算法竞赛进阶指南 0x43 线段树
线段树简介
英文名称:Segment Tree
相比于树状数组,是一种更加通用的结构。
- 每一个节点代表一个区间。
- 只有唯一的根节点,根节点对应的是所有统计区间(\(1-N\))上的值。
- 线段树的每一个叶子节点都代表着x-x的值。
- 对于一个线段树的内部节点,当TA对应的是\(L-R\),那么
- 左孩子对应\(L-\lfloor {{L+R}\over {2}} \rfloor\)
- 右孩子对应\(\lfloor {{L+R}\over {2}} \rfloor-R\)
线段树的规律研究:
除去最后一层,发现线段树是一个完全二叉树。
所以可以像二叉堆那样,使用一个数组来存储整棵二叉树- 对于二叉树的父亲节点:x/2
- 对于二叉树的左孩子:x*2
- 对于二叉树的右孩子:x*2+1
线段树的高度是\(logN\)
对于具有N个节点的满二叉树,需要有\(2N-1\)个节点。但是对线段树,最后一层也许会有枝叶,所以应该创建\(4N\)的数组。
线段树的简单代码实现
下面使用维护一个区间最大值的这一个任务来熟悉线段树的基本使用
父亲节点对应区间的最大值等于两个儿子节点的最大值的最大值
线段树的建立方法:
- 从上往下建树
- 从下往上传递信息
建树代码
#include <bits/stdc++.h>
using namespace std;
#define SIZE 100
struct SegmentTree{
int l, r;
int data;
}t[4*SIZE];
int s[SIZE];//表示需要被维护最大值的区间
void build(int p, int l, int r)
{
t[p].l = l;
t[p].r = r;
if(l == r)
{
t[p].data = s[l];
return;
}
int mid = (l+r)/2;
build(p*2, l, mid);
build(p*2+1, mid+1, r);
t[p].data = max(t[p*2].data, t[p*2+1].data);
}
int main()
{
int n;
cin>>n;
for(int i = 1; i <= n; i++)
scanf("%d", s+i);
build(1, 1, n);
return 0;
}
修改操作
void change(int p, int x, int v)
//p表示当前的位置指针,x表示在s数组中需要修改的下标。v表示修改之后的值
{
if(t[p].l == t[p].r) {
t[p].data = v;
return;
}
int mid = (t[p].l+t[p].r) / 2;
if(x <= mid) change(2*p, x, v);
else change(2*p+1, x, v);
t[p].data = max(t[p*2].data, t[p*2+1].data);
}
查询操作
有两种情况:
- 所要查询的区间完全覆盖了当前节点的区间,此时,应该直接返回这一个区间的值(作为要查询区间的最大值的候选)
- 否则进行递归查找。
int ask(int p, int l, int r)
{
if(l <= t[p].l && r >= t[p].r)
{
return t[p].data;
}
int mid = (t[p].l + t[p].r)/2;
int ans = INT_MIN;
if(l <= mid) ans = max(ask(p*2, l, r), ans);
if(r > mid) ans = max(ask(p*2+1, l, r), ans);
return ans;
}
线段树的查询操作的时间复杂度分析:
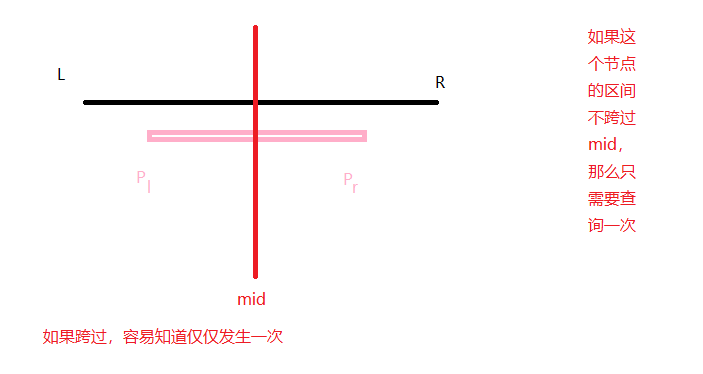
有以下几种情况:(不妨认为l,r表示要查询的区间)
(\(p_l\)表示节点的左端点,\(p_r\)表示节点的右端点)
不妨设\(mid=\lfloor\frac{p_l+p_r}{2} \rfloor\)
当\(l\leq p_l 并且 p_r\leq r\),此时,不产生递归。直接返回
\(l> p_l 并且 l\leq p_r\leq r\)
- 情形一:当\(l \leq mid\),那么就会递归两个区间,但是右半区间只进行递归一次。
- 情形而:当\(l>mid\)此时,递归一个子区间.
\(r<p_r 并且 l\leq p_l \leq r\),与2相同
AcWing245. 你能回答这些问题吗

思路
线段树可以更加方便地维护各种区间的信息。
但是要注意:这些信息必须具备空间可加性!!
