使用Kubeadm搭建高可用Kubernetes集群
1.概述
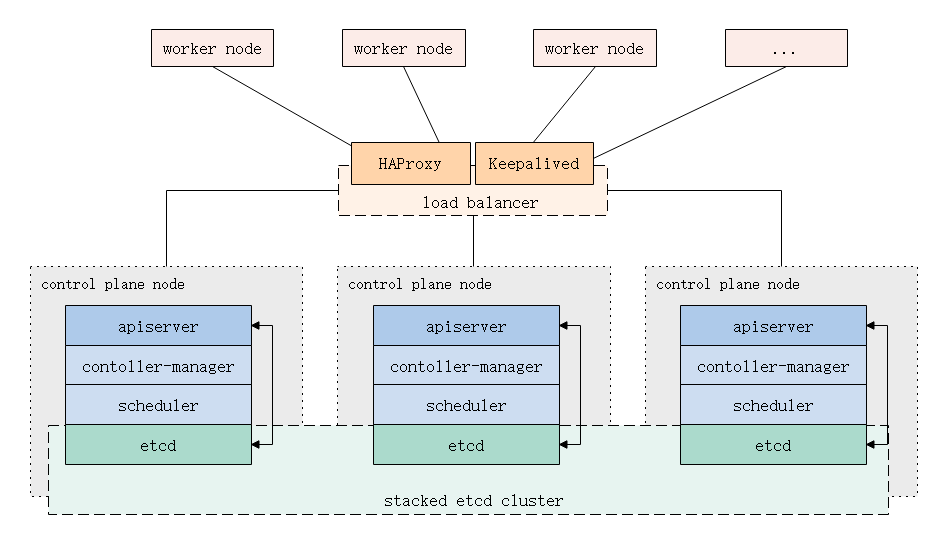
Kubenetes集群的控制平面节点(即Master节点)由数据库服务(Etcd)+其他组件服务(Apiserver、Controller-manager、Scheduler...)组成。
整个集群系统运行的交互数据都将存储到数据库服务(Etcd)中,所以Kubernetes集群的高可用性取决于数据库服务(Etcd)在多个控制平面(Master)节点构建的数据同步复制关系。
由此搭建Kubernetes的高可用集群可以选择以下两种部署方式:
使用堆叠的控制平面(Master)节点,其中etcd与组成控制平面的其他组件在同台机器上;
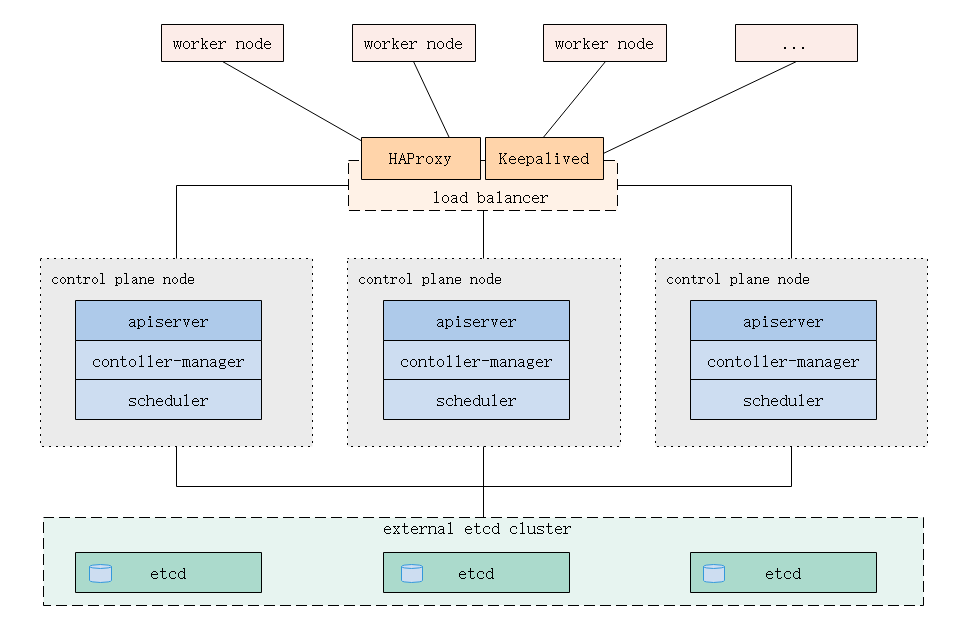
使用外部Etcd节点,其中Etcd与控制平台的其他组件在不同的机器上。
参考文档:https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/
1.1.堆叠Etcd拓扑(推荐)
Etcd与其他组件共同运行在多台控制平面(Master)机器上,构建Etcd集群关系以形成高可用的Kubernetes集群。
先决条件:
- 最少三个或更多奇数Master节点;
- 最少三个或更多Node节点;
- 集群中所有机器之间的完整网络连接(公共或专用网络);
- 使用超级用户权限;
- 在集群中的任何一个节点上都可以使用SSH远程访问;
- Kubeadm和Kubelet已经安装到机器上。
使用这种方案可以减少要使用机器的数量,降低成本,降低部署复杂度;多组件服务之间竞争主机资源,可能导致性能瓶颈,以及当Master主机发生故障时影响到所有组件正常工作。
在实际应用中,你可以选择部署更多数量>3的Master主机,则该拓扑的劣势将会减弱!
这是kubeadm中的默认拓扑,kubeadm会在Master节点上自动创建本地etcd成员。
1.2.外部Etcd拓扑
控制平面的Etcd组件运行在外部主机上,其他组件连接到外部的Etcd集群以形成高可用的Kubernetes集群。
先决条件:
- 最少三个或更多奇数Master主机;
- 最少三个或更多Node主机;
- 还需要三台或更多奇数Etcd主机。
- 集群中所有主机之间的完整网络连接(公共或专用网络);
- 使用超级用户权限;
- 在集群中的任何一个节点主机上都可以使用SSH远程访问;
- Kubeadm和Kubelet已经安装到机器上。
使用外部主机搭建起来的Etcd集群,拥有更多的主机资源和可扩展性,以及故障影响范围缩小,但更多的机器将导致增加部署成本。
2.搭建Kubernetes集群(堆叠Etcd拓扑)
2.1.运行环境与主机规划
主机系统:CentOS Linux release 7.6.1810 (Core)
Kubernetes版本:Kubernetes-1.23.0
Kubernetes与Docker兼容性:v20.10.7+不兼容 -> v20.10.12+不兼容
本文使用Docker版本:Docker-ce-19.03.0
硬件条件:集群中的机器最少需要2GB或者以上的内存,最少需要2核或者以上更多的CPU
| 主机名 | 主机地址 | 主机角色 | 运行服务 |
|---|---|---|---|
| k8s-master01 | 192.168.124.128 VIP:192.168.124.100 |
control plane node(master) | kube-apiserver etcd kube-scheduler kube-controller-manager docker kubelet keepalived ipvs |
| k8s-master02 | 192.168.124.130 VIP:192.168.124.100 |
control plane node(master) | kube-apiserver etcd kube-scheduler kube-controller-manager docker kubelet keepalived ipvs |
| k8s-master03 | 192.168.124.131 VIP:192.168.124.100 |
control plane node(master) | kube-apiserver etcd kube-scheduler kube-controller-manager docker kubelet keepalived ipvs |
| k8s-node01 | 192.168.124.133 | worker node(node) | kubelet kube-proxy docker |
2.2.检查和配置主机环境
1、验证每个主机上的MAC地址和Product_id的唯一性
所有主机上:
[root@localhost ~]# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:40:e3:9f brd ff:ff:ff:ff:ff:ff
[root@localhost ~]# cat /sys/class/dmi/id/product_uuid
B70F4D56-1F69-3997-AD55-83725A40E39F
2、检查运行Kubernetes所需的端口是否未被占用
| 角色 | 协议 | 方向 | 服务:端口范围 |
|---|---|---|---|
| Master(Control Plane) | TCP | Inbound | Kubernetes API server:6443 etcd server client API:2379-2380 Kubelet API:10250 kube-scheduler:10259 kube-controller-manager:10257 |
| Node(Worker Node) | TCP | Inbound | Kubelet API:10250 NodePort Services+:30000-32767 |
所有master主机上:
[root@localhost ~]# ss -alnupt |grep -E '6443|10250|10259|10257|2379|2380'
所有node主机上:
[root@localhost ~]# ss -alnupt |grep -E '10250|3[0-2][0-7][0-6][0-7]'
3、配置主机名称
k8s-master01:
[root@localhost ~]# echo "k8s-master01" >/etc/hostname
[root@localhost ~]# cat /etc/hostname | xargs hostname
[root@localhost ~]# bash
[root@k8s-master01 ~]#
k8s-master02:
[root@localhost ~]# echo "k8s-master02" >/etc/hostname
[root@localhost ~]# cat /etc/hostname | xargs hostname
[root@localhost ~]# bash
[root@k8s-master02 ~]#
k8s-master03:
[root@localhost ~]# echo "k8s-master03" >/etc/hostname
[root@localhost ~]# cat /etc/hostname | xargs hostname
[root@localhost ~]# bash
[root@k8s-master03 ~]#
k8s-node01:
[root@localhost ~]# echo "k8s-node01" >/etc/hostname
[root@localhost ~]# cat /etc/hostname | xargs hostname
[root@localhost ~]# bash
[root@k8s-node01 ~]#
4、添加hosts名称解析
所有主机上:
[root@k8s-master01 ~]# cat >> /etc/hosts << EOF
192.168.124.128 k8s-master01
192.168.124.130 k8s-master02
192.168.124.131 k8s-master03
192.168.124.132 k8s-node01
EOF
5、主机间时间同步
k8s-master01:
设置优先从cn.ntp.org.cn公共时间服务器上同步时间。
# 安装NTP时间服务和NTP客户端
[root@k8s-master01 ~]# yum -y install epel-release.noarch
[root@k8s-master01 ~]# yum -y install ntp ntpdate
# 使用NTP客户端从外部公共NTP时间服务器同步本机时间
[root@k8s-master01 ~]# ntpdate cn.ntp.org.cn
# 配置NTP时间服务
[root@k8s-master01 ~]# vim /etc/ntp.conf
# 访问控制
# 允许外部客户端从本机同步时间,但不允许外部客户端修改本机时间
restrict default nomodify notrap nopeer noquery
restrict 127.0.0.1
restrict ::1
# 从外部服务器主动同步时间
# 如果外部服务器连接失败时则以本机时间为准
server 127.127.1.0
Fudge 127.127.1.0 stratum 10
server cn.ntp.org.cn prefer iburst minpoll 4 maxpoll 10
server ntp.aliyun.com iburst minpoll 4 maxpoll 10
server ntp.tuna.tsinghua.edu.cn iburst minpoll 4 maxpoll 10
server time.ustc.edu.cn iburst minpoll 4 maxpoll 10
# 启动NTP时间服务并设置服务开机自启
[root@k8s-master01 ~]# systemctl start ntpd
[root@k8s-master01 ~]# systemctl enable ntpd
[root@k8s-master01 ~]# systemctl status ntpd
● ntpd.service - Network Time Service
Loaded: loaded (/usr/lib/systemd/system/ntpd.service; disabled; vendor preset: disabled)
Active: active (running) since Mon 2022-03-21 02:59:43 EDT; 4min 52s ago
Process: 27106 ExecStart=/usr/sbin/ntpd -u ntp:ntp $OPTIONS (code=exited, status=0/SUCCESS)
[root@k8s-master01 ~]# ntpstat
synchronised to NTP server (120.25.108.11) at stratum 3
time correct to within 70 ms
