Hadoop集群搭建(完全分布式版本) VMWARE虚拟机
Hadoop集群搭建(完全分布式版本)
VMWARE虚拟机
一、准备工作
三台虚拟机:master、node1、node2
时间同步
ntpdate ntp.aliyun.com
调整时区
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
jdk1.8(以1.8为例,目前大多数企业都是使用1.8版本,最稳定)
java -version
修改主机名
三台分别执行 vim /etc/hostname 并将内容指定为对应的主机名
关闭防火墙:systemctl stop firewalld
查看防火墙状态:systemctl status firewalld
取消防火墙自启:systemctl disable firewalld
静态IP配置
直接使用图形化界面配置(不推荐)
手动编辑配置文件进行配置
1、编辑网络配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
BOOTPROTO=static
HWADDR=00:0C:29:E2:B8:F2
NAME=ens33
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.190.100
GATEWAY=192.168.190.2
NETMASK=255.255.255.0
DNS1=192.168.190.2
DNS2=223.6.6.6
需要修改:HWADDR(mac地址,centos7不需要手动指定mac地址)
IPADDR(根据自己的网段,自定义IP地址)
GATEWAY(根据自己的网段填写对应的网关地址)
2、关闭NetworkManager,并取消开机自启
systemctl stop NetworkManager
systemctl disable NetworkManager
3、重启网络服务
systemctl restart network
免密登录
# 1、生成密钥
ssh-keygen -t rsa
注意:连敲三次生成方格形状的密钥,在当前状态下,配置免密钥登陆。
# 2、配置免密登录(三台虚拟机都需要进行免密操作,不要怕麻烦!!)
ssh-copy-id master
ssh-copy-id node1
ssh-copy-id node2
# 3、测试免密登录
ssh node1
ssh node2
ssh master配置好映射文件:/etc/hosts(三台虚拟机都需要配置)
192.168.170.100 master
192.168.170.101 node1
192.168.170.102 node2
注意:每个人的IP地址都是不一样的,查看自己的IP地址使用 ifconfig
使用远程复制
cd /etc
scp -r hosts/ node1:`pwd`
scp -r hosts/ node2:`pwd`
二、搭建Hadoop集群
NameNode:接受客户端的读/写服务,收集 DataNode 汇报的 Block 列表信息
DataNode:真实数据存储的地方(block)
SecondaryNameNode:做持久化的时候用到
| 进程 | master(主) | node1(从) | node2(从) |
|---|---|---|---|
| NameNode | √ | ||
| SecondaryNameNode | √ | ||
| ResourceManager | √ | ||
| DataNode | √ | √ | |
| NodeManager | √ | √ |
2.1 完全分布式搭建
1、上传安装包并解压
# 使用xftp上传压缩包至master的/usr/local/soft/packages/
cd /urs/local/soft/packages/
# 解压
tar -zxvf hadoop-2.7.6.tar.gz -C /usr/local/soft/
2、配置环境变量(三台虚拟机都需要i配置)
vim /etc/profile JAVA_HOME=/usr/local/soft/jdk1.8.0_171
HADOOP_HOME=/usr/local/soft/hadoop-2.7.6
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH # 重新加载环境变量
source /etc/profile 使用远程复制(进行覆盖)
cd /etc
scp -r profile/ node1:`pwd`
scp -r profile/ node2:`pwd`
3、修改Hadoop配置文件
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop/core-site.xml
fs.defaultFS: 默认文件系统的名称。其方案和权限决定文件系统实现的URI。uri的方案确定命名文件系统实现类的配置属性(fs.scheme.impl)。uri的权限用于确定文件系统的主机、端口等。
hadoop.tmp.dir:是 hadoop文件系统依赖的基本配置,很多配置路径都依赖它,它的默认位置是在 /tmp/{$user}下面,注意这是个临时目录!!!