我的思路是把每一个区间的最大区间维护出来,在把该最大区间的左右端点维护出来,但是这样在进行传递的时候仅仅可以知道是否能把区间合并到一起,但是最大值又会发生变化,为此进行分析:
区间最大值的可能情况有以下三种情况
- 最大值位于左子树中
- 最大值位于右son中
- 最大值跨越位于左树与右树的
所以在维护最大值的同时,应该加上从区间的左边往右数的区间最大值lmax以及右边往左数的区间最大值rmax
对于区间最大值,那么就是两个字树区间单独区间最大值与左子树的rmax以及右子树的lmax之中的最大值
即max(t[p*2].maxx, t[p*2+1].maxx, t[p*2].rmax+t[p*2+1].lmax)
但是对于lmax以及rmax有两种情况:
lmax仍然是左子树的lmaxlmax是左子树的全部区间加上右子树的lmax
对于这种情况,还要知道左子树的区间总和sum
综上,共维护4+2个信息
lmax,rmax,maxx,sum,l,r
代码[时间复杂度:\(O( \space(N+M)logN)\) ]
#include<bits/stdc++.h>
using namespace std;
#define N 20
//500000
int s[N];
class SegmentTree{
private:
struct T{
int l, r, lmax, rmax, maxx, sum;
}t[4*N];
public:
void build(int p, int l, int r)
{
t[p].l = l;
t[p].r = r;
if(l==r)
{
t[p].lmax = t[p].rmax = t[p].maxx = t[p].sum = s[l];
return;
}
int mid = (l+r)/2;
build(p*2, l, mid);
build(p*2+1, mid+1, r);
t[p].lmax = max(t[p*2].lmax, t[p*2].sum+t[p*2+1].lmax);
t[p].rmax = max(t[p*2+1].rmax, t[p*2+1].sum + t[p*2].rmax);
t[p].sum = t[p*2].sum + t[p*2+1].sum;
t[p].maxx = max(max(t[p*2].maxx, t[p*2+1].maxx), t[p*2].rmax + t[p*2+1].lmax);
return;
}
void change(int p, int x, int v)
{
if(t[p].l == t[p].r)
{
t[p].lmax = t[p].rmax = t[p].maxx = t[p].sum = v;
return ;
}
int mid = (t[p].l+t[p].r)/2;
if(x <= mid) change(p*2, x, v);
else change(p*2+1, x, v);
t[p].lmax = max(t[p*2].lmax, t[p*2].sum+t[p*2+1].lmax);
t[p].rmax = max(t[p*2+1].rmax, t[p*2+1].sum + t[p*2].rmax);
t[p].sum = t[p*2].sum + t[p*2+1].sum;
t[p].maxx = max(max(t[p*2].maxx, t[p*2+1].maxx), t[p*2].rmax + t[p*2+1].lmax);
return;
}
T ask_pro(int p, int l, int r)
{
if(l <= t[p].l && t[p].r <= r) return t[p];
T a, b, ans;
a.lmax = a.rmax = a.maxx = a.sum = b.sum = b.lmax = b.rmax = b.maxx = -0x3f3f3f3f;//注意,虽然INT_MIN更加小,但是可能会发生溢出!!!
ans.sum = 0;//ans其他的属性在之后会有更新,所以不需要初始化~~
int mid = (t[p].l + t[p].r)/2;
if(l <= mid)
{
a = ask_pro(2*p, l, r);
ans.sum += a.sum;
}
if(r > mid)
{
b = ask_pro(2*p+1, l, r);
ans.sum += b.sum;
}
ans.lmax = max(a.lmax, a.sum+b.lmax);//假设是有两个区间,在下面进行讨论
ans.rmax = max(b.rmax, a.rmax+b.sum);
ans.maxx = max(max(a.maxx, b.maxx), a.rmax+b.lmax);
if(l > mid) ans.lmax = max(ans.lmax, b.lmax);
if(r <= mid) ans.rmax = max(ans.rmax, a.rmax);
return ans;
}
int ask(int p, int l, int r)
{
return ask_pro(p, l, r).maxx;
}
};
SegmentTree t;
int main()
{
int n, m;
scanf("%d%d", &n, &m);
for(int i = 1; i <= n; i++) scanf("%d", s+i);
t.build(1, 1, n);
for(int i = 1; i <= m; i++)
{
int k, x, y;
scanf("%d%d%d", &k, &x, &y);
if(k==1)//表示查询
{
if(x > y) swap(x, y);
printf("%d\n", t.ask(1, x, y));
}
else//表示修改
{
t.change(1, x, y);
}
}
return 0;
}
错误分析
int ask(int p, int l, int r)
{
if(l <= t[p].l && t[p].r <= r)
{
return t[p].maxx;
}
int mid = (t[p].r + t[p].l)/2;
int ans = INT_MIN;
if(l <= mid) ans = max(ask(p*2, l, r), ans);
if(r > mid) ans = max(ask(p*2+1, l, r), ans);
return ans;
}
经过分析,发现是在ask这里发生了错误。
区间最大值的结果并不是一味地累加,而是要做许多决策。
注意:我在新改进的代码中,在ask中建立的ans,a,b,的l和r变量其实都没有用!!
