果做 Sharding,单队列处理能力可以达到 10K/s。
上述结论都是以消息能够被正常快速消费为前提,实际上在高流量或者大量消息积压的情况会导致集群性能急剧下降。
运维&管控
基于以上现有的问题和难点,我们决定对 Rabbit 进行全量迁移至 Kafka,以便能在业务高速发展过程中能够保障对于稳定性、高可用、高性能方面的追求。
在方法论和理论体系层面,我们对业务生产有三板斧:可灰度、可监控、可回滚。
同样,对于消息中间件平台运维我们希望有三板斧:可运维、可观测、可管控,那么目前基于 Kafka 的集群管控和 Kafka Manager 的能力我们已经基本做到了上述几点。
- 高可用:根据自身经验,Kafka 本身拥有极高的平台可用性
- 高性能:Kafka 可支撑极高的 TPS,并且支持水平扩展,可快速满足业务的流量增长需求
- 功能支持:在原有两个 MQ 能力基础上,基础支持顺序消息、延时消息、灰度消息、消息轨迹等
- 运维管控:基于 Kafka Manager 基础上进行二次开发,丰富管控能力和运维支撑能力,提供给开发、运维、测试更好的使用体验和运维能力。
模型对比
RabbitMQ
Exchange:生产者将消息发送到Exchange,由交换器将消息通过匹配Exchange Type、Binding Key、Routing Key后路由到一个或者多个队列中。
Queue:用于存储消息,消费者直接绑定Queue进行消费消息
