Elasticsearch中text与keyword的区别
text类型
1:支持分词,全文检索,支持模糊、精确查询,不支持聚合,排序操作;
2:test类型的最大支持的字符长度无限制,适合大字段存储;
使用场景:
存储全文搜索数据, 例如: 邮箱内容、地址、代码块、博客文章内容等。
默认结合standard analyzer(标准解析器)对文本进行分词、倒排索引。
默认结合标准分析器进行词命中、词频相关度打分。
keyword
1:不进行分词,直接索引,支持模糊、支持精确匹配,支持聚合、排序操作。
2:keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
使用场景:
存储邮箱号码、url、name、title,手机号码、主机名、状态码、邮政编码、标签、年龄、性别等数据。
用于筛选数据(例如: select * from x where status='open')、排序、聚合(统计)。
直接将完整的文本保存到倒排索引中。
Dynamic
dynamic属性:默认值为true,允许动态地向文档类型中加入新的字段。推荐设置为false,禁止向文档中添加字段,这样,文档类型的所有字段必须在索引映射的properties属性中显式定义,在properties字段中未定义的字段都将会ElasticSearch忽略。
dynamic设置为ture:默认值,新增加的字段被添加到索引映射中;
dynamic设置为false:新增加的字段会被忽略;
dynamic设置为strict:当向文档中新增字段时,ElasticSearch引擎抛出异常;
# index
index定义字段的分析类型以及检索方式,控制字段值是否被索引.他可以设置成 true 或者 false。没有被索引的字段将无法搜索