有用的只有lmax和rmax和maxx
AcWing246. 区间最大公约数

思路
注意:线段树同样也是单点修改,区间查询
如果同时修改一个区间的值,求出一个差分序列或许会比较好。
注意:补充欧几里得定律
\(gcd(a, b, c) = gcd(a, b-a, c-b)\) [对于任意多个整数均成立]
这启示我们可以采用求差分来求gcd
- 好处:支持把区间操作化为单点操作
- 可以使用线段树来对gcd进行维护
设a[]存储原始数据,b[]存储a的差分
这个时候,gcd = gcd(a[l], b[l~r])这样,还需要一个区间修改,单点查询的树状数组来查询a[l]
代码
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define N 500010
ll a[N];
ll gcd(ll x, ll y)
{
if(y==0) return x;
return gcd(y, x%y);
}
class BIT{
private:
ll c[N];
public:
void add(ll x, ll y, ll max)
{
for(; x <= max; x += x&-x)
{
c[x] += y;
}
}
ll ask(ll x)
{
ll ans = 0;
for(; x; x -= x&-x)
{
ans += c[x];
}
return ans;
}
};
class SegmentTree{
private:
struct {
ll ans, l, r;
}t[4*N];
public:
void build(ll p, ll l, ll r)
{
t[p].l = l;
t[p].r = r;
if(l == r)
{
t[p].ans = a[l];
return;
}
ll mid = (l + r)/2;
build(p<<1, l, mid);
build(p<<1|1, mid+1, r);
t[p].ans = gcd(t[p<<1].ans, t[p<<1|1].ans);
}
ll ask(ll p, ll l, ll r)
{
if(l <= t[p].l && t[p].r <= r) return t[p].ans;
ll mid = (t[p].l + t[p].r)>>1;
ll ans = 0;
if(l <= mid) ans = gcd(ask(p<<1, l, r), ans);
if(r > mid) ans = gcd(ans, ask(p<<1|1, l, r));// ******
return abs(ans);// ************
}
void add(ll p, ll x, ll y)
{
if(t[p].l == t[p].r)
{
t[p].ans += y;
return;
}
ll mid = (t[p].l+t[p].r)>>1;
if(x <= mid) add(p<<1, x, y);
else add(p<<1|1, x, y);
t[p].ans = gcd(t[p<<1].ans, t[p<<1|1].ans);
}
};
BIT bit;
SegmentTree st;
int main()
{
ll n, m;
cin >> n >> m;
for(int i = 1; i <= n; i++)
{
scanf("%lld", a+i);
}
for(int i = n; i >= 1; i--)
{
a[i] -= a[i-1];
}
for(int i = 1; i <= n; i++)
{
bit.add(i, a[i], n);//建立树状数组
}
st.build(1, 1, n);
for(int i = 1; i <= m; i++)
{
char buf[4];
scanf("%s", buf);
if(buf[0]=='C')//表示修改
{
ll l, r, d;
scanf("%lld%lld%lld", &l, &r, &d);
st.add(1, l, d);
if(r+1 <= n) st.add(1, r+1, -d);
bit.add(l, d, n);
if(r+1 <= n)bit.add(r+1, -d, n);
}
else//表示进行询问
{
ll l, r;
scanf("%lld%lld", &l, &r);
if(l == r) cout << bit.ask(l) << '\n';
else cout << gcd(bit.ask(l), st.ask(1, l+1, r)) << '\n';
}
}
return 0;
}
总结
关于gcd的求法:
- 0与一个数字gcd还是这个数字。
- 对于负数,也可以使用gcd,效果与正数是一致的。
延迟标记
回顾并查集
当把两个集合合并的时候,只是把一个集合的根节点连接到了父亲节点,并没有花费大量的时间来处理被连接的这颗子树。
在查询的时候使用路径压缩进行处理。
概览
延迟标记主要适用于对于区间的修改。就像查询一样,当样修改的区间完全覆盖当前节点的区间的时候,然后就直接回溯,不再继续向下,把这一个节点做一个标记。当某一次查询的时候,如果需要查询这个节点的子节点,那么就
- 使用这个节点更新下面的值
- 给两个儿子打上标记
- 消除这个节点的标记
注意延迟标记的定义:当前节点已经被修改,但是子节点还没有被修改
AcWing243. 一个简单的整数问题2

总结与反思
在这道题目中,我仅仅是给当前节点增加了一个数字,并没有考虑到子区间的每一个数字全部增加,所以这个点在修改之后的值应该是区间长度乘以增加的值。
if(l <= t[p].l && t[p].r <= r)
{
t[p].add += d;
t[p].sum += d;
return;
}
代码
#include <bits/stdc++.h>
using namespace std;
#define N 100020
typedef long long ll;
ll s[N];
class SegmentTree{
private:
struct {
ll l, r, sum, add;//注意:add是增量延迟标记。
}t[4*N];
inline void spread(ll p)
{
if(t[p].add)
{
t[p<<1].add += t[p].add;
t[p<<1|1].add += t[p].add;
t[p<<1].sum += (t[p].add)*(t[p<<1].r-t[p<<1].l+1);
t[p<<1|1].sum += t[p].add*(t[p<<1|1].r-t[p<<1|1].l+1);
t[p].add = 0;
}
}
public:
void build(ll p, ll l, ll r)
{
t[p].l = l;
t[p].r = r;
if(l==r)
{
t[p].add = 0;//其实这一句话并没有什么实际的作用,因为在初始化的时候全部是0.