因此,它的持久化配置很重要的! 如果选择默认,一旦因为断电等外在因素影响,/tmp/{$user}下的所有东西都会丢失。
fs.trash.interval:启用垃圾箱配置,dfs命令删除的文件不会立即从HDFS中删除。相反,HDFS将其移动到垃圾目录(每个用户在
/user/<username>/.Trash下都有自己的垃圾目录)。只要文件保留在垃圾箱中,文件可以快速恢复。<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/tmp</value>
</property> <property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>hadoop-env.sh
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
hdfs-site.xml
dfs.replication:每个datanode上只能存放一个副本。我这里就2个datanode
dfs.permissions:如果为“true”,则在HDFS中启用权限检查。如果为“false”,则关闭权限检查,但所有其他行为保持不变。从一个参数值切换到另一个参数值不会更改文件或目录的模式、所有者或组。
<property>
<name>dfs.replication</name>
<value>1</value>
</property> <property>
<name>dfs.permissions</name>
<value>false</value>
</property>mapred-site.xml.template
mapreduce.framework.name:用于执行MapReduce作业的运行时框架。
mapreduce.jobhistory.address:Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过*mr-jobhistory-daemon.sh start historyserver命令来启动Havim doop历史服务器。我们可以通过Hadoop jar的命令来实现我们的程序jar包的运行,关于运行的日志,我们一般都需要通过启动一个服务来进行查看,就是我们的JobHistoryServer,我们可以启动一个进程,专门用于查看我们的任务提交的日志。mapreduce.jobhistory.address和mapreduce.jobhistory.webapp.address默认的值分别是0.0.0.0:10020和0.0.0.0:19888
# 1、重命名文件
cp mapred-site.xml.template mapred-site.xml