Routing Key:生产者发送消息给 Exchange 会指定一个Routing Key。
Binding Key:在绑定Exchange与Queue时会指定一个Binding Key。
Exchange Type:
- Direct:把消息路由到那些 Binding Key 和 Routing Key 完全匹配的队列中
- Fanout:把消息转发给所有与它绑定的队列上,相当于广播模式
- Topic:通过对消息的 Routing Key 和 Exchange、Queue 进行匹配,将消息路由给一个或多个队列,发布/订阅模式
- Headers:根据消息的 Header 将消息路由到不同的队列,和 Routing Key 无关
Kafka
Topic:发送消息的主题,对消息的组织形式
Broker:Kafka 服务端
Consumer Group:消费者组
Partition:分区,topic 会由多个分区组成,通常每个分区的消息都是按照顺序读取的,不同的分区无法保证顺序性,分区也就是我们常说的数据分片sharding机制,主要目的就是为了提高系统的伸缩能力,通过分区,消息的读写可以负载均衡到多个不同的节点上
迁移方案
综上,我们将要对系统中所有使用RabbitMQ的服务进行迁移操作,整个迁移我们应该保证以下 3 点:
- 操作便捷,不能过于复杂,复杂会带来更多的不可控风险
- 风险可控,尽最大可能降低迁移对业务的影响
- 不影响业务正常运行
消费者双订阅
- 对消费者进行改造,同时监听 Rabbit 和 Kafka 消息
