3.7:基于Weka的K-means聚类的算法示例
〇、目标
1、使用Weka平台,并在该平台使用数据导入、可视化等基本操作;
2、对K-means算法的不同初始k值进行比较,对比结果得出结论。
一、打开Weka3.8并导入数据
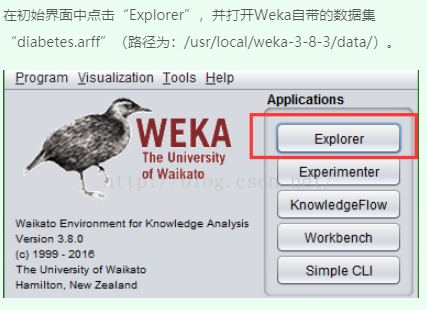
二、导入数据
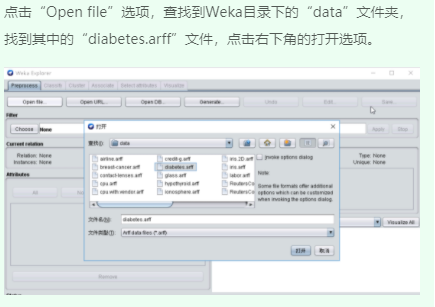
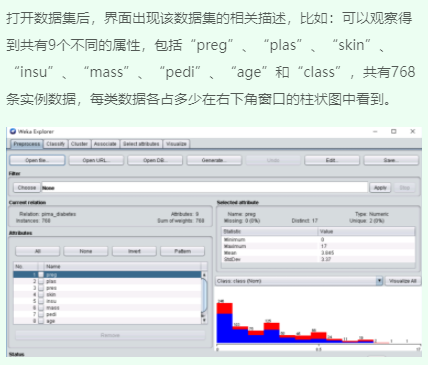
三、SimpleKMeans算法聚类
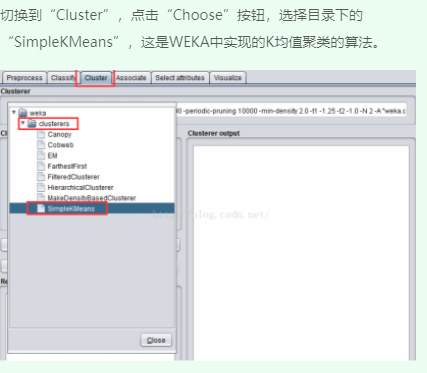
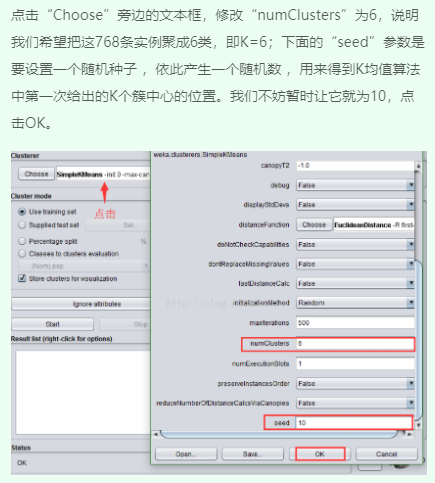
四、运行观察结果
1、观察聚类输出结果
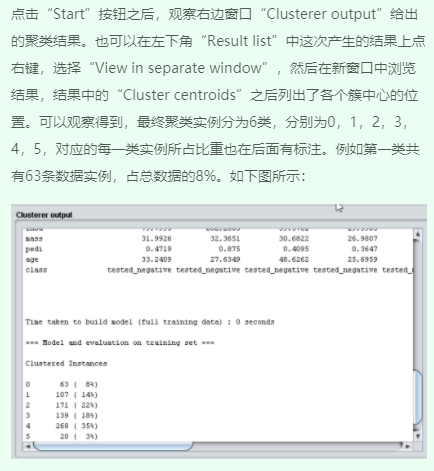
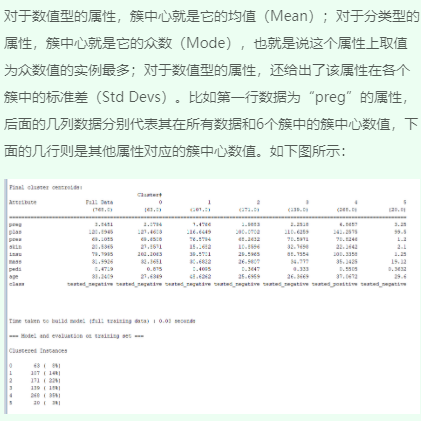
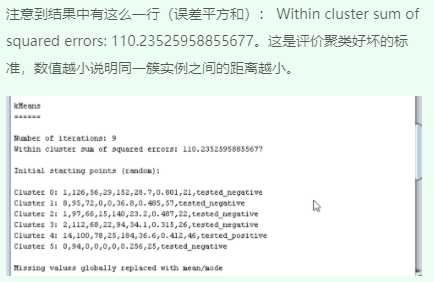
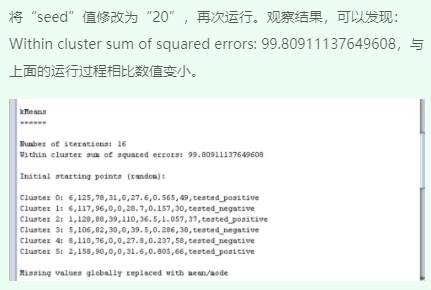
2、修改参数值重新运行并观察结果

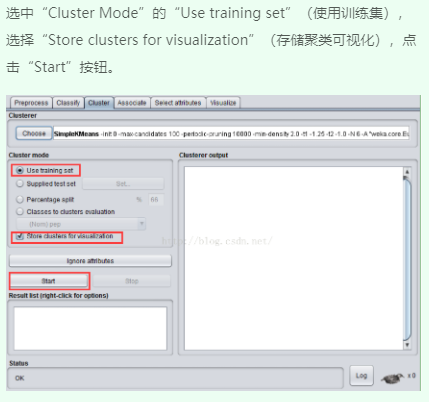
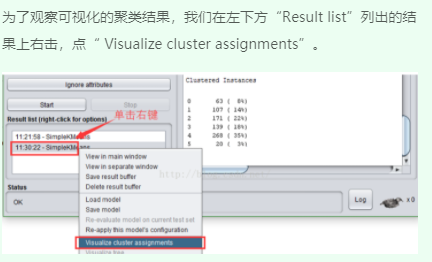
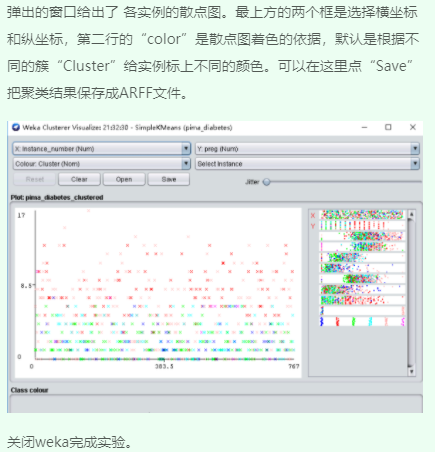
3、可视化聚类结果
3.7:基于Weka的K-means聚类的算法示例的更多相关文章
- R与数据分析旧笔记(十五) 基于有代表性的点的技术:K中心聚类法
基于有代表性的点的技术:K中心聚类法 基于有代表性的点的技术:K中心聚类法 算法步骤 随机选择k个点作为"中心点" 计算剩余的点到这个k中心点的距离,每个点被分配到最近的中心点组成 ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
- 5-Spark高级数据分析-第五章 基于K均值聚类的网络流量异常检测
据我们所知,有‘已知的已知’,有些事,我们知道我们知道:我们也知道,有 ‘已知的未知’,也就是说,有些事,我们现在知道我们不知道.但是,同样存在‘不知的不知’——有些事,我们不知道我们不知道. 上一章 ...
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- 【转】算法杂货铺——k均值聚类(K-means)
k均值聚类(K-means) 4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是很多时 ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- SciPy k均值聚类
章节 SciPy 介绍 SciPy 安装 SciPy 基础功能 SciPy 特殊函数 SciPy k均值聚类 SciPy 常量 SciPy fftpack(傅里叶变换) SciPy 积分 SciPy ...
- Sklearn K均值聚类
## 版权所有,转帖注明出处 章节 SciKit-Learn 加载数据集 SciKit-Learn 数据集基本信息 SciKit-Learn 使用matplotlib可视化数据 SciKit-Lear ...
- Python实现kMeans(k均值聚类)