polling server every 16 s
其他主机均从k8s-master01主机上同步时间:
# 安装NTP时间服务和NTP客户端
[root@k8s-master02 ~]# yum -y install epel-release.noarch
[root@k8s-master02 ~]# yum -y install ntp ntpdate
# 使用NTP客户端从NTP时间服务器同步本机时间
[root@k8s-master02 ~]# ntpdate 192.168.124.128
# 配置NTP时间服务
[root@k8s-master02 ~]# vim /etc/ntp.conf
# 设置从刚刚搭建的NTP时间服务器主动同步时间
# 如果NTP时间服务器连接失败时则以本机时间为准
server 127.127.1.0
Fudge 127.127.1.0 stratum 10
server 192.168.124.128 prefer iburst minpoll 4 maxpoll 10
# 启动NTP时间服务并设置服务开机自启
[root@k8s-master02 ~]# systemctl start ntpd
[root@k8s-master02 ~]# systemctl enable ntpd
[root@k8s-master02 ~]# systemctl status ntpd
● ntpd.service - Network Time Service
Loaded: loaded (/usr/lib/systemd/system/ntpd.service; disabled; vendor preset: disabled)
Active: active (running) since Mon 2022-03-21 02:59:43 EDT; 4min 52s ago
Process: 27106 ExecStart=/usr/sbin/ntpd -u ntp:ntp $OPTIONS (code=exited, status=0/SUCCESS)
[root@k8s-master02 ~]# ntpstat
synchronised to NTP server (192.168.124.128) at stratum 3
time correct to within 70 ms
polling server every 16 s
6、关闭SWAP
SWAP可能导致容器出现性能下降问题。
所有主机上:
[root@k8s-master01 ~]# swapoff -a # 临时关闭
[root@k8s-master01 ~]# free -mh
total used free shared buff/cache available
Mem: 1.8G 133M 1.4G 9.5M 216M 1.5G
Swap: 0B 0B 0B
[root@k8s-master01 ~]# vim /etc/fstab # 永久关闭
#/dev/mapper/centos-swap swap swap defaults 0 0
7、关闭Firewalld
Kubernetes中的kube-proxy组件需要利用IPtables或者IPVS创建Service对象,CentOS7默认使用Firewalld防火墙服务,为了避免冲突,所以需要禁用和关闭它。
所有主机上:
[root@k8s-master01 ~]# systemctl stop firewalld
[root@k8s-master01 ~]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
8、关闭SeLinux
所有主机上:
[root@k8s-master01 ~]# setenforce 0 # 临时关闭
[root@k8s-master01 ~]# sed -i 's/SELINUX=.*/SELINUX=disabled/g' /etc/sysconfig/selinux # 永久关闭
9、启用bridge-nf功能
开启IPtables的网桥透明工作模式,即二层的流量也会受到IPtables规则影响。
如果该功能模块开机没有加载,则需要加载"br_netfilter"模块。
所有主机上:
[root@k8s-master01 ~]# modprobe br_netfilter
[root@k8s-master01 ~]# lsmod | grep br_netfilter
br_netfilter 22256 0
bridge 151336 1 br_netfilter
[root@k8s-master01 ~]# cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
[root@k8s-master01 ~]# cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
[root@k8s-master01 ~]# sysctl --system
10、安装并启用IPVS
kube-proxy组件支持三种工作模式转发流量到Pod:userspace、iptables、ipvs。
如果想要使用ipvs模式则需要安装IPVS。
所有主机上:
[root@k8s-master01 ~]# yum -y install kernel-devel
[root@k8s-master01 ~]# cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
[root@k8s-master01 ~]# chmod 755 /etc/sysconfig/modules/ipvs.modules
[root@k8s-master01 ~]# bash /etc/sysconfig/modules/ipvs.modules
[root@k8s-master01 ~]# lsmod |grep ip_vs
ip_vs_sh 12688 0
ip_vs_wrr 12697 0
ip_vs_rr 12600 0
ip_vs 145497 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack 133095 2 ip_vs,nf_conntrack_ipv4
libcrc32c 12644 3 xfs,ip_vs,nf_conntrack
[root@k8s-master01 ~]# yum -y install ipset ipvsadm
2.3.安装容器运行平台(Docker)
容器运行平台用于承载和管理运行容器应用。
配置Docker在线镜像源为国内镜像源,官方推荐使用的cgroup驱动为"systemd"。
所有主机上:
# 安装指定版本的docker
[root@k8s-master01 ~]# yum -y install epel-release.noarch yum-utils
[root@k8s-master01 ~]# yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@k8s-master01 ~]# yum -y install device-mapper-persistent-data lvm2
[root@k8s-master01 ~]# yum list docker-ce --showduplicates | sort -r
[root@k8s-master01 ~]# yum -y install docker-ce-19.03.0
[root@k8s-master01 ~]# systemctl start docker
[root@k8s-master01 ~]# systemctl enable docker
# 配置docker
[root@k8s-master01 ~]# cat > /etc/docker/daemon.json <<EOF
{
"registry-mirrors": [
"https://7mimmp7p.mirror.aliyuncs.com",
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn"
],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
EOF
[root@k8s-master01 ~]# systemctl restart docker
[root@k8s-master01 ~]# systemctl status docker
● docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled)
Active: active (running) since Mon 2022-03-21 06:26:38 EDT; 4s ago
[root@k8s-master01 ~]# docker info | grep Cgroup
Cgroup Driver: systemd
2.4.安装Kubeadm、Kubelet、Kubectl
kubeadm,引导构建集群所使用的工具。
kubelet,在集群中所有机器上要运行的组件,用于管理Pod和容器。
kubectl,在命令行操作和使用集群的客户端工具。
在所有主机上:
[root@k8s-master01 ~]# cat <<EOF >/etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
[root@k8s-master01 ~]# yum install -y kubelet-1.23.0 kubectl-1.23.0 kubeadm-1.23.0 --disableexcludes=kubernetes --nogpgcheck
[root@k8s-master01 ~]# systemctl enable kubelet
[root@k8s-master01 ~]# cat > /etc/sysconfig/kubelet <<EOF
KUBELET_EXTRA_ARGS="--fail-swap-on=false"
EOF
2.5.创建负载均衡器(HAProxy+Keepalived)
参考文档:https://github.com/kubernetes/kubeadm/blob/main/docs/ha-considerations.md#options-for-software-load-balancing
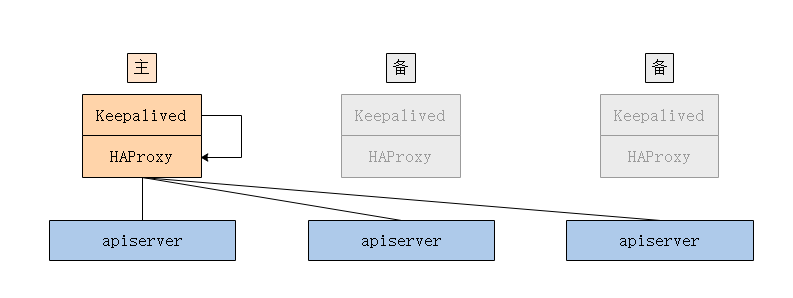
当存在多个控制平面时,kube-apiserver也存在多个,可以使用Nginx+Keepalived、HAProxy+Keepalived等工具实现多个kube-apiserver的负载均衡和高可用。
推荐使用HAProxy+Keepalived这个组合,因为HAProxy可以提高更高性能的四层负载均衡功能,这也是大多数人的选择。
1、安装HAProxy、Keepalived
HAProxy可以实现对后端APIServer的负载均衡与健康检查,不会转发请求到不可用的APIServer,以避免失败的请求。
[root@k8s-master01 ~]# yum -y install haproxy keepalived
2、配置并启动HAProxy
启动的HAProxy服务由于后端的api-server还没有部署运行,需要等待Kubernetes初始化完成才可以正常接受处理请求!
