SpringBoot 2.X 快速掌握
0、重写博文的原因
- 当初我的SpringBoot系列的知识是采用分节来写的,即:每一个知识点为一篇博文,但是:最近我霉到家了,我发现有些博文神奇般地打不开了,害我去找当初的markdown笔记,但是方便的话还是在线版舒服,只要有网就可以访问,因此昨天晚上东拼西凑搞出了这篇SpringBoot基础系列知识
1、什么是springboot?
1.1、老规矩:百度百科一下
2、对springboot快速上手
2.1、通过官网来创建 - 了解
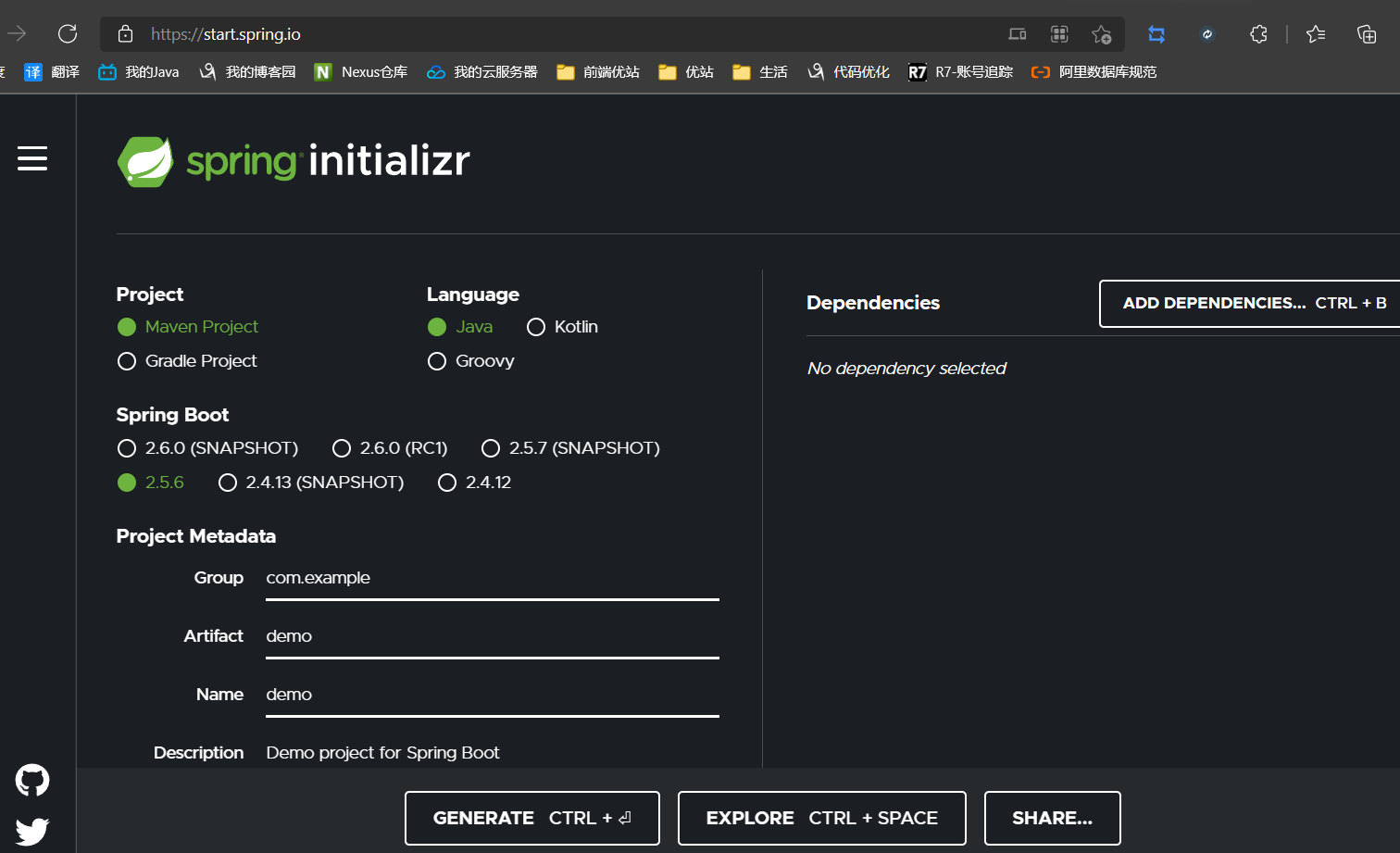
这里面的创建方式不做过多说明,只需要在官网里面创建好了,然后下载解压,就可以了,我这里直接使用编辑器创建
springboot搭建项目官网
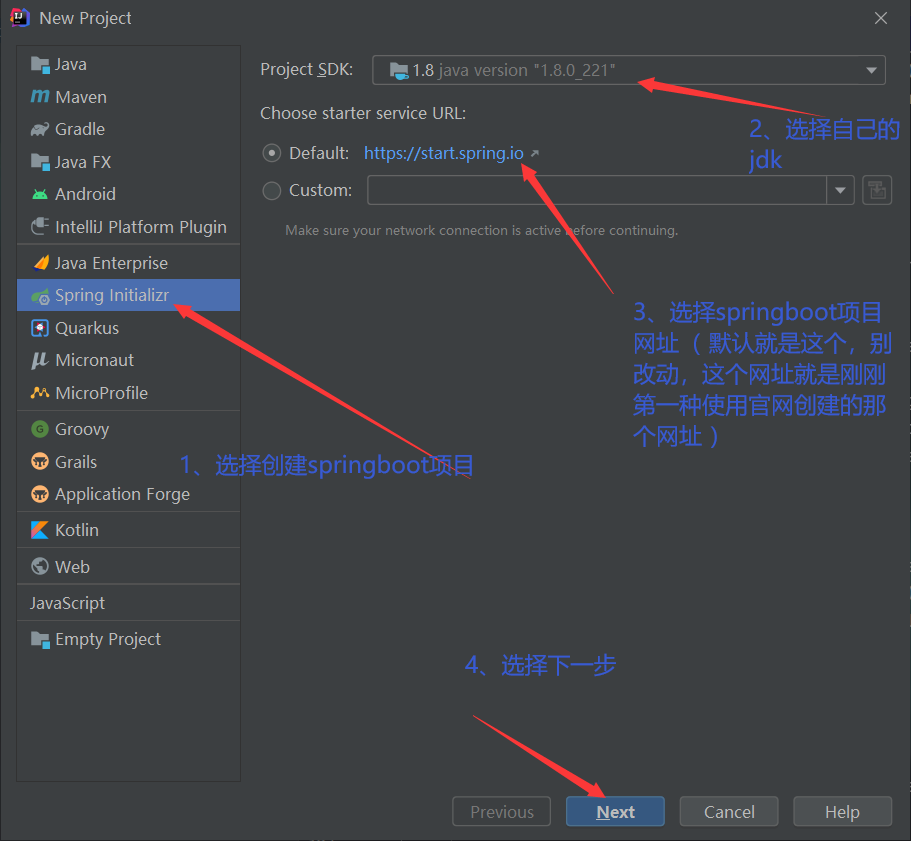
2.2、使用IDEA编辑器创建
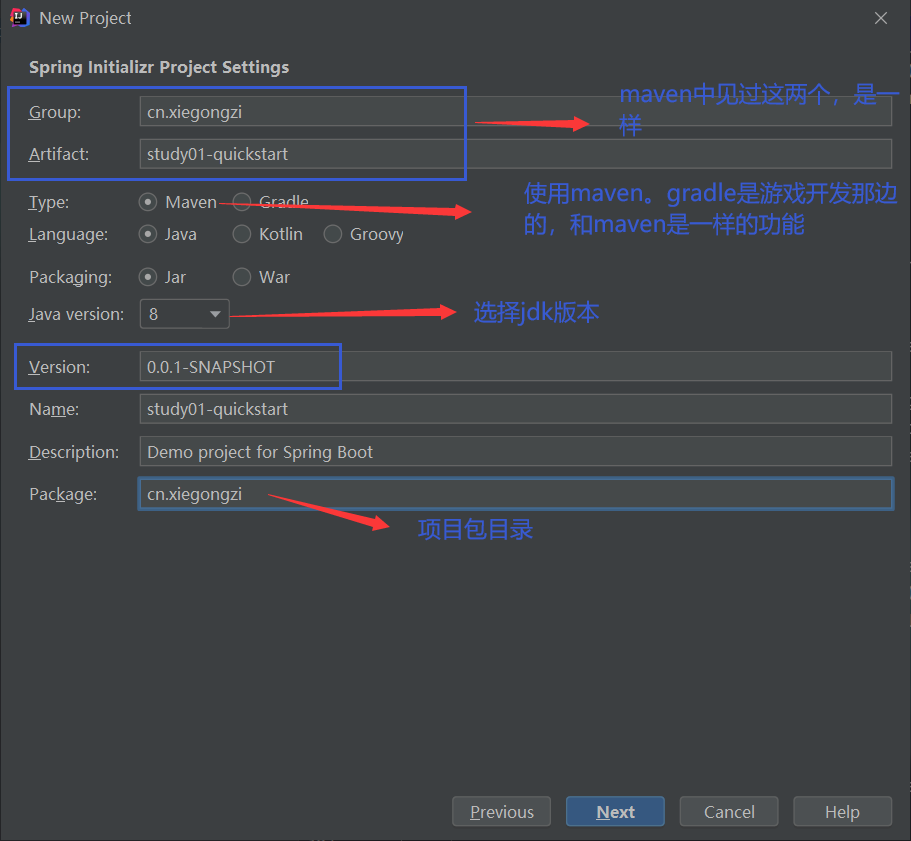

选完之后,idea就会去拉取相应的jar包,创建结果如下:
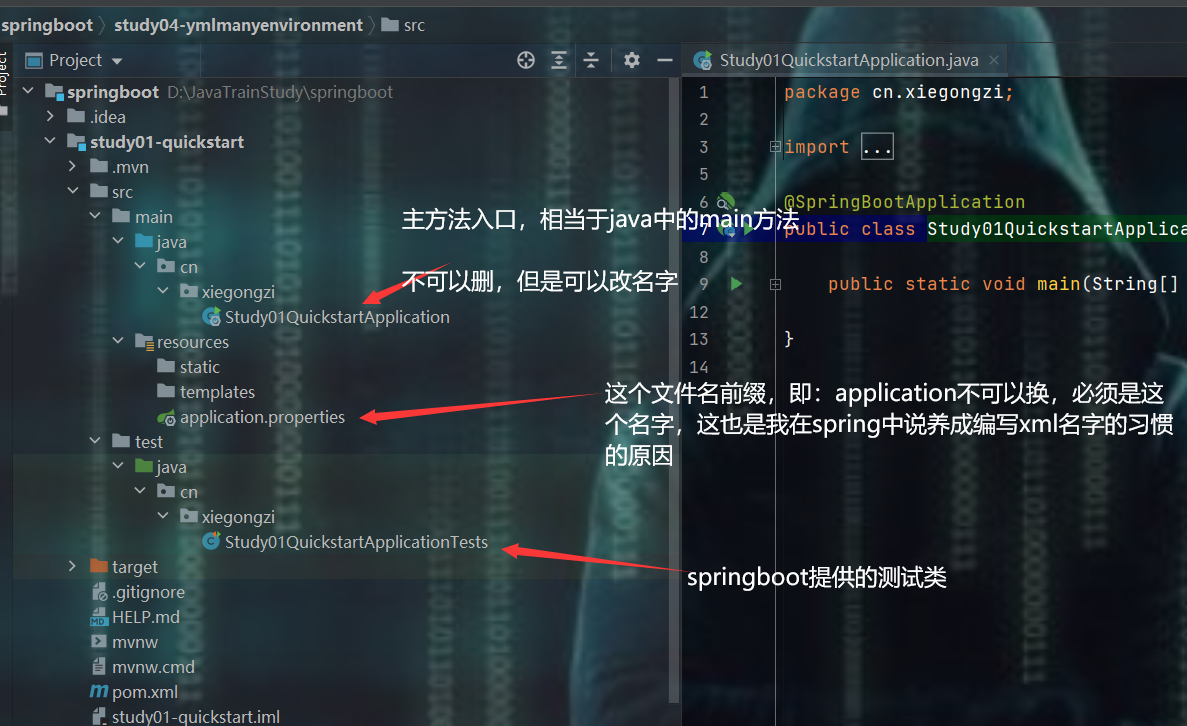
启动项目
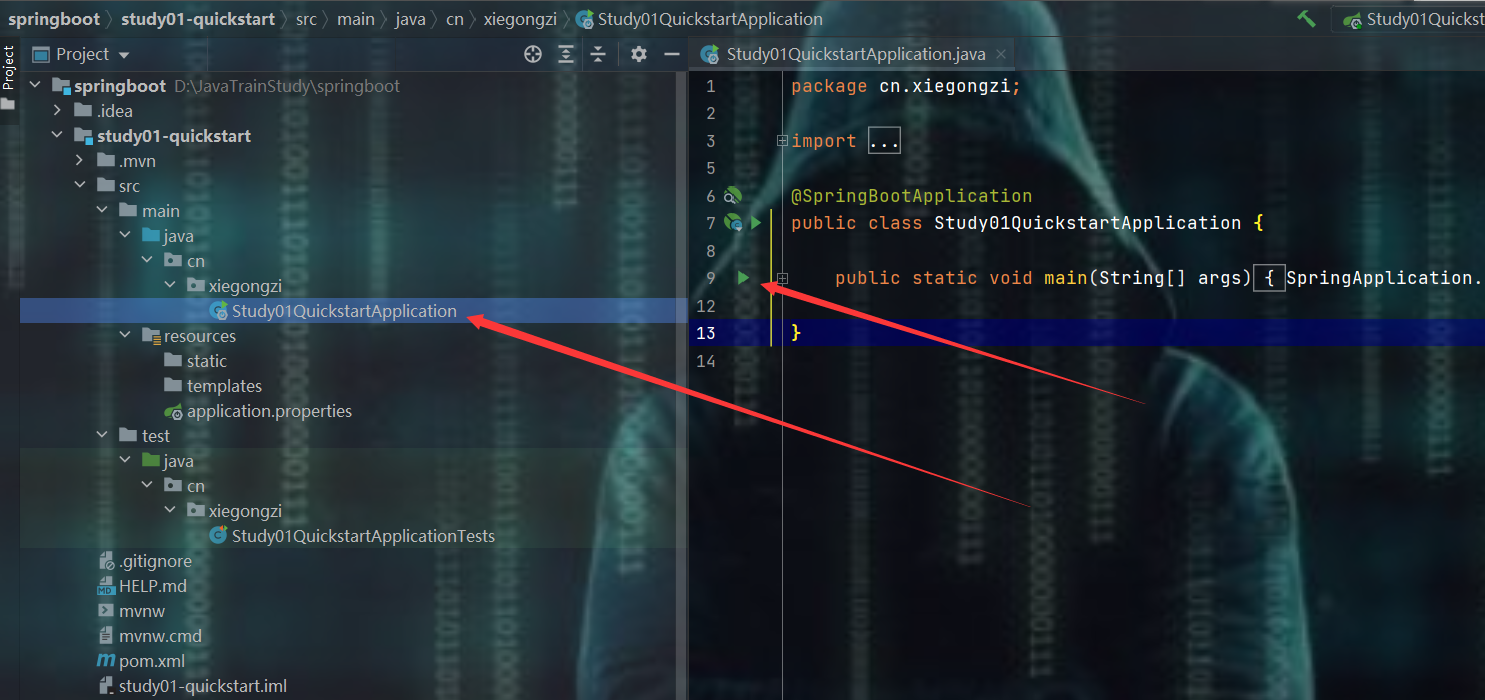
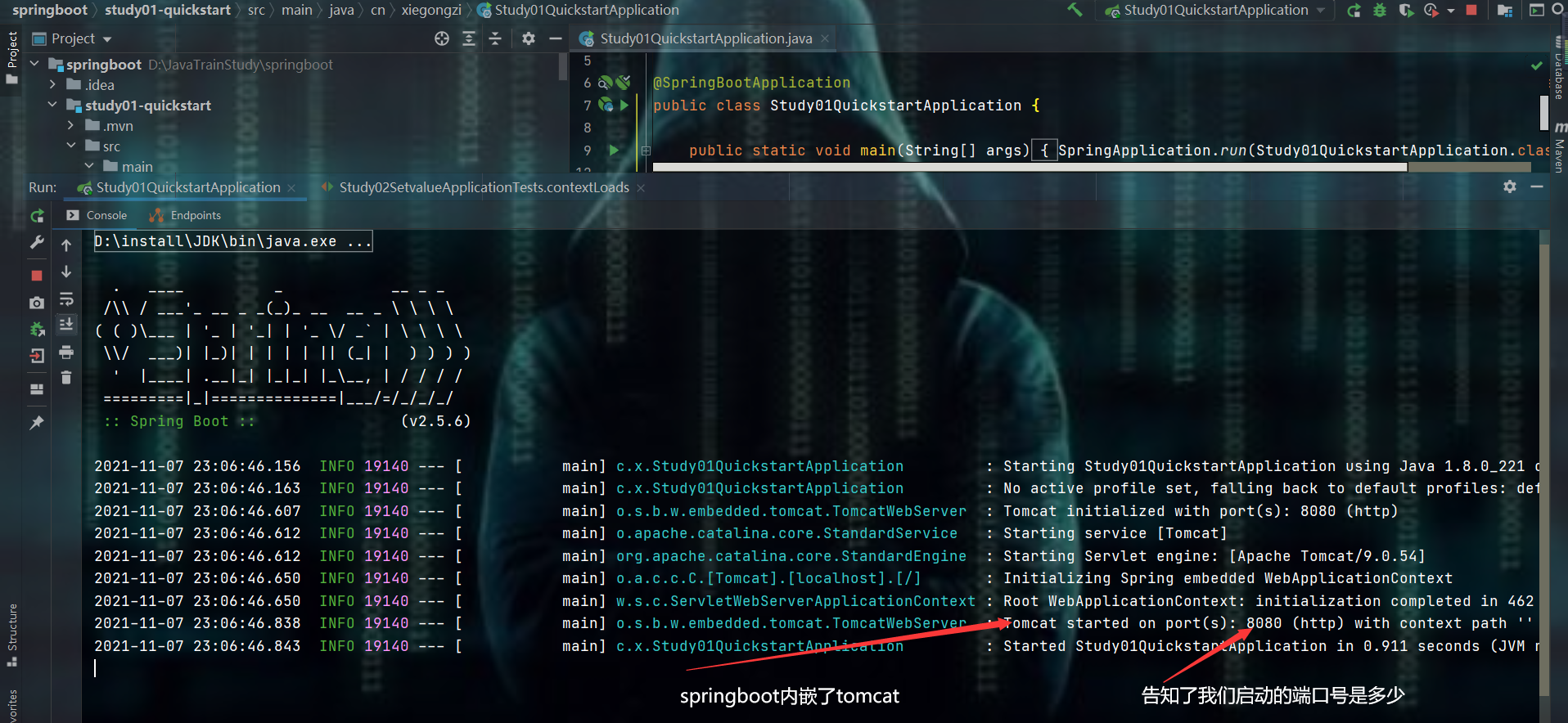
编写controller
