【实时数仓】Day00:数据流程、课程内容、框架结构、知识点总结
一、数据流程
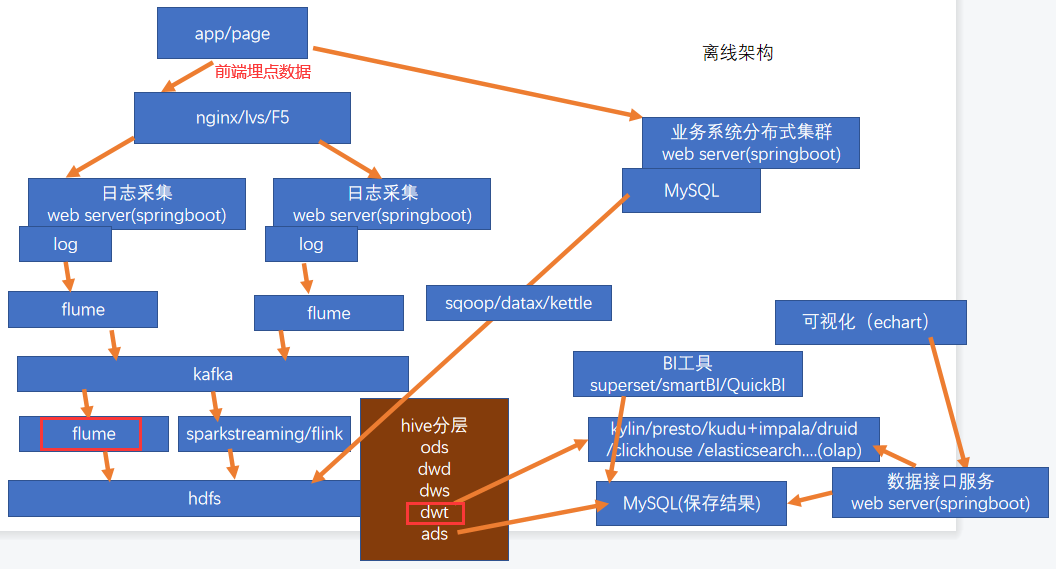
1、离线数仓

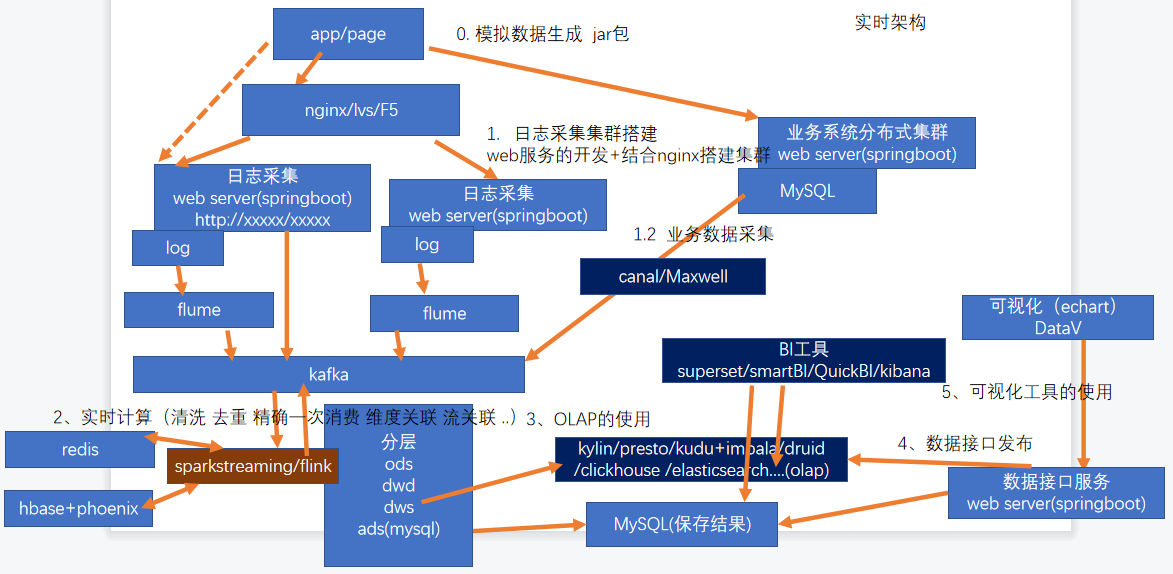
2、实时数仓
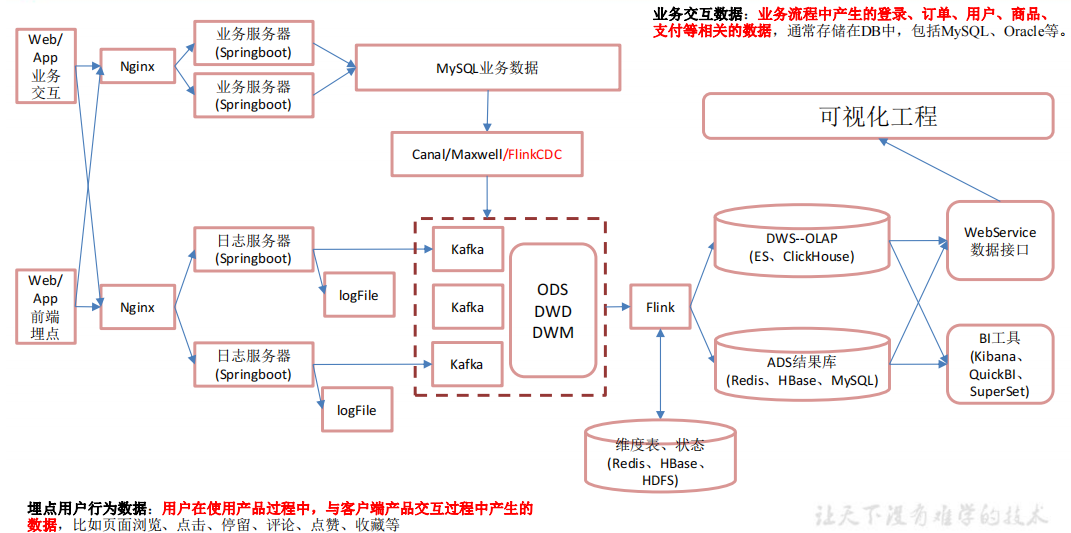
二、课程内容
1、数据采集层(ODS)