在所有master主机上:
[root@k8s-master01 ~]# vim /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local2 emerg info
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# apiserver frontend which proxys to the control plane nodes
#---------------------------------------------------------------------
frontend apiserver
bind *:9443
mode tcp
option tcplog
default_backend apiserver
#---------------------------------------------------------------------
# round robin balancing for apiserver
#---------------------------------------------------------------------
backend apiserver
mode tcp
balance roundrobin
server k8s-master01 192.168.124.128:6443 check
server k8s-master02 192.168.124.130:6443 check
server k8s-master03 192.168.124.131:6443 check
[root@k8s-master01 ~]# haproxy -f /etc/haproxy/haproxy.cfg -c
Configuration file is valid
[root@k8s-master01 ~]# systemctl start haproxy
[root@k8s-master01 ~]# systemctl enable haproxy
[root@k8s-master01 ~]# netstat -lnupt |grep 9443
tcp 0 0 0.0.0.0:9443 0.0.0.0:* LISTEN 44965/haproxy
[root@k8s-master01 ~]# curl localhost:9443
curl: (52) Empty reply from server
3、配置并重启rsyslog
HAProxy采用rsyslog记录日志,日志有助于后续我们观察和分析问题。
所有master主机上:
[root@k8s-master01 ~]# vim /etc/rsyslog.conf
local2.* /var/log/haproxy.log
[root@k8s-master01 ~]# systemctl restart rsyslog
[root@k8s-master01 ~]# systemctl status rsyslog
● rsyslog.service - System Logging Service
Loaded: loaded (/usr/lib/systemd/system/rsyslog.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2022-04-12 16:39:50 CST; 2h 11min ago
4、配置Keeaplived
配置Keepalived以实现HAProxy的高可用性,当A主负载均衡器不可用时,还有B、C备用负载均衡器继续提供服务。
配置基于脚本(vrrp_script)的健康检查,当检查失败时,权重-2,即优先级-2,这时候就会发生主备切换。
k8s-master01(MASTER):
[root@k8s-master01 ~]# vim /etc/keepalived/keepalived.conf
! /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id 192.168.124.128
}
vrrp_script check_haproxy {
script "bash -c 'if [ $(ss -alnupt |grep 9443|wc -l) -eq 0 ];then exit 1;fi'"
interval 3
weight -2
fall 3
rise 3
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 50
priority 100
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.124.100
}
track_script {
check_haproxy
}
}
k8s-master02(BACKUP):
[root@k8s-master02 ~]# vim /etc/keepalived/keepalived.conf
! /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id 192.168.124.130
}
vrrp_script check_haproxy {
script "bash -c 'if [ $(ss -alnupt |grep 9443|wc -l) -eq 0 ];then exit 1;fi'"
interval 3
weight -2
fall 3
rise 3
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 50
priority 99
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.124.100
}
track_script {
check_haproxy
}
}
k8s-master03(BACKUP):
[root@k8s-master03 ~]# vim /etc/keepalived/keepalived.conf
! /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id 192.168.124.131
}
vrrp_script check_haproxy {
script "bash -c 'if [ $(ss -alnupt |grep 9443|wc -l) -eq 0 ];then exit 1;fi'"
interval 3
weight -2
fall 3
rise 3
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 50
priority 98
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.124.100
}
track_script {
check_haproxy
}
}
5、启动并设置Keepalived开机自启
所有master主机上:
[root@k8s-master01 ~]# systemctl start keepalived
[root@k8s-master01 ~]# systemctl status keepalived
● keepalived.service - LVS and VRRP High Availability Monitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; enabled; vendor preset: disabled)
Active: active (running) since Mon 2022-03-21 11:48:06 EDT; 4min 0s ago
Main PID: 48653 (keepalived)
[root@k8s-master01 ~]# systemctl enable keepalived
6、查看VIP是否在MASTER主机上
[root@k8s-master01 ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:40:e3:9f brd ff:ff:ff:ff:ff:ff
inet 192.168.124.128/24 brd 192.168.124.255 scope global dynamic ens33
valid_lft 1057sec preferred_lft 1057sec
inet 192.168.124.100/32 scope global ens33
valid_lft forever preferred_lft forever
7、测试:主故障时自动切换至备
主故障自动切换:
停止MASTER主机上的HAProxy服务,这个时候检查脚本触发优先级-2,则就会发生主备切换,VIP则会漂移到另外一台优先级较低的BACKUP主机上以代替成为新的MASTER。
以下可以看出VIP已经漂移到了k8s-master02上。
[root@k8s-master01 ~]# systemctl stop haproxy
[root@k8s-master01 ~]# ip addr
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:40:e3:9f brd ff:ff:ff:ff:ff:ff
inet 192.168.124.128/24 brd 192.168.124.255 scope global dynamic ens33
valid_lft 1451sec preferred_lft 1451sec
[root@k8s-master02 ~]# ip addr
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:c4:65:67 brd ff:ff:ff:ff:ff:ff
inet 192.168.124.130/24 brd 192.168.124.255 scope global dynamic ens33
valid_lft 1320sec preferred_lft 1320sec
inet 192.168.124.100/32 scope global ens33
valid_lft forever preferred_lft forever
主故障后恢复:
当MASTER主机上的HAProxy服务恢复时,这个时候检查脚本触发优先级+2,也会发生切换,VIP会漂移到优先级更高的已恢复正常的MASTER主机继续作为MASTER提供服务。
[root@k8s-master01 ~]# systemctl start haproxy
[root@k8s-master01 ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:40:e3:9f brd ff:ff:ff:ff:ff:ff
inet 192.168.124.128/24 brd 192.168.124.255 scope global dynamic ens33
valid_lft 1175sec preferred_lft 1175sec
inet 192.168.124.100/32 scope global ens33
valid_lft forever preferred_lft forever
2.6.部署并构建Kubernetes集群
1、准备镜像
可以使用以下命令查看kubeadm-v1.23.0部署kubernetes-v1.23.0所需要的镜像列表以及默认所使用的的镜像来源。
所有主机上:
[root@k8s-master01 ~]# kubeadm config print init-defaults |grep imageRepository
imageRepository: k8s.gcr.io
[root@k8s-master01 ~]# kubeadm config images list --kubernetes-version 1.23.0
k8s.gcr.io/kube-apiserver:v1.23.0
k8s.gcr.io/kube-controller-manager:v1.23.0
k8s.gcr.io/kube-scheduler:v1.23.0
k8s.gcr.io/kube-proxy:v1.23.0
k8s.gcr.io/pause:3.6
k8s.gcr.io/etcd:3.5.1-0
k8s.gcr.io/coredns/coredns:v1.8.6
由于访问k8s.gcr.io可能需要FQ,所以我们可以在国内的镜像仓库中下载它们(比如使用阿里云镜像仓库。阿里云代理镜像仓库地址:registry.aliyuncs.com/google_containers
如果你需要在更多台主机上使用它们,则可以考虑使用Harbor或Docker Register搭建私有化镜像仓库。
所有主机上:
# 从镜像仓库中拉取镜像
[root@k8s-master01 ~]# kubeadm config images pull --kubernetes-version=v1.23.0 --image-repository=registry.aliyuncs.com/google_containers
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.23.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.23.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.23.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.23.0
[config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.6
[config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.5.1-0
[config/images] Pulled registry.aliyuncs.com/google_containers/coredns:v1.8.6
# 查看本地镜像列表
[root@k8s-master01 ~]# docker images |grep 'registry.aliyuncs.com/google_containers'
registry.aliyuncs.com/google_containers/kube-apiserver v1.23.0 e6bf5ddd4098 4 months ago 135MB
registry.aliyuncs.com/google_containers/kube-controller-manager v1.23.0 37c6aeb3663b 4 months ago 125MB
registry.aliyuncs.com/google_containers/kube-proxy v1.23.0 e03484a90585 4 months ago 112MB
registry.aliyuncs.com/google_containers/kube-scheduler v1.23.0 56c5af1d00b5 4 months ago 53.5MB
registry.aliyuncs.com/google_containers/etcd 3.5.1-0 25f8c7f3da61 5 months ago 293MB
registry.aliyuncs.com/google_containers/coredns v1.8.6 a4ca41631cc7 6 months ago 46.8MB
registry.aliyuncs.com/google_containers/pause 3.6 6270bb605e12 7 months ago 683kB
2、准备kubeadm-init配置文件
kubeadm相关配置可以参考文档:https://kubernetes.io/docs/reference/config-api/kubeadm-config.v1beta3/
k8s-master01:
[root@k8s-master01 ~]# kubeadm config print init-defaults > kubeadm-init.yaml
[root@k8s-master01 ~]# vim kubeadm-init.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: "0" # 设置引导令牌的永不过期
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.124.128 # 绑定APIServer要监听的本机IP地址
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
imagePullPolicy: IfNotPresent
name: k8s-master01 # 节点名称
taints: null
---
controlPlaneEndpoint: "192.168.124.100:9443" # 控制平面入口点地址:"负载均衡器VIP或DNS:负载均衡器端口"
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers # 设置部署集群时要使用的镜像仓库地址
kind: ClusterConfiguration
kubernetesVersion: 1.23.0 # 设置要部署的kubernetes版本
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs # 设置kube-proxy工作模式为ipvs
3、安装kubeadm_src,防止kubernetes证书过期(可选步骤)
在Kubernetes中,客户端与APIServer通信需要使用X509证书,各组件之间也是使用证书进行身份验证的,由于官方默认使用kubeadm创建的相关证书有效期只有一年,如果证书到期后可能导致集群不可用,这非常严重。
所以我们这里对kubernetes源码进行修改后编译生成后的kubeadm(重命名为kubeadm_src)初始化控制平面节点,在初始化的过程中会生成有效期为其100年的的kubernetes证书!
k8s-master01:
# 安装GO
[root@k8s-master01 ~]# wget https://go.dev/dl/go1.17.8.linux-amd64.tar.gz
[root@k8s-master01 ~]# tar xzvf go1.17.8.linux-amd64.tar.gz -C /usr/local
[root@k8s-master01 ~]# vim /etc/profile
export PATH=$PATH:/usr/local/go/bin
export GO111MODULE=auto
export GOPROXY=https://goproxy.cn
[root@k8s-master01 ~]# source /etc/profile
[root@k8s-master01 ~]# go version
go version go1.17.8 linux/amd64
# 从GITHUB克隆官方代码
[root@k8s-master01 ~]# yum -y install git
[root@k8s-master01 ~]# git clone https://github.91chi.fun/https://github.com/kubernetes/kubernetes.git
[root@k8s-master01 ~]# cd kubernetes
[root@k8s-master01 kubernetes]# git tag -l
...
v1.23.0
...
[root@k8s-master01 kubernetes]# git checkout -b v1.23.0 v1.23.0
# 修改证书有效期相关代码
[root@k8s-master01 kubernetes]# vim cmd/kubeadm/app/constants/constants.go
const (
...
// CertificateValidity defines the validity for all the signed certificates generated by kubeadm
// CertificateValidity = time.Hour * 24 * 365
CertificateValidity = time.Hour * 24 * 365 * 100
...