- 对生产者进行改造,迁移至Kafka发送消息
- 等待 Rabbit 遗留消息消费完毕之后,直接下线即可
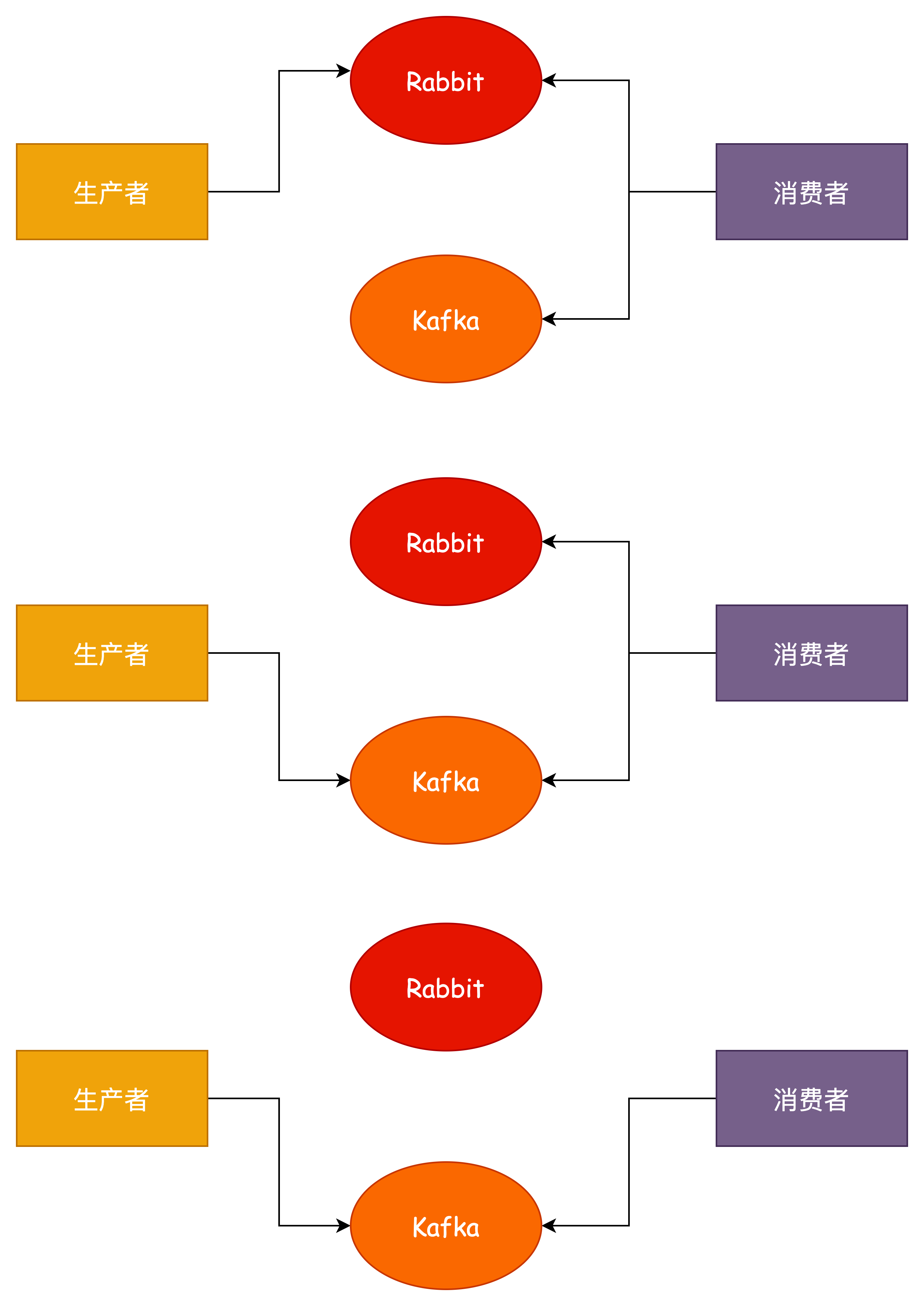
优点:可以做到无损迁移
缺点:
- 需要同时维护两套监听代码,可能有大量的工作量,迁移完成之后还需要再进行一次老代码下线
- 消息无法保证顺序性
基于灰度单订阅
这是基于双订阅模式的优化,通过使用我们的灰度/蓝绿发布的能力,做到可以不双订阅,不用同时监听两个消息队列的消息。
- 直接修改消费者代码,发布灰度/蓝节点,监听 Kafka 消息
- 生产者改造,往 Kafka 发送消息
- 等待老的 Rabbit 消息消费完毕,下线,这里存在一个问题就是在进行灰度之后全量的过程中可能造成消息丢失的情况,对于这个问题的解决方案要区分来看,如果业务允许少量的丢失,那么直接全量即可,否则需要对业务做一定的改造,比如增加开关,全量之前关闭发送消息,等待存量消息消费完毕之后再全量。
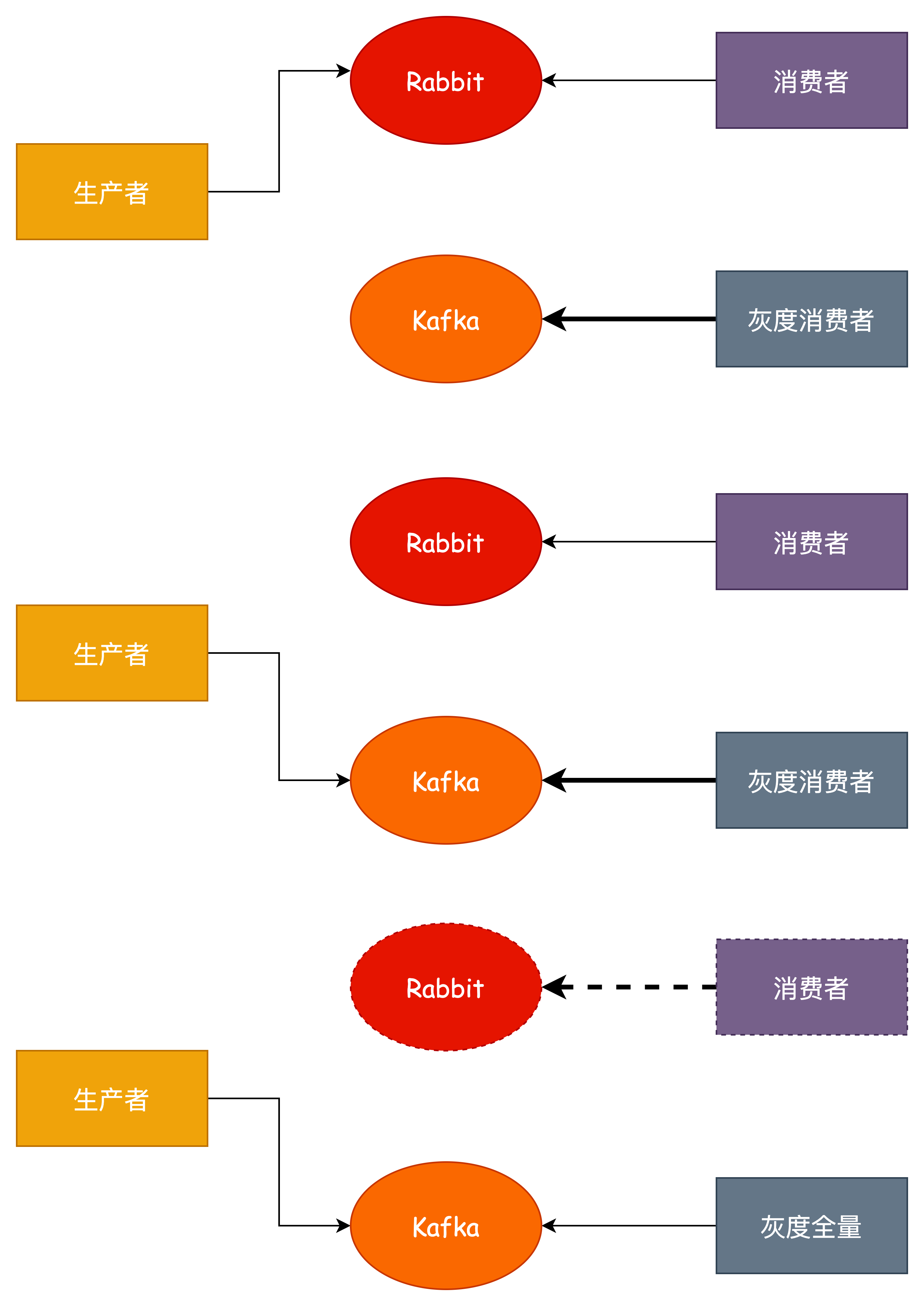
优点:
- 基于双订阅方案改造,可以做到不同时监听两个队列的消息,减少工作量
- 可以做到无损迁移
缺点:同样无法保证消息有序性
实际场景问题
上述只是针对现状的迁移方案考虑,那么还有一些跟实际和复杂的问题可能需要考虑。
比如消息的场景有可能不是这种简单的发布/订阅关系,可能存在网状、环状的发布/订阅关系,该如何处理?