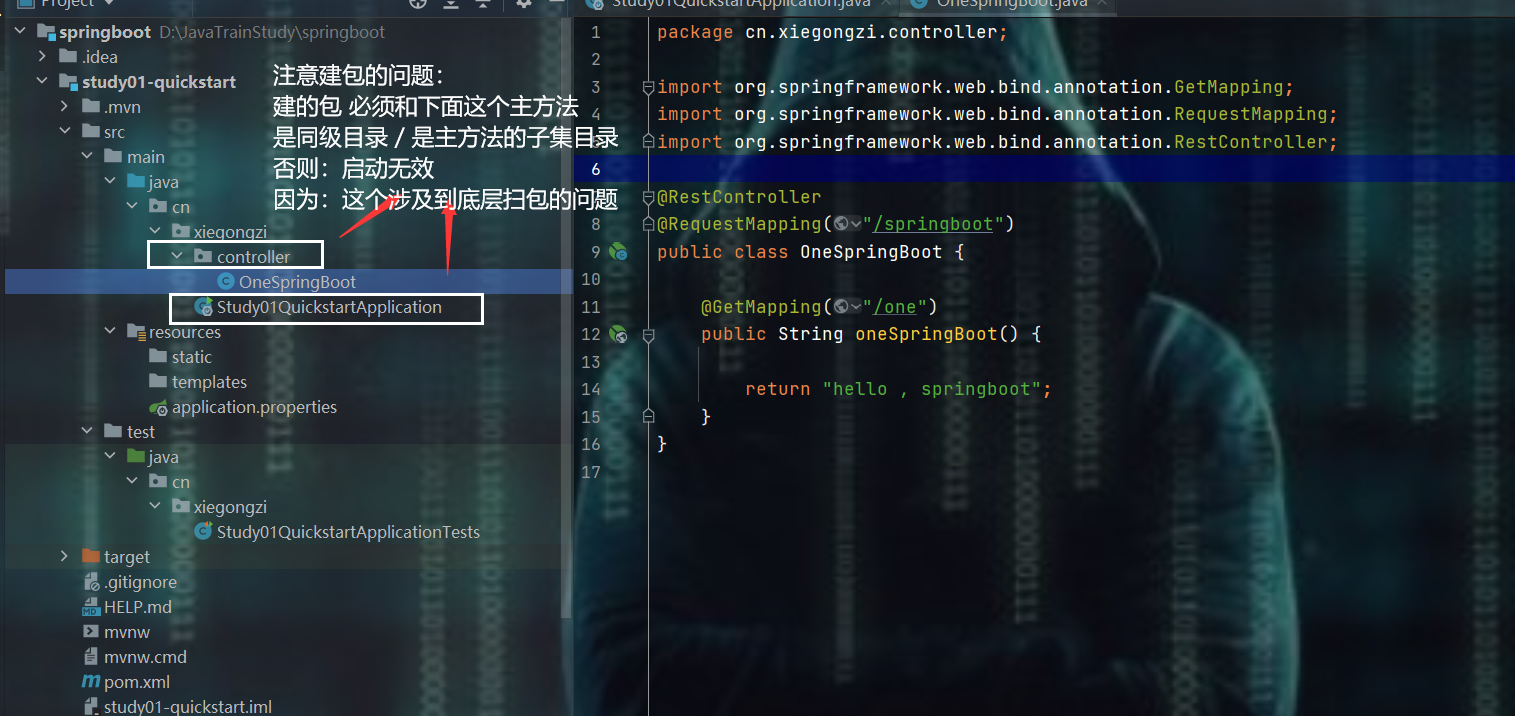
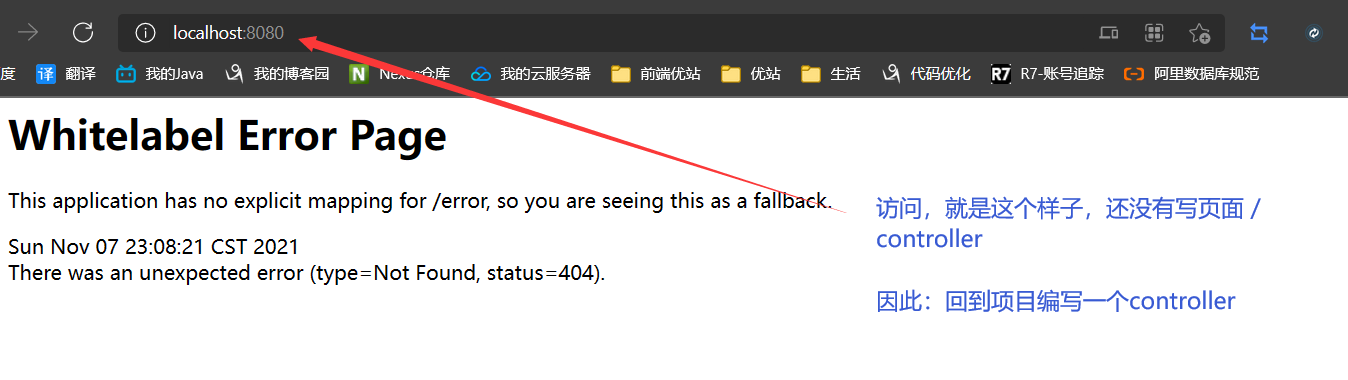
重新启动主方法,输入请求
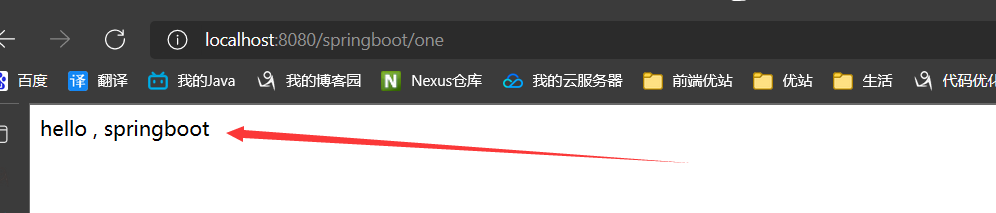
这样就创建成功了一个springboot项目
3、小彩蛋 - banner
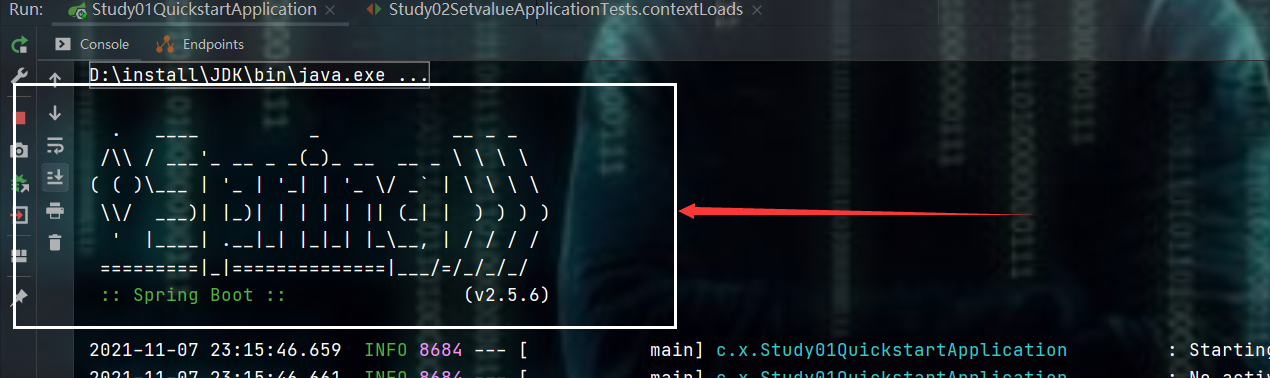
上面这玩意儿,我不想看到它
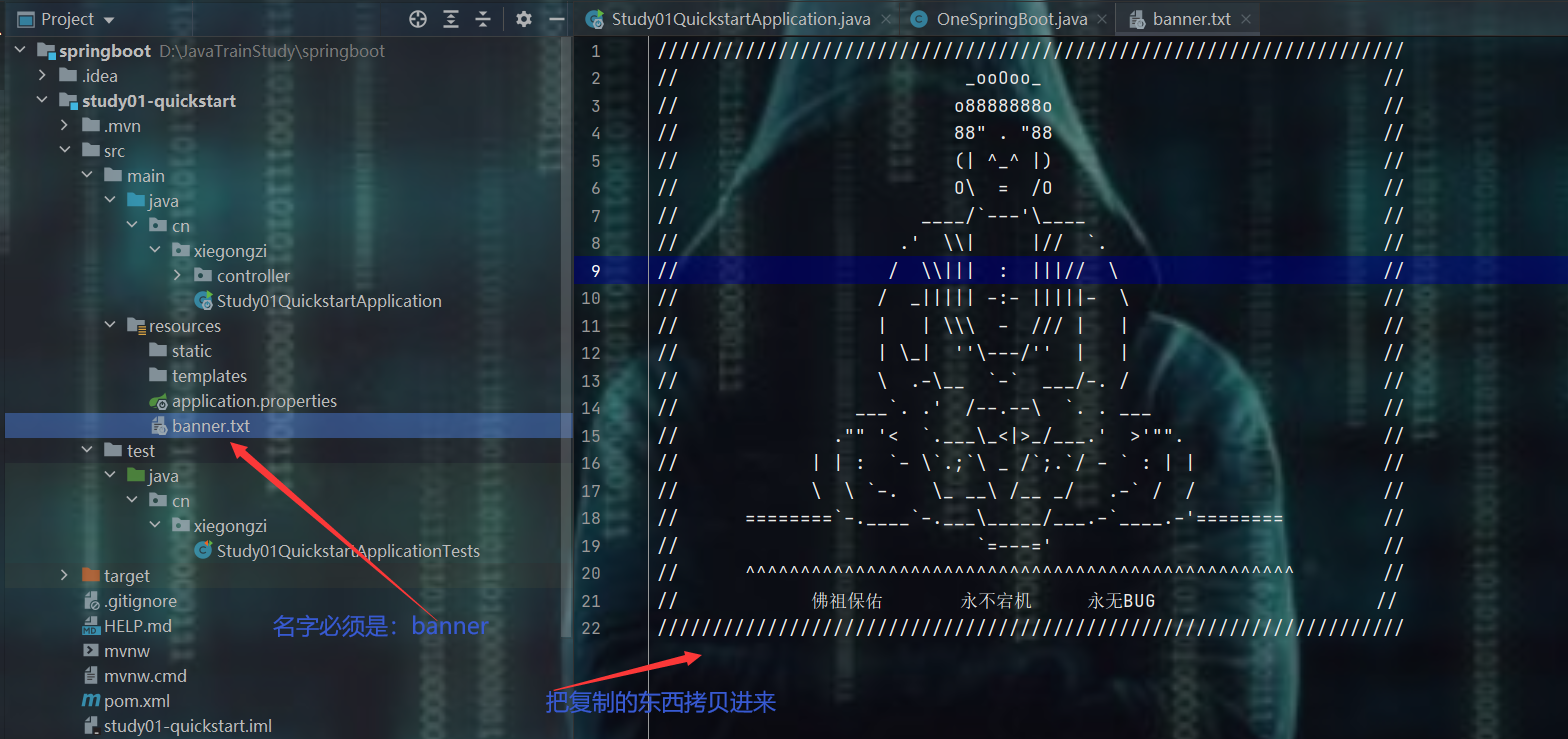
在项目的resources资源目录下,新建一个banner文件
再运行项目主方法
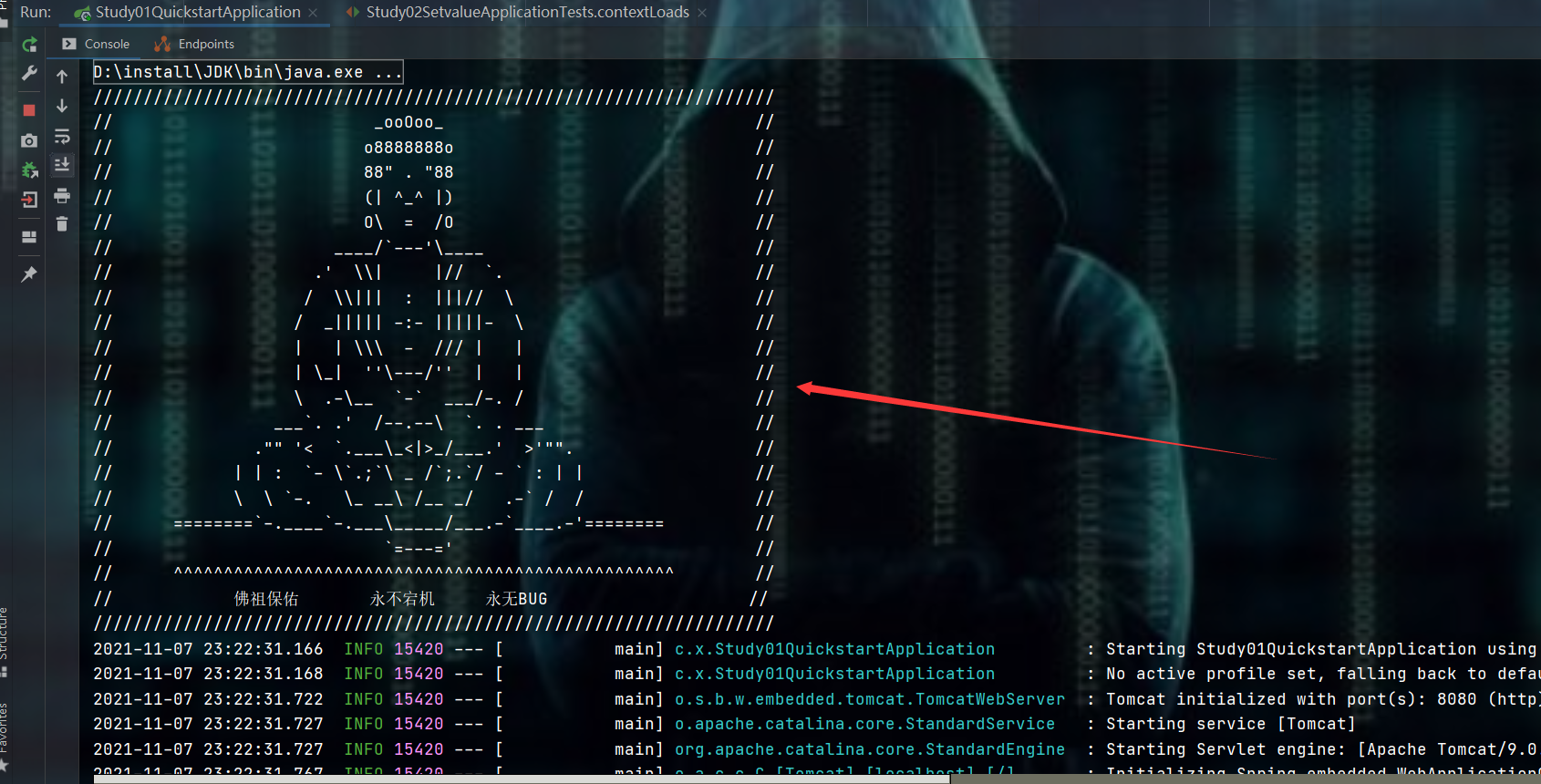
- 至于这个banner为什么可以启动,在下一篇小博客中说SpringBoot的原理图时,里面有
4、了解yml语法
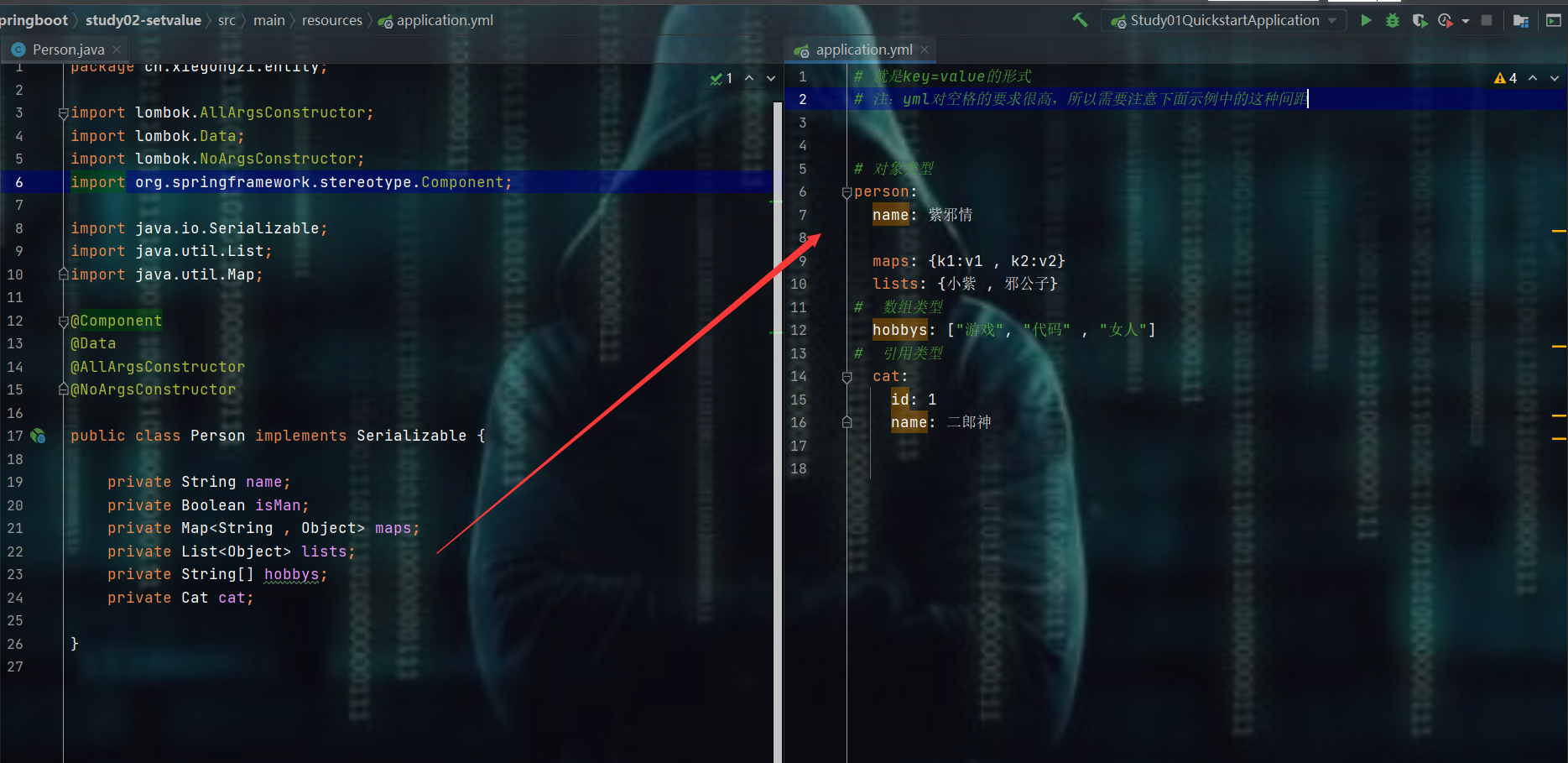
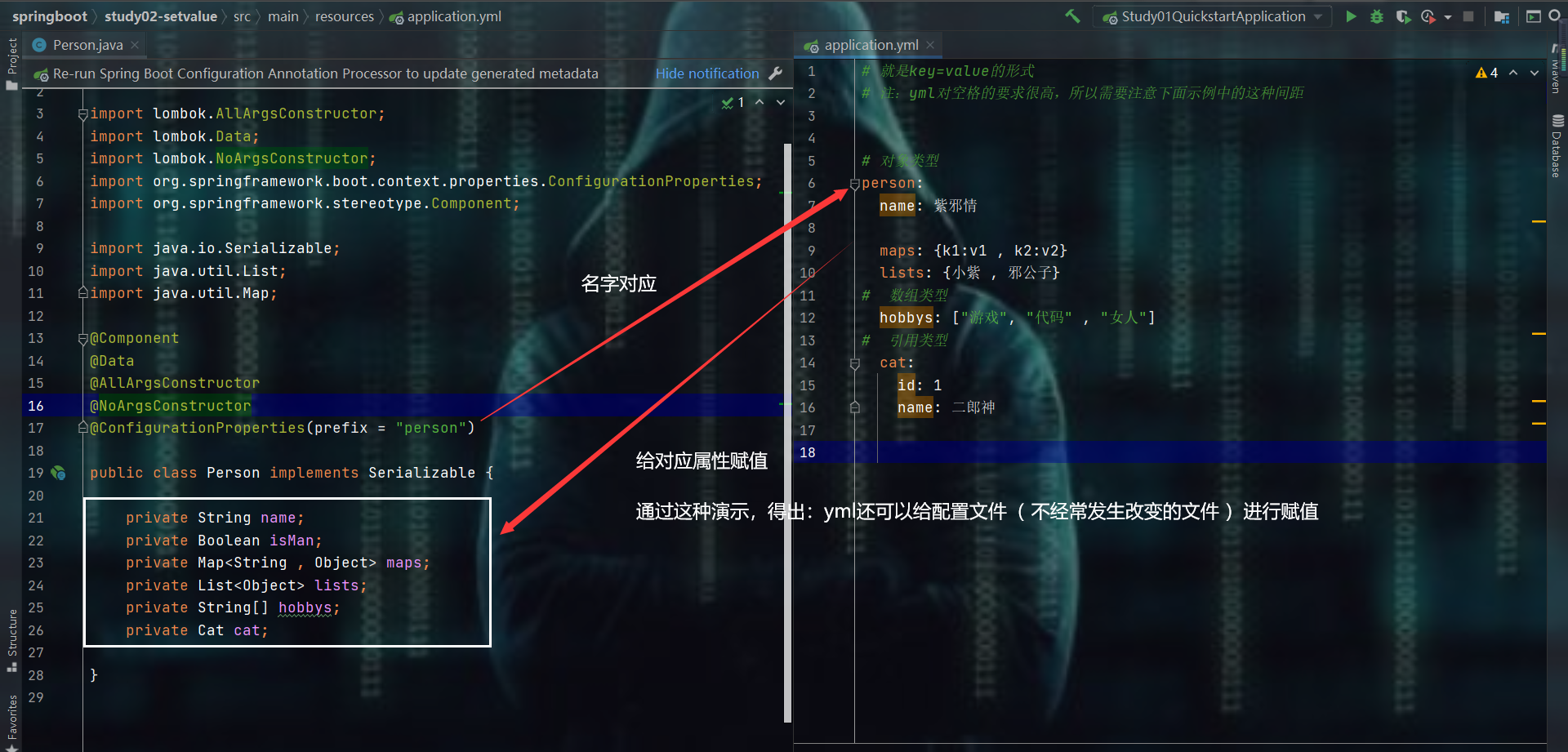
4.1、使用yml给实体类赋值
- 准备工作:导入依赖
<!-- 这个jar包就是为了实体类中使用@ConfigurationProperties(prefix = "person")
这个注解而不报红
-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