}
[root@k8s-master01 kubernetes]# vim staging/src/k8s.io/client-go/util/cert/cert.go
...
// NewSelfSignedCACert creates a CA certificate
func NewSelfSignedCACert(cfg Config, key crypto.Signer) (*x509.Certificate, error) {
now := time.Now()
tmpl := x509.Certificate{
SerialNumber: new(big.Int).SetInt64(0),
Subject: pkix.Name{
CommonName: cfg.CommonName,
Organization: cfg.Organization,
},
DNSNames: []string{cfg.CommonName},
NotBefore: now.UTC(),
//NotAfter: now.Add(duration365d * 10).UTC(),
NotAfter: now.Add(duration365d * 100).UTC(),
KeyUsage: x509.KeyUsageKeyEncipherment | x509.KeyUsageDigitalSignature | x509.KeyUsageCertSign,
BasicConstraintsValid: true,
IsCA: true,
}
}
...
# 编译生成新的kubeadm命令,这将会输出到_output/bin/目录下
[root@k8s-master01 kubernetes]# make WHAT=cmd/kubeadm GOFLAGS=-v
# 拷贝kubeadm到所有节点主机的/usr/bin目录下,并重命名为kubeadm_src
[root@k8s-master01 kubernetes]# cd _output/bin/ && cp -rf kubeadm /usr/bin/kubeadm_src
[root@k8s-master01 bin]# scp kubeadm root@k8s-master02:/usr/bin/kubeadm_src
[root@k8s-master01 bin]# scp kubeadm root@k8s-master03:/usr/bin/kubeadm_src
[root@k8s-master01 bin]# scp kubeadm root@k8s-node01:/usr/bin/kubeadm_src
4、基于kubeadm-init配置并使用源码编译的kubeadm创建一个初始化控制平面节点
kubeadm在初始化控制平面时会生成部署Kubernetes集群中各个组件所需的相关配置文件在/etc/kubernetes目录下,可以供我们参考。
注:由于源码生成kubeadm在初始化节点的时候无法正确的配置YUM安装的kubelet服务,所以需要YUM安装的kubeadm先配置kubelet服务!
初始化完成后的提示信息和后续执行命令需要保存一下!
k8s-master01:
# 使用YUM安装的kubeadm初始配置kubelet
[root@k8s-master01 ~]# kubeadm init phase kubelet-start --config kubeadm-init.yaml
# 使用源码编译的kubeadm初始化控制平面节点
[root@k8s-master01 ~]# kubeadm_src init --config kubeadm-init.yaml --upload-certs
Your Kubernetes control-plane has initialized successfully!
你的Kubernetes控制平面已初始化成功!
To start using your cluster, you need to run the following as a regular user:
你的集群是启动状态,如果你是普通用户的话请继续执行以下命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
或者,如果你是root用户的话请继续执行以下命令:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
你还需要在集群上部署一个Pod网络插件!
You can now join any number of the control-plane node running the following command on each as root:
你如果需要更多数量的控制平面节点加入到集群的话,请使用root用户在节点执行以下命令:
kubeadm join 192.168.124.100:9443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:64c918139d7d344b64b0720244077b60ea10f5572717f92113c08fe9c56be3c9 \
--control-plane --certificate-key 5d87ca735c040ba6b04de388f2857530bbd9de094cbd43810904afe9a6aec50d
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
证书的访问密钥有效期只有2小时,如果你还需要部署更多的节点,请先执行"kubeadm init phase upload-certs --upload-certs"重新上传证书到kubeadm-certs!
Then you can join any number of worker nodes by running the following on each as root:
你如果需要更多数量的工作节点加入到集群的话,请使用root用户在节点上执行以下命令:
kubeadm join 192.168.124.100:9443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:64c918139d7d344b64b0720244077b60ea10f5572717f92113c08fe9c56be3c9
5、将正确的kubelet服务配置文件拷贝到其他主机
k8s-master01:
[root@k8s-master01 ~]# systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
[root@k8s-master01 ~]# scp -r /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf root@k8s-master02:/usr/lib/systemd/system/kubelet.service.d
[root@k8s-master01 ~]# scp -r /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf root@k8s-master03:/usr/lib/systemd/system/kubelet.service.d
[root@k8s-master01 ~]# scp -r /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf root@k8s-node01:/usr/lib/systemd/system/kubelet.service.d
其他主机上重载服务配置:
[root@k8s-master02 ~]# systemctl daemon-reload
6、其他节点加入到集群
请使用源码编译后的kubeadm命令!
其他控制平面节点加入到集群:
[root@k8s-master02 ~]# kubeadm_src join 192.168.124.100:9443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:64c918139d7d344b64b0720244077b60ea10f5572717f92113c08fe9c56be3c9 --control-plane --certificate-key 5d87ca735c040ba6b04de388f2857530bbd9de094cbd43810904afe9a6aec50d
工作节点加入到集群:
[root@k8s-node01 ~]# kubeadm_src join 192.168.124.100:9443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:64c918139d7d344b64b0720244077b60ea10f5572717f92113c08fe9c56be3c9
7、观察Etcd
可见Etcd是以集群的方式运行的!
[root@k8s-master03 ~]# ps aux |grep etcd
root 1971 5.4 4.5 11283128 84128 ? Ssl 16:33 1:00 etcd --advertise-client-urls=https://192.168.124.131:2379 --cert-file=/etc/kubernetes/pki/etcd/server.crt --client-cert-auth=true --data-dir=/var/lib/etcd --initial-advertise-peer-urls=https://192.168.124.131:2380 --initial-cluster=k8s-master03=https://192.168.124.131:2380,k8s-master01=https://192.168.124.128:2380,k8s-master02=https://192.168.124.130:2380 --initial-cluster-state=existing --key-file=/etc/kubernetes/pki/etcd/server.key --listen-client-urls=https://127.0.0.1:2379,https://192.168.124.131:2379 --listen-metrics-urls=http://127.0.0.1:2381 --listen-peer-urls=https://192.168.124.131:2380 --name=k8s-master03 --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt --peer-client-cert-auth=true --peer-key-file=/etc/kubernetes/pki/etcd/peer.key --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt --snapshot-count=10000 --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
8、查看Kubernetes证书有效期
[root@k8s-master01 ~]# kubeadm certs check-expiration
[check-expiration] Reading configuration from the cluster...
[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Mar 18, 2122 04:38 UTC 99y no
apiserver Mar 18, 2122 04:38 UTC 99y ca no
apiserver-etcd-client Mar 18, 2122 04:38 UTC 99y etcd-ca no
apiserver-kubelet-client Mar 18, 2122 04:38 UTC 99y ca no
controller-manager.conf Mar 18, 2122 04:38 UTC 99y no
etcd-healthcheck-client Mar 18, 2122 04:38 UTC 99y etcd-ca no
etcd-peer Mar 18, 2122 04:38 UTC 99y etcd-ca no
etcd-server Mar 18, 2122 04:38 UTC 99y etcd-ca no
front-proxy-client Mar 18, 2122 04:38 UTC 99y front-proxy-ca no
scheduler.conf Mar 18, 2122 04:38 UTC 99y no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Mar 18, 2122 04:38 UTC 99y no
etcd-ca Mar 18, 2122 04:38 UTC 99y no
front-proxy-ca Mar 18, 2122 04:38 UTC 99y no
9、设置kubectl客户端以连接到集群
节点在部署完成时,会生成用于kubectl登录所使用的kubeconfig配置文件在"/etc/kubernetes/admin.conf"!
所有master主机上:
[root@k8s-master01 ~]# mkdir -p $HOME/.kube
[root@k8s-master01 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8s-master01 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
10、查看集群中节点列表
可见所有节点都是"NotReady"未就绪状态,这需要在集群中安装Pod网络插件!
[root@k8s-master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 NotReady control-plane,master 145m v1.23.0
k8s-master02 NotReady control-plane,master 144m v1.23.0
k8s-master03 NotReady control-plane,master 143m v1.23.0
k8s-node01 NotReady <none> 76m v1.23.0
[root@k8s-master01 ~]# kubectl describe nodes k8s-master01
Name: k8s-master01
...
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------
KubeletNotReady container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
3.安装一些必要的插件
3.1.安装Pod网络插件(CNI)-Calico
Calico是一个开源的虚拟化网络方案,支持基础的Pod网络通信和网络策略功能。
Kubernetes有一种资源类型"NetworkPolicy",用于描述Pod的网络策略,要想使用该资源类型,则需要Pod网络插件支持网络策略功能。
参考文档:https://github.com/projectcalico/calico
任意一台master主机上:
[root@k8s-master01 ~]# wget https://docs.projectcalico.org/manifests/calico.yaml --no-check-certificate
[root@k8s-master01 ~]# kubectl apply -f calico.yaml
configmap/calico-config created
customresourcedefinition.apiextensions.k8s.io/bgpconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/bgppeers.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/blockaffinities.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/caliconodestatuses.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/clusterinformations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/felixconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/globalnetworkpolicies.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/globalnetworksets.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/hostendpoints.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamblocks.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamconfigs.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamhandles.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ippools.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipreservations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/kubecontrollersconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/networkpolicies.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/networksets.crd.projectcalico.org created
clusterrole.rbac.authorization.k8s.io/calico-kube-controllers created
clusterrolebinding.rbac.authorization.k8s.io/calico-kube-controllers created
clusterrole.rbac.authorization.k8s.io/calico-node created
clusterrolebinding.rbac.authorization.k8s.io/calico-node created
daemonset.apps/calico-node created
serviceaccount/calico-node created
deployment.apps/calico-kube-controllers created
serviceaccount/calico-kube-controllers created
Warning: policy/v1beta1 PodDisruptionBudget is deprecated in v1.21+, unavailable in v1.25+; use policy/v1 PodDisruptionBudget
poddisruptionudget.policy/calico-kube-controllers created
安装完成后可以看到Calico会在集群中创建并运行对应Pod,并且此时所有的Node已经是就绪状态:
[root@k8s-master01 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-56fcbf9d6b-phf49 1/1 Running 0 12m
calico-node-8frvw 1/1 Running 0 12m
calico-node-mzpmv 1/1 Running 0 12m
calico-node-rblcg 1/1 Running 0 12m
calico-node-vh9c9 1/1 Running 0 12m
coredns-6d8c4cb4d-85b5t 1/1 Running 0 39m
coredns-6d8c4cb4d-h7ttw 1/1 Running 0 38m
[root@k8s-master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready control-plane,master 28h v1.23.0
k8s-master02 Ready control-plane,master 28h v1.23.0
k8s-master03 Ready control-plane,master 28h v1.23.0
k8s-node01 Ready <none> 27h v1.23.0
3.2.安装Ingress控制器-Ingress-Nginx
Ingress是Kubernetes标准的资源类型之一,用于描述Service的七层实现,实现基于HTTP协议的反向代理功能,这在Web项目中是经常要用的。
"Ingress"功能的提供由Ingress控制器(插件)实现,ingress-nginx是常用的Ingress控制器。
参考文档:
https://github.com/kubernetes/ingress-nginx
https://kubernetes.github.io/ingress-nginx/deploy/
1、查看兼容版本
Ingress-NGINX version k8s supported version Alpine Version Nginx Version
v1.1.3 1.23, 1.22, 1.21, 1.20, 1.19 3.14.4 1.19.10†
v1.1.2 1.23, 1.22, 1.21, 1.20, 1.19 3.14.2 1.19.9†
v1.1.1 1.23, 1.22, 1.21, 1.20, 1.19 3.14.2 1.19.9†
2、搜索国内镜像源
注:这边需要修改一下镜像源为国内克隆镜像源,否则可能无法下载镜像。
可以去DockerHUB中搜索一下对应版本的相关镜像!