如果是no,则无法通过检索查询到该字段;
如果设置为not_analyzed则会将整个字段存储为关键词,常用于汉字短语、邮箱等复杂的字符串;
如果设置为analyzed则将会通过默认的standard分析器进行分析
# 集群分片
Elasticsearch 有一个硬编码限制,单个分片内的文档总数不得超过 2147483519 个。
一般来说这个限制在日志场景下是不太会触发的,但是如果做 TSDB 用,则需要多加注意!
ES更新到5版本后,取消了 string 数据类型,代替它的是 keyword 和 text 数据类型.那么 text 和keyword有什么区别呢?
# 添加数据
使用bulk往es数据库中批量添加一些document
POST /book/novel/_bulk
{"index": {"_id": 1}}
{"name": "Gone with the Wind", "author": "Margaret Mitchell", "date": "2018-01-01"}
{"index": {"_id": 2}}
{"name": "Robinson Crusoe", "author": "Daniel Defoe", "date": "2018-01-02"}
{"index": {"_id": 3}}
{"name": "Pride and Prejudice", "author": "Jane Austen", "date": "2018-01-01"}
{"index": {"_id": 4}}
{"name": "Jane Eyre", "author": "Charlotte Bronte", "date": "2018-01-02"}
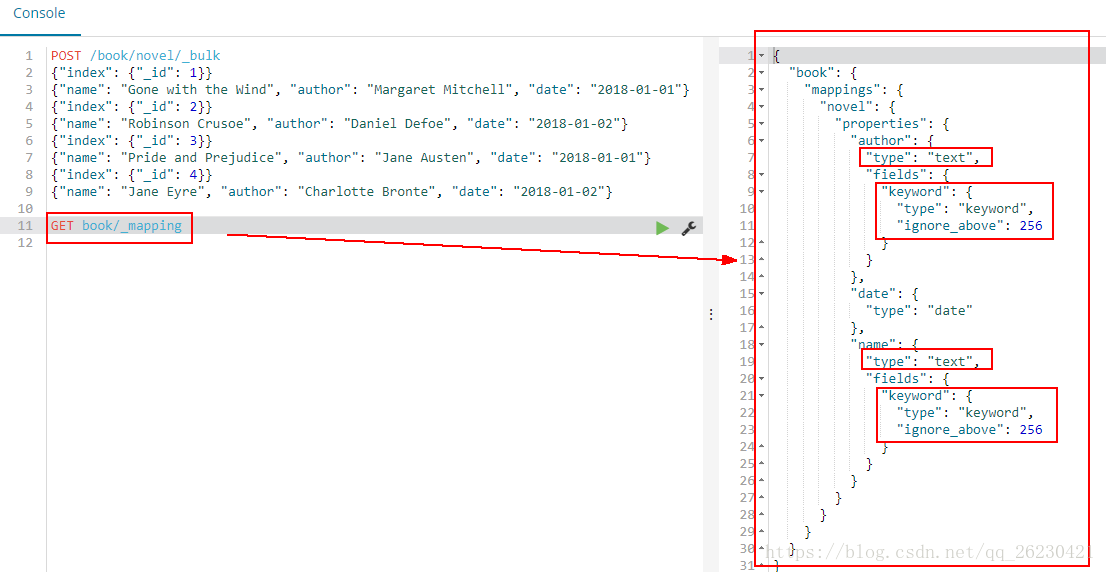