- 使用
@ConfigurationProperties注解实现给实体类属性赋值
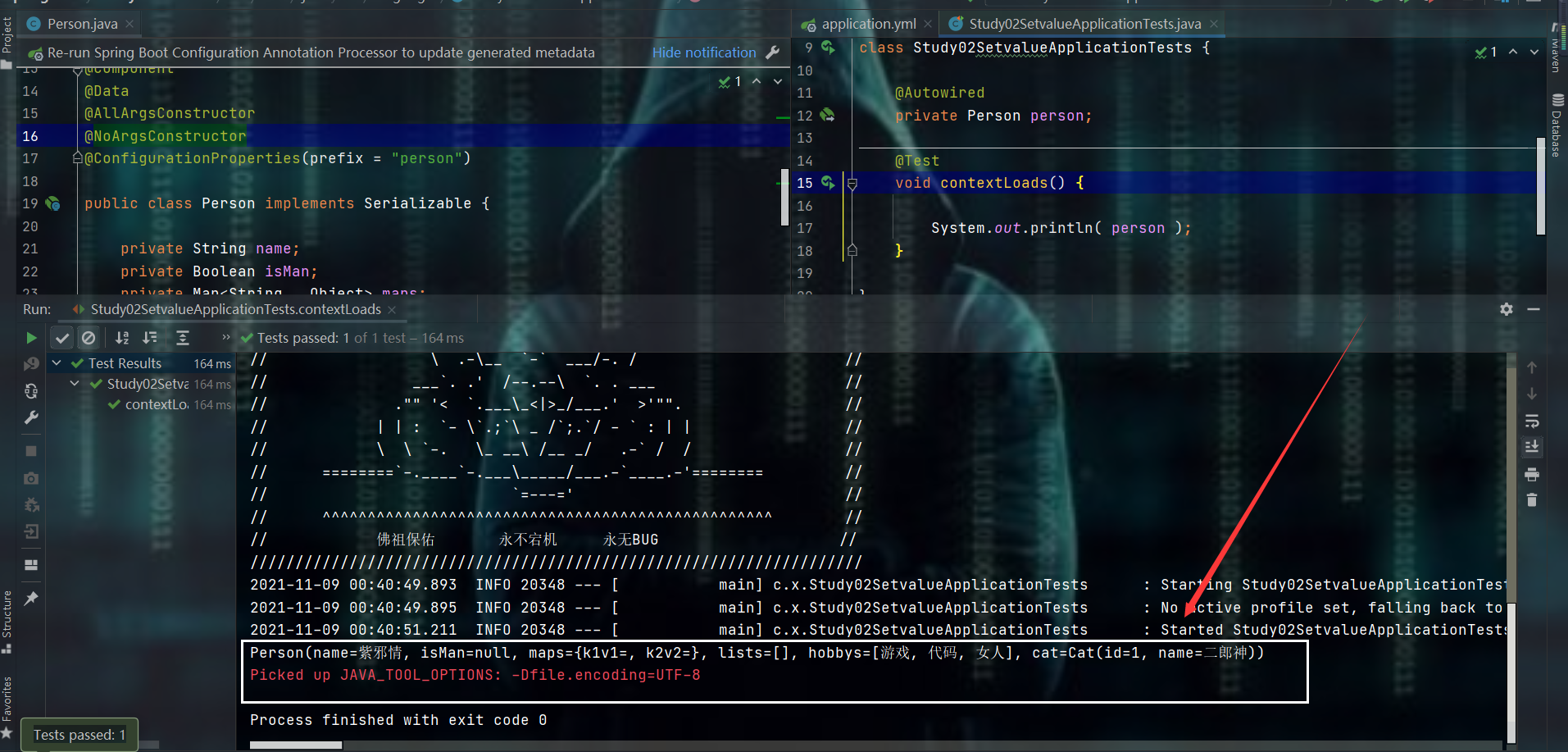
- 测试
5、jsr303检验
依赖
<!--JSR303校验的依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
使用jsr303检验
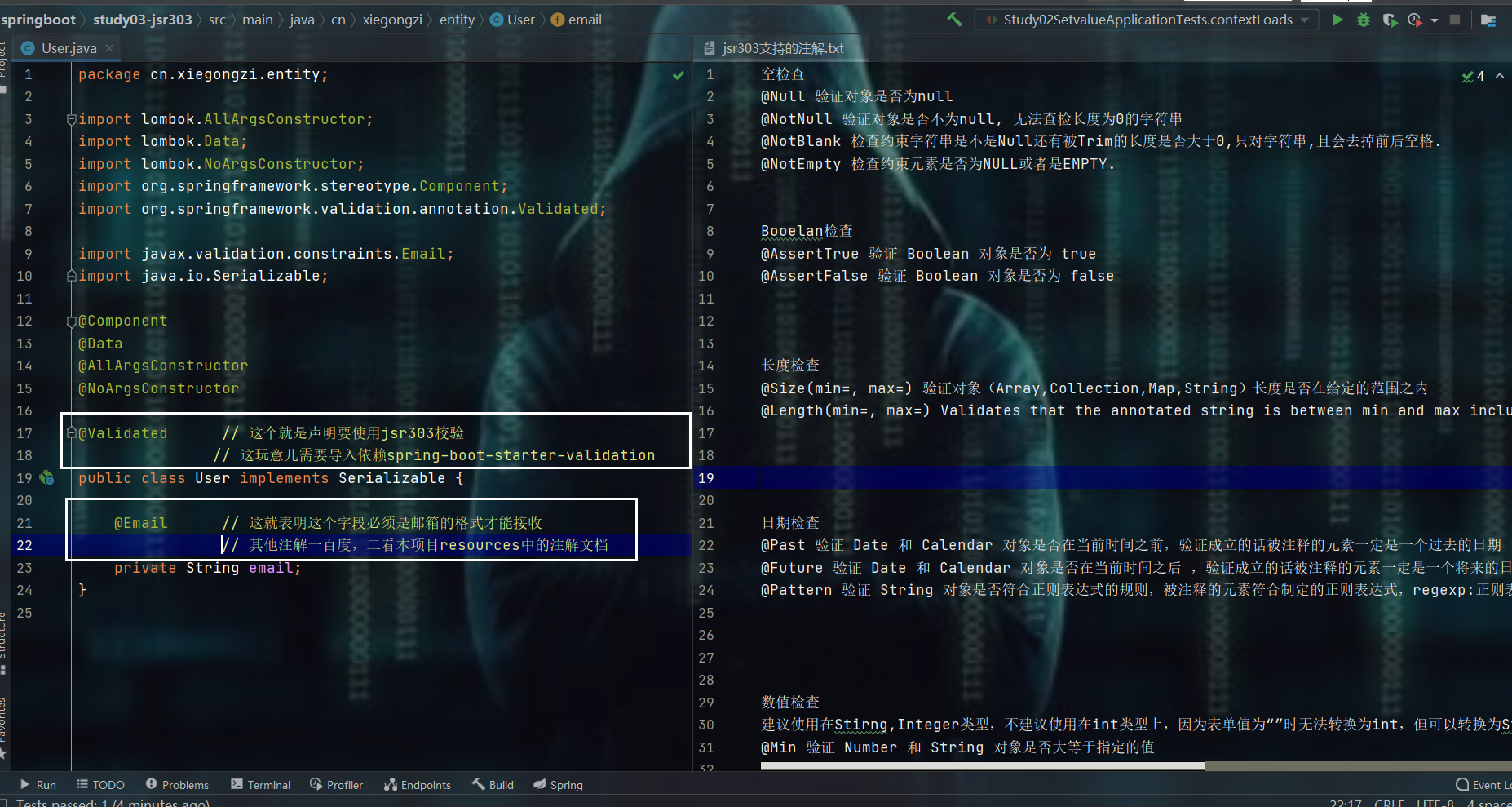
- 可以搭配的注解如下:
空检查
@Null 验证对象是否为null
@NotNull 验证对象是否不为null, 无法查检长度为0的字符串
@NotBlank 检查约束字符串是不是Null还有被Trim的长度是否大于0,只对字符串,且会去掉前后空格.
@NotEmpty 检查约束元素是否为NULL或者是EMPTY.
Booelan检查
@AssertTrue 验证 Boolean 对象是否为 true
@AssertFalse 验证 Boolean 对象是否为 false
长度检查
@Size(min=, max=) 验证对象(Array,Collection,Map,String)长度是否在给定的范围之内
@Length(min=, max=) Validates that the annotated string is between min and max included.