3、安装Ingress-Nginx-Controller
[root@k8s-master01 ~]# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.1.2/deploy/static/provider/cloud/deploy.yaml -O ingress-nginx.yaml
[root@k8s-master01 ~]# vim ingress-nginx.yaml
#image: k8s.gcr.io/ingress-nginx/controllerv1.1.2@...
image: willdockerhub/ingress-nginx-controller:v1.1.2
#image: k8s.gcr.io/ingress-nginx/kube-webhook-certgen:v1.1.1@...
image: liangjw/kube-webhook-certgen:v1.1.1
[root@k8s-master01 ~]# kubectl apply -f ingress-nginx.yaml
namespace/ingress-nginx created
serviceaccount/ingress-nginx created
serviceaccount/ingress-nginx-admission created
role.rbac.authorization.k8s.io/ingress-nginx created
role.rbac.authorization.k8s.io/ingress-nginx-admission created
clusterrole.rbac.authorization.k8s.io/ingress-nginx created
clusterrole.rbac.authorization.k8s.io/ingress-nginx-admission created
rolebinding.rbac.authorization.k8s.io/ingress-nginx created
rolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
configmap/ingress-nginx-controller created
service/ingress-nginx-controller created
service/ingress-nginx-controller-admission created
deployment.apps/ingress-nginx-controller created
job.batch/ingress-nginx-admission-create created
job.batch/ingress-nginx-admission-patch created
ingressclass.networking.k8s.io/nginx created
validatingwebhookconfiguration.admissionregistration.k8s.io/ingress-nginx-admission created
4、查看运行状态
[root@k8s-master01 ~]# kubectl get pods --namespace=ingress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-admission-create-6xk5t 0/1 Completed 0 11m
ingress-nginx-admission-patch-sp6w2 0/1 Completed 0 11m
ingress-nginx-controller-7bc7476f95-gdxkz 1/1 Running 0 11m
5、使用外部负载均衡器关联Ingress控制器
外部主机想要访问到Pod-Ingress控制器需要通过Service,默认情况下使用.yaml安装Ingress-nginx-controller时会创建LoadBalancer类型的Service,以用于外部负载均衡器关联并将访问请求转发至Ingress控制器处理。
LoadBalancer类型的Service是NodePort类型的上层实现,同理它会在每台节点主机上都开放一个映射端口,可用于外部负载均衡器进行关联。
[root@k8s-master01 ~]# kubectl get service --namespace=ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.103.77.111 <pending> 80:30408/TCP,443:32686/TCP 20m
ingress-nginx-controller-admission ClusterIP 10.98.133.60 <none> 443/TCP 20m
[root@k8s-master01 ~]# netstat -lnupt |grep -E '30408|32686'
tcp 1 0 0.0.0.0:30408 0.0.0.0:* LISTEN 41631/kube-proxy
tcp 0 0 0.0.0.0:32686 0.0.0.0:* LISTEN 41631/kube-proxy
3.3.安装Metrics-Server
Metrices-Server,指标服务器,Metrices-Server是Kubernetes中的一个常用插件,它类似于Top命令,可以查看Kubernetes中Node和Pod的CPU和内存资源使用情况。
Metrices-Server每15秒收集一次指标,它在集群中的每个节点中运行,可扩展支持多达5000个节点的集群。
Metrices-Server从0.5版本开始默认情况下要求节点上需要的资源请求为100m的CPU和200MiB的内存,以保证100+节点数量的性能是良好的。
参考文档:https://github.com/kubernetes-sigs/metrics-server
1、查看与Kuberneres的兼容性
Metrics Server Metrics API group/version Supported Kubernetes version
0.6.x metrics.k8s.io/v1beta1 1.19+
0.5.x metrics.k8s.io/v1beta1 *1.8+
0.4.x metrics.k8s.io/v1beta1 *1.8+
0.3.x metrics.k8s.io/v1beta1 1.8-1.21
2、搜索国内克隆镜像
官方的安装清单components.yaml默认情况下使用的镜像仓库为k8s.gcr.io,在没有FQ的情况下Pod运行可能无法正常获取到Metrics-Server的安装镜像。
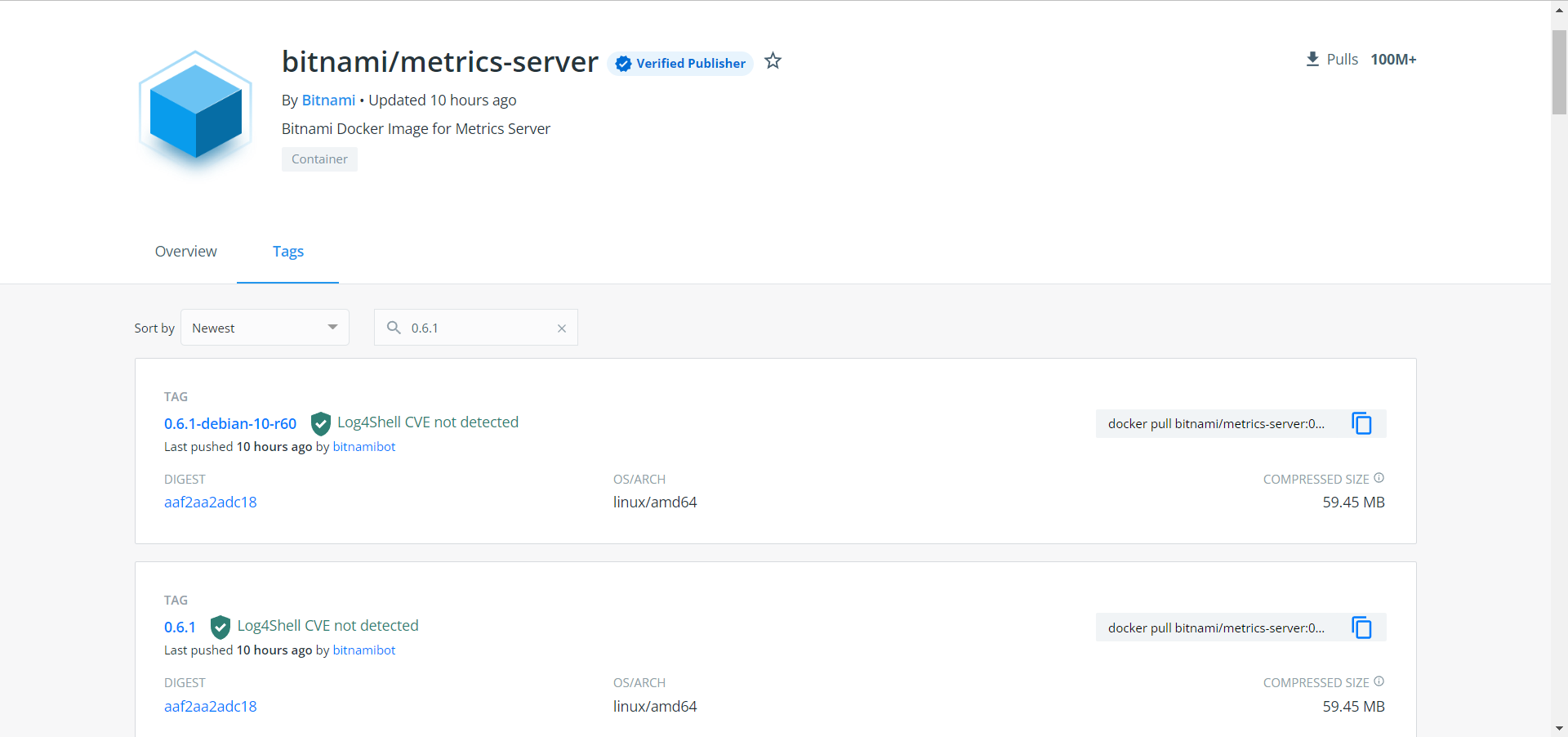
3、安装Metrics-Server
Metrics-Server默认情况下在启动的时候需要验证kubelet提供的CA证书,这可能会导致其启动失败,所以需要添加参数"--kubelet-insecure-tls"禁用此校验证书功能。
[root@k8s-master01 ~]# wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml -O metrics-server.yaml
[root@k8s-master01 ~]# vim metrics-server.yaml
spec:
containers:
- args:
- --kubelet-insecure-tls
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
image: bitnami/metrics-server:0.6.1
[root@k8s-master01 ~]# kubectl apply -f metrics-server.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
[root@k8s-master01 ~]# kubectl get pods --namespace=kube-system |grep -E 'NAME|metrics-server'
NAME READY STATUS RESTARTS AGE
metrics-server-599b4c96ff-njg8b 1/1 Running 0 76s
4、查看集群中节点的资源使用情况
[root@k8s-master01 ~]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master01 331m 8% 1177Mi 68%
k8s-master02 419m 10% 1216Mi 70%
k8s-master03 344m 8% 1155Mi 67%
k8s-node01 246m 6% 997Mi 57%
5、查看集群中指定名称空间下Pod的资源使用情况
[root@k8s-master01 ~]# kubectl top pod --namespace=kube-system
NAME CPU(cores) MEMORY(bytes)
calico-kube-controllers-56fcbf9d6b-phf49 5m 29Mi
calico-node-8frvw 98m 120Mi
calico-node-mzpmv 71m 121Mi
...