# 2、修改
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> <property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property> <property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>slaves
从节点的信息
node1
node2yarn-site.xml
yarn.resourcemanager.hostname:指定yarn主节点
yarn.nodemanager.aux-services:NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序。默认值:“”
yarn.log-aggregation-enable:yarn日志聚合功能开关
yarn.log-aggregation.retain-seconds:日志保留时限,默认7天
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property> <property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
4、分发Hadoop到node1、node2
cd /usr/local/soft/
scp -r hadoop-2.7.6/ node1:`pwd`
scp -r hadoop-2.7.6/ node2:`pwd`
5、格式化namenode(第一次启动的时候需要执行,以及每次修改核心配置文件后都需要)
hdfs namenode -format
6、启动Hadoop集群
start-all.sh
7、检查master、node1、node2上的进程
master:
[root@master soft]# jps
2597 NameNode
2793 SecondaryNameNode
2953 ResourceManager
3215 Jpsnode1:
[root@node1 jdk1.8.0_171]# jps
11361 DataNode
11459 NodeManager
11559 Jpsnode2:
[root@node2 ~]# jps
11384 DataNode
11482 NodeManager
11582 Jps
8、访问HDFS的WEB界面
http://master:50070
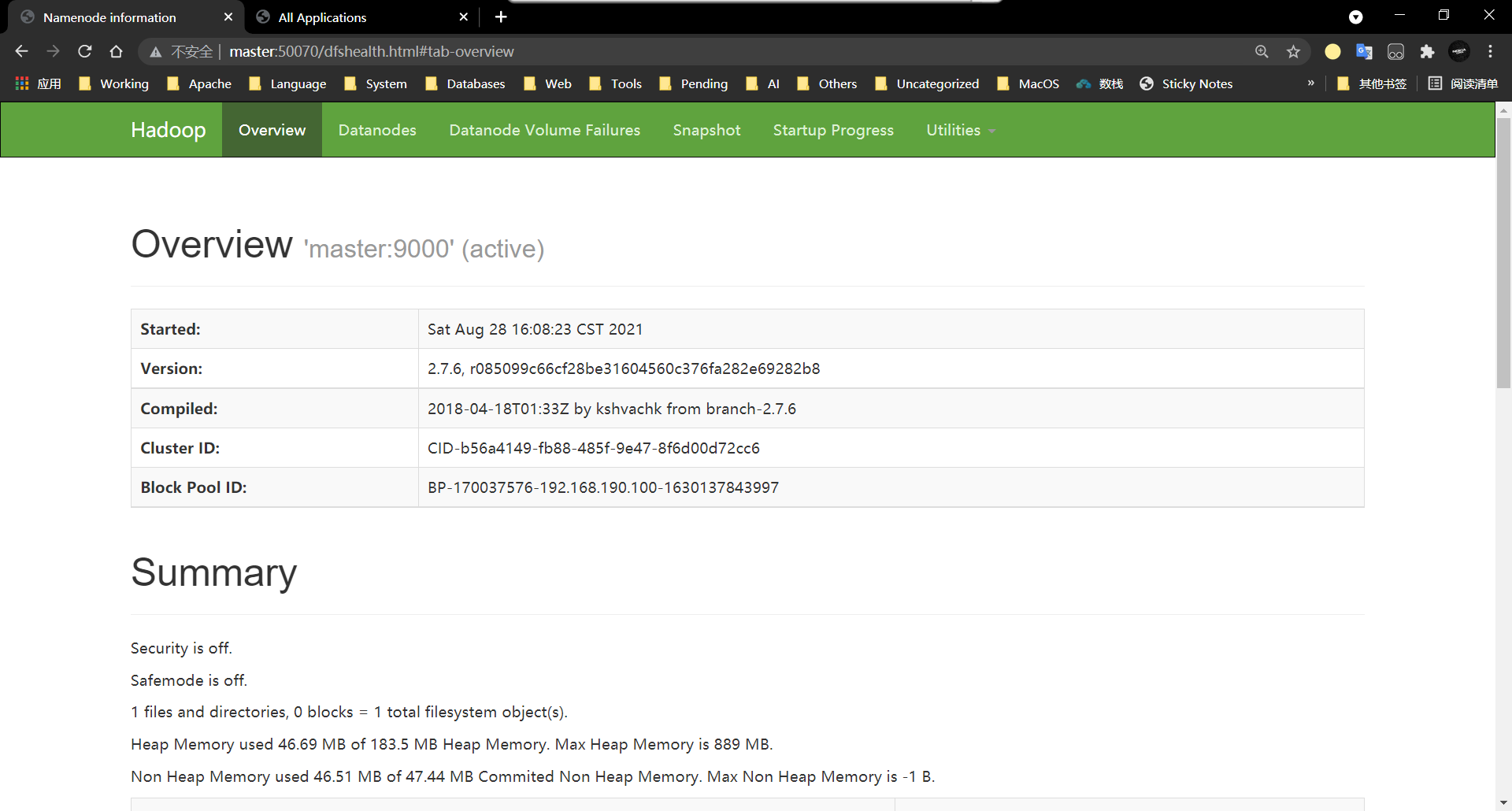
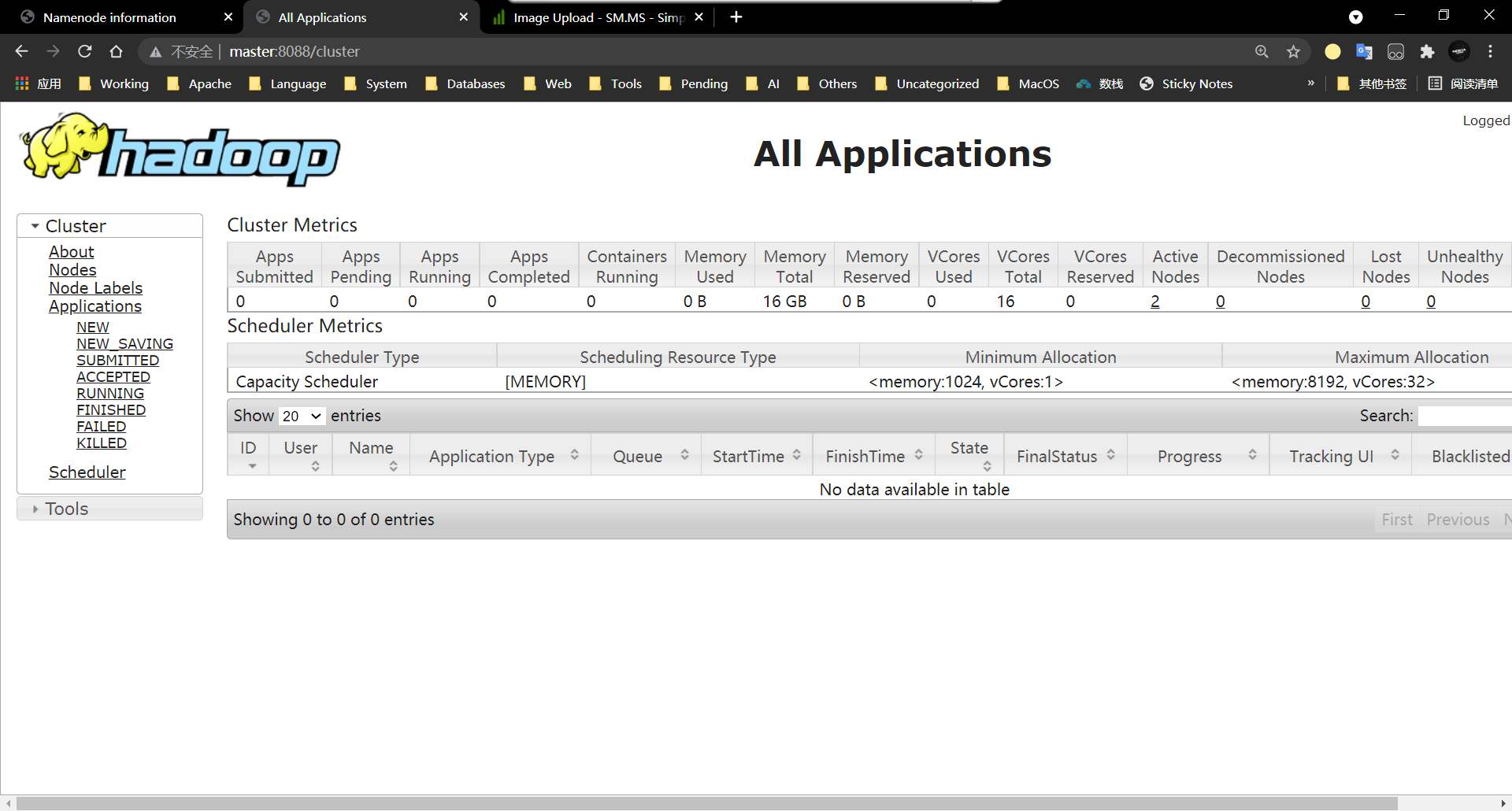