其实是一样的道理,只要我们能够梳理清楚每个 Exchange 之间的发布/订阅的关系,针对每个 Exchange 进行操作,就能达到一样的平滑迁移效果。
我们要做的就是针对每个 Exchange 进行迁移,而不是针对服务,否则迁移是无法进行下去的,但是这样带来的另外一个问题就是每个服务需要发布多次,而且如果碰到多个复杂消费或者生产的情况要特别小心。
实施细节
基于现状,我们对所有 Rabbit Exchange 的情况进行了详细的统计,将针对不同的 Exchange 和类型以及功能使用以下方式处理。
- 无用的Exchange、无生产者或者无消费者,还有没有任何流量的,可以直接删除
- Fanout 类型,Exchange 对应 Topic,Queue 对应 Consumer Group,还有存在使用随机队列的,需要对应多个Consumer Group(单独做一个简单的能力封装处理)
- Direct 类型,RoutingKey 对应 Topic,Queue 对应 Consumer Group
- Topic 类型,RoutingKey 对应 Topic,Queue 对应 Consumer Group,实际并未发现使用到通配符情况
- 延迟队列、重试等功能,基于 spring-kafka 做二次封装
验证&监控&灰度&回滚
验证
- 迁移后针对 Rabbit 验证,通过管理平台流量或者日志输出来确认,而且现状是大部分 Exchange 流量都比较小,所以可能需要自行发送消息验证迁移效果。
- 迁移后针对 Kafka 流量进行验证可以通过 Kafka Manager 平台或者日志
监控
监控通过 Kafka Manager 平台或者现有监控
灰度
方案本身 Consumer 和 Producer 都可以直接灰度发布,预发验证
回滚
服务回滚,按照发布顺序控制回退顺序
巨人的肩膀:
大曝光!从RabbitMQ平滑迁移至Kafka架构设计方案!的更多相关文章
- 从RabbitMQ平滑迁移到RocketMQ技术实战
作者:vivo 互联网中间件团队- Liu Runyun 大量业务使用消息中间件进行系统间的解耦.异步化.削峰填谷设计实现.公司内部前期基于RabbitMQ实现了一套高可用的消息中间件平台.随着业务的 ...
- RabbitMQ,RocketMQ,Kafka 几种消息队列的对比
常用的几款消息队列的对比 前言 RabbitMQ 优点 缺点 RocketMQ 优点 缺点 Kafka 优点 缺点 如何选择合适的消息队列 参考 常用的几款消息队列的对比 前言 消息队列的作用: 1. ...
- 关于消息队列的使用----ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ
一.消息队列概述消息队列中间件是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削锋等问题,实现高性能,高可用,可伸缩和最终一致性架构.目前使用较多的消息队列有ActiveMQ,RabbitM ...
- RDS经典网络平滑迁移到VPC的混访方案
专有网络VPC(Virtual Private Cloud)之间在逻辑上彻底隔离,可以使您在阿里云上构建出一个隔离的网络环境,其安全性及性能都高于经典网络,已成为云上用户首选的网络类型.为满足日益增多 ...
- HBase数据迁移到Kafka实战
1.概述 在实际的应用场景中,数据存储在HBase集群中,但是由于一些特殊的原因,需要将数据从HBase迁移到Kafka.正常情况下,一般都是源数据到Kafka,再有消费者处理数据,将数据写入HBas ...
- RabbitMQ,RocketMQ,Kafka 消息模型对比分析
消息模型 消息队列的演进 消息队列模型 发布订阅模型 RabbitMQ的消息模型 交换器的类型 direct topic fanout headers Kafka的消息模型 RocketMQ的消息模型 ...