2、DWD层与DIM层数据准备
3、DWM层业务实现
4、DWS层业务实现
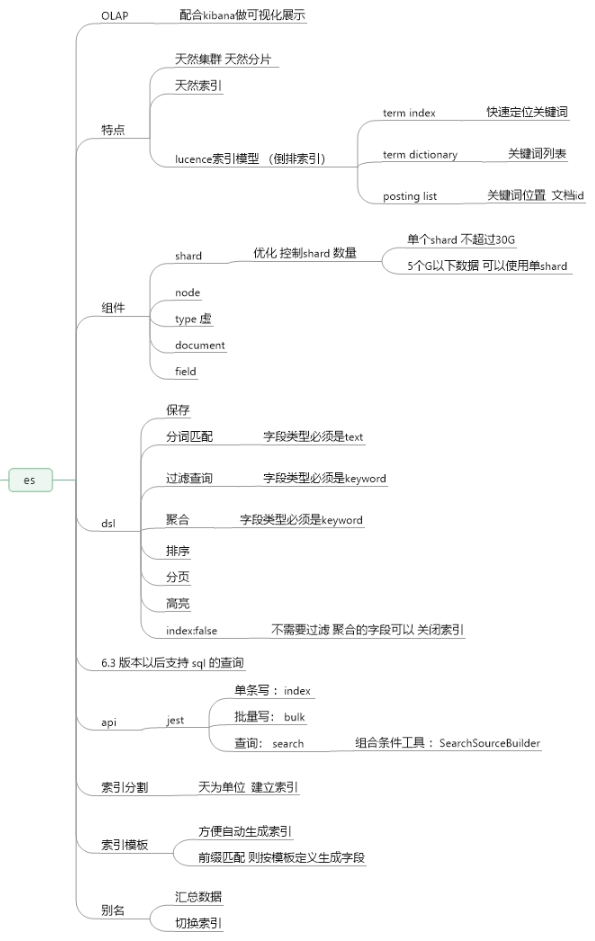
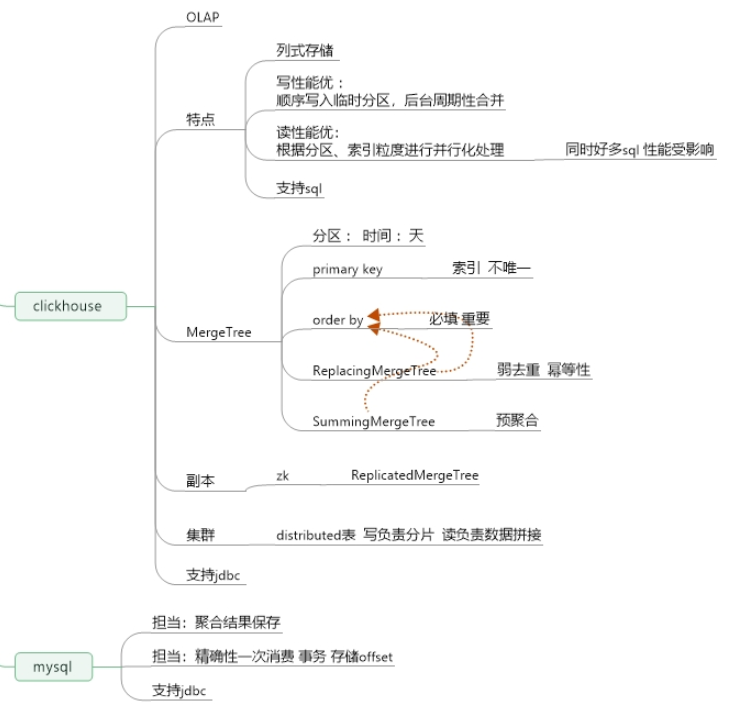
5、ClickHouse
6、数据可视化接口实现
7、数仓优化
8、FlinkCDC
三、框架结构
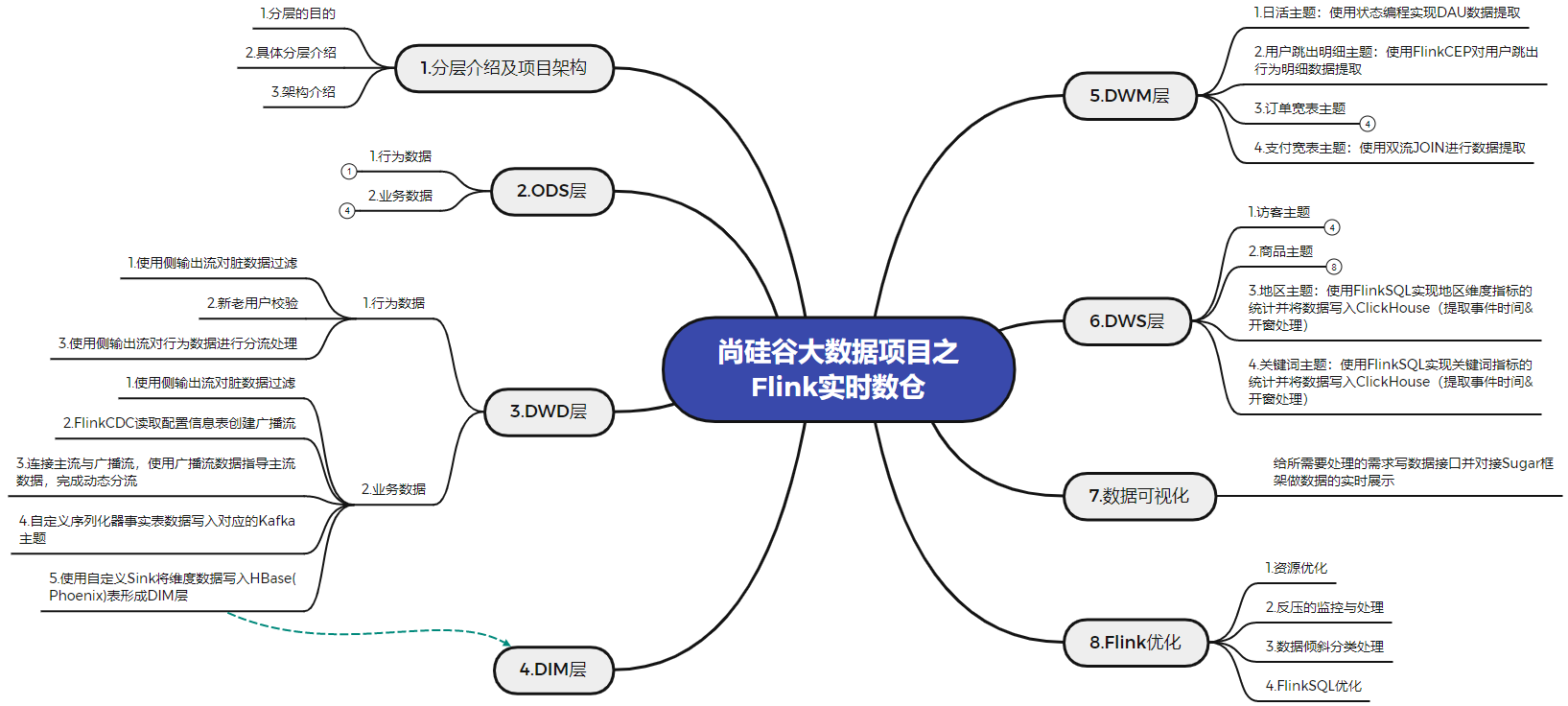