9、访问YARN的WEB界面
http://master:8088
Hadoop中的常见的shell命令 1、如何将linux本地的数据上传到HDFS中呢?
hadoop fs -put 本地的文件 HDFS中的目录
hdfs dfs -put 本地的文件 HDFS中的目录
cd /usr/local/soft
hadoop fs -put hadoop-2.7.6.tar.gz /
hadoop fs -put students.txt / 2、如何创建HDFS中的文件夹呢?
需求:想创建/shujia/bigdata17
hadoop fs -mkdir -p /shujia/bigdata17
hdfs dfs -mkdir -p /shujia/bigdata17 3、查看当前HDFS目录下的文件和文件夹
hadoop fs -ls /shujia/bigdata17
hdfs dfs -ls /shujia/bigdata17 举例
[root@master soft]# hadoop fs -ls /
Found 4 items
-rw-r--r-- 1 root supergroup 216745683 2022-05-21 19:23 /hadoop-2.7.6.tar.gz
-rw-r--r-- 1 root supergroup 1415 2022-05-21 19:31 /initdemo.sh
drwxr-xr-x - root supergroup 0 2022-05-21 19:33 /shujia
drwx------ - root supergroup 0 2022-05-21 19:26 /user 4、将HDFS的文件下载到Linux本地中
hadoop fs -get HDFS中的文件目录 本地要存放文件的目录
hdfs dfs -get HDFS中的文件目录 本地要存放文件的目录
hdfs dfs -get /students.txt /usr/local/soft/data/ 5、删除命令(如果垃圾回收站大小小于被删除文件的大小,直接被删除,不经过回收站)
hadoop fs -rm .... # 仅删除文件
hadoop fs -rmr .... # 删除文件夹
举例:
[root@master soft]# hadoop fs -rmr /students.txt
rmr: DEPRECATED: Please use 'rm -r' instead.
22/05/21 19:37:00 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 1440 minutes, Emptier interval = 0 minutes.