# 查看mapping
发现name、author的type是text,
还有个field是keyword,keyword的type是keyword:
# 查询
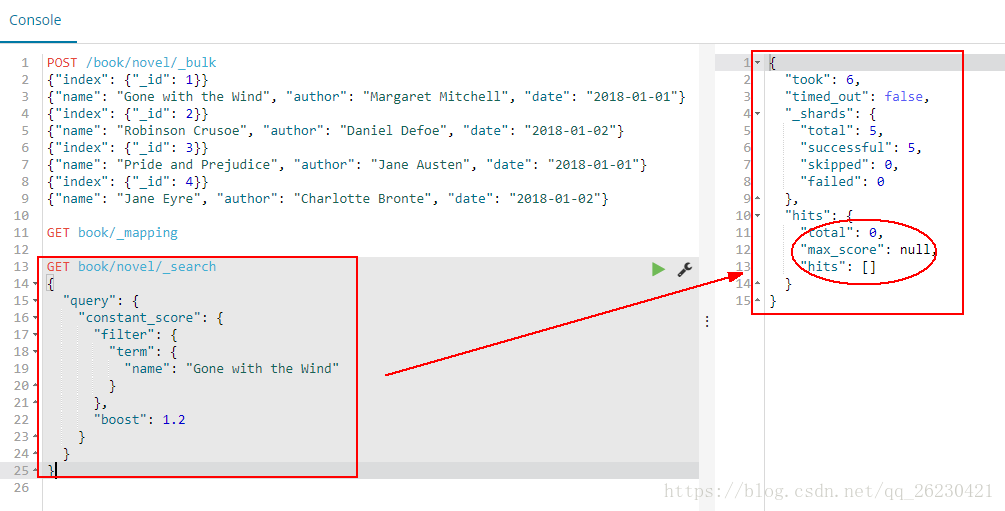
使用term查询某个小说:
GET book/novel/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"name": "Gone with the Wind"
}
},
"boost": 1.2
}
}
}
结果是什么也没有查到:
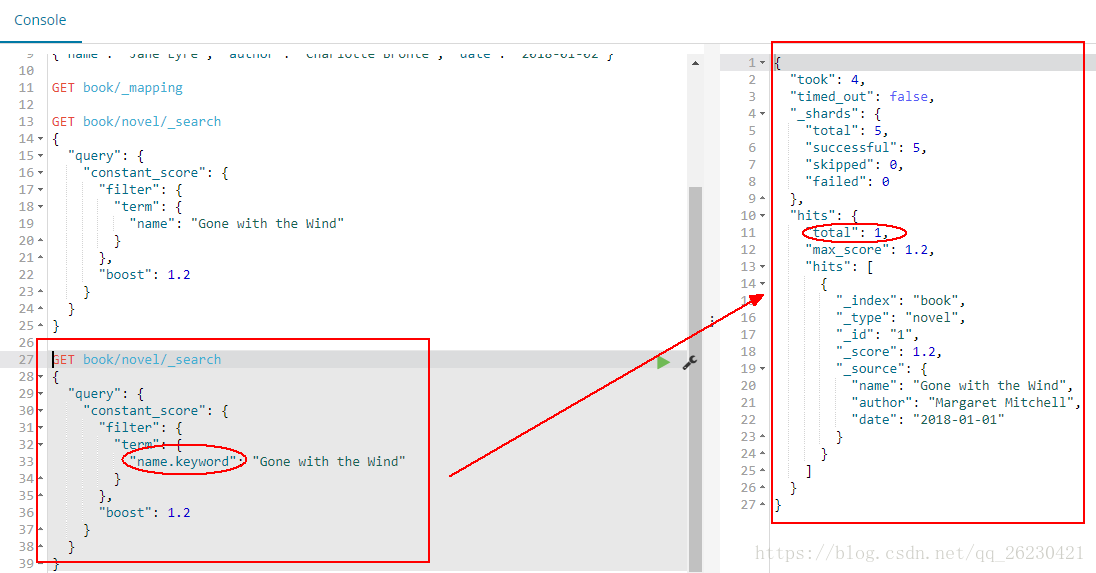
然后使用name的keyword查询:
GET book/novel/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"name.keyword": "Gone with the Wind"
}
},
"boost": 1.2
}
}
}
可以查询到一条数据:
# 实验
使用name不能查到,而使用name.keyword可以查到,我们可以通过下面的实验来判断:
使用name进行分词的时候,结果会有4个词出来:
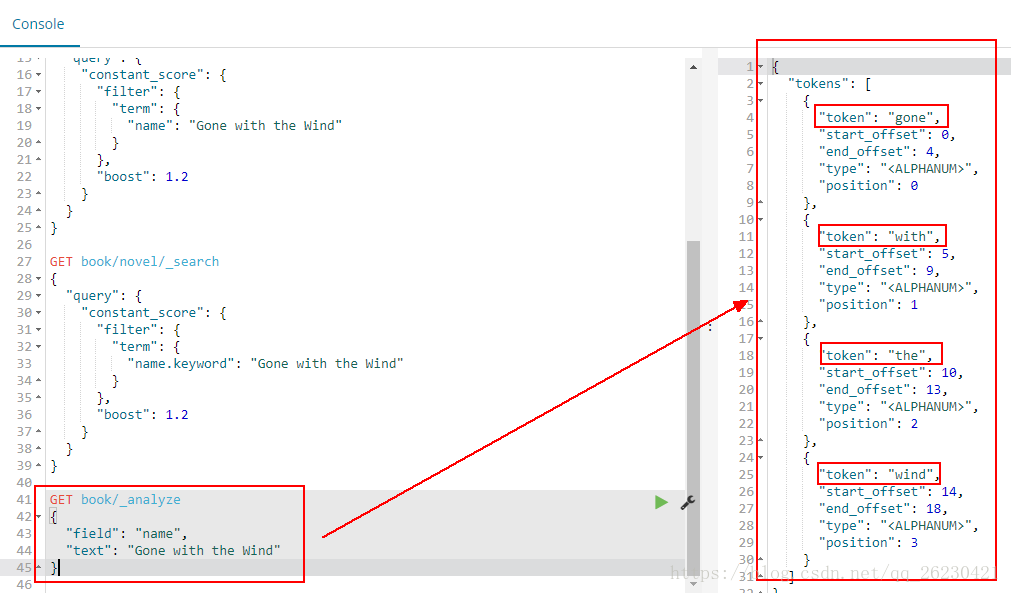
使用name.keyword进行分词的时候,结果只有一个词出来:
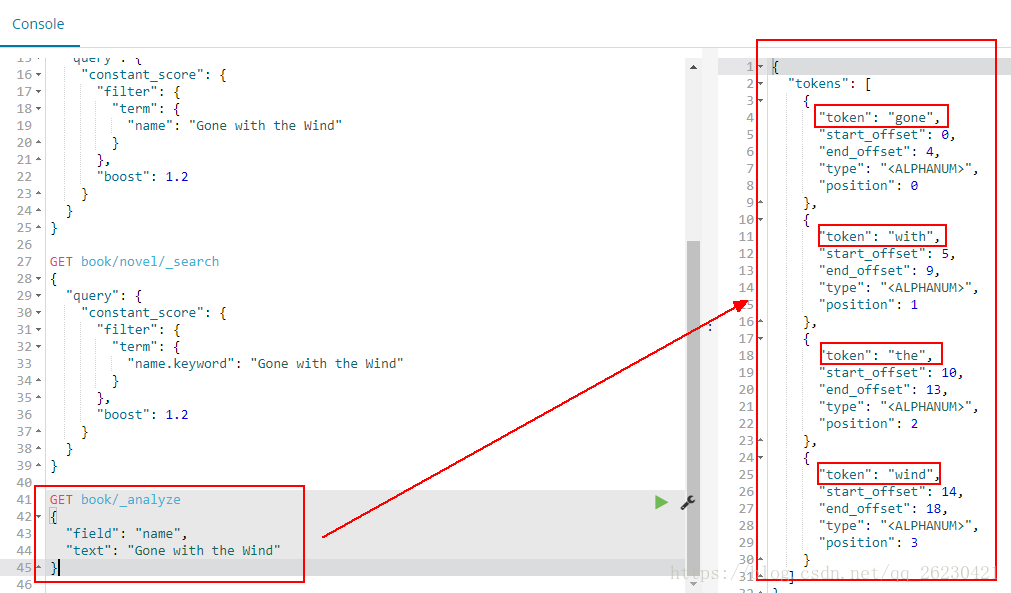
# 结论
text类型:会分词,先把对象进行分词处理,然后再再存入到es中。
当使用多个单词进行查询的时候,当然查不到已经分词过的内容!
keyword:不分词,没有把es中的对象进行分词处理,而是存入了整个对象!
这时候当然可以进行完整地查询!默认是256个字符!