- ActiveMQ、RabbitMQ、RocketMQ、Kafka四种消息中间件分析介绍
ActiveMQ.RabbitMQ.RocketMQ.Kafka四种消息中间件分析介绍 我们从四种消息中间件的介绍到基本使用,以及高可用,消息重复性,消息丢失,消息顺序性能方面进行分析介绍! 一.消息 ...
- 《黑客大曝光》实践部分——sql注入(7/8)
SQL注入实践 由于<黑客大曝光>中涉及到形形色色的攻击方式,从软件到硬件,甚至还有物理锁的开锁教程,当中的很多教程很有趣,但是我没有相关的环境,实践起来不好操作,比如说,查点扫描我还可以 ...
- 大数据平台Hive数据迁移至阿里云ODPS平台流程与问题记录
一.背景介绍 最近几天,接到公司的一个将当前大数据平台数据全部迁移到阿里云ODPS平台上的任务.而申请的这个ODPS平台是属于政务内网的,因考虑到安全问题当前的大数据平台与阿里云ODPS的网络是不通的 ...
- ActiveMQ、RabbitMQ、RocketMQ、Kafka 对比(图示)
RabbitMQ 和 Kafka 对比,一篇好的介绍文章:https://my.oschina.net/u/236698/blog/501834 ActiveMQ.RabbitMQ.RocketMQ. ...
随机推荐
- linux驱动移植
1.1 开发前准备 1.1.1 Linux 驱动(面向对象) 1).Linux 驱动框架 思想:写驱动的时候,只提供操作硬件设备的函数接口 文件存放磁盘: open ,read ,write ,clo ...
- kubernetes数据持久化PV-PVC详解(一)
官方文档地址: https://kubernetes.io/zh-cn/docs/concepts/storage/persistent-volumes/ 1. 什么是PV,PVC? 1.1 什么是P ...
- day11 枚举类enum & 单例模式 & 异常以及抛出
day11 枚举enum 用enum关键字定义枚举类 特点 1.用enum关键字定义枚举类 2.枚举类默认继承java.lang.Enum类 3.枚举类的构造方法只能使用private修饰,省略则默认 ...
- Qwt开发笔记(二):Qwt基础框架介绍、折线图介绍、折线图Demo以及代码详解
前言 QWT开发笔记系列整理集合,这是目前使用最为广泛的Qt图表类(Qt的QWidget代码方向只有QtCharts,Qwt,QCustomPlot),使用多年,系统性的整理,本系列旨在系统解说并 ...
- kali2021.4a安装angr(使用virtualenv)
在Linux中安装各种依赖python的软件时,最头疼的问题之一就是各个软件的python版本不匹配的问题,angr依赖python3,因此考虑使用virtualenv来安装angr Virtuale ...
- MySQL数据结构(索引)
目录 一:MySQL索引与慢查询优化 1.什么是索引? 2.索引类型分类介绍 3.不同的存储引擎支持的索引类型也不一样 二:索引的数据结构 1.二叉树(每个节点只能分两个叉) 2.数据结构(B树) 3 ...
- jQuery基本使用
目录 一:jQuery查找标签 1.基本选择器 二:分组与嵌套 三:组合选择器 四:jQuery基本筛选器 五:属性选择器 1.属性标签 六:JQuery表单筛选器 1.type属性 2.表单对象属性 ...
- AcWing786.第k个数
题目描述 给定一个长度为 \(n\) 的整数数列,以及一个整数 \(k\),请用快速选择算法求出数列从小到大排序后的第 \(k\) 个数. 输入格式 第一行包含两个整数 \(n\) 和 \(k\). ...
- MVP、原型、概念验证,傻傻分不清楚?
MVP.原型以及概念验证这三者的概念虽然没有密切的联系,但也有不少人会分不清这三者的区别,在这篇文章中,我们会帮大家区分一下这三个概念.首先是MVP,MVP是Minimum Viable Produc ...
- Hive详解(06) - Hive调优实战
Hive详解(06) - Hive调优实战 执行计划(Explain) 基本语法 EXPLAIN [EXTENDED | DEPENDENCY | AUTHORIZATION] query 案例实操 ...