四、知识点总结
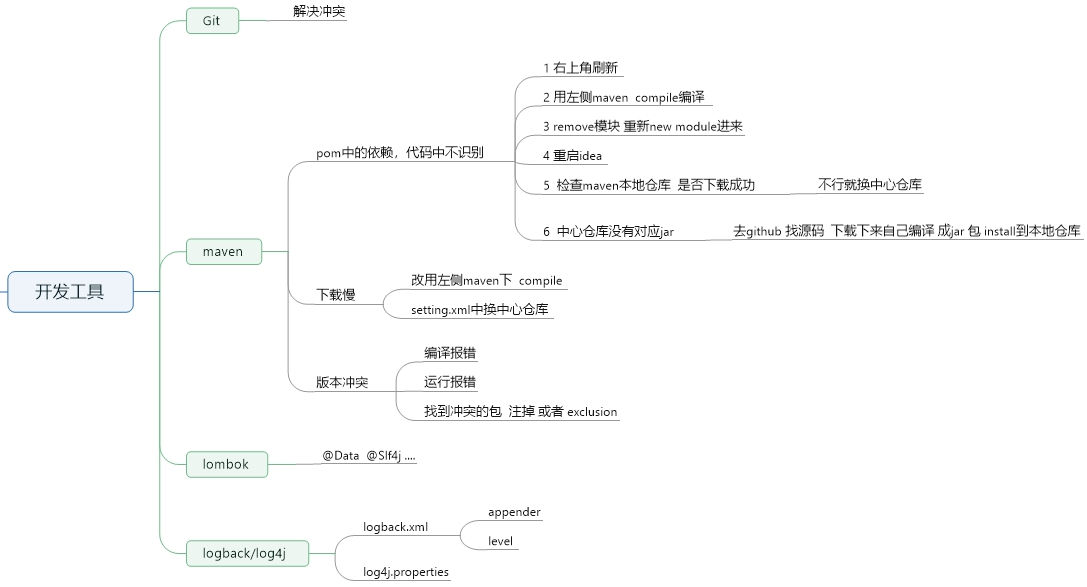
1、开发工具
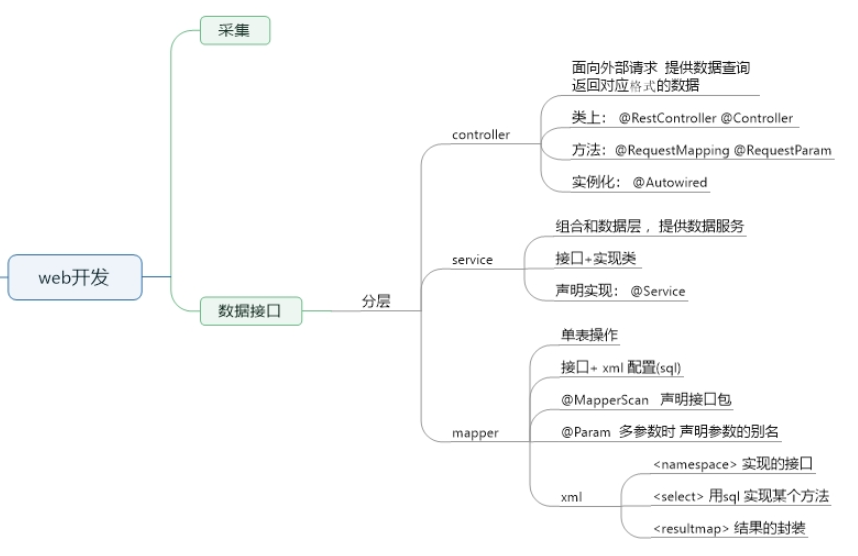
2、web开发
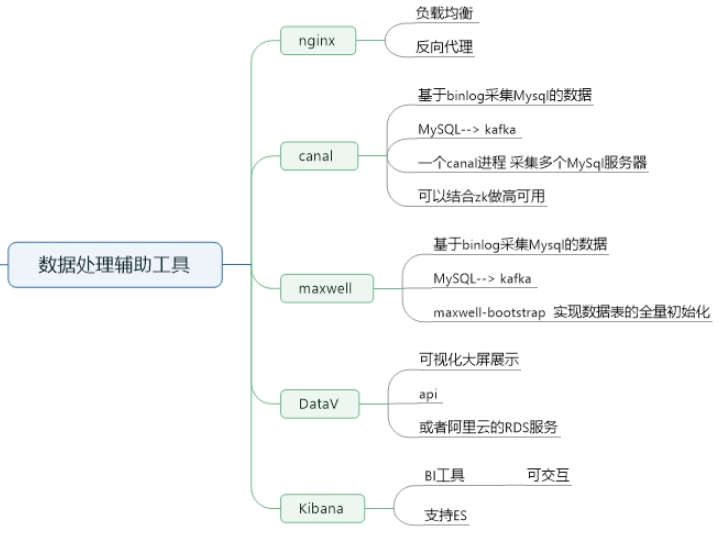
3、数据处理辅助工具
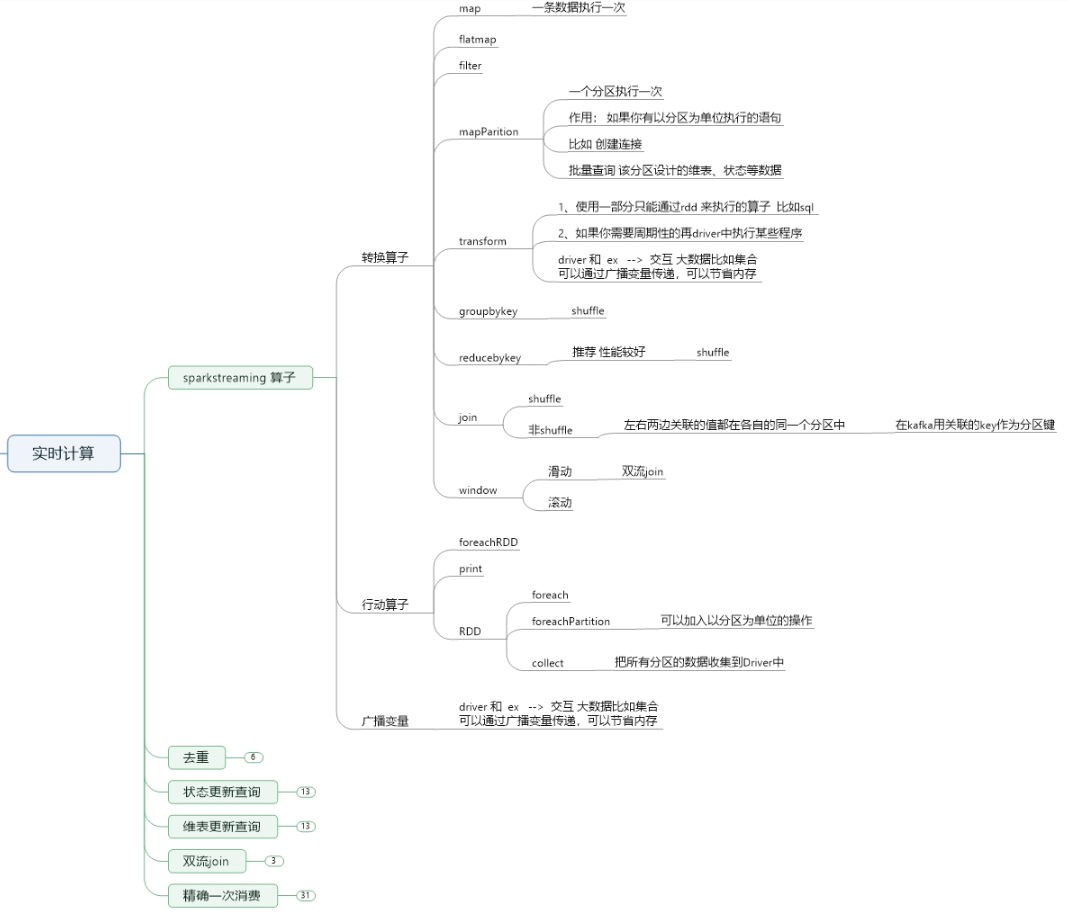
4、实时计算