t[p].sum = s[l];
return;
}
ll mid = (l+r)>>1;
build(p<<1, l, mid);
build(p<<1|1, mid+1, r);
t[p].sum = t[p<<1].sum + t[p<<1|1].sum;
}
ll ask(ll p, ll l, ll r)
{
if(l <= t[p].l && t[p].r <= r)
return t[p].sum;
ll mid = (t[p].l+t[p].r) >> 1;
ll ans = 0;
if(l <= mid)
{
if(t[p].add) spread(p);
ans += ask(p<<1, l, r);
}
if(r > mid)
{ if(t[p].add) spread(p);
ans += ask(p<<1 | 1, l, r);
}
return ans;
}
void change_add(ll p, ll l, ll r, ll d)
{
if(l <= t[p].l && t[p].r <= r)
{
t[p].add += d;
t[p].sum += d*(t[p].r - t[p].l + 1);
return;
}
ll mid = (t[p].l + t[p].r) >> 1;
if(l <= mid)
{
if(t[p].add) spread(p);
change_add(p<<1, l, r, d);
}
if(r > mid)
{
if(t[p].add) spread(p);
change_add(p<<1|1, l, r, d);
}
t[p].sum = t[p<<1].sum + t[p<<1|1].sum;
}
};
SegmentTree t;
int main()
{
ll n, m;
scanf("%lld%lld", &n, &m);
for(int i = 1; i <= n; i++) scanf("%lld", s+i);
t.build(1, 1, n);
for(int i = 1; i <= m; i++)
{
char ch;
cin >> ch;
ll l, r;
scanf("%lld%lld", &l, &r);
if(ch=='C')//表示需要进行更改
{
ll d;
scanf("%lld", &d);
t.change_add(1, l, r, d);
}
else
{
printf("%lld\n", t.ask(1, l, r));
}
}
return 0;
}
扫描线
AcWing247. 亚特兰蒂斯

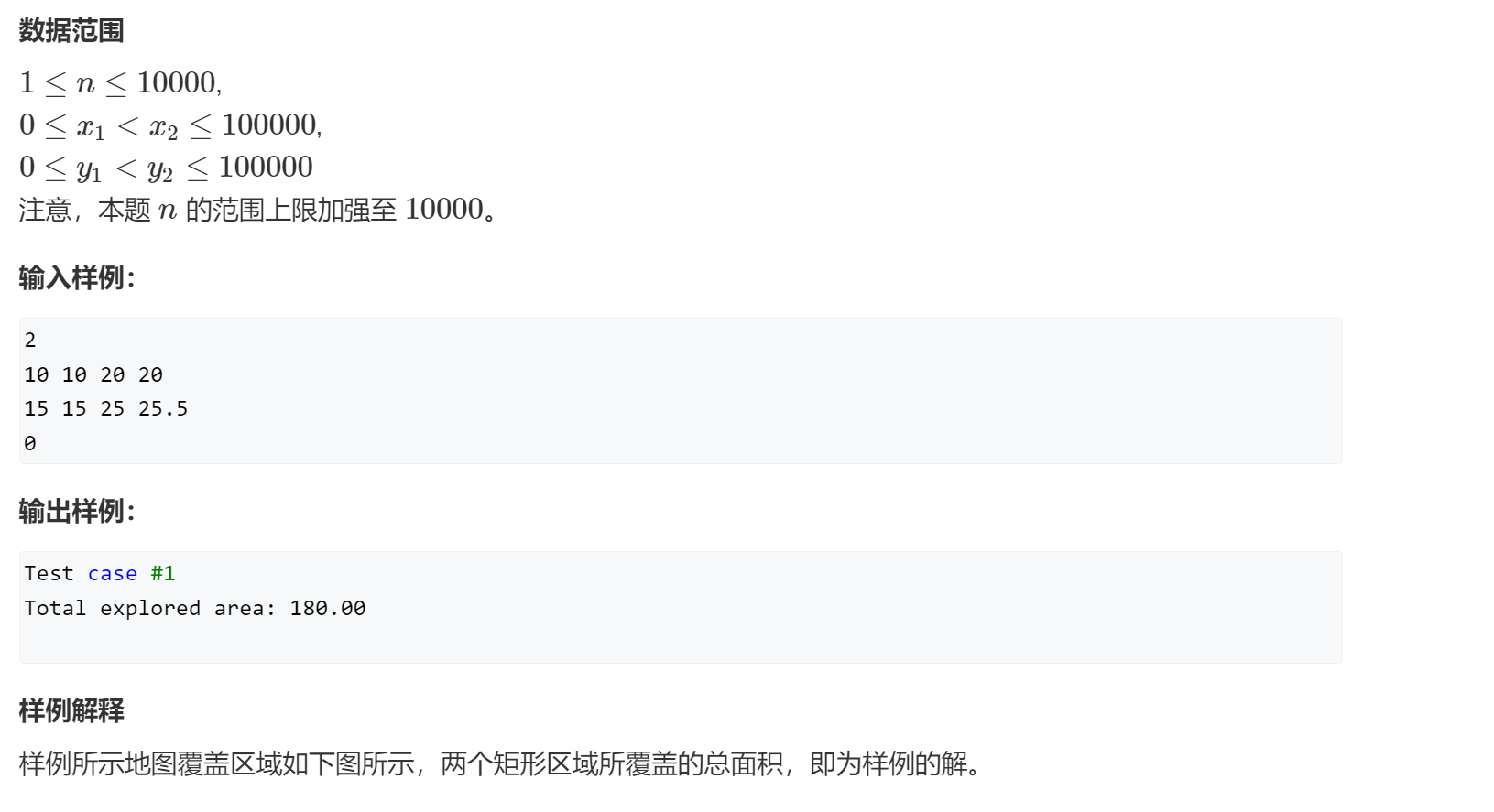
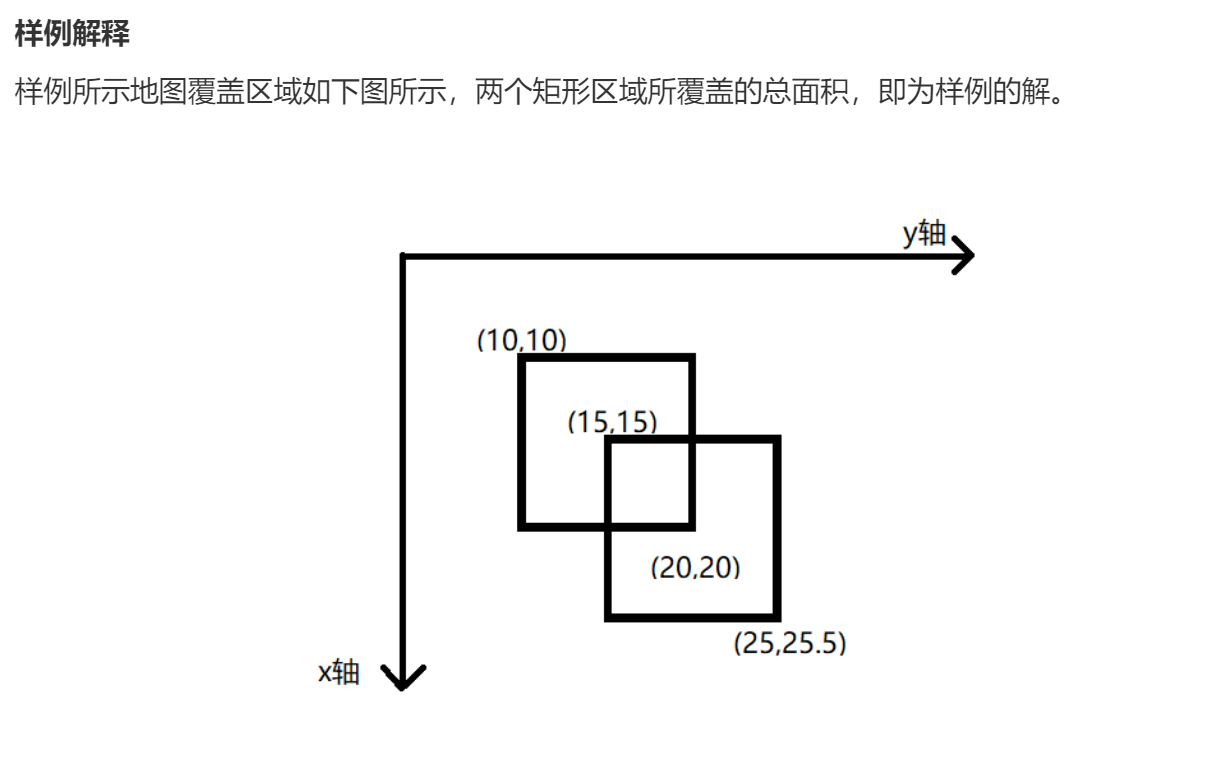
思路
这道题目我只会暴力。。
DeBug
我在处理线段树的过程中遇到了一些问题。
我认为线段树应该按照实际的端点进行存储。但是实际上,线段树必须存储区间(因为我的cnt操作是针对区间进行的)
是
代码
#include <bits/stdc++.h>
using namespace std;
#define N 100009
typedef long long ll;
struct EDGE{
double x;//表示横坐标