日期检查
@Past 验证 Date 和 Calendar 对象是否在当前时间之前,验证成立的话被注释的元素一定是一个过去的日期
@Future 验证 Date 和 Calendar 对象是否在当前时间之后 ,验证成立的话被注释的元素一定是一个将来的日期
@Pattern 验证 String 对象是否符合正则表达式的规则,被注释的元素符合制定的正则表达式,regexp:正则表达式 flags: 指定 Pattern.Flag 的数组,表示正则表达式的相关选项。
数值检查
建议使用在Stirng,Integer类型,不建议使用在int类型上,因为表单值为“”时无法转换为int,但可以转换为Stirng为”“,Integer为null
@Min 验证 Number 和 String 对象是否大等于指定的值
@Max 验证 Number 和 String 对象是否小等于指定的值
@DecimalMax 被标注的值必须不大于约束中指定的最大值. 这个约束的参数是一个通过BigDecimal定义的最大值的字符串表示.小数存在精度
@DecimalMin 被标注的值必须不小于约束中指定的最小值. 这个约束的参数是一个通过BigDecimal定义的最小值的字符串表示.小数存在精度
@Digits 验证 Number 和 String 的构成是否合法
@Digits(integer=,fraction=) 验证字符串是否是符合指定格式的数字,interger指定整数精度,fraction指定小数精度。
@Range(min=, max=) 被指定的元素必须在合适的范围内
@Range(min=10000,max=50000,message=”range.bean.wage”)
@Valid 递归的对关联对象进行校验, 如果关联对象是个集合或者数组,那么对其中的元素进行递归校验,如果是一个map,则对其中的值部分进行校验.(是否进行递归验证)
@CreditCardNumber信用卡验证
@Email 验证是否是邮件地址,如果为null,不进行验证,算通过验证。
@ScriptAssert(lang= ,script=, alias=)
@URL(protocol=,host=, port=,regexp=, flags=)
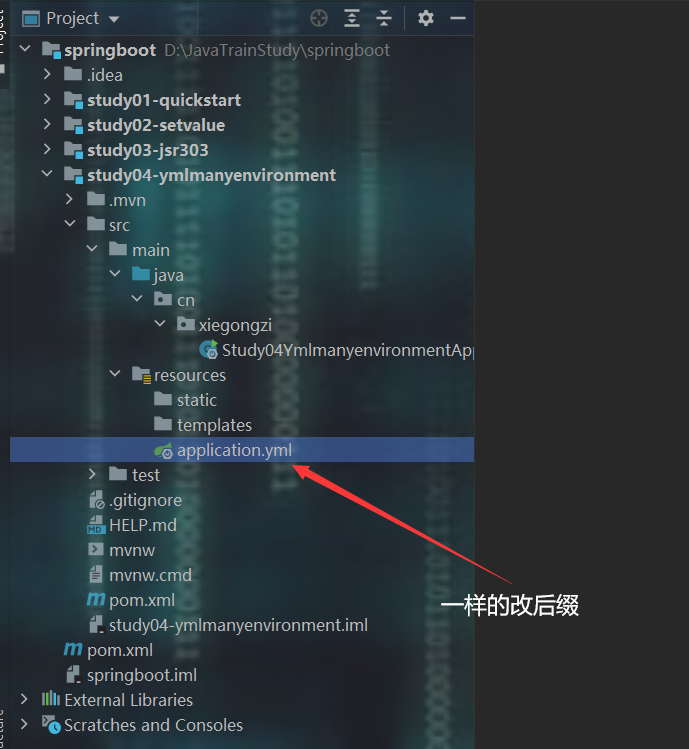
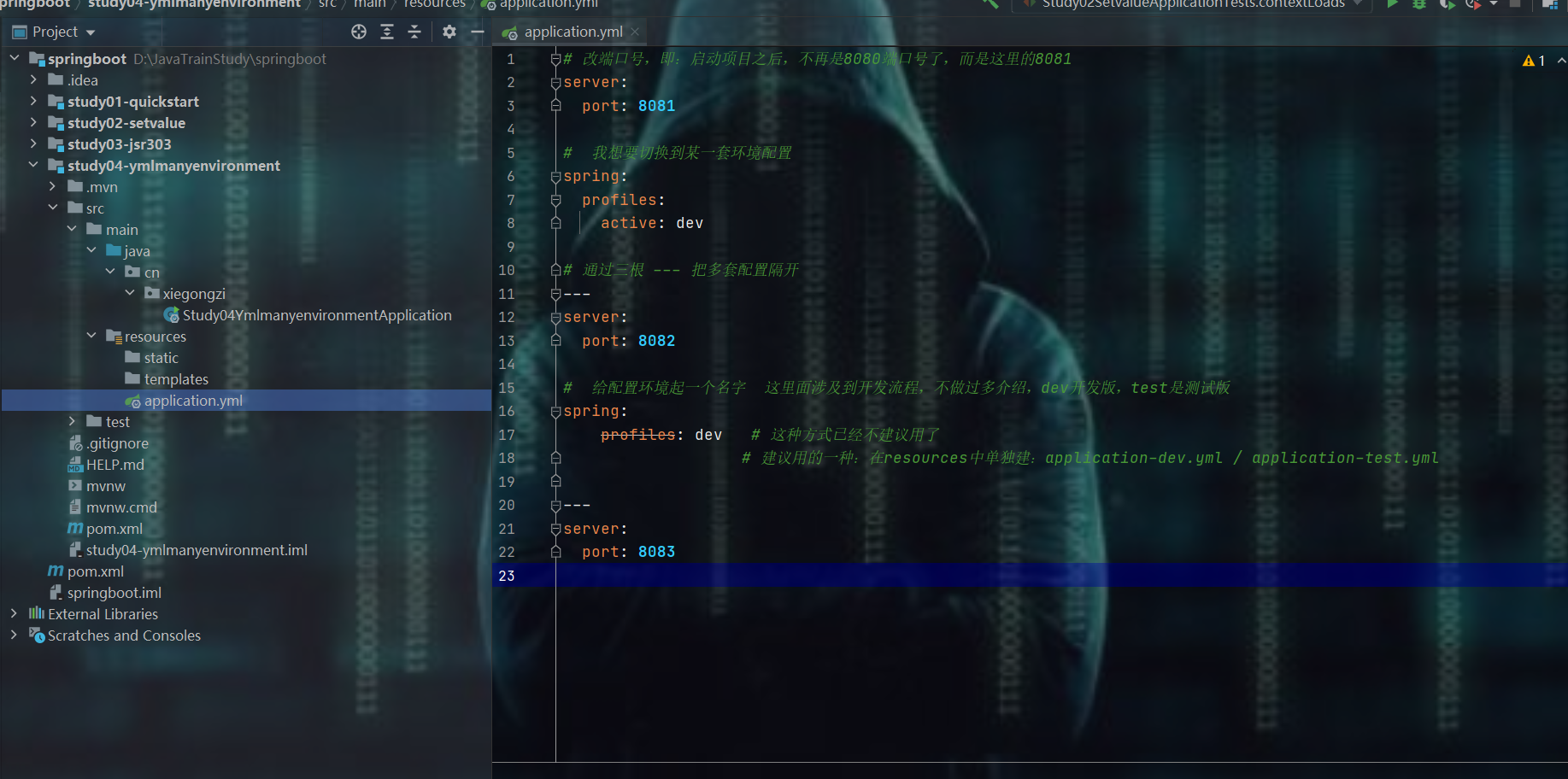
6、yml多环境配置
7、设置默认首页
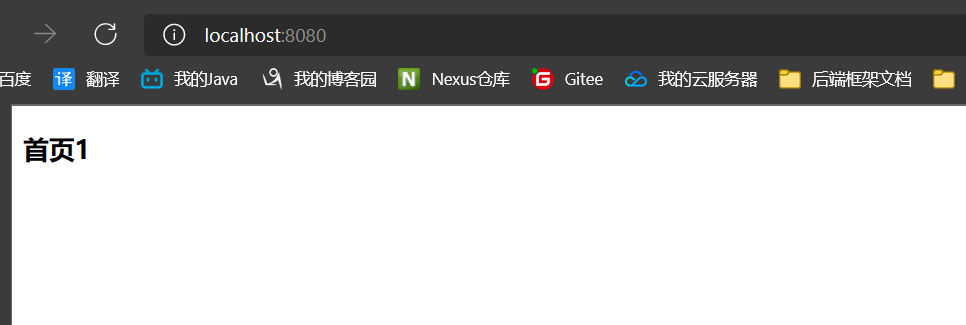
7.1、页面在static目录中时
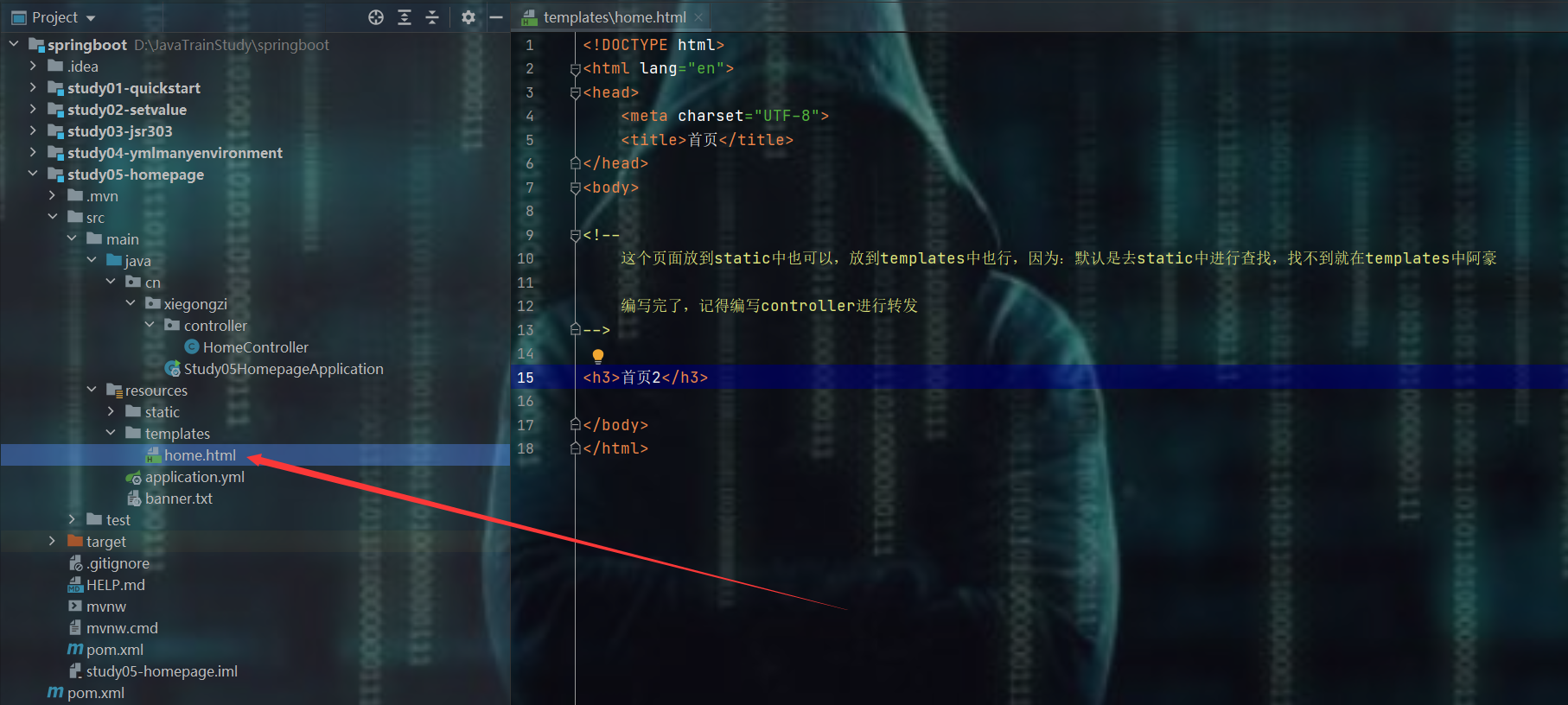
7.2、页面在templates模板引擎中时
这种需要导入相应的启动器
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
编写controller
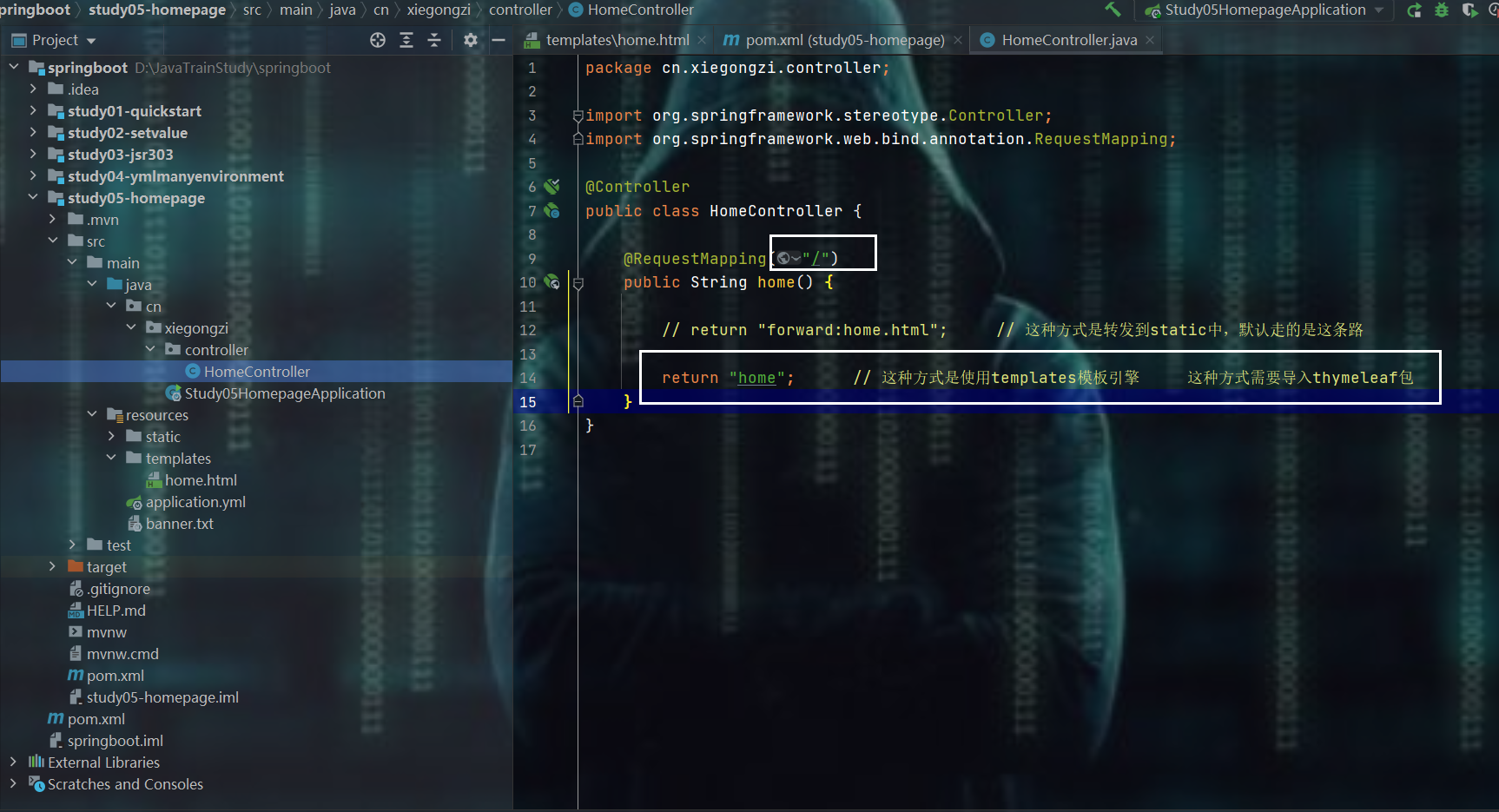
测试
8、简单认识thymeleaf
官网学习地址
8.1、什么是thymeleaf?
一张图看明白:
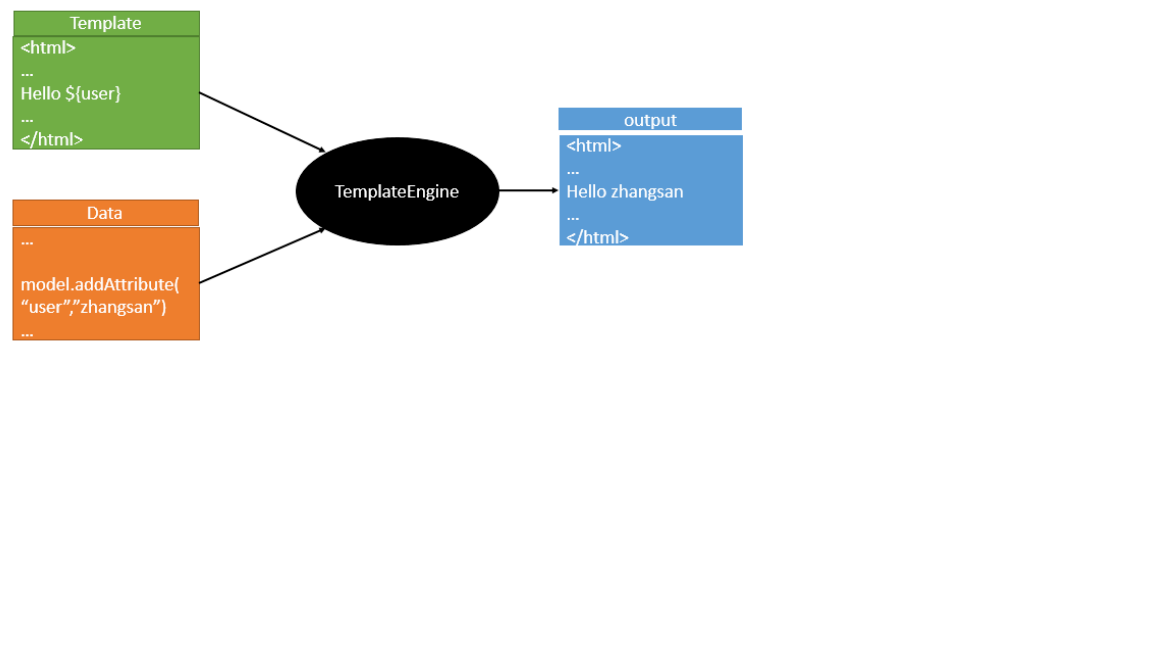
解读:
前端交给我们的页面,是html页面。如果是我们以前开发,我们需要把他们转成jsp页面,jsp好处就是当我们查出一些数据转发到JSP页面以后,我们可以用jsp轻松实现数据的显示,及交互等
jsp支持非常强大的功能,包括能写Java代码,但是,SpringBoot是以jar的方式,不是war,第二,我们用的还是嵌入式的Tomcat,所以,springboot现在默认是不支持jsp的
那不支持jsp,如果我们直接用纯静态页面的方式,那给我们开发会带来非常大的麻烦,那怎么办?