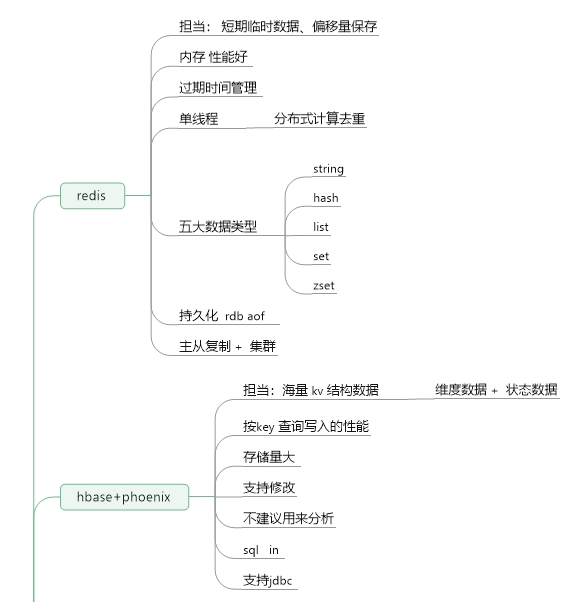
5、数据容器
【实时数仓】Day00:数据流程、课程内容、框架结构、知识点总结的更多相关文章
- 美团点评基于 Flink 的实时数仓建设实践
https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651749037&idx=1&sn=4a448647b3dae5 ...
- 大数据之Hudi + Kylin的准实时数仓实现
问题导读:1.数据库.数据仓库如何理解?2.数据湖有什么用途?解决什么问题?3.数据仓库的加载链路如何实现?4.Hudi新一代数据湖项目有什么优势? 在近期的 Apache Kylin × Apach ...
- HBase实战 | 知乎实时数仓架构演进
https://mp.weixin.qq.com/s/hx-q13QteNvtXRpNsE5Y0A 作者 | 知乎数据工程团队编辑 | VincentAI 前线导读:“数据智能” (Data Inte ...
- (转)用Flink取代Spark Streaming!知乎实时数仓架构演进
转:https://mp.weixin.qq.com/s/e8lsGyl8oVtfg6HhXyIe4A AI 前线导读:“数据智能” (Data Intelligence) 有一个必须且基础的环节,就 ...
