基础分类算法_KNN算法
KNN(K-NearestNeighbor)算法
KNN算法是有监督学习中的分类算法.
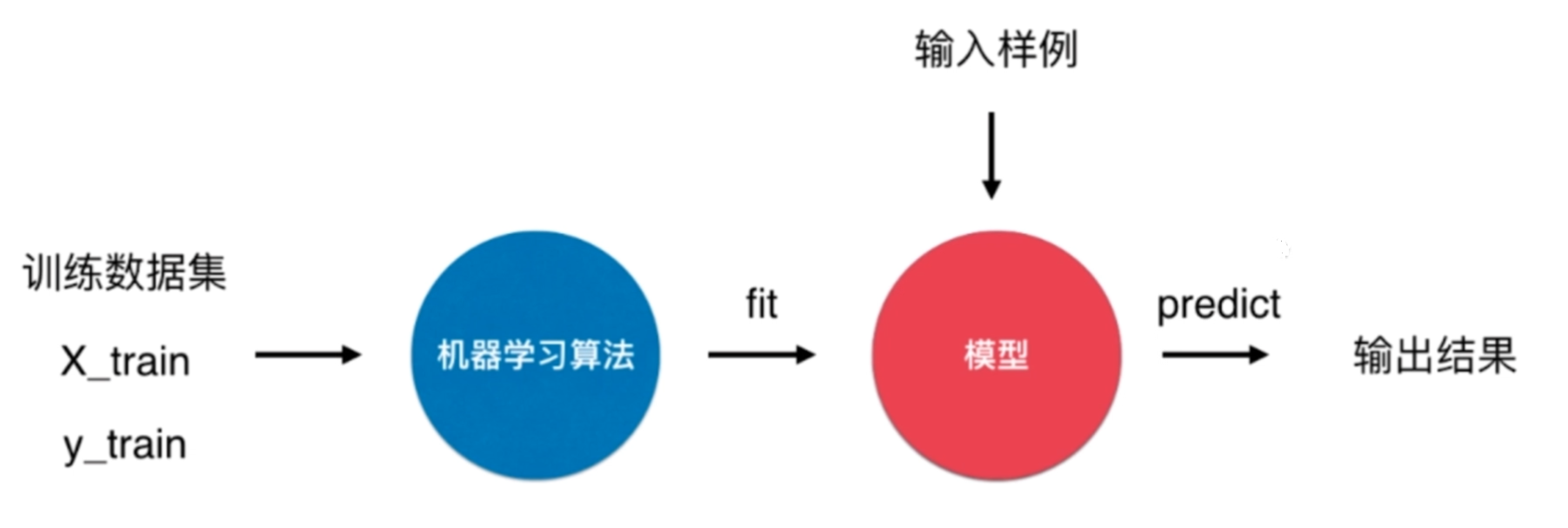
KNN算法很特殊,可以被认为是没有模型的算法,也可以认为其训练数据集就是模型本身。
KNN算法的原理
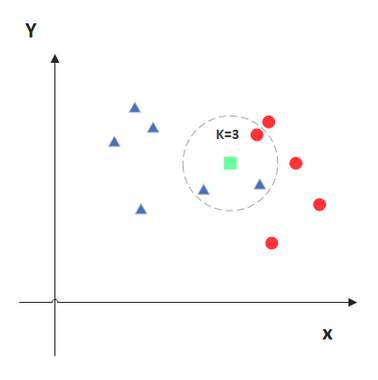
KNN的原理就是当预测一个新的值\(x\)的时候,根据它距离最近的\(K\)个点是什么类别来判断\(x\)属于哪个类别。
KNN算法的实现
实现knn算法需要计算两个点之前的距离,计算距离常用的有直线距离(欧拉距离)和曼哈顿距离。(这里使用欧拉距离来进行计算)
- 欧拉距离
\]
- 曼哈顿距离
\]
- 明可夫斯基距离
- \(p\)为超参数
- 默认值为\(2\)的时候取的为欧拉距离
\]
- 向量空间余弦相似度
一个向量空间中两个向量夹角间的余弦值作为衡量两个个体之间差异的大小,余弦值接近1,夹角趋于0,表明两个向量越相似,余弦值接近于0,夹角趋于90度,表明两个向量越不相似。
\]
- 皮尔森相关系数
两个变量之间的协方差和标准差的商
\frac{\mathrm{cov}(X,Y)}{\sigma_{X}\sigma_{Y}}
= \frac{E[(X-\mu_{x})(Y-\mu_{y})]}{\sigma_{X}\sigma_{Y}}
\]
import numpy as np
from math import sqrt
from collections import Counter
class KNN_Classifier:
def __init__(self, k):
# 初始化分类器
assert k >= 1, "k must be valid"
self.k = k
self._x_train = None
self._y_train = None
def fit(self, x_train, y_train):
# 根据训练集来训练
assert x_train.shape[0] == y_train.shape[0], \
"the size of x_train and y_train must be common"
assert self.k <= x_train.shape[0], \
"the size of train can't less than k"
self._x_train = x_train
self._y_train = y_train
return self
# 传入的需要预测的数据
def predict(self, x_predict):
assert self._x_train is not None and self._y_train is not None, \
"must fit it before predict"
assert x_predict.shape[1] == self._x_train.shape[1], \
"the feature number of x_predict must be equal to x_train"
y_predict = [self._predict(x) for x in x_predict]
return np.array(y_predict)
# 进行单个数据的预测
def _predict(self, x):