SpringBoot推荐使用模板引擎:
模板引擎,我们其实大家听或多或少都听说过一些,其实jsp就是一个模板引擎,还有用的比较多的freemarker,包括SpringBoot给我们推荐的Thymeleaf,模板引擎有非常多,但再多的模板引擎,他们的思想都是一样的
模板引擎的作用就是我们来写一个页面模板,比如有些值,是动态的,我们写一些表达式。而这些值从哪来?就是我们在后台封装一些数据。然后把这个模板和这个数据交给模板引擎,模板引擎按照我们封装的数据把这表达式解析出来、填充到我们指定的位置,然后把这个数据最终生成一个我们想要的内容从而最后显示出来,这就是模板引擎。
不管是jsp还是其他模板引擎,都是这个思想。只不过,不同模板引擎之间,他们可能语法有点不一样。其他的就不介绍了,这里主要介绍一下SpringBoot给我们推荐的Thymeleaf模板引擎,这模板引擎,是一个高级语言的模板引擎,他的这个语法更简单。而且功能更强大
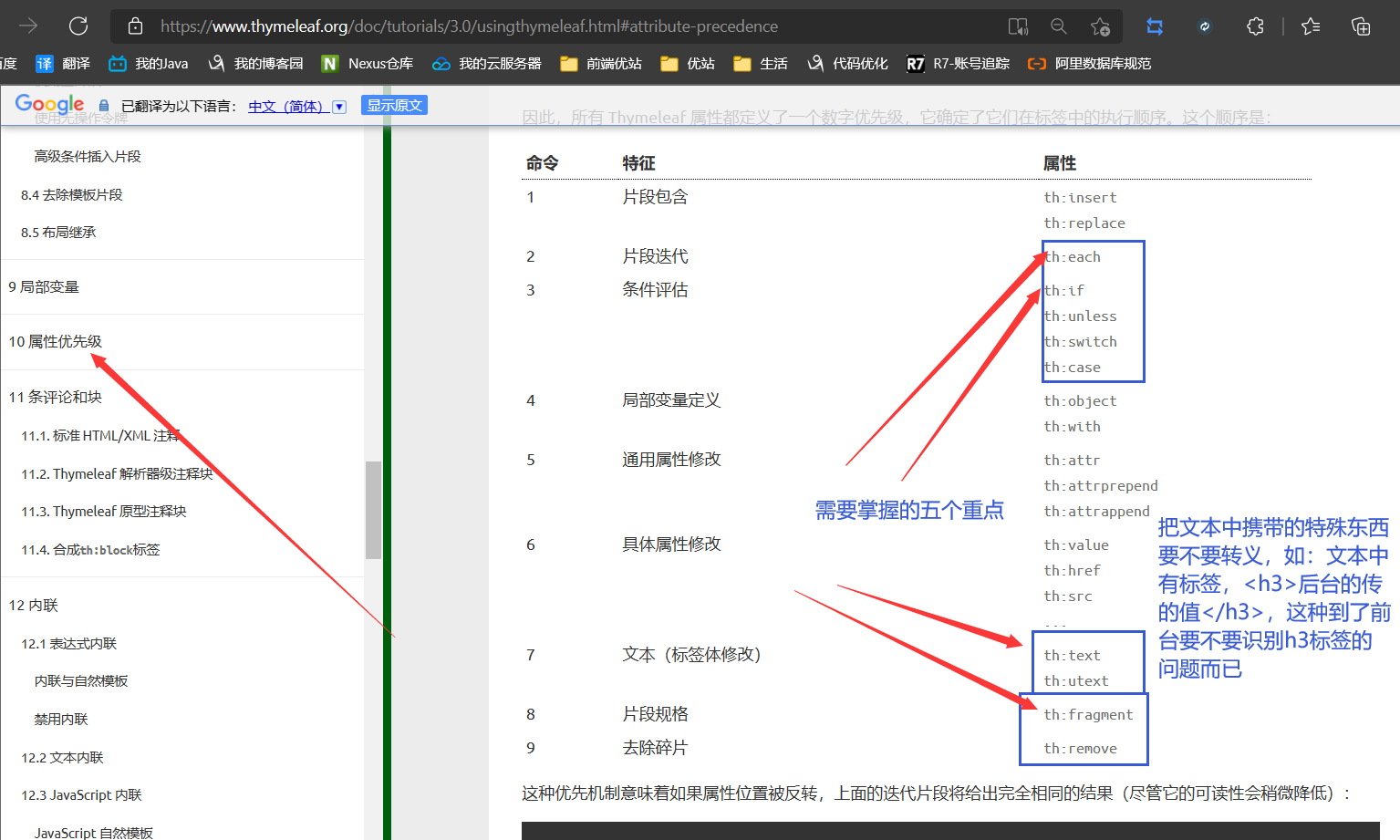
8.2、thymeleaf的取数据方式
- 官网中有说明
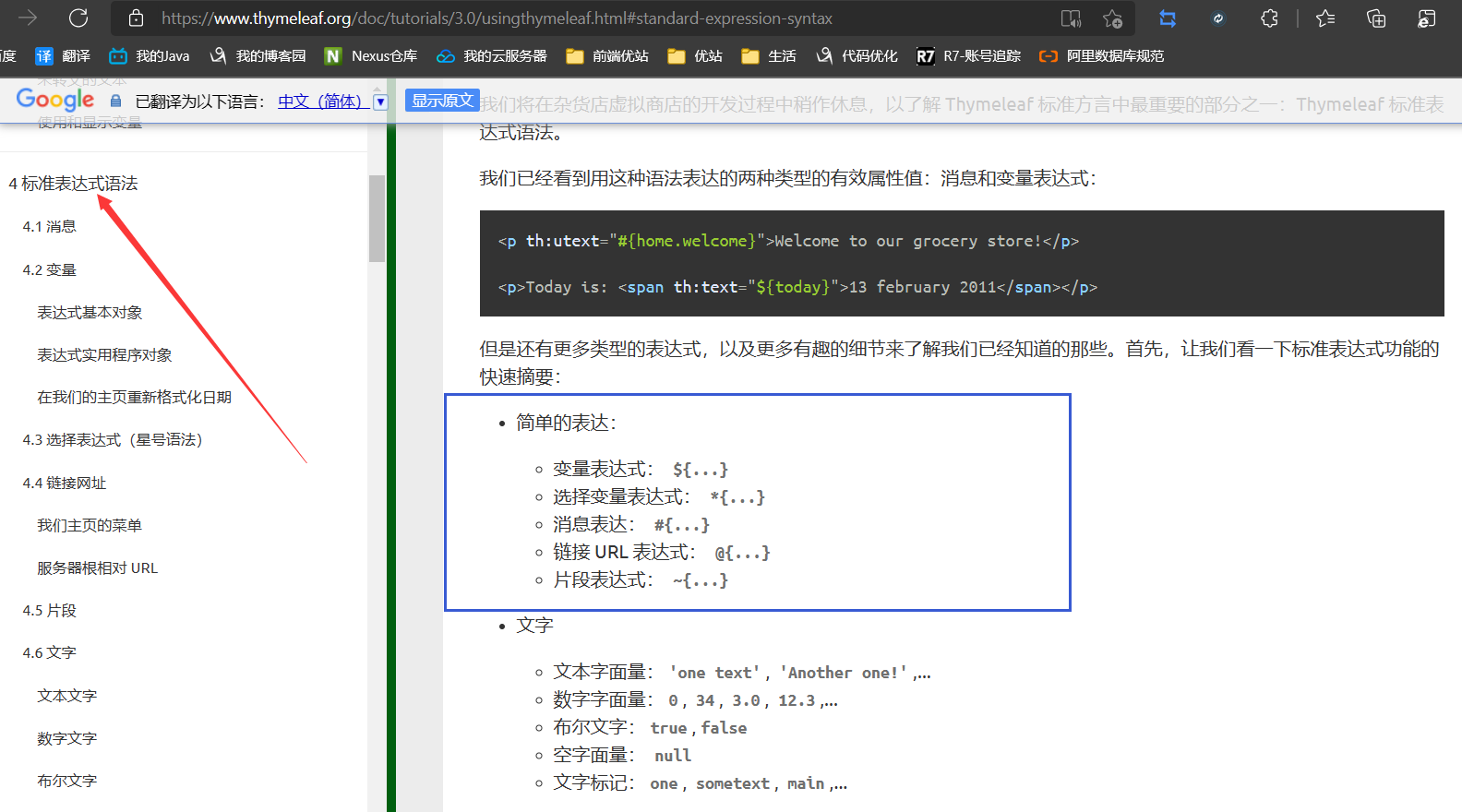
提取出来看一下,从而在springboot中演示一下
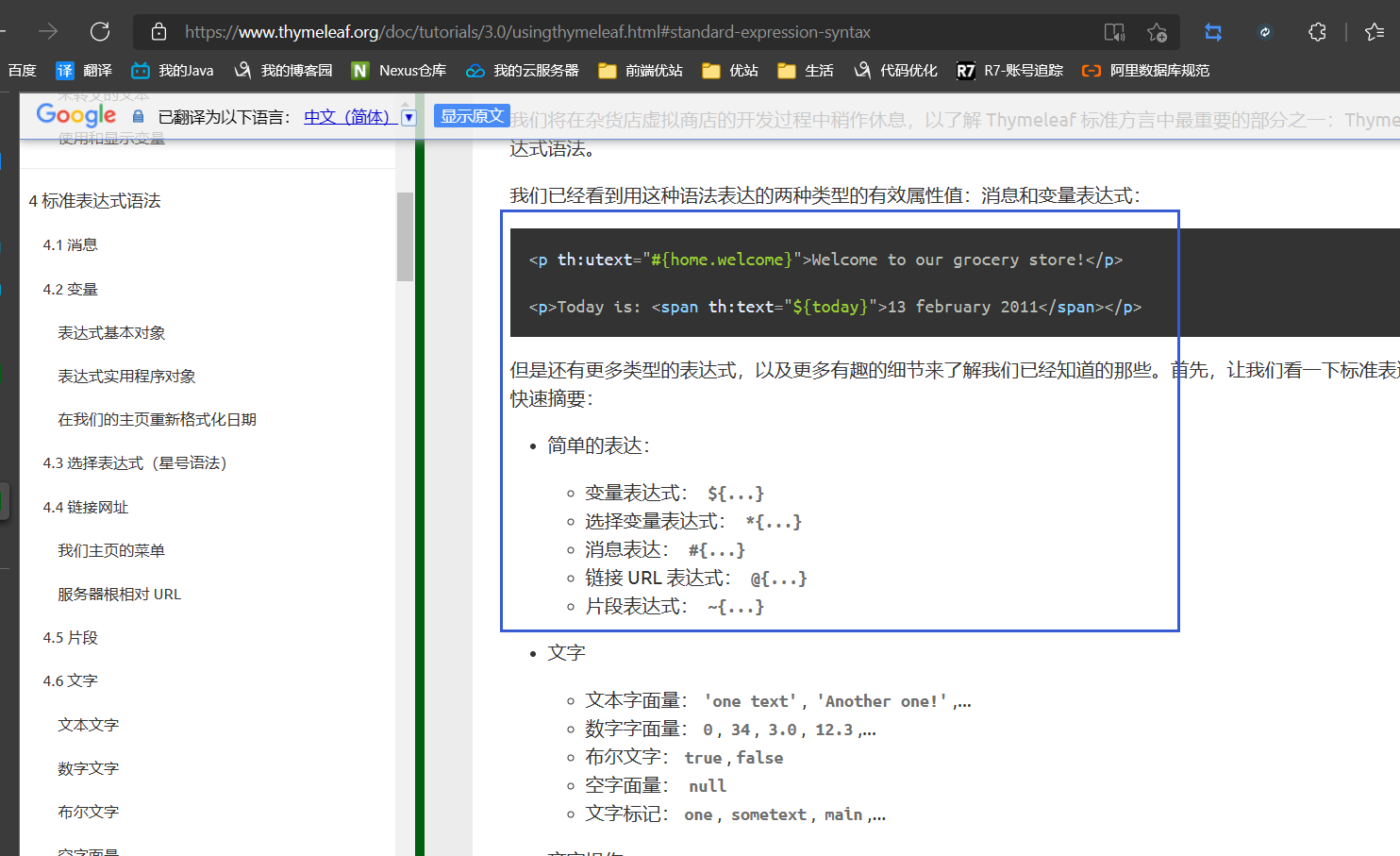
- 简单的表达:
- 变量表达式: ${...}
- 选择变量表达式: *{...}
- 消息表达: #{...}
- 链接 URL 表达式: @{...}
- 片段表达式: ~{...}
8.3、在springboot中使用thymeleaf
依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
怎么使用thymeleaf?
- 这个问题换言之就是:html文件应该放到什么目录下
- 前面我们已经导入了依赖,那么按照springboot的原理,底层会帮我们导入相应的东西,并做了相应的配置,那么就去看一下源码,从而知道我们应该把文件放在什么地方( 注:springboot中和配置相关的都在xxxxxProperties文件中,因此:去看一下thymeleaf对应的thymeleafProperties文件 )
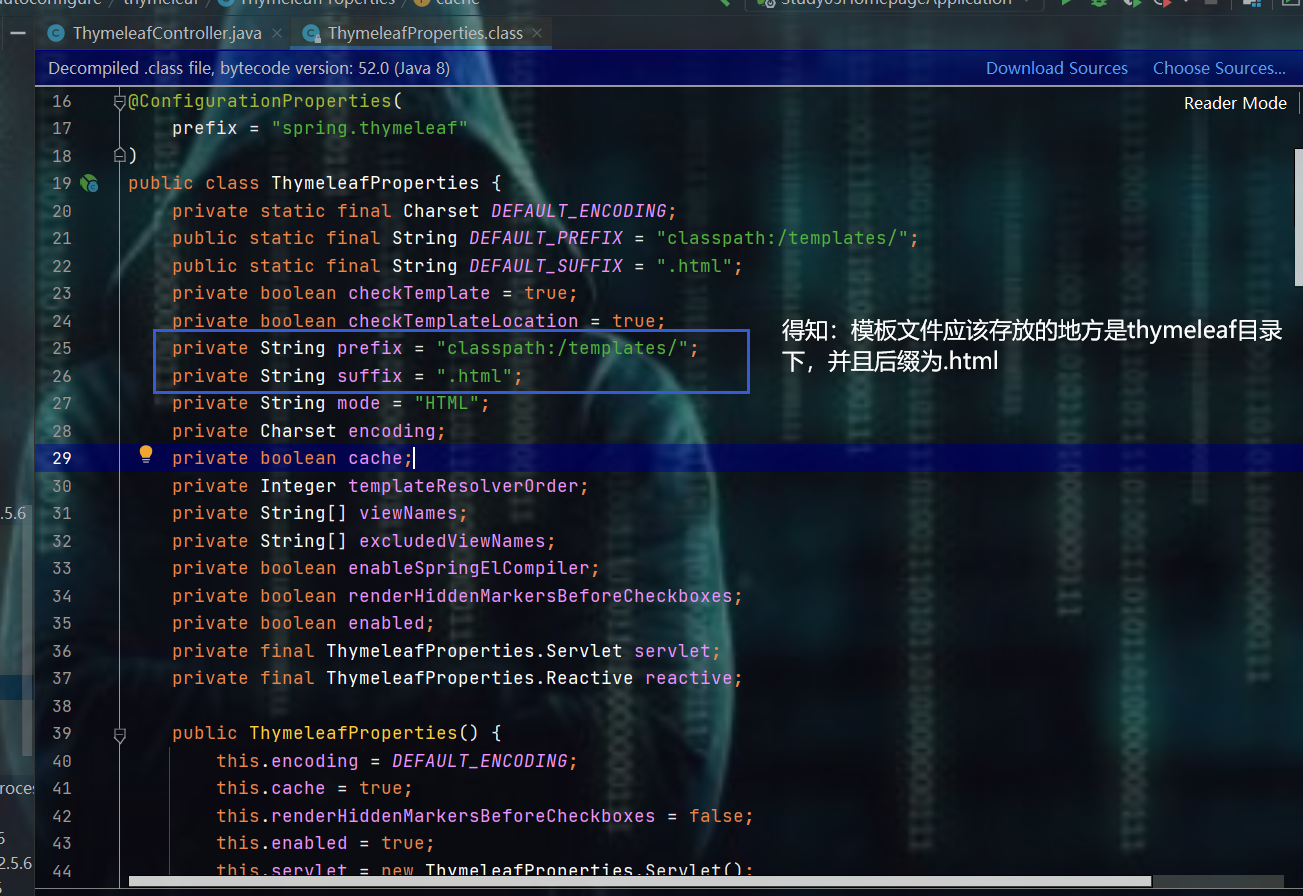