double y, z;//表示纵坐标,其中y < z
int k;//如果是1,那么就增加这一条边,如果是-1,那么就删除这一条边
inline bool operator < (const EDGE &o)const{//别忘记两个const
return x < o.x;
}
}a[2*N];
double raw[2*N];//离散化之后的整数对应的原始值
map<double, int> val;//原始值映射到的整数值
int m;//表示纵坐标的个数
class SegmentTree{
private:
struct {
int l, r, cnt;
double len;
}t[8*N];//因为最多有2*N个纵坐标的边界
//注意线段树的l与r和离散化之后的整数之间的标记的区别
//线段树里面的叶子节点表示的是长度为1的区间,这个编号为i的区间相当于离散化之后的[i, i+1]。
//所以线段树里有m-1个叶子节点。
void getval(int p)
{
if(t[p].cnt > 0) //这里有三种关系:
//第一种:这个点已经被标记了,这个时候,就应该直接冉伟这一个点所表示的区间已经全部被标记。
//第二种:这一个点没有被标记,此时,该点不是叶子节点,向下深入
//第三种:这一个点没有标记,同时不是叶子节点,直接认为是0。
{
t[p].len = raw[t[p].r+1]-raw[t[p].l];
}
else
{
if(t[p].l == t[p].r) t[p].len = 0;
else t[p].len = t[p<<1].len + t[p<<1|1].len;
}
}
public:
void build(int p, int l, int r)
{
//建树的时候只是所有节点的len和cnt全部都是0,所以不需要进行值的回溯
t[p].l = l;
t[p].r = r;
t[p].len = 0;
t[p].cnt = 0;
if(l==r)
{
return;
}
int mid = (l+r)>>1;
build(p<<1, l, mid);
build(p<<1|1, mid+1, r);
}
void change(int p, int l, int r, int d)
{
if(l <= t[p].l && t[p].r <= r)
{
t[p].cnt += d;
getval(p);
return ;
}
int mid = (t[p].l+t[p].r)>>1;
if(l <= mid) change(p<<1, l, r, d);
if(r > mid) change(p<<1|1, l, r, d);
getval(p);
}
double ask()
{
return t[1].len;
}
};
SegmentTree t;
int asdf= 0;//计数器
void solve(int n)
{
double ans = 0;//一定要注意这一个答案是double类型的
for(int i = 1; i <= n; i++)
{
int k = i << 1;
double y, z;
scanf("%lf%lf%lf%lf", &a[k-1].x, &y, &a[k].x, &z);// ******************!!!