3.4.安装Dashboard
Kubernetes Dashboard是Kubernetes集群的通用、基于Web的UI。它允许用户管理集群中运行的应用程序并对其进行故障排除,以及管理集群本身。
Dashboard是Kubernetes的一个插件,由APIServer提供的一个URL提供访问入口:/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy
当前你也可以通过Service直接访问到DashBoard!
参考文档:
https://github.com/kubernetes/dashboard
https://github.com/kubernetes/dashboard/blob/master/docs/user/accessing-dashboard/README.md#login-not-available
1、安装Dashboard
根据配置清单安装Dashboard,会创建Cluster类型的Service,仅只能从集群内部主机访问到Dashboard,所以这边需要简单修改一下,将Service修改为NodePort类型,这样外部主机也可以访问它。
[root@k8s-master01 ~]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.5.1/aio/deploy/recommended.yaml -O dashboard.yaml
[root@k8s-master01 ~]# vim dashboard.yaml
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
selector:
k8s-app: kubernetes-dashboard
[root@k8s-master01 ~]# kubectl apply -f dashboard.yaml
namespace/kubernetes-dashboard created
serviceaccount/kubernetes-dashboard created
service/kubernetes-dashboard created
secret/kubernetes-dashboard-certs created
secret/kubernetes-dashboard-csrf created
secret/kubernetes-dashboard-key-holder created
configmap/kubernetes-dashboard-settings created
role.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
deployment.apps/kubernetes-dashboard created
service/dashboard-metrics-scraper created
deployment.apps/dashboard-metrics-scraper created
[root@k8s-master01 ~]# kubectl get pod --namespace=kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-799d786dbf-xx9j7 1/1 Running 0 3m16s
kubernetes-dashboard-fb8648fd9-rgc2z 1/1 Running 0 3m17s
2、访问到Dashboard
[root@k8s-master01 ~]# kubectl get service --namespace=kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.97.23.158 <none> 8000/TCP 4m6s
kubernetes-dashboard NodePort 10.103.40.153 <none> 443:32358/TCP 4m7s
[root@k8s-master01 ~]# netstat -lnupt |grep 32358
tcp 0 0 0.0.0.0:32358 0.0.0.0:* LISTEN 41631/kube-proxy
浏览器输入:https://<任一节点主机IP>:/#/login
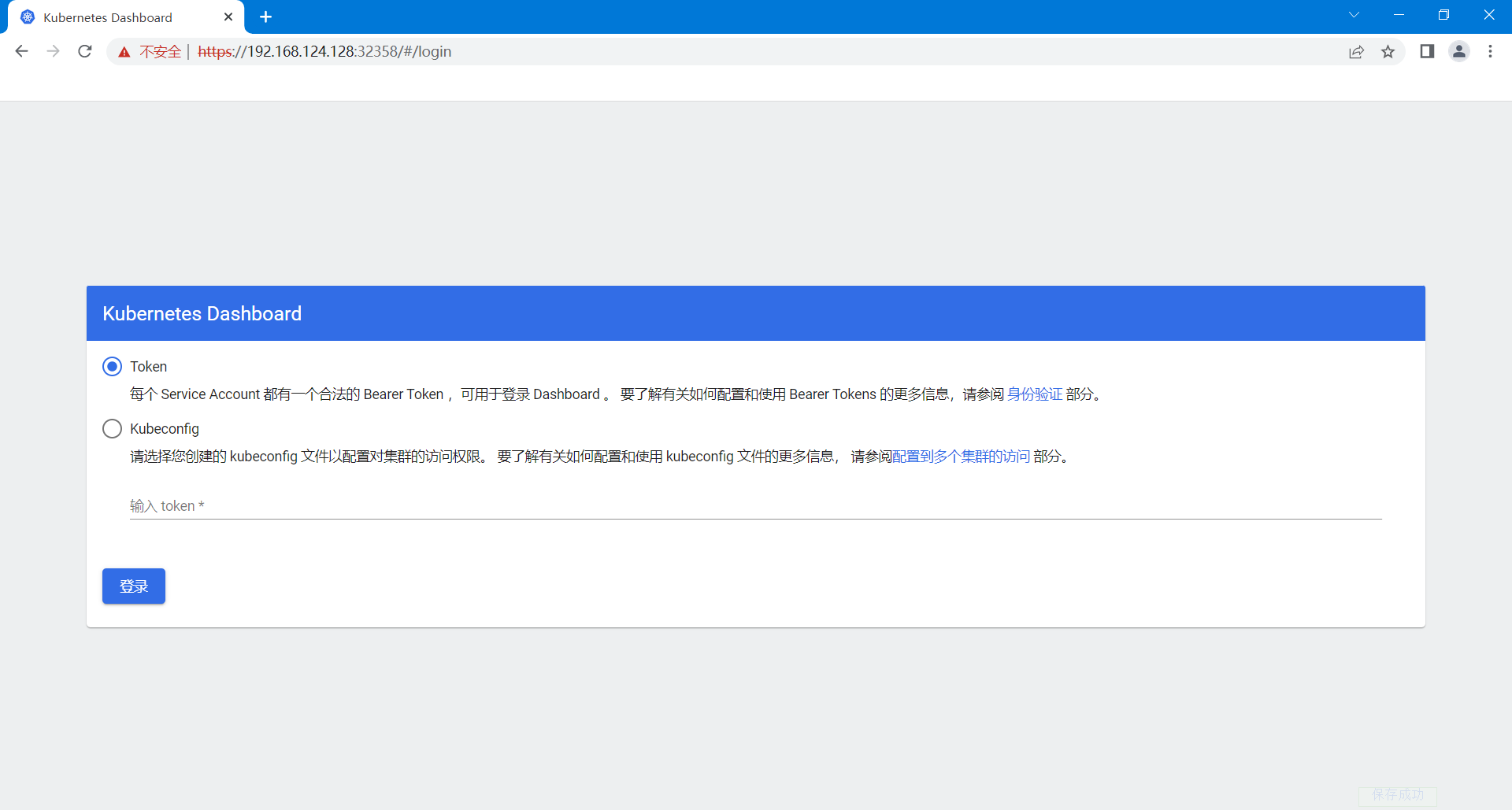
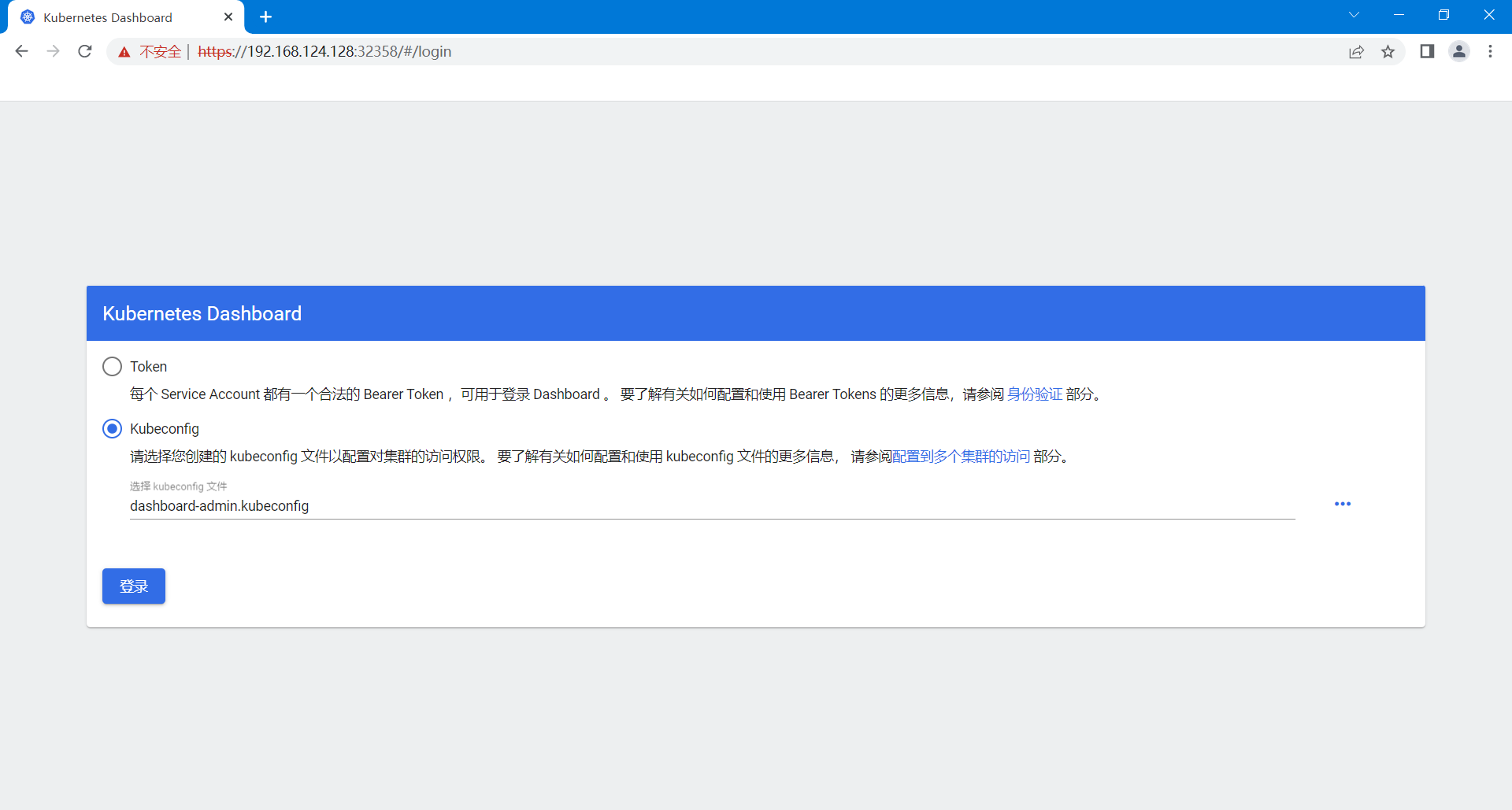
3、选择登录到Dashboard要使用的身份认证方式
登录进入Dashboard需要进行身份认证。
Dashboard服务在Pod中运行,Pod想要访问并获取到集群相关信息的话则需要创建一个ServiceAccount以验证身份。
Dashboard想要管理Kubernetes集群需要进行身份认证,目前支持Token和Kubeconfig两种方式。
Token:
创建一个拥有集群角色"cluster-admin"的服务账户"dashboard-admin",然后使用dashboard-admin的Token即可!当然你也可以根据特殊需要创建拥有指定权限的集群角色将其绑定到对应的服务账户上,以管理集群中指定资源。
# 创建一个专用于Dashboard的服务账户"dashboard-admin"
[root@k8s-master01 ~]# kubectl create serviceaccount dashboard-admin -n kubernetes-dashboard
serviceaccount/dashboard-admin created
# 为服务账户"dashboard-admin"绑定到拥有超级管理员权限的集群角色"cluster-admin"
# 则dashboard-admin就拥有了超级管理员权限
[root@k8s-master01 ~]# kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:dashboard-admin
clusterrolebinding.rbac.authorization.k8s.io/dashboard-admin created
# 创建的服务账户,会自动生成一个Token,它是Secret类型的资源对象
# 我们可以使用以下操作获取到服务账户"dashboard-admin"的Token以用于Dashboard身份验证
[root@k8s-master01 ~]# kubectl get secrets -n kubernetes-dashboard |grep dashboard-admin-token
dashboard-admin-token-2bxfl kubernetes.io/service-account-token 3 66s
[root@k8s-master01 ~]# kubectl describe secrets/dashboard-admin-token-2bxfl -n kubernetes-dashboard
Name: dashboard-admin-token-2bxfl
Namespace: kubernetes-dashboard
Labels: <none>
Annotations: kubernetes.io/service-account.name: dashboard-admin
kubernetes.io/service-account.uid: 492a031e-db41-4a65-a8d4-af0e240e7f9d
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1103 bytes
namespace: 20 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6ImFXTzZFUElaS2RoTUpScHFwNzJSNUN5eU1lcFNSZEZqNWNNbi1VbFV2Zk0ifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tMmJ4ZmwiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiNDkyYTAzMWUtZGI0MS00YTY1LWE4ZDQtYWYwZTI0MGU3ZjlkIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmVybmV0ZXMtZGFzaGJvYXJkOmRhc2hib2FyZC1hZG1pbiJ9.l5VEIPd9nIsJuXMh86rjFHhkIoZmg5nlDw7Bixn0b3-KT1r6o7WRegq8DJyVk_iiIfRnrrz5jjuOOkCKwXwvI1NCfVdsuBKXFwFZ1Crc-BwHjIxWbGuZfEGxSbN8du4T4xcUuNU-7HuZQcGDY23uy68aPqWSm8UoIcOFwUgVcYkKlOuW76tIXxG_upxWpWZz74aMDUIkjar7sdWXzMr1m5G43TLE9Z_lKCgoV-hc4Fo9_Er-TIAPqDG6-sfZZZ9Raldvn3j380QDYahUKaGKabnOFDXbODKOQ1VKRizgiRTOqt-z9YRPTcyxQzfheKC8DTb2X8D-E4x6azulenNgqw