- 那就来建一个
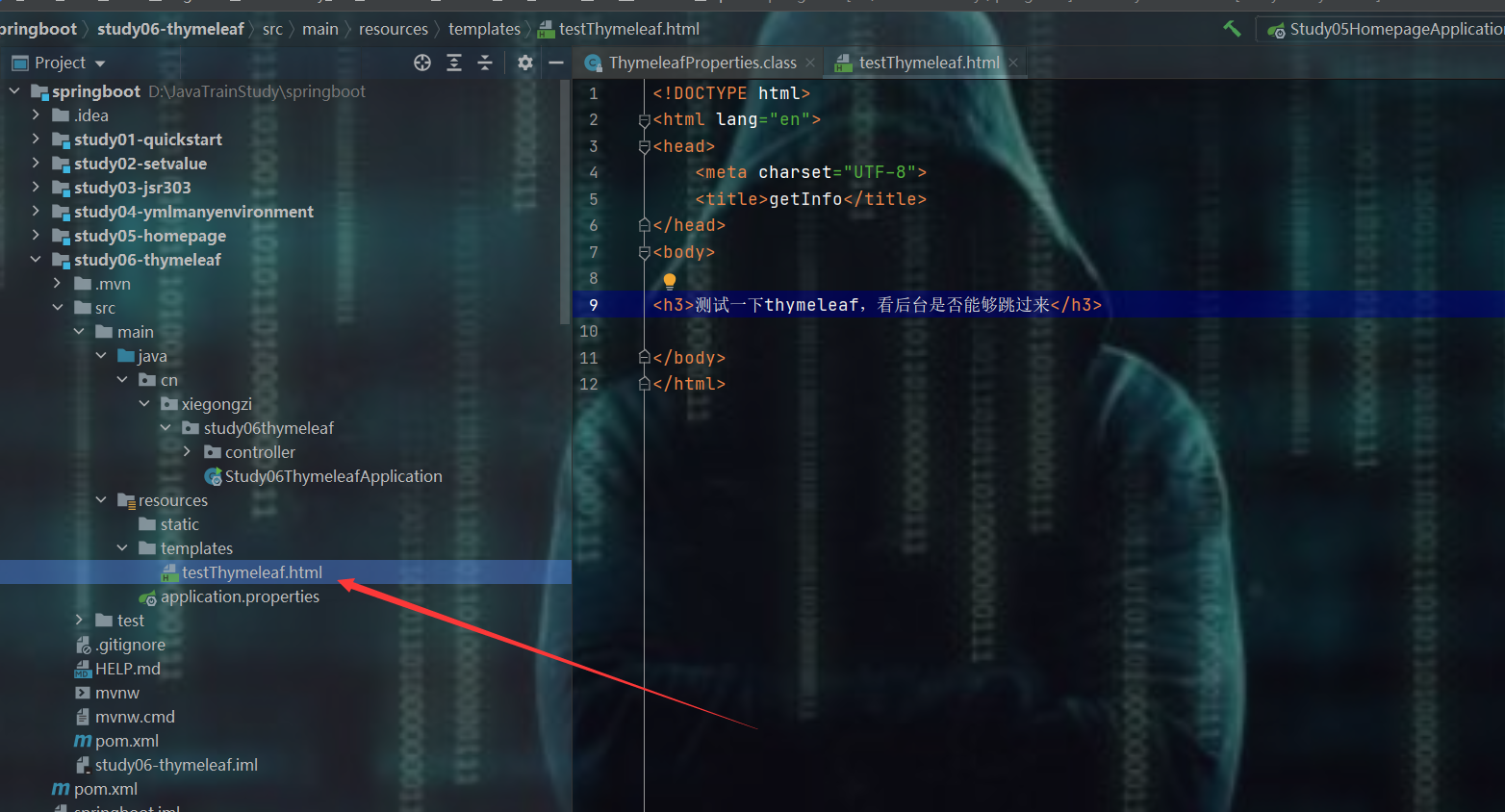
- 编写controller,让其跳到templates目录的页面中去
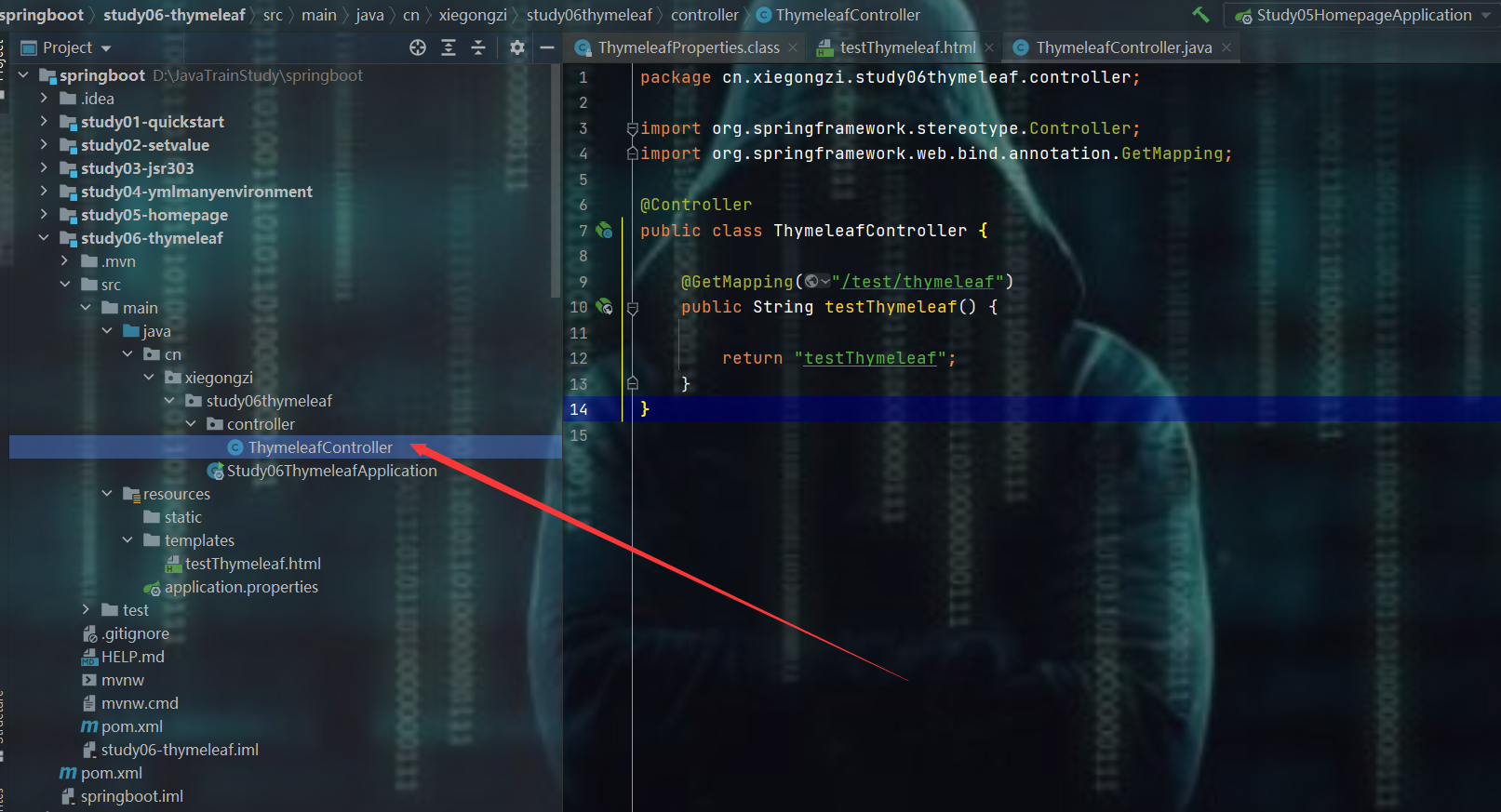
测试

成功跳过去了
8.4、延伸:传输数据
8.4.1、开胃菜
- 参照官网来( 这里只演示 变量表达式: ${...},其他的都是一样的原理 )
编写后台,存入数据
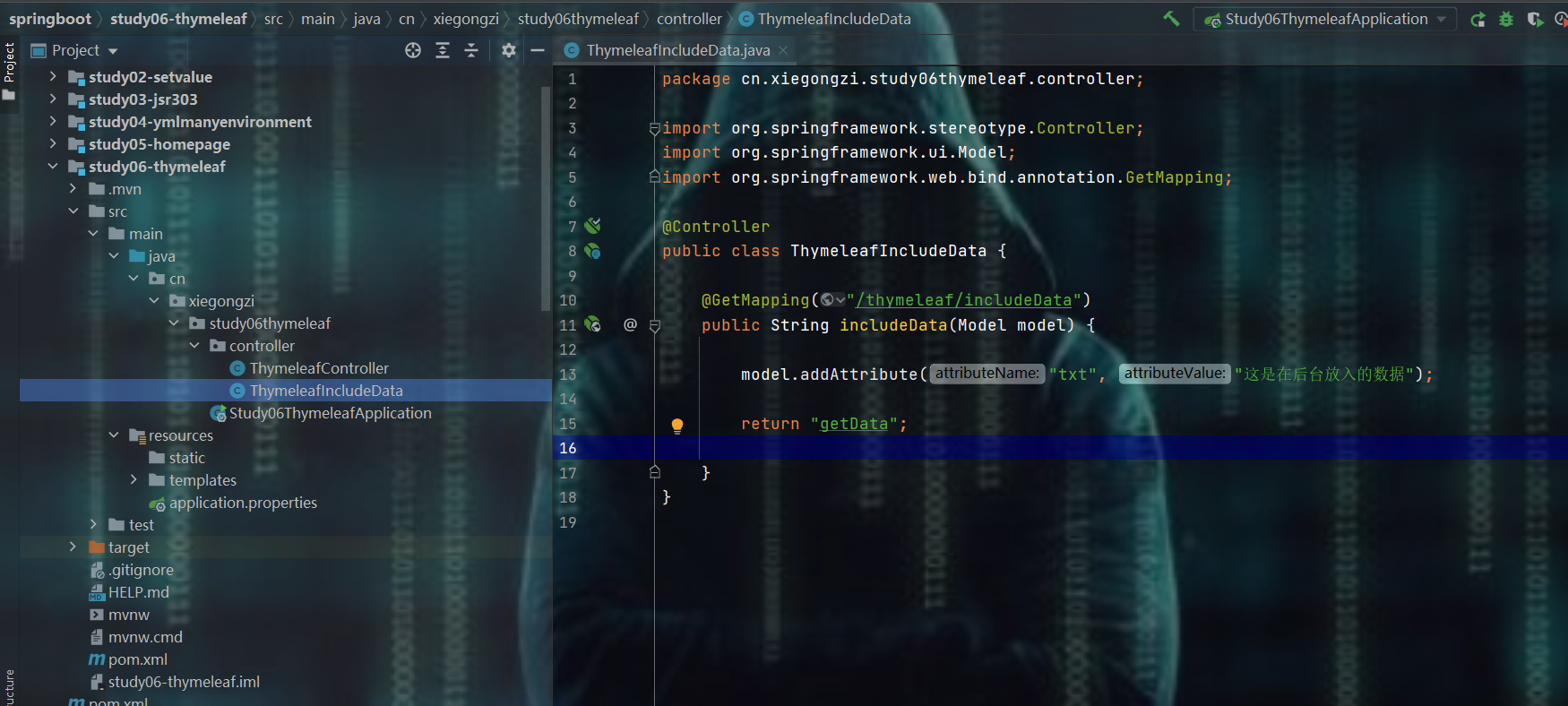
在前台获取数据
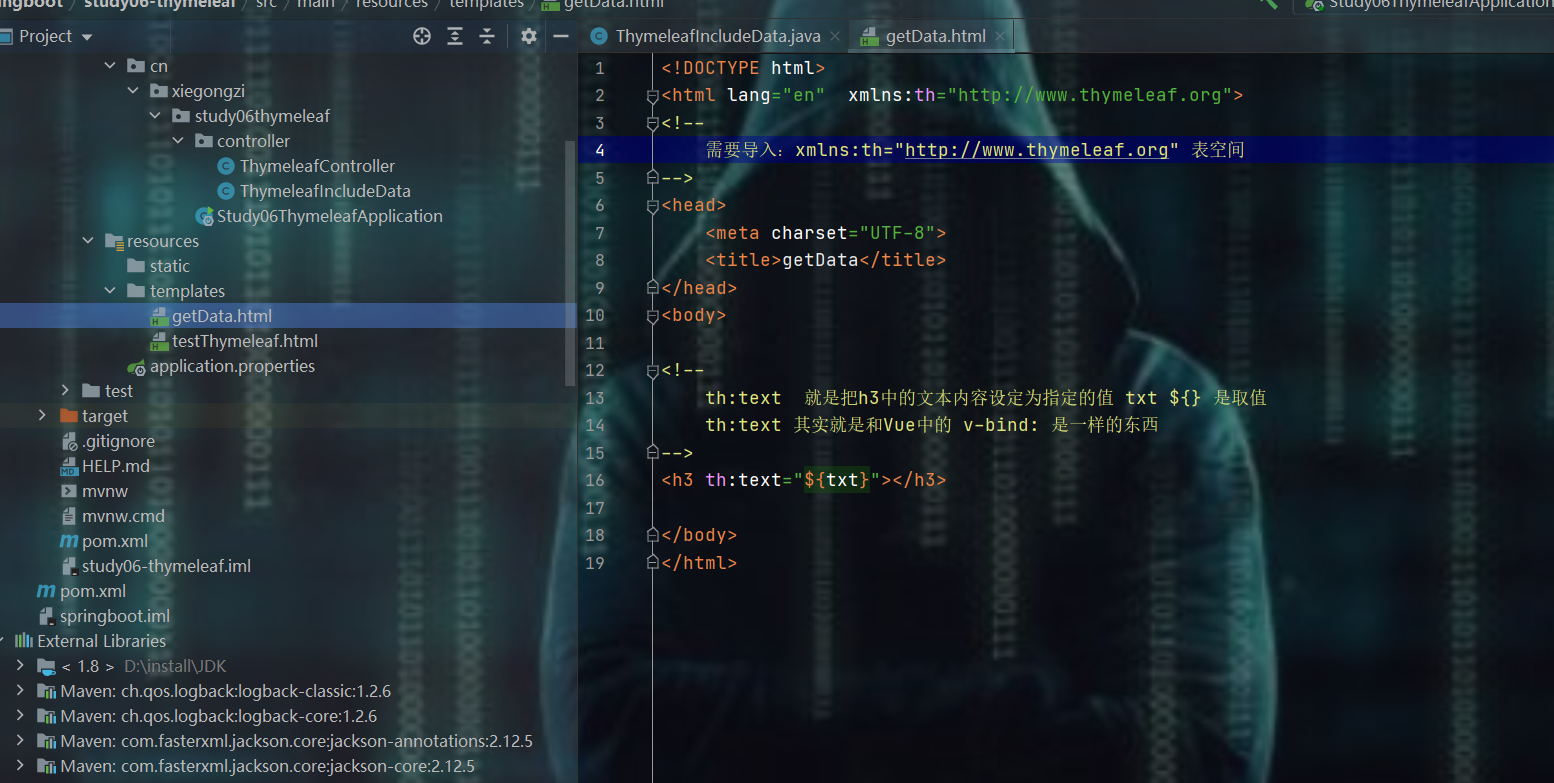
** 表空间约束链接如下,这个在thymeleaf官网中有**
xmlns:th="http://www.thymeleaf.org"
测试:

8.4.2、开整
后台
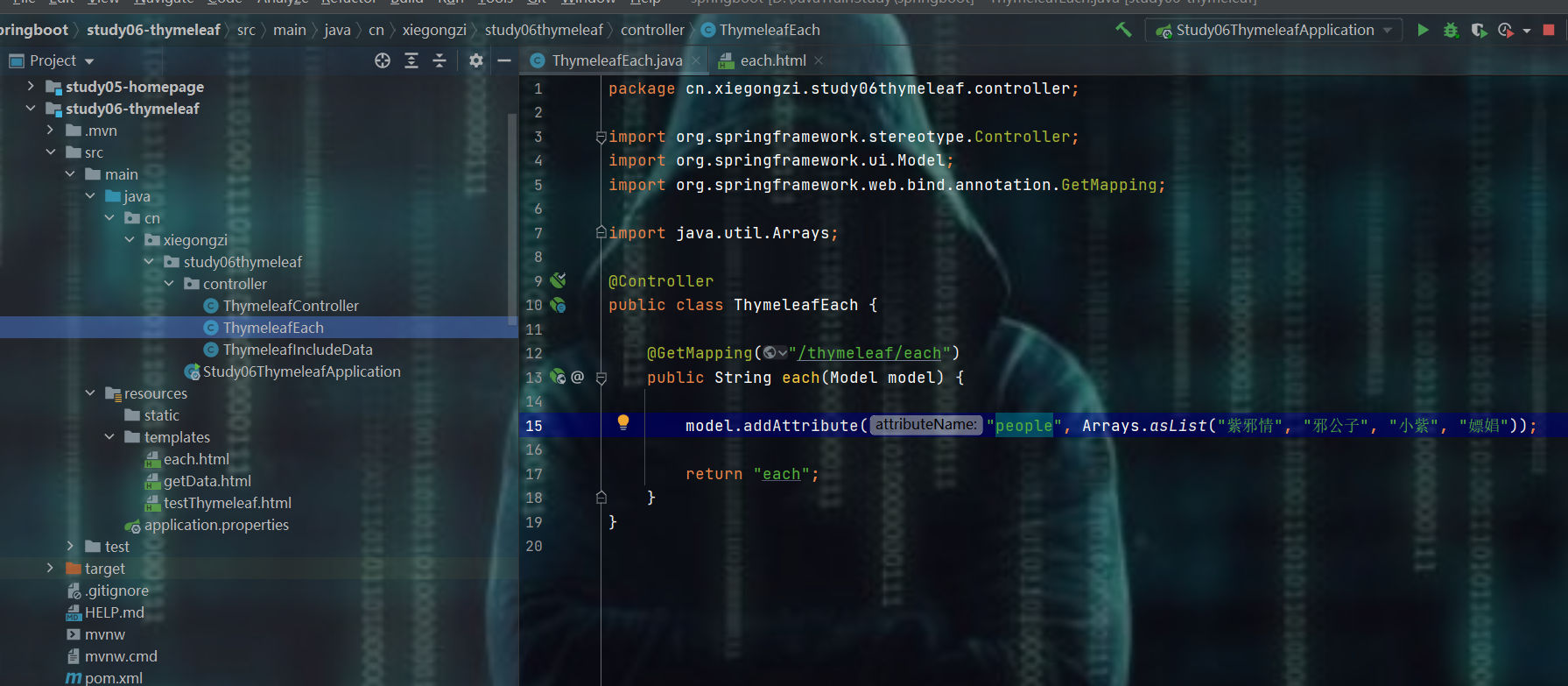
前台

测试
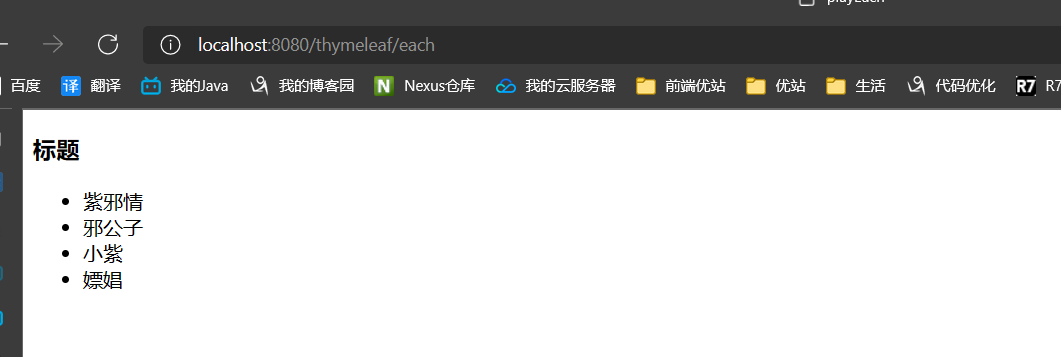
其他的玩法都差不多
9、静态资源处理方式
- 在前面玩了thymeleaf,在resources中还有一个目录是static
- 那么就来研究一下静态资源:静态资源,springboot底层是怎么去装配的?
- 都在WebMvcAutoConfiguration有答案,去看一下
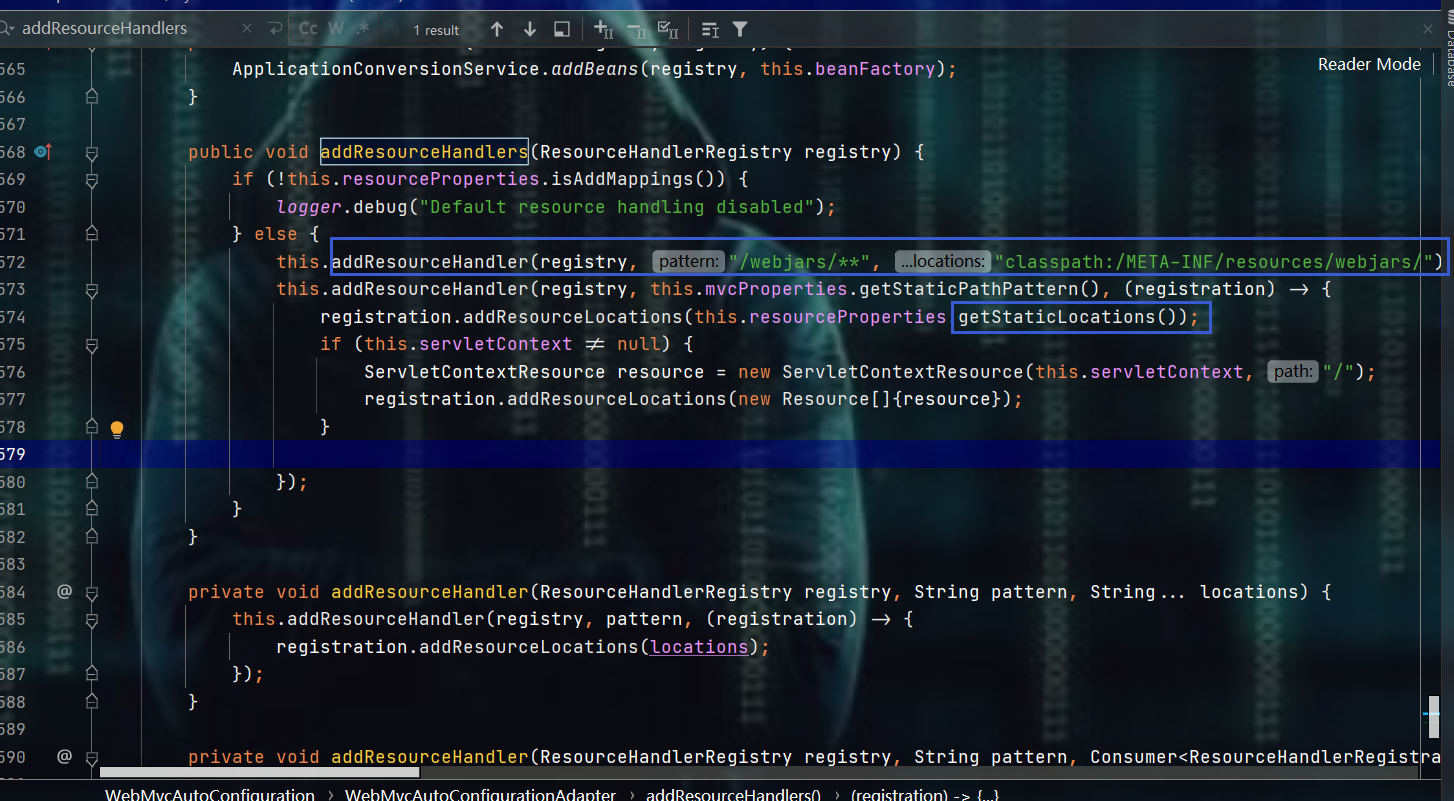
- 通过上述的源码发现两个东西:
webjars和getStaticLocations()
9.1、webjars的方式处理静态资源
- webjars的官网:https://www.webjars.org/all
- 进去之后:里面就是各种各样的jar包
使用jQuery做演示
- 导入jQuery的依赖
<dependency>
<groupId>org.webjars</groupId>
<artifactId>jquery</artifactId>
<version>3.4.1</version>
</dependency>
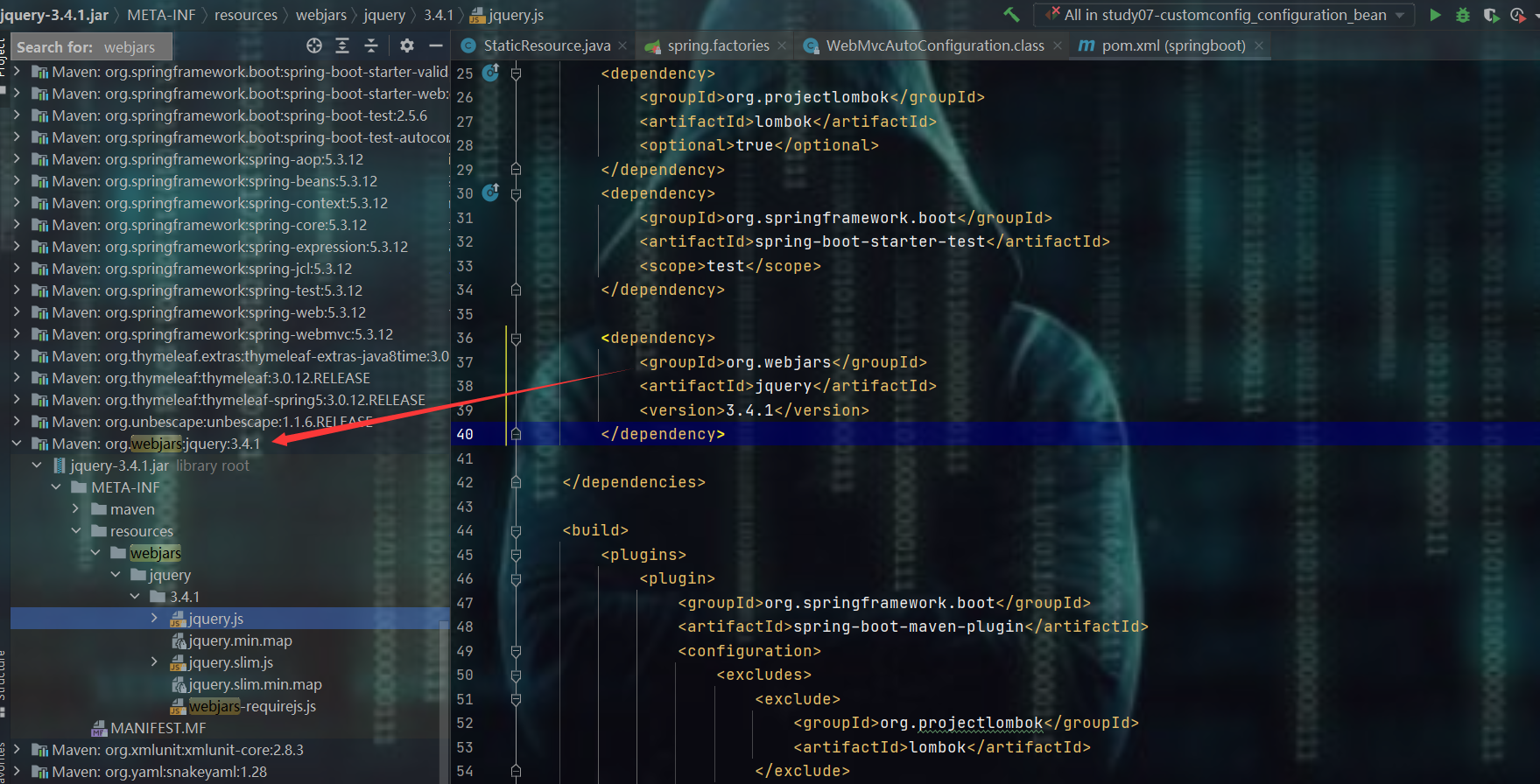
- 导入之后:发现多了这么一个jar包,现在我们去直接访问一下
- 是可以直接访问的,为什么?