a[k-1].y = a[k].y = y;
a[k].z = a[k-1].z = z;
raw[k-1] = y;
raw[k] = z;
a[k-1].k = 1;
a[k].k = -1;
}
sort(raw+1, raw+1+2*n);
m = unique(raw+1, raw+1+2*n)-(raw+1);//unique返回的值是去重之后区域的尾指针。
for(int i = 1; i <= m; i++) val[raw[i]] = i;
sort(a+1, a+1+2*n);
t.build(1, 1, m-1);// *********!!!!
for(int i = 1; i <= 2*n; i++)
{
ans += (a[i].x-a[i-1].x)*t.ask();// ********************
//cout << "debug" << val[a[i].y] << " " << val[a[i].z-1];
//fflush(stdout);
t.change(1, val[a[i].y], val[a[i].z]-1, a[i].k);
}
printf("Test case #%d\nTotal explored area: %.2lf\n",++asdf, ans);
puts("");
}
int main()
{
int n;
while(scanf("%d", &n) && n) solve(n);
return 0;
}
思路解析
如代码部分所示。
要注意,在这一道题目中,线段树是区间修改,按照道理,应该使用延迟标记来进行加快速度。
但是由于:
- 这道题目的增加以及删除是成对出现的
- 每一次查询全部是查询的最大的哪一个区间。
所以可以不适用延迟标记采用getval()函数内部的方法。
AcWing248. 窗内的星星

输入样例:
3 5 4
1 2 3
2 3 2
6 3 1
3 5 4
1 2 3
2 3 2
5 3 1
输出样例:
5
6
思路
这道题目就很像前缀和的板子题。
就是坐标的范围有一点大,但是可以进行离散化,然后就能统计前缀和,得到答案。
当然,这里使用线段树。
使用线段树需要迈过两个关卡
关卡一:框柱星星的边框边界的处理

关卡二:我框星星 or 星星自己来一个框
我框住的星星的亮度的最大值就等价于把每一个星星作为左下角,然后生成宽W-1,高H-1的亮度为c边框,所有边框放在一起,(亮度可以叠加),找到一点最亮的点。
证明:- 对于我框柱的星星的亮度 = 边框的右上角就是星星生成的边框中亮度叠加。
- 边框中任一点的叠加 = 以这一点为框框的右上角框柱的星星亮度的和。
两个集合等价,所以最大值也相等。
得证!
根据上一道题的做法,写代码不成问题!
注意:上一个题目是没有用到延迟标记(用了延迟标记的一半),但是这一道题目不能与上一道题目一样。
这里必须完整的延迟标记。
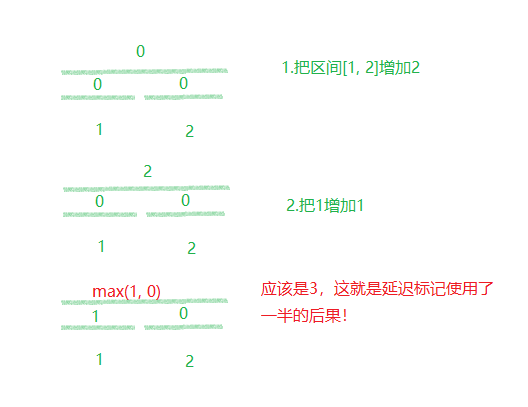
代码
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define N 10005
#define lc (p<<1)
#define rc (p<<1|1)
ll raw[N*2];//离散化之后的值 ———> 离散化之前的值
map<ll, ll> val;//离散化之前的值------> 离散化之后的值
struct AABS{
ll x, y, z, c;
inline bool operator < (const AABS &o) const{
return x < o.x || (x == o.x && c > o.c);// 注意我的第二关键字!!!!!!!!