22/05/21 19:37:00 INFO fs.TrashPolicyDefault: Moved: 'hdfs://master:9000/students.txt' to trash at: hdfs://master:9000/user/root/.Trash/Current/students.txt
Moved: 'hdfs://master:9000/students.txt' to trash at: hdfs://master:9000/user/root/.Trash/Current 6、移动文件
hadoop fs -mv 目标文件 目的地路径
hadoop fs -mv /user/root/.Trash/Current/students.txt /
7、HDFS内部复制文件
hadoop fs -cp [-p] ... ... # 如果想复制文件夹,加上-p参数
hadoop fs -cp -p /hadoop-2.7.6.tar.gz /shujia/bigdata/
强制格式化集群(遇到问题的简单暴力的方法)
1、停止正在运行的集群
stop-all.sh
2、删除所有节点hadoop根目录中的tmp文件夹
3、在主节点(master)中hadoop的根目录中的bin目录下,重新格式化HDFS
./hdfs namenode -format
4、启动集群
start-all.sh
2.2 进程理解
2.1.1 HDFS相关(NN,DN,SSN)
NameNode(NN)
功能:
1、接受客户端的读/写服务
因为NameNode知道文件与DataNode的对应关系
2、保存文件的时候会保存文件的元数据信息
a. 文件的归属
b. 文件的权限
c. 文件的大小,时间
d. Block信息,但是block的位置信息不会持久化,需要每次开启集群的时候DN向NN汇报。(带同学们画图讲解,引出这4个点)
3、收集Block的位置信息
3.1 系统启动
a. NN关机的时候是不会存储任意的Block与DataNode的映射信息的
b. DN启动的时候会自动将自己节点上存储的Block信息汇报给NN
c. NN接收请求之后会重新生成映射关系
File ----> Block
Block---> DN
d. 如果数据块的副本数小于设置数,那么NN会将这个副本拷贝到其他节点
3.2 集群运行中
a. NN与DN保持心跳机制,三秒钟发送一次
b. 如果客户端需要读取或者上传数据的时候,NN可以知道DN的健康情况
c. 可以让客户端读取存活的DN节点
d. 如果NN与DN三秒没有心跳则认为DN出现异常,此时不会让新的数据写到这个异常的DN中,客户端访问的时候不提供异常DN节点地址
e. 如果超过十分钟没有心跳,那么NN会将当前DN节点存储的数据转移到其他的节点
4、NameNode为了效率,将所有的操作都在内存中进行
a. 执行速度快
b. NameNode不会和磁盘进行任何的数据交换
但是会存在两个问题:
1)数据的持久化
2)数据保存在内存中,断电丢失
DataNode(DN)
1、存放的是文件的数据信息,以及验证文件完整性的校验信息
2、数据会存放在硬盘上
a. 1m=1条元数据
b. 1G=1条元数据
c. NameNode非常排斥存储小文件(能存,但是不推荐!!)
一般小文件在存储之前需要进行压缩
3、汇报
1)启动时
汇报之前会验证Block文件是否被损坏
向NN汇报当前DN上block的信息
2)运行中
向NN保持心跳机制
4、当客户端读写数据的时候,首先会先去NN查询file与block与DN的映射,然后直接与DN建立连接,然后读写数据
SecondaryNameNode(SNN)
1、传统的那日村持久化方案
1)日志机制
a. 做任何操作之前先记录日志
b. 在数据改变之前先记录对应的日志,当NN停止的时候
c. 当我下次启动的时候,只需要重新按照以前的日志“重做一遍”即可
缺点:
a. log日志文件的大小不可控,随着时间的发展,集群启动的时间会越来越长
b. 有可能日志中存在大量的无效日志
优点:
a. 绝对不会丢失数据
2)拍摄快照
a. 我们可以将内存中的数据写出到硬盘上(序列化)
b. 启动时还可以将硬盘上的数据写回到内存中(反序列化)
缺点:
a. 关机时间过长
b. 如果是异常关机,数据还在内存中,没法写入到硬盘
c. 如果写出的频率过高,导致内存使用效率低
优点:
启动时间较短
2、SNN的解决方案
1)解决思路
a. 让日志大小可控
b. 快照需要定时保存
c. 日志+快照
2)解决方案
a. 当我们启动一个集群的时候,会产生4个文件 ..../name/current/
b. 我们每次操作都会记录日志
Hadoop集群搭建(完全分布式版本) VMWARE虚拟机的更多相关文章
- Hadoop集群搭建的详细过程
Hadoop集群搭建 一.准备 三台虚拟机:master01,node1,node2 时间同步 1.date命令查看三台虚拟机时间是否一致 2.不一致时间同步:ntpdate ntp.aliyun.c ...