# 单个待测数据 返回预测结果
assert x.shape[0] == self._x_train.shape[1], \
"the feature number of x must be equal to x_train"
dis = [sqrt(np.sum((x_tem - x) ** 2)) for x_tem in self._x_train]
near = np.argsort(dis)
top_k = [self._y_train[i] for i in near[:self.k]]
return Counter(top_k).most_common(1)[0][0]
def __repr__(self):
return "KNN(k=%d)" % self.k
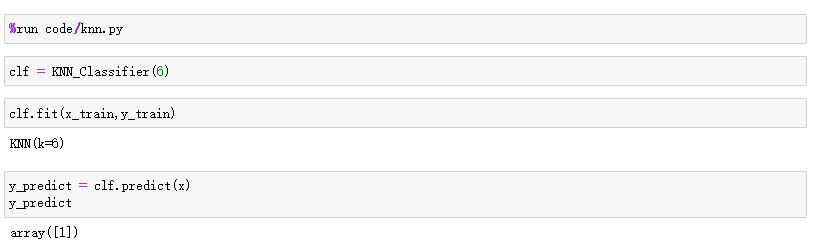
数据测试
- 测试数据
# 数据集
raw_data_x = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]]
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
x_train = np.array(raw_data_x)
y_train = np.array(raw_data_y)
# 预测数据 (需要以矩阵的方式传入)
x = np.array([8.093607318, 3.365731514]).reshape(1,-1)
- 测试结果
KNN算法的优点
- 效果好
- 思想简单
- 对异常值不敏感。
- 需要的数学知识较少
- 直观完整的刻画机器学习应用的流程
KNN算法的缺点
- 计算复杂性高;空间复杂性高。
- 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少)
- 一般数值很大的时候不用这个,计算量太大。但是单个样本又不能太少,否则容易发生误分。
- 最大的缺点是无法给出数据的内在含义。
基础分类算法_KNN算法的更多相关文章
- 01--STL算法(算法基础)
一:算法概述 算法部分主要由头文件<algorithm>,<numeric>和<functional>组成. <algorithm>是所有STL头文件中 ...
- 数据挖掘入门系列教程(二)之分类问题OneR算法
数据挖掘入门系列教程(二)之分类问题OneR算法 数据挖掘入门系列博客:https://www.cnblogs.com/xiaohuiduan/category/1661541.html 项目地址:G ...
- 【Java基础】数组和算法
数组和算法 查找算法 线性查找 ... 二分查找 二分查找要求数据结构是有序的. package com.parzulpan.java.ch03; /** * @Author : parzulpan ...
- 【java基础 8】垃圾收集算法及内存分配策略
本篇博客,主要介绍GC的收集算法以及根据算法要求所得的内存分配策略! 一.收集算法 收集算法,主要包括四种,分别是:Mark-Sweep(标记-清除).Copying(复制).Mark-Compact ...
- 最短路径算法-Dijkstra算法的应用之单词转换(词梯问题)(转)
一,问题描述 在英文单词表中,有一些单词非常相似,它们可以通过只变换一个字符而得到另一个单词.比如:hive-->five:wine-->line:line-->nine:nine- ...