作者:香山上的麻雀
链接:https://www.jianshu.com/p/1189ff372c38
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。Elasticsearch中text与keyword的区别的更多相关文章
- Elasticsearch 中数据类型 text 与 keyword 的区别
随着ElasticSearch 5.X 系列的到来, 同时也迎来了该版本的重大特性之一: 移除了string类型. 这个变动的根本原因是string类型会给我们带来很多困惑: 因为ElasticSea ...
- SQL Server中Text和varchar(max) 区别
SQL Server 2005之后版本:请使用 varchar(max).nvarchar(max) 和 varbinary(max) 数据类型,而不要使用 text.ntext 和 image 数据 ...
- JQuery中text(),html(),val()的区别
这3个都是jquery类库中的语法,分别是: text():获取或者改变指定元素的文本: html():获取或改变指定元素的html元素以及文本: val():获取或者改变指定元素的value值(一般 ...
- elasticsearch中query和filter的区别
参考博客来自: https://mp.weixin.qq.com/s/tiiveCW3W-oDIgxvlwsmXA?utm_medium=hao.caibaojian.com&utm_sour ...
- requests中text和content的区别
# -*- coding: utf-8 -*- __author__ = "nixinxin" import re img_url = "https://f11.baid ...
- jquery中text、html的区别
- ES 15 - Elasticsearch中的数据类型 (text、keyword、date、geo等)
目录 1 核心数据类型 1.1 字符串类型 - string(不再支持) 1.1.1 文本类型 - text 1.1.2 关键字类型 - keyword 1.2 数字类型 - 8种 1.3 日期类型 ...
- 【转】elasticsearch中字段类型默认显示{ "foo": { "type": "text", "fields": { "keyword": {"type": "keyword", "ignore_above": 256} }
官方原文链接:https://www.elastic.co/cn/blog/strings-are-dead-long-live-strings 转载原文连接:https://segmentfault ...
- ES索引Index相关操作&ES数据类型、字符串类型text和keyword区别
1.查看索引以及删除之前的测试索引 1. 查看索引以及索引数量信息 liqiang@root MINGW64 ~/Desktop $ curl -X GET http://127.0.0.1:9200 ...
随机推荐
- python+tkinter 的布局
from tkinter import * win = Tk() win.title("布局") # #窗口标题 win.geometry("600x500+200+20 ...
- 【填坑】树莓派4B上运行Bullseye版本系统,不能登录xrdp的问题~~
以前使用 buster,安装xrdp后 pi用户xrdp登录正常, 可自从使用了 bullseye系统,pi登录xrdp后,出现黑屏不能登录现象. 网上搜寻解决方案,一种方法是: 登录树莓派后,打开这 ...
- WPF 制作 Windows 屏保
分享如何使用WPF 制作 Windows 屏保 WPF 制作 Windows 屏保 作者:驚鏵 原文链接:https://github.com/yanjinhuagood/ScreenSaver 框架 ...
- 一步一步在angular11中添加多语言支持
1.新建angular 2.添加@angular/localize ng add @angular/localize 3.设置默认locale_id,在app.module.ts中 import { ...
- 珠联壁合地设天造|M1 Mac os(Apple Silicon)基于vscode(arm64)配置搭建Java开发环境(集成web框架Springboot)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_194 也许有人从未听说过Python,但是不会有人没听说过Java,它作为一个拥有悠久历史的老牌编程语言,常年雄踞TIOBE编程语 ...
- 关于微信豆苹果(IOS)用户1比10充值方法
微信iOS端微信7.0.20版本之后就上线了微信豆功能,相比大家对微信豆已经不陌生了. 微信官方现在给出了微信豆的含义,微信豆是用于支付微信内虚拟物品的道具,支持在视频号中购买虚拟礼物.也可以对公 ...
- BMP位图之8位位图(三)
起始结构 typedef struct tagBITMAPFILEHEADER { WORD bfType; //类型名,字符串"BM", DWORD bfSize; //文件大小 ...
- axios post请求变为options请求的解决方法
全局配置 axios.defaults.headers['Content-Type']='application/x-www-form-urlencoded' 注意:使用全局配置会导致所有请求头的'C ...
- Docker Compose之容器编排开发初探
1.前言 Docker Compose 是 Docker 官方编排(Orchestration)项目之一,负责快速在集群中部署分布式应用. Compose 是一个用于定义和运行多个 Docker 应用 ...
- 使用 Java 操作 Redis
Jedis 1. 概述 Jedis 是一款使用 Java 操作 Redis 的工具,有点类似于 JDBC 2. 引入依赖 <dependency> <groupId>redis ...