Kubeconfig:
Token是很长的复杂的密钥字符串,使用它进行身份认证并不方便,所以Dashboard支持使用Kubeconfig文件的方式登陆到Dashboard。
基于上面Token的创建的服务账户,创建一个Kubeconfig配置文件。
# 查看集群信息
[root@k8s-master01 ~]# kubectl cluster-info
Kubernetes control plane is running at https://192.168.124.100:9443
# 创建kubeconfig文件并设置集群相关
[root@k8s-master01 ~]# kubectl config set-cluster kubernetes --embed-certs=true --server="https://192.168.124.100:9443" --certificate-authority=/etc/kubernetes/pki/ca.crt --kubeconfig=dashboard-admin.kubeconfig
# 设置认证相关到kubeconfig文件
# 默认情况下服务账户的Token是base64编码格式,如果需要将其写到kubeconfig中的则需要使用"base64 -d"进行解
# 码
[root@k8s-master01 ~]# Token=$(kubectl get secrets/dashboard-admin-token-2bxfl -n kubernetes-dashboard -o jsonpath={.data.token} |base64 -d)
[root@k8s-master01 ~]# kubectl config set-credentials dashboard-admin --token=${Token} --kubeconfig=./dashboard-admin.kubeconfig
# 设置上下文相关到kubeconfig文件
[root@k8s-master01 ~]# kubectl config set-context dashboard-admin --cluster=kubernetes --user=dashboard-admin --kubeconfig=./dashboard-admin.kubeconfig
# 设置当前要使用的上下文到kubeconfig文件
[root@k8s-master01 ~]# kubectl config use-context dashboard-admin --cluster=kubernetes --user=dashboard-admin --kubeconfig=./dashboard-admin.kubeconfig
# 最后得到以下文件
[root@k8s-master01 ~]# cat dashboard-admin.kubeconfig
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURBRENDQWVpZ0F3SUJBZ0lCQURBTkJna3Foa2lHOXcwQkFRc0ZBREFWTVJNd0VRWURWUVFERXdwcmRXSmwKY201bGRHVnpNQ0FYRFRJeU1EUXhNVEEwTXpnME1Gb1lEekl4TWpJd016RTRNRFF6T0RRd1dqQVZNUk13RVFZRApWUVFERXdwcmRXSmxjbTVsZEdWek1JSUJJakFOQmdrcWhraUc5dzBCQVFFRkFBT0NBUThBTUlJQkNnS0NBUUVBCjR0RDRmU2ZmcHU1WS9KUGJrQWgvdG0xS1lSeWQ5YU9MVk9xTDQyc1M5YmxiZGh0WU9QSHYvWEpVb1k1ZSs5MXgKUE9NbnZnWmhiR29uditHQWVFazRKeUl4MTNiTm1XUk1DZ1QyYnJIWlhvcm5QeGE0ZlVsNHg5K2swVEc5ejdIMAo0cjF5MFkzWXNXaGJIeHBwL0hvQzNRR2JVWVJyMm03NVgxTWUvdFFCL25FcUNybUZxNkRveEU3REIxMkRnemE4CjBrM3FwZllGZHBOcnZBakdIcUlSZ0ZxT24ybDVkb0c3bGVhbkIrY2wxQWltUnZCMDdQdlVKdVhrK1N5NUhmdnMKNzYyYXJRYklNMUlISkJ0ZXBaQzVjYi9pNGZhcWNrTXJaeTZvanlnN2JPcjBuMlpQcHV5SnR5QjhLMnJDZCtYZApTeXlrZG44S0MxRlRSR0p6dkdpaVRRSURBUUFCbzFrd1Z6QU9CZ05WSFE4QkFmOEVCQU1DQXFRd0R3WURWUjBUCkFRSC9CQVV3QXdFQi96QWRCZ05WSFE0RUZnUVVucEhxdGJzZ01CcSt4Q1MzTVErWnk4akFpeFV3RlFZRFZSMFIKQkE0d0RJSUthM1ZpWlhKdVpYUmxjekFOQmdrcWhraUc5dzBCQVFzRkFBT0NBUUVBRHhpR3c2bk5NV1hRMnVlRgppK2R2Nittc1FUT0JCWWJENkhIblVETUtnK0loaEcwclA5MkFRRjFWcUZaN1ZDSTgyWmJ5VnVWSmVvMjlkdjZpClBDeFJzWERxdHl0TG1CMkFPRUxXOFdqSCtheTZ5a3JYbGIwK1NIZ1Q3Q1NJRHhRdG9TeE8rK094WjhBb1JGMmUKTy94U1YxM0E0eG45RytmUEJETkVnWUJHbWd6L1RjSjZhYnljZnNNaGNwZ1kwKzJKZlJDemZBeFNiMld6TzBqaApucFRONUg2dG1ST3RlQ2h3anRWVDYrUXBUSzdkN0hjNmZlZ0w0S1pQZDEwZ0hyRFV1eWtpY01UNkpWNXNJSjArCmw5eWt2V1R2M2hEN0NJSmpJWnUySjdod0FGeW1hSmxzekZuZEpNZUFEL21pcDBMQk40OUdER2M2UFROdUw0WHEKeUxrYUhRPT0KLS0tLS1FTkQgQ0VSVElGSUNBVEUtLS0tLQo=
server: https://192.168.124.100:9443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: dashboard-admin
name: dashboard-admin
current-context: dashboard-admin
kind: Config
preferences: {}
users:
- name: dashboard-admin
user:
token: eyJhbGciOiJSUzI1NiIsImtpZCI6ImFXTzZFUElaS2RoTUpScHFwNzJSNUN5eU1lcFNSZEZqNWNNbi1VbFV2Zk0ifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tMmJ4ZmwiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiNDkyYTAzMWUtZGI0MS00YTY1LWE4ZDQtYWYwZTI0MGU3ZjlkIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmVybmV0ZXMtZGFzaGJvYXJkOmRhc2hib2FyZC1hZG1pbiJ9.l5VEIPd9nIsJuXMh86rjFHhkIoZmg5nlDw7Bixn0b3-KT1r6o7WRegq8DJyVk_iiIfRnrrz5jjuOOkCKwXwvI1NCfVdsuBKXFwFZ1Crc-BwHjIxWbGuZfEGxSbN8du4T4xcUuNU-7HuZQcGDY23uy68aPqWSm8UoIcOFwUgVcYkKlOuW76tIXxG_upxWpWZz74aMDUIkjar7sdWXzMr1m5G43TLE9Z_lKCgoV-hc4Fo9_Er-TIAPqDG6-sfZZZ9Raldvn3j380QDYahUKaGKabnOFDXbODKOQ1VKRizgiRTOqt-z9YRPTcyxQzfheKC8DTb2X8D-E4x6azulenNgqw
4、选择Kubeconfig文件登陆Dashboard即可
附录-查看Kubernetes与Docker兼容性
访问网址:https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.23.md
附录-重置节点
当在使用"kubeadm init"或"kubeadm join"部署节点出现失败状况时,可以使用以下操作对节点进行重置!