- 目标检测算法YOLO算法介绍
YOLO算法(You Only Look Once) 比如你输入图像是100x100,然后在图像上放一个网络,为了方便讲述,此处使用3x3网格,实际实现时会用更精细的网格(如19x19).基本思想是, ...
- 理解Liang-Barsky裁剪算法的算法原理
0.补充知识向量点积:结果等于0, 两向量垂直; 结果大于0, 两向量夹角小于90度; 结果小于0, 两向量夹角大于90度.直线的参数方程:(x1, y1)和(x2, y2)两点确定的直线, 其参数方 ...
- 网络流入门--最大流算法Dicnic 算法
感谢WHD的大力支持 最早知道网络流的内容便是最大流问题,最大流问题很好理解: 解释一定要通俗! 如右图所示,有一个管道系统,节点{1,2,3,4},有向管道{A,B,C,D,E},即有向图一张. ...
- 数据聚类算法-K-means算法
深入浅出K-Means算法 摘要: 在数据挖掘中,K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法. K-Mea ...
- 强化学习中REIINFORCE算法和AC算法在算法理论和实际代码设计中的区别
背景就不介绍了,REINFORCE算法和AC算法是强化学习中基于策略这类的基础算法,这两个算法的算法描述(伪代码)参见Sutton的reinforcement introduction(2nd). A ...
随机推荐
- 二十三、Pod的service介绍
Pod 的 Service 介绍 一.Service 介绍 Kubernetes Service 定义了这样一种抽象: 一个 Pod 的逻辑分组,一种可以访问它们的策略,通常称为微服务. 这一组 Po ...
- idea如何生成jar包
最近在研究RMI反序列化命令执行的漏洞,让我这个java新手吃尽了苦头,能多学习一些是一些吧. 记录一下写好的java文件生成jar包的过程. 环境: Win10,jdk1.7, idea2016.2 ...
- Android10 dex2oat实践
最近看到一篇博客:Android性能优化之Android 10+ dex2oat实践,对这个优化很感兴趣,打算研究研究能否接入到项目中.不过该博客只讲述了思路,没有给完整源码.本项目参考该博客的思路, ...
- Python基础部分:3、 pycharm的下载与使用
目录 pycharm下载与使用 一.软件说明 二.版本说明 三.如何免费使用正式版软件 四.pycharm运行空间 五.文件后缀名 六.安装pycharm工具 七.pycharm的基本配置和PY文件的 ...
- 扫雷(哈希+bfs)
扫雷 题目描述: 小明最近迷上了一款名为<扫雷>的游戏. 其中有一个关卡的任务如下: 在一个二维平面上放置着 n 个炸雷,第 i 个炸雷 (x\(_i\),y\(_i\),r\(_i\)) ...
- 某厂面试:如何优雅使用 SPI 机制
代码不多,文章可能有点长.朋友面试某厂问到的 SPI 机制,联想到自己项目最近写到的 SPI 场景,文章简要描述下 SPI 机制的发展历程 产出背景 因为最近项目中使用分库分表以及数据加密使用到了 S ...
- kotlin的suspend对比csharp的async&await
协程的出现大大降低了异步编程的复杂度,可以让我们像写同步代码一样去写异步代码,如果没有它,那么很多异步的代码都是需要靠回调函数来一层层嵌套,这个在我之前的一篇有介绍 rxjava回调地狱-kotlin ...
- # Android网络请求(4) 网络请求框架Volley
Android网络请求(4) 网络请求框架Volley Volley是Google在2013年5月15日到17日在旧金山Moscone中心举办网络开发者年会中推出的Android异步网络加载框架和图片 ...
- 第2-4-3章 规则引擎Drools基础语法-业务规则管理系统-组件化-中台
目录 4. Drools基础语法 4.1 规则文件构成 4.2 规则体语法结构 4.3 注释 4.4 Pattern模式匹配 4.5 比较操作符 4.5.1 语法 4.5.2 操作步骤 4.6 执行指 ...
- vscode 更新后重启恢复旧版
vscode的自动更新自动安装在C:\Users\admin\AppData\Local\,如果之前的vscode不在默认位置,就会更新出两个版本,如果还用了固定在开始屏幕或者任务栏,则一直在打开旧版 ...