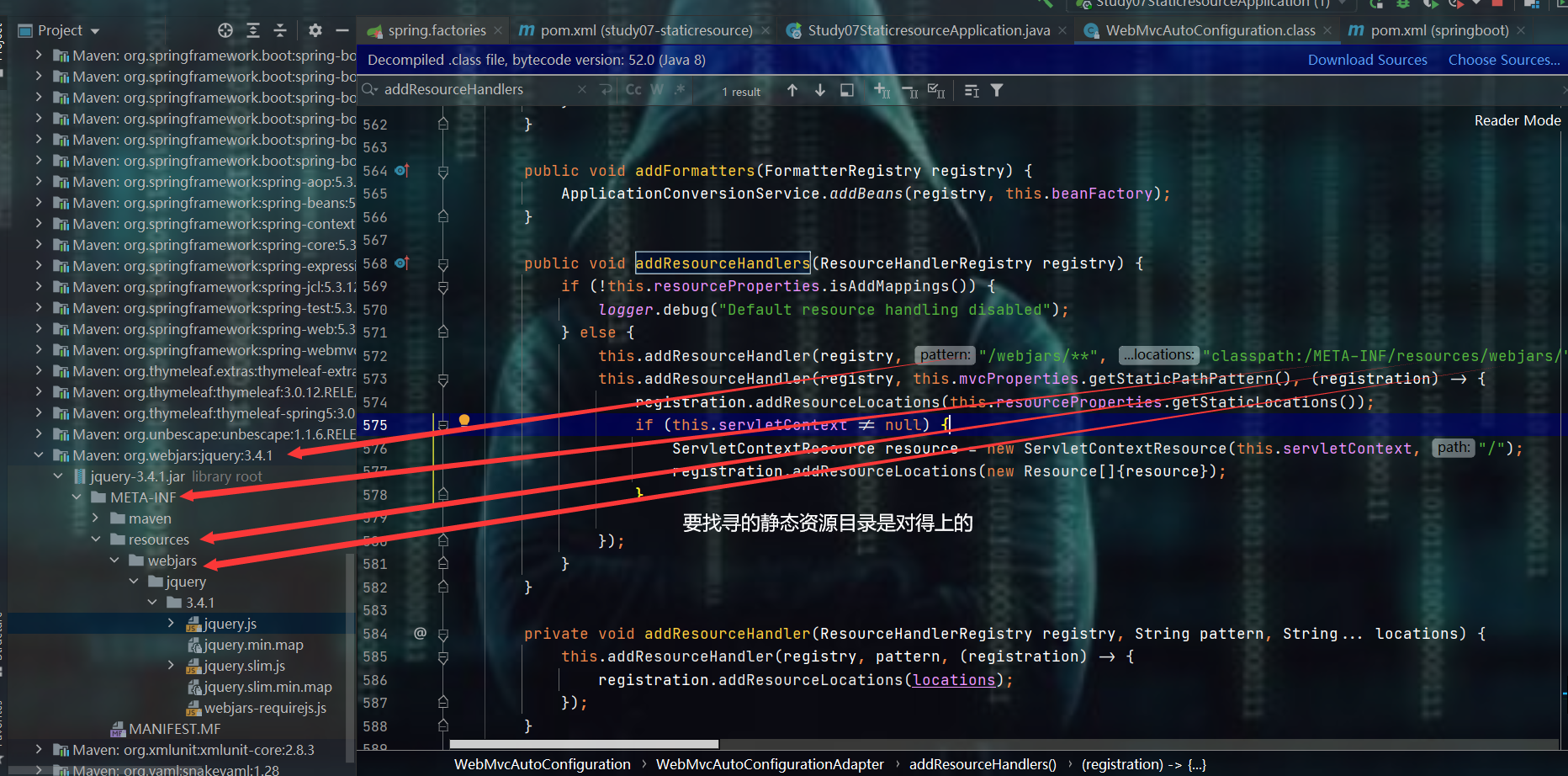
getStaticLocations(),点进去看一下
发现是如下这么一个方法
public String[] getStaticLocations() {
return this.staticLocations;
}
- 查看
staticLocations
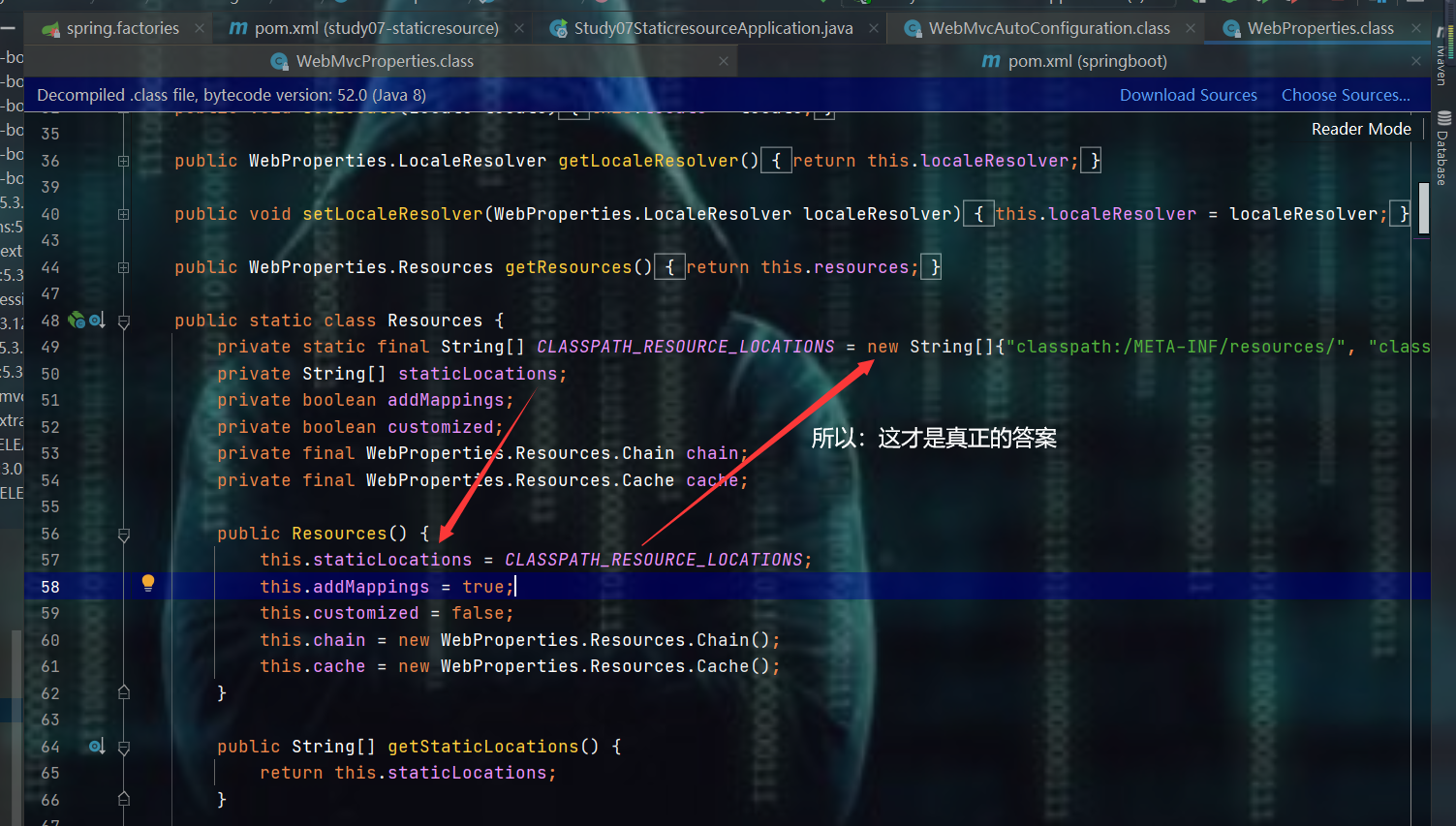
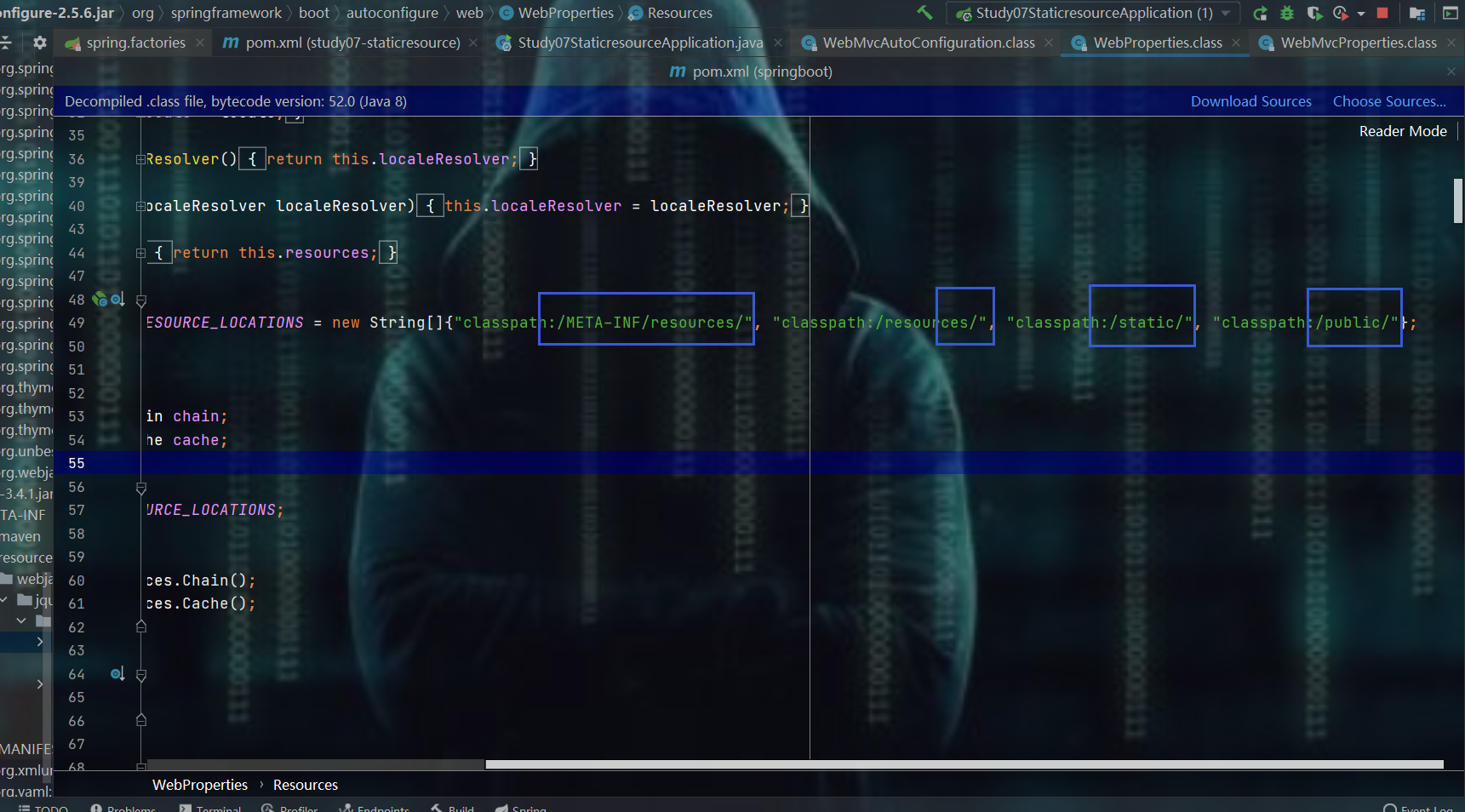
"classpath:/META-INF/resources/", <!--这个就不多说明,前面已经见过这种目录了 -->
"classpath:/resources/",
"classpath:/static/",
"classpath:/public/"
- 发现有四种方式可以放静态资源,那就来测试一下
9.1.1、resources/ static/ public的优先级
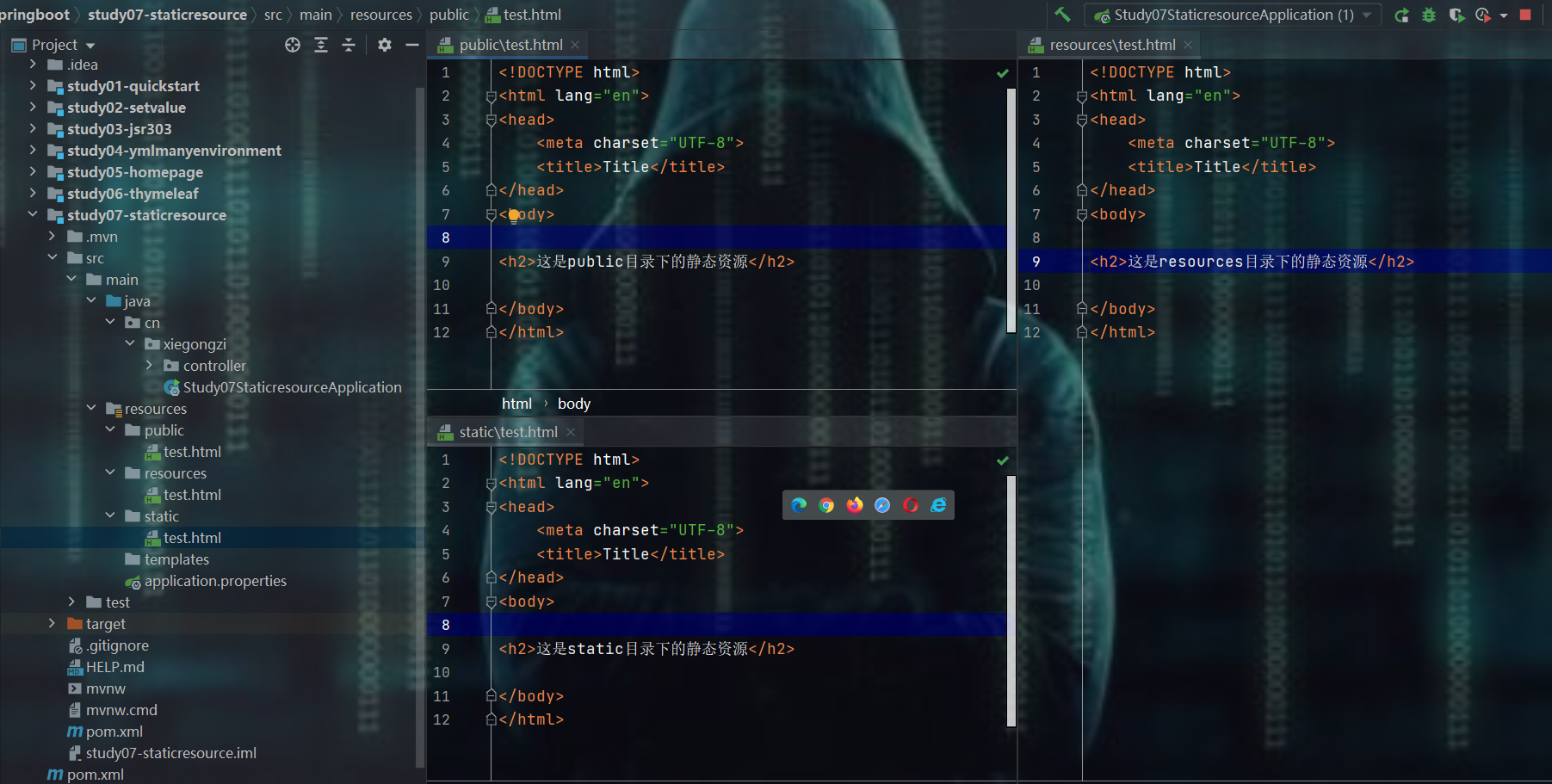
测试
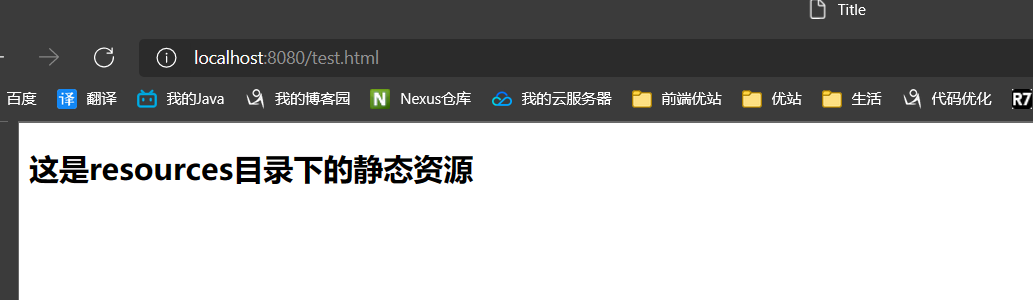
- 发现resources下的优先级最高
删掉resources中的资源文件,继续测试
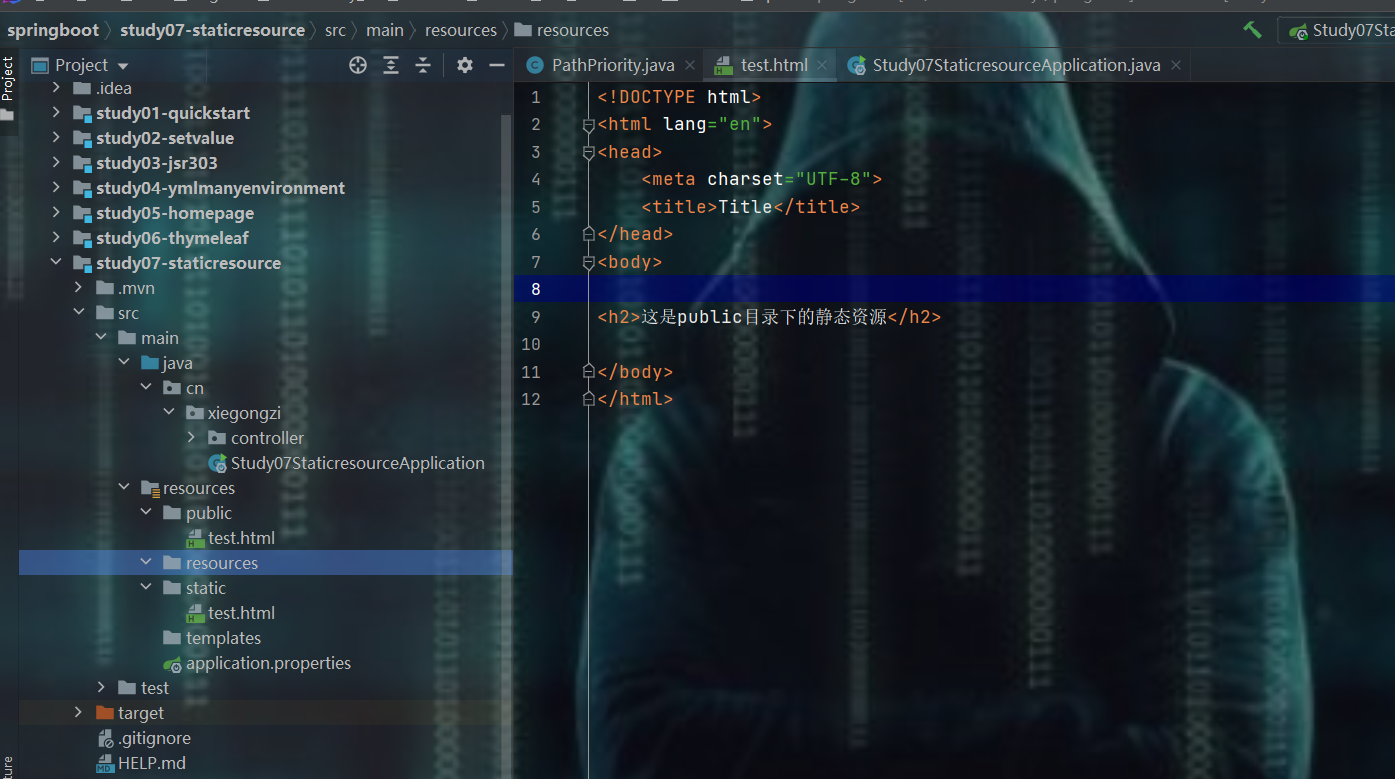
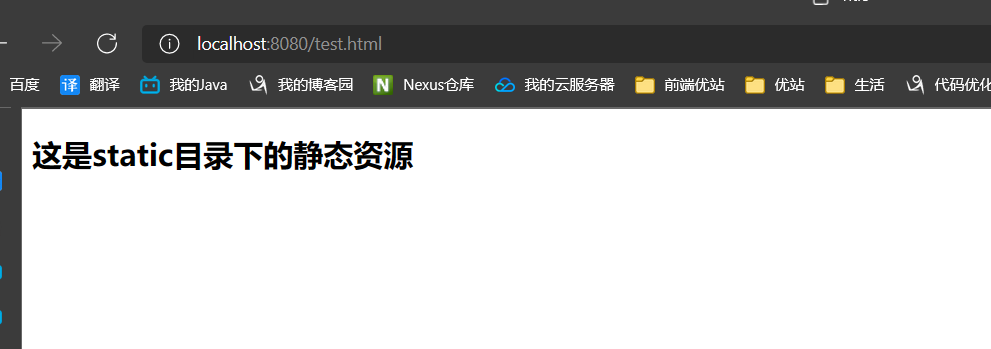
- 发现static目录其次
9.1.1.1、总结:resources、static、public优先级
- resources目录下的优先级最高
- 其次是static
- 最后是public
资源放置建议:
- public放置公有的资源,如:img、js、css....