注:重置会将节点恢复到未部署前状态,若集群已正常工作则无需重置,否则将引起不可恢复的集群故障!
[root@k8s-master01 ~]# kubeadm reset -f
[root@k8s-master01 ~]# ipvsadm --clear
[root@k8s-master01 ~]# iptables -F && iptables -X && iptables -Z
附录-常用查看命令
更多的操作请完整学习Kubernetes的资源和集群管理!
查看令牌(Token)列表:
[root@k8s-master01 ~]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
abcdef.0123456789abcdef <forever> <never> authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
ek6xtl.s3dk4vjxzp83bcx3 1h 2022-04-06T13:30:39Z <none> Proxy for managing TTL for the kubeadm-certs secret <none>
查看kubernetes集群中证书到期时间:
[root@k8s-master01 ~]# kubeadm certs check-expiration
[check-expiration] Reading configuration from the cluster...
[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Mar 18, 2122 04:02 UTC 99y no
apiserver Mar 18, 2122 04:02 UTC 99y ca no
apiserver-etcd-client Mar 18, 2122 04:02 UTC 99y etcd-ca no
apiserver-kubelet-client Mar 18, 2122 04:02 UTC 99y ca no
controller-manager.conf Mar 18, 2122 04:02 UTC 99y no
etcd-healthcheck-client Mar 18, 2122 04:02 UTC 99y etcd-ca no
etcd-peer Mar 18, 2122 04:02 UTC 99y etcd-ca no
etcd-server Mar 18, 2122 04:02 UTC 99y etcd-ca no
front-proxy-client Mar 18, 2122 04:02 UTC 99y front-proxy-ca no
scheduler.conf Mar 18, 2122 04:02 UTC 99y no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Mar 18, 2122 04:02 UTC 99y no
etcd-ca Mar 18, 2122 04:02 UTC 99y no
front-proxy-ca Mar 18, 2122 04:02 UTC 99y no
查看节点运行状态:
[root@k8s-master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready control-plane,master 40h v1.23.0
k8s-master02 Ready control-plane,master 40h v1.23.0
k8s-master03 Ready control-plane,master 40h v1.23.0
k8s-node01 Ready <none> 39h v1.23.0
查看Kubeadm初始化控制平面默认使用的配置信息:
[root@k8s-master ~]# kubeadm config print init-defaults
查看Kubeadm部署安装Kubernetes集群所要使用的容器镜像列表:
[root@k8s-master ~]# kubeadm config images list
查看集群中的名称空间(NameSpace):
[root@k8s-master01 ~]# kubectl get namespace
NAME STATUS AGE
default Active 44h
ingress-nginx Active 13h
kube-node-lease Active 44h
kube-public Active 44h
kube-system Active 44h
kubernetes-dashboard Active 7h7m
查看指定名称空间下Pod运行状态:
[root@k8s-master01 ~]# kubectl get pod --namespace=kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-56fcbf9d6b-phf49 1/1 Running 0 16h
calico-node-8frvw 1/1 Running 0 16h
calico-node-mzpmv 1/1 Running 0 16h
calico-node-rblcg 1/1 Running 0 16h
calico-node-vh9c9 1/1 Running 0 16h
coredns-6d8c4cb4d-85b5t 1/1 Running 0 16h
coredns-6d8c4cb4d-h7ttw 1/1 Running 0 16h
etcd-k8s-master01 1/1 Running 73 (19h ago) 44h
etcd-k8s-master02 1/1 Running 51 (19h ago) 43h
etcd-k8s-master03 1/1 Running 1 (24h ago) 43h
...
附录-新的Pod可以调度到Master节点上运行吗?
可以,默认情况下Master节点在创建的时候,就已经被填充了污点"taints",如果想要在Master节点上运行Pod,只需要将"taints"删除即可!(不建议的操作)
[root@k8s-master01 ~]# kubectl describe nodes/k8s-master01
Name: k8s-master01
...
Taints: node-role.kubernetes.io/master:NoSchedule
...
[root@k8s-master ~]# kubectl taint nodes --all node-role.kubernetes.io/master-
附录-集群最大支持多少个节点那?
参考文档:https://kubernetes.io/docs/setup/best-practices/cluster-large/
Kubernetes集群是由一组运行有Kubernetes代理的节点(物理机/虚拟机)组成,由控制平面节点管理着工作节点。
Kubernetes-v1.23.x理论上支持5000个节点的集群,其中:
- 每个节点不超过110个Pod;
- 集群中总的Pod数量不超过150000个;
- 集群中总的容器数量不超过300000个。
以上数据仅是官方实践后得出的结论!
工作节点由一个或多个控制平面节点管理,控制平面节点可以管理工作节点的数量取决于控制平面节点所在物理主机的CPU、内存、磁盘IO和空间使用情况!那么这时候对主机以及相关组件做好监控是非常重要的!
其他人员的经验:
一台1核2GB的控制平面节点可以管理约5个工作节点!
一台32核120GB的控制平面节点可以管理约500个工作节点!
以上数据仅供参考!
使用Kubeadm搭建高可用Kubernetes集群的更多相关文章
- 搭建高可用kubernetes集群(keepalived+haproxy)
序 由于单master节点的kubernetes集群,存在master节点异常之后无法继续使用的缺陷.本文参考网管流程搭建一套多master节点负载均衡的kubernetes集群.官网给出了两种拓扑结 ...
- 用kubeadm创建高可用kubernetes集群后,如何重新添加控制平面
集群信息 集群版本:1.13.1 3个控制平面,2个worker节点 k8s-001:10.0.3.4 k8s-002:10.0.3.5 k8s-003:10.0.3.6 k8s-004:10.0.3 ...
- 搭建高可用mongodb集群(四)—— 分片(经典)
转自:http://www.lanceyan.com/tech/arch/mongodb_shard1.html 按照上一节中<搭建高可用mongodb集群(三)-- 深入副本集>搭建后还 ...
- [转]搭建高可用mongodb集群(四)—— 分片
按照上一节中<搭建高可用mongodb集群(三)—— 深入副本集>搭建后还有两个问题没有解决: 从节点每个上面的数据都是对数据库全量拷贝,从节点压力会不会过大? 数据压力大到机器支撑不了的 ...
- [转]搭建高可用mongodb集群(二)—— 副本集
在上一篇文章<搭建高可用MongoDB集群(一)——配置MongoDB> 提到了几个问题还没有解决. 主节点挂了能否自动切换连接?目前需要手工切换. 主节点的读写压力过大如何解决? 从节点 ...
- 搭建高可用mongodb集群(四)—— 分片
按照上一节中<搭建高可用mongodb集群(三)—— 深入副本集>搭建后还有两个问题没有解决: 从节点每个上面的数据都是对数据库全量拷贝,从节点压力会不会过大? 数据压力大到机器支撑不了的 ...
- 搭建高可用mongodb集群(三)—— 深入副本集内部机制
在上一篇文章<搭建高可用mongodb集群(二)—— 副本集> 介绍了副本集的配置,这篇文章深入研究一下副本集的内部机制.还是带着副本集的问题来看吧! 副本集故障转移,主节点是如何选举的? ...
- 搭建高可用mongodb集群(二)—— 副本集
在上一篇文章<搭建高可用MongoDB集群(一)——配置MongoDB> 提到了几个问题还没有解决. 主节点挂了能否自动切换连接?目前需要手工切换. 主节点的读写压力过大如何解决? 从节点 ...
- 搭建高可用mongodb集群(一)——配置mongodb
在大数据的时代,传统的关系型数据库要能更高的服务必须要解决高并发读写.海量数据高效存储.高可扩展性和高可用性这些难题.不过就是因为这些问题Nosql诞生了. NOSQL有这些优势: 大数据量,可以通过 ...
随机推荐
- CTF--Do you like xml
题目链接:http://47.94.221.39:8008/ 扫描目录得到/.DS_Store文件 下载文件,直接用脚本进行还原操作. https://github.com/lijiejie/ds_s ...
- 西门子STEP7安装过程不断提示电脑重启的解决方法
win+R打开注册表 进入 计算机\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager 删除PendingFileR ...
- Kafka 的高可靠性是怎么实现的?
可以参见我这篇文章:Kafka 是如何保证数据可靠性和一致性
- linux设置java环境变量与开机自启
一.下载jdk并放置在指定位置 二.编辑profile文件 vim /etc/profile 或者 将/etc下的profile 文件修改好再上传覆盖源文件 修改方式即添加以下内容至文件最底部即可 ...
- jQuery--筛选【过滤函数】
之前选择器可以完成的功能,筛选也提供了相同的函数 筛选函数介绍 eq(index|-index) 类似:eq()index:正数,从头开始获得指定所有的元素,从0算起,0表示第一个-index:负数, ...
- Linux Yum仓库源配置
Yum概念:Yum软件仓库的作用是为了进一步简化RPM管理软件的难度以及自动分析所需软件包及其依赖关系的技术 Yum配置仓库源放置位置:/etc/yum.repo.d/ :配置文件需以 .repo 结 ...
- idea-spring-boot打包jar/var
下面的插件配置的里面需要加上具体的main类 <groupId>org.springframework.boot</groupId> <artifactId>spr ...
- jvm性能调优工具
1.jstat 命令 jstat: 查看类装载,内存,垃圾收集,gc相关信息 命令参数 # jstat -option -t #option:参数选项,-t:显示系统的时间 # jstat -opti ...
- Spring Mvc 源代码之我见 一
spring mvc 是一个web框架,包括controller.model.view 三大块.其中,核心在于model这个模块,用于处理请求的request. 和之前的博客一样,关键的代码,我会标注 ...
- glusterfs架构和原理
分布式存储已经研究很多年,但直到近年来,伴随着谷歌.亚马逊和阿里等互联网公司云计算和大数据应用的兴起,它才大规模应用到工程实践中.如谷歌的分布式文件系统GFS.分布式表格系统google Bigtab ...