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- Hadoop(二) HADOOP集群搭建
一.HADOOP集群搭建 1.集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 Na ...
- 大数据初级笔记二:Hadoop入门之Hadoop集群搭建
Hadoop集群搭建 把环境全部准备好,包括编程环境. JDK安装 版本要求: 强烈建议使用64位的JDK版本,这样的优势在于JVM的能够访问到的最大内存就不受限制,基于后期可能会学习到Spark技术 ...
- 环境搭建-Hadoop集群搭建
环境搭建-Hadoop集群搭建 写在前面,前面我们快速搭建好了centos的集群环境,接下来,我们就来开始hadoop的集群的搭建工作 实验环境 Hadoop版本:CDH 5.7.0 这里,我想说一下 ...
- Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!) 一.JDK的安装 安装位置都在同一位置(/usr/tools/jdk1.8.0_73) jdk的安装在克隆三台机器的时候可以提前安装 ...
- Linux环境下Hadoop集群搭建
Linux环境下Hadoop集群搭建 前言: 最近来到了武汉大学,在这里开始了我的研究生生涯.昨天通过学长们的耐心培训,了解了Hadoop,Hdfs,Hive,Hbase,MangoDB等等相关的知识 ...
- 1.Hadoop集群搭建之Linux主机环境准备
Hadoop集群搭建之Linux主机环境 创建虚拟机包含1个主节点master,2个从节点slave1,slave2 虚拟机网络连接模式为host-only(非虚拟机环境可跳过) 集群规划如下表: 主 ...
- Hadoop集群搭建-04安装配置HDFS
Hadoop集群搭建-05安装配置YARN Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hado ...
随机推荐
- 干货 | Keepalived高可用服务配置实例
一个执着于技术的公众号 Keepalived系列导读 Keepalived入门学习 keepalived安装及配置文件详解 前言 在前面的章节中,我们学习了Keepalived简介.原理.以及Keep ...
- 数据管理技术发展,数据库应用发展史,数据库分类,MySQL
计算机数据管理技术发展 1. 自由管理阶段 用户以文件形式将数据组织起来,并附属在各自的应用程序下. 1.数据不保存 当时计算机主要用于科学计算,一般不需要将数据长期保存,只是计算某一课 ...
- [C++STL] vector 容器的入门
vector容器的入门 #include<vector> 创建vector容器的几种方式 数据类型可以是结构体,也能是另外一个容器 vector 的初始化: (1) 创建并声明大小 vec ...
- 基础篇:java GC 总结,建议收藏
垃圾标记算法 垃圾回收算法 major gc.mini gc.full gc.mixed gc 又是什么,怎么触发的 垃圾回收器的介绍 Safe Point 和 Safe Region 什么是 TLA ...
- 一文带你看懂Java中的Lock锁底层AQS到底是如何实现的
前言 相信大家对Java中的Lock锁应该不会陌生,比如ReentrantLock,锁主要是用来解决解决多线程运行访问共享资源时的线程安全问题.那你是不是很好奇,这些Lock锁api是如何实现的呢?本 ...
- Microsoft Office 代码执行漏洞临时防范方法
一.删除ms-msdt URI 注册表 1.按下键盘上的快捷组合键:win键 和 R键,打开运行(也可以在开始菜单打开运行). 2.在运行窗口中输入命令:regedit,点击确定或敲回车键就可以快速打 ...
- cloudwu/coroutine 源码分析
1 与其它协程库使用对比 这个 C 协程库是云风(cloudwu) 写的,其接口风格与 Lua 协程类似,并且都是非对称 stackful 协程.这个是源代码中的示例: #include " ...
- JavaScript中的??和?.和??=操作符
JS中两种不常使用但挺实用的操作符:??和?. 一起来了解并学会使用它们吧: 空值合并操作符:?? 只有当操作符左侧为null或undefined时才会返回操作符右侧的值,否则返回左侧的值. eg: ...
- windiws下安装Composer
1.先下载Composer-Setup.exe,下载地址:下载Composer .会自动搜索php.exe的安装路径,如果没有,就手动找到php路径下的php.exe. 2.在PHP目录下,打开php ...
- make 随笔
# --with--cc-opt flag导致./configure时找不到对应库文件? checking for --with-ld-opt="-Wl,-z,relro -Wl,-z,no ...