//因为边界上的也算,
//假设有以下情况:在边界x上有一条边是$c = 5$,另一条边是$c = -3$,这个时候,应该先加上C大的(c小的在这里仍然起作用)
}
}a[N*2];
class SegmentTree{
private:
struct {
ll l, r, ans, add;
}t[N*8];
inline void spread(ll p)
{
if(t[p].add == 0) return;
t[lc].add += t[p].add;
t[rc].add += t[p].add;
t[lc].ans += t[p].add;
t[rc].ans += t[p].add;//这里的spread就是简单的+=
t[p].add = 0;
}
public:
void build(ll p, ll l, ll r)
{
t[p].l = l;
t[p].r = r;
t[p].ans = 0;
t[p].add = 0;//全部需要归零
if(l==r)
{
return ;
}
ll mid = (l+r)>>1;
build(lc, l, mid);
build(rc, mid+1, r);
}
void change(ll p, ll l, ll r, ll d)
{
if(l<= t[p].l&& r >= t[p].r)
{
t[p].ans += d;
t[p].add += d;
return ;
}
ll mid = (t[p].l + t[p].r)>>1;
spread(p);
if(l <= mid) change(lc, l, r, d);
if(r > mid) change(rc, l, r, d);
t[p].ans = max(t[lc].ans, t[rc].ans);
}
ll ask(ll p, ll l, ll r)
{//其实针对所有区间的(不用这样麻烦)~ ~ ~ ~ ~
if(l <= t[p].l && t[p].r <= r)
{
return t[p].ans;
}
ll mid = (t[p].l + t[p].r) >> 1;
ll ret = -0x3f3f3f3f3f3f3f;
if(l <= mid) ret = max(ret, ask(lc, l, r));
if(r > mid) ret = max(ret, ask(lc, l, r));
return ret;
}
};
SegmentTree t;
void solve(int n, int W, int H)
{
ll ans = 0;
val.clear();
for(int i = 1; i <= n; i++)
{
ll x, y, c;
scanf("%lld%lld%lld", &x, &y, &c);
x++;//注意还有x==0 的情况,所以我在这里加1以防止越界!!!
y++;
ll k = i<<1;
a[k-1].x = x;
a[k].x = x+W-1;// 还可以是另一种组合:
//是a[k].x = x+W; 并且 最一开始的a的比较应该是把c小的放在前面(两种全部可以AC)
a[k].y = a[k-1].y = y;
a[k].z = a[k-1].z = y+H-1;
a[k-1].c = c;
a[k].c = -c;
raw[k-1] = y;
raw[k] = y+H-1;
}
sort(a+1, a+1+2*n);
sort(raw+1, raw+1+2*n);
ll m = unique(raw+1, raw+1+n*2)-(raw+1);
for(int i = 1; i <= m; i++)
{
val[raw[i]] = i;
}
t.build(1, 1, m);//注意:这里是维护的点的最大值
//注意:这里需要建立m个
for(int i = 1; i <= 2*n; i++)
{
t.change(1, val[a[i].y], val[a[i].z], a[i].c);
ans = max(ans, t.ask(1, 1, m));
}
cout << ans << "\n";
}
int main()
{
int n, H, W;
while(cin >> n >> W >> H) solve(n, W, H);
return 0;
}
动态开点与线段树的合并
动态开点
线段树用来维护一段的权值范围:称为权值线段树。
动态开点的意义:
降低空间复杂度
- 优点
- 可以降低空间复杂度。
之前需要开4*N
现在的空间复杂度是\(O(MlogN)\),M 是操作次数,最大不超过N-1(如果所有叶子节点全部连进来)
- 可以降低空间复杂度。
- 缺点
- 抛弃了之前的完全二叉树的2倍存储结构,左右孩子的索引需要借助指针进行实现。
- 区别
- 原来的l和r已经变成现在的左孩子以及右孩子指针,
l和r依靠区间进行传递。
- 原来的l和r已经变成现在的左孩子以及右孩子指针,
初始化代码
#include <bits/stdc++.h>
using namespace std;
#define N 100
struct Tree{
int lc, rc, ans;
}t[2*N];
int tot = 0;
int root;
//所需要的三要素:
//1.大小为2*N的结构体
//2.tot表示计数
//3.root表示根节点
int build()//作用为新建一个节点
{
tot++;
t[tot].ans = t[tot].lc = t[tot].rc = 0;
return tot;
}
int main()
{
tot = 0;
root = build(); //这两步相当于是初始化
return 0;
}
示例操作代码
void add(int p, int l, int r, int val, int delta)//作用:把val位置增加delta
{
if(l==r)
{
t[p].ans += delta;
return ;
}
int mid = (l+r)>>1;
if(val <= mid)
{
if(!t[p].lc) t[p].lc = build();
add(t[p].lc, l, mid, val, delta);
}
else
{
if(!t[p].rc) t[p].rc = build();
add(t[p].rc, mid+1, r, val, delta);
}
t[p].ans = max(t[t[p].lc].ans, t[t[p].rc].ans);
//注意:当某一个孩子不存在的时候,访问的是t[0],注意把t[0].ans 设置合适的值
}
线段树的合并
初始条件:
两个线段树要维护相同的总区间
合并代码
注意:仅仅适用于
- 动态开点
- 两个线段树维护的区间值相同
以下代码表示得到把两个线段树维护的数列相加之后的线段树。
如果直接暴力操作比较麻烦,直接线段树合并比较容易
int Merge(int p, int q, int l,int r)
{
if(!q) return p;
if(!p) return q;
if(l == r)
{
t[p].ans += t[q].ans;
return p;
}
int mid = (l+r)>>1;
t[p].lc = Merge(t[p].lc, t[q].lc, l, mid);
t[p].rc = Merge(t[p].rc, t[q].rc, mid+1, r);
t[p].ans = max(t[t[p].lc].ans, t[t[p].rc].ans);//不要忘记更新值
return p;//不要忘记返回
}
时间复杂度分析
由于在合并的过程中,每一次调用Merge函数都会删除一个节点。所以时间复杂度为\(MlogN\),其中M是插入的次数,N是区间的长度。时间复杂度最多不超过2*N。
完!
算法竞赛进阶指南 0x43 线段树的更多相关文章
- POJ1639 算法竞赛进阶指南 野餐规划
题目描述 原题链接 一群小丑演员,以其出色的柔术表演,可以无限量的钻进同一辆汽车中,而闻名世界. 现在他们想要去公园玩耍,但是他们的经费非常紧缺. 他们将乘车前往公园,为了减少花费,他们决定选择一种合 ...