Python实现kMeans(k均值聚类) 运行环境 Pyhton3 numpy(科学计算包) matplotlib(画图所需,不画图可不必) 计算过程 st=>start: 开始 e=> ...
随机推荐
- CVE-2022-39197(CobaltStrike XSS <=4.7)漏洞复现
最新文章更新见个人博客 漏洞说明 根据9.20日CobaltStrike官方发布的最新4.7.1版本的更新日志中介绍,<=4.7的teamserver版本存在XSS漏洞,从而可以造成RCE远程代 ...
- Elasticsearch:Cluster备份 Snapshot及Restore API
Elasticsearch提供了replica解决方案,它可以帮我们解决了如果有一个或多个node失败了,那么我们的数据还是可以保证完整的情况,并且搜索还可以继续进行.但是,有一种情况是我们的所有的n ...
- 使用yum方式安装的openresty参数
nginx version: openresty/1.19.3.1 built by gcc 8.3.1 20190311 (Red Hat 8.3.1-3) (GCC) built with Ope ...
- Fluentd部署:如何监控Fluentd
监控的目的是确保日志采集能稳定高效运行. Fluentd内部运行指标 Fluentd内部保存着一些运行指标,这些指标可通过REST api直接获取,也支持通过第三方工具,如Prometheus,来访问 ...
- PAT (Basic Level) Practice 1019 数字黑洞 分数 20
给定任一个各位数字不完全相同的 4 位正整数,如果我们先把 4 个数字按非递增排序,再按非递减排序,然后用第 1 个数字减第 2 个数字,将得到一个新的数字.一直重复这样做,我们很快会停在有" ...
- P7476 苦涩 题解
Link 一道很好的复杂度均摊题目. 只需要考虑删除操作时的时间复杂度.保证复杂度的重点之一是精确定位到所有包含最大值的区间,即不去碰多余的区间.每次删除操作会删除若干个整个区间,以及至多两个区间被删 ...
- sql内连查询
select <查询的列名> from <表名> inner join `<连接的表名称>` on <第一张表的主键> = <第二张表的外键> ...
- <三>从编译器角度理解C++代码编译和链接原理
1代码 点击查看代码 **sum.cpp** int gdata=10; int sum(int a,int b){ return a+b; } **main.cpp** extern int gda ...
- Kafka 之 Streams
Kafka 之 Streams 一.概述 1.1 Kafka Streams Kafka Streams.Apache Kafka开源项目的一个组成部分.是一个功能强大,易于使用的库.用于在Kafka ...
- 深入剖析Sgementation fault原理
深入剖析Sgementation fault原理 前言 我们在日常的编程当中,我们很容易遇到的一个程序崩溃的错误就是segmentation fault,在本篇文章当中将主要分析段错误发生的原因! S ...