- flink实时数仓从入门到实战
第一章.flink实时数仓入门 一.依赖 <!--Licensed to the Apache Software Foundation (ASF) under oneor more contri ...
- 基于 Kafka 的实时数仓在搜索的实践应用
一.概述 Apache Kafka 发展至今,已经是一个很成熟的消息队列组件了,也是大数据生态圈中不可或缺的一员.Apache Kafka 社区非常的活跃,通过社区成员不断的贡献代码和迭代项目,使得 ...
- 基于 Flink 的实时数仓生产实践
数据仓库的建设是“数据智能”必不可少的一环,也是大规模数据应用中必然面临的挑战.在智能商业中,数据的结果代表了用户反馈.获取数据的及时性尤为重要.快速获取数据反馈能够帮助公司更快地做出决策,更好地进行 ...
- 更强大的实时数仓构建能力!分析型数据库PostgreSQL 6.0新特性解读
阿里云 AnalyticDB for PostgreSQL 为采用MPP架构的分布式集群数据库,完备支持SQL 2003,部分兼容Oracle语法,支持PL/SQL存储过程,触发器,支持标准数据库事务 ...
- 基于Flink构建全场景实时数仓
目录: 一. 实时计算初期 二. 实时数仓建设 三. Lambda架构的实时数仓 四. Kappa架构的实时数仓 五. 流批结合的实时数仓 实时计算初期 虽然实时计算在最近几年才火起来,但是在早期也有 ...
- 实时数仓(二):DWD层-数据处理
目录 实时数仓(二):DWD层-数据处理 1.数据源 2.用户行为日志 2.1开发环境搭建 1)包结构 2)pom.xml 3)MykafkaUtil.java 4)log4j.properties ...
随机推荐
- 2.Ceph 基础篇 - 集群部署及故障排查
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI1MDgwNzQ1MQ==&mid=2247485243&idx=1&sn=e425c31a ...
- Elasticsearch:Index生命周期管理入门
如果您要处理时间序列数据,则不想将所有内容连续转储到单个索引中. 取而代之的是,您可以定期将数据滚动到新索引,以防止数据过大而又缓慢又昂贵. 随着索引的老化和查询频率的降低,您可能会将其转移到价格较低 ...
- MySQL 数据更新过程
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI1MDgwNzQ1MQ==&mid=2247486441&idx=1&sn=fcf93709 ...
- 《深入理解Elasticsearch》读书笔记 ---重点概念汇总
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247483918&idx=1&sn=a9f2ad3 ...
- jmeter录制登录脚本
1.添加代理服务器 在非测试元件添加http代理服务器,端口写8888,域写127.0.0.1 在排除模式里填入.*.(js|css|PNG|jpg|ico|png|gif|woff|ttf).* 2 ...
- 云数据库技术|“重磅升级”后再测 TDSQL-C
来源:云数据库技术 标题 1.摘要 前段时间,测试了国内主要云原生数据库 PolarDB.TDSQL-C.GaussDB 的性能,参考:<再测云原生数据库性能>.在上次测试结果中,由于地域 ...
- Kafka之配置信息
Kafka之配置信息 一.Broker配置信息 属性 默认值 描述 broker.id 必填参数,broker的唯一标识 log.dirs /tmp/kafka-logs Kafka数据存放的目录 ...
- Vue3 SFC 和 TSX 方式自定义组件实现 v-model
1 v-model 1.1 理解 v-model v-model 是 vue3 中的一个内置指令,很多表单元素都可以使用这个属性,如 input.checkbox 等,咱可以在自定义组件中实现 v-m ...
- AngouriMath: 用于C#和F#的开源跨平台符号代数库
AngouriMath是一个MIT协议开源符号代数库.也就是说,通过AngouriMath,您可以自动求解方程.方程组.微分.从字符串解析.编译表达式.处理矩阵.查找极限.将表达式转换为LaTeX,以 ...
- Java Timer使用介绍
java.util包下提供了对定时任务的支持,涉及2个类: Timer:定时器类 TimerTask:任务抽象类 使用该定时任务我们需要继承TimerTask抽象类,覆盖run方法编写任务执行代码,并 ...