- 算法竞赛进阶指南0x14 Hash
组成部分: 哈希函数: 链表 AcWing137. 雪花雪花雪花 因为所需要数据量过于大,所以只能以O(n)的复杂度. 所以不可能在实现的过程中一一顺时针逆时针进行比较,所以采用一种合适的数据结构. ...
- 《算法竞赛进阶指南》0x10 基本数据结构 Hash
Hash的基本知识 字符串hash算法将字符串看成p进制数字,再将结果mod q例如:abcabcdefg 将字母转换位数字(1231234567)=(1*p9+2*p8+3*p7+1*p6+2*p5 ...
- 《算法竞赛进阶指南》1.4Hash
137. 雪花雪花雪花 有N片雪花,每片雪花由六个角组成,每个角都有长度. 第i片雪花六个角的长度从某个角开始顺时针依次记为ai,1,ai,2,-,ai,6. 因为雪花的形状是封闭的环形,所以从任何一 ...
- 《算法竞赛进阶指南》1.6Trie
142. 前缀统计 给定N个字符串S1,S2-SN,接下来进行M次询问,每次询问给定一个字符串T,求S1-SN中有多少个字符串是T的前缀. 输入字符串的总长度不超过106,仅包含小写字母. 输入格式 ...
- bzoj 1787 && bzoj 1832: [Ahoi2008]Meet 紧急集合(倍增LCA)算法竞赛进阶指南
题目描述 原题连接 Y岛风景美丽宜人,气候温和,物产丰富. Y岛上有N个城市(编号\(1,2,-,N\)),有\(N-1\)条城市间的道路连接着它们. 每一条道路都连接某两个城市. 幸运的是,小可可通 ...
- 算法竞赛进阶指南 0x00 基本算法
放在原来这个地方不太方便,影响阅读体验.为了读者能更好的刷题,另起一篇随笔. 0x00 基本算法 0x01 位运算 [题目][64位整数乘法] 知识点:快速幂思想的灵活运用 [题目][最短Hamilt ...
- 算法竞赛进阶指南--快速幂,求a^b mod p
// 快速幂,求a^b mod p int power(int a, int b, int p) { int ans = 1; for (; b; b >>= 1) { if (b &am ...
- 算法竞赛进阶指南0x41并查集
并查集简介 并查集的两类操作: Get 查询任意一个元素是属于哪一个集合. Merge 把两个集合合并在一起. 基本思想:找到代表元. 注意有两种方法: 使用一个固定的值(查询方便,但是在合并的时候需 ...
随机推荐
- 1 Mybatis动态SQL
Mybatis动态SQL 1. 注解开发 我们也可以使用注解的形式来进行开发,用注解来替换掉xml. 使用注解来映射简单语句会使代码显得更加简洁,但对于稍微复杂一点的语句,Java 注解不仅力不从 ...
- PowerJob高级特效-容器部署完整教程
介绍 powerjob提供了容器功能,用来做一些灵活的任务处理.这里容器为 JVM 级容器,而不是操作系统级容器(Docker).(至于为什么取"容器"这个有歧义的名字是因为作者没 ...
- 是时候使用 YAML 来做配置或数据文件了
概述 我们做程序,经常需要用到配置信息,回顾一下这么多年的搬砖生涯,我记得用过多种格式的文件来定义配置信息,例如 ini文件,xml文件,或者现在比较流行的 json 文件. 这些年虽然云计算和云原生 ...
- linux篇-linux iptables配置
1 iptables默认系统自带 setup 2重启防火墙 /etc/init.d/iptables restart 3接受端口 Vi /etc/sysconfig/iptables -A INPUT ...
- 151-模型-Power BI&Power Pivot模型DAX函数使用量分析
151-模型-Power BI&Power Pivot模型DAX函数使用量分析 1.背景 我们在 Power BI 或者 Power Pivot 项目中会写很多的 DAX 表达式.在最后项目交 ...
- 基于Python的渗透测试信息收集系统的设计和实现
信息收集系统的设计和实现 渗透测试是保卫网络安全的一种有效且必要的技术手段,而渗透测试的本质就是信息收集,信息搜集整理可为后续的情报跟进提供强大的保证,目标资产信息搜集的广度,决定渗透过程的复杂程度, ...
- HTML行内元素与块级元素有哪些及区别详解
转自 https://www.jb51.net/web/724286.html 这篇文章主要介绍了HTML行内元素与块级元素有哪些及区别详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具 ...
- 支付宝开放平台--网页&移动应用(一)
前提是先在支付宝上签约自己需要的支付宝功能,然后支付宝开放平台才能设置你需要的功能 一:支付宝开放平台登录 登录进入支付宝开放平台 二:根据自己的需求创建应用(我是用的网页&移动应用) 三:点 ...
- 入坑KeePass(二)重置keepass设置
保留好.kdbx和密钥文件,软件的文件可以删除掉,重新下载并解压设置就恢复默认了
- SSMS设置为深色模式
更新记录 2022年4月16日:本文迁移自Panda666原博客,原发布时间:2022年2月8日. 2022年4月16日:SSMS很好用,但现在我更多使用DataGrip了. 2022年6月11日:S ...