- static放置静态访问的页面,如:登录、注册....
- resources,应该说是templates,反正我没用过resources这个目录,所以templates放置动态资源,如:用户管理.....
10、整合jdbc、druid、druid实现日志监控
10.1、整合jdbc、druid
依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
编写application.yml
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/mybatis_spring?useUnicode=true&characterEncoding=utf-8
username: root
password: "072413"
测试
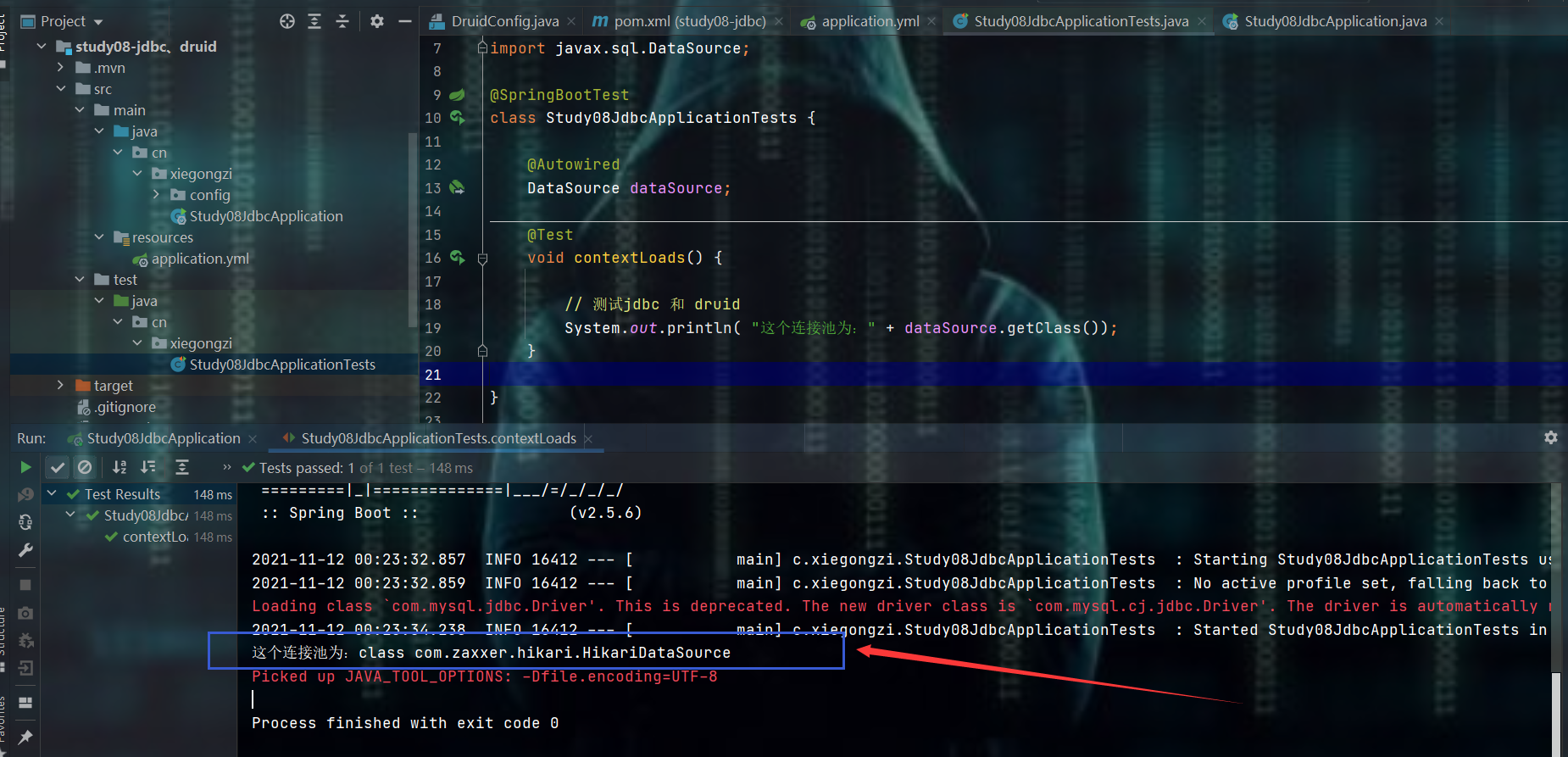
10.2、整合druid
依赖
<!-- 要玩druid的话,需要导入下面这个依赖 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
修改yml文件
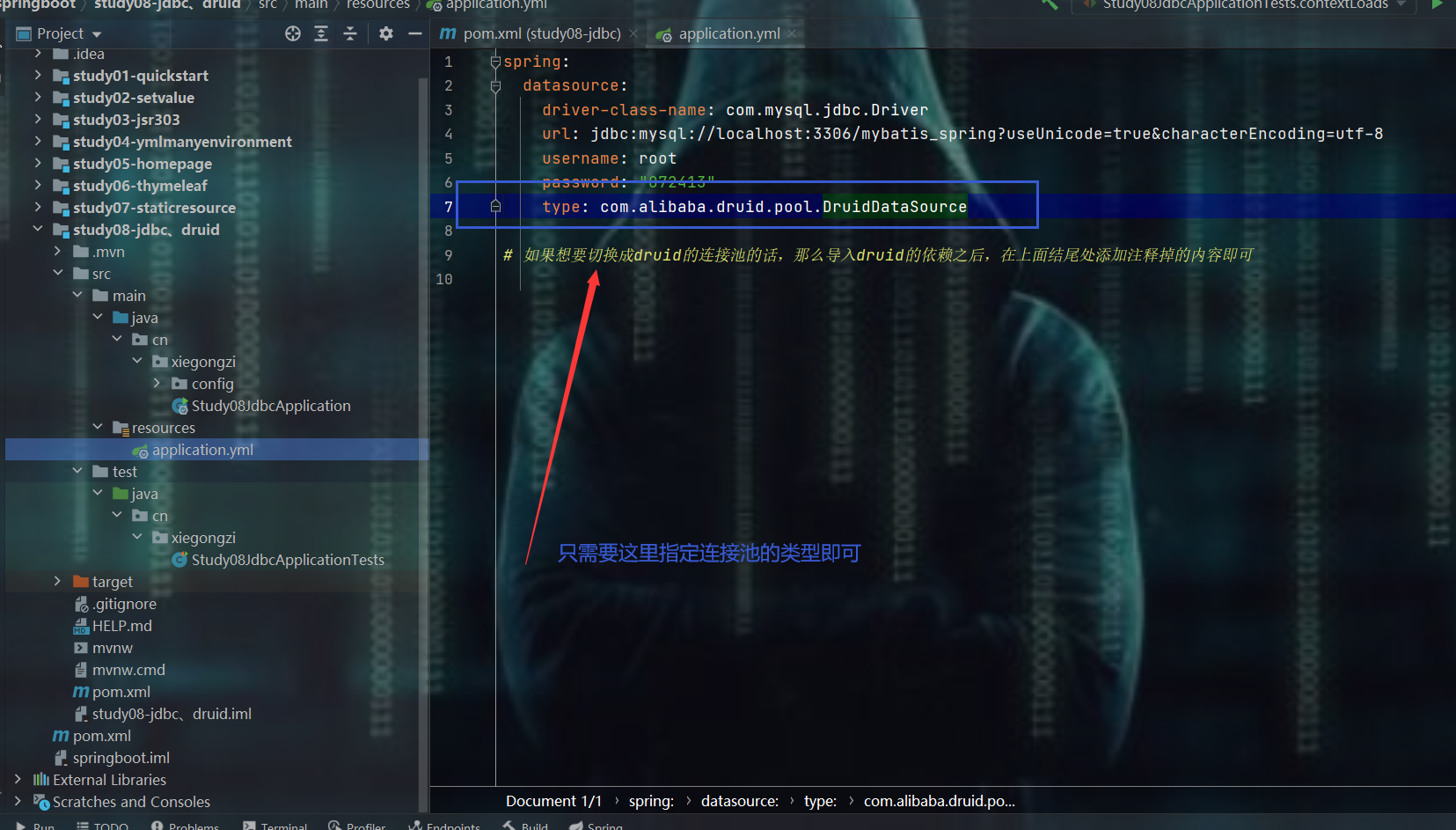
测试
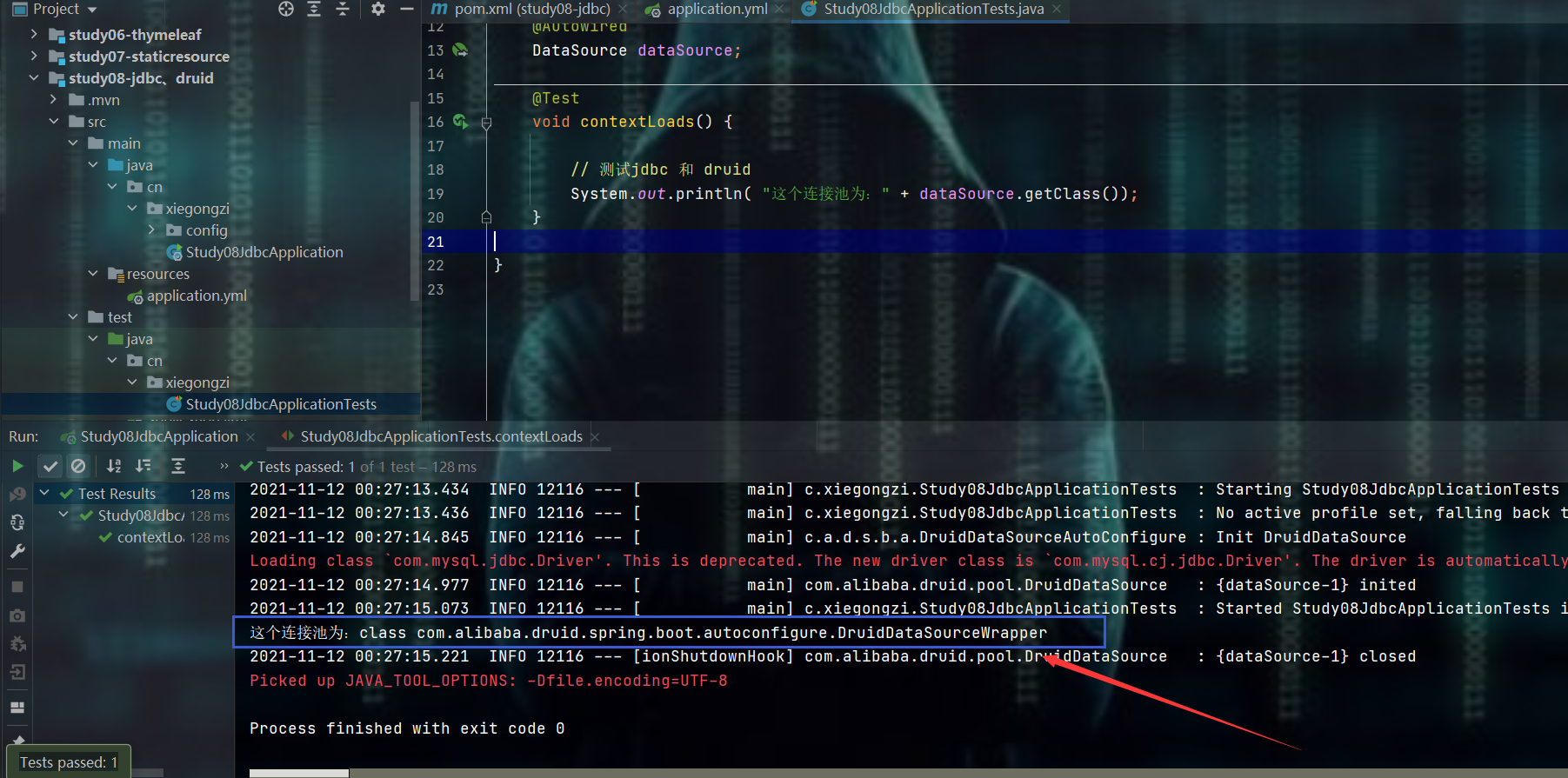
10.3、druid实现日志监控
- 注意点:需要web启动器支持
<!--
玩druid实现监控日志,需要web启动器支持,因为:druid的statViewServlet本质是继承了servlet
因此:需要web的依赖支持 / servlet支持
-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
编写配置
package cn.xiegongzi.config;
// 这个类是为了延伸druid的强大功能 ————— 监控后台
// 注意:这个需要spring的web启动器支持,即:这个监控后台的本质StatViewServlet就是servlet,所以需要servlet支持
import com.alibaba.druid.support.http.StatViewServlet;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
@Configuration
public class DruidConfig {
@Bean
public ServletRegistrationBean StatViewServlet() {
ServletRegistrationBean bean = new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
HashMap<String, String> initParameters = new HashMap<>();
// 下面这些参数可以在 com.alibaba.druid.support.http.StatViewServlet
// 的父类 com.alibaba.druid.support.http.ResourceServlet 中找到
initParameters.put("loginUsername", "zixieqing"); // 登录日志监控的用户名
initParameters.put("loginPassword", "072413"); // 登录密码
initParameters.put("allow", "`localhost`"); // 运行谁可以访问日志监控
bean.setInitParameters(initParameters);
return bean;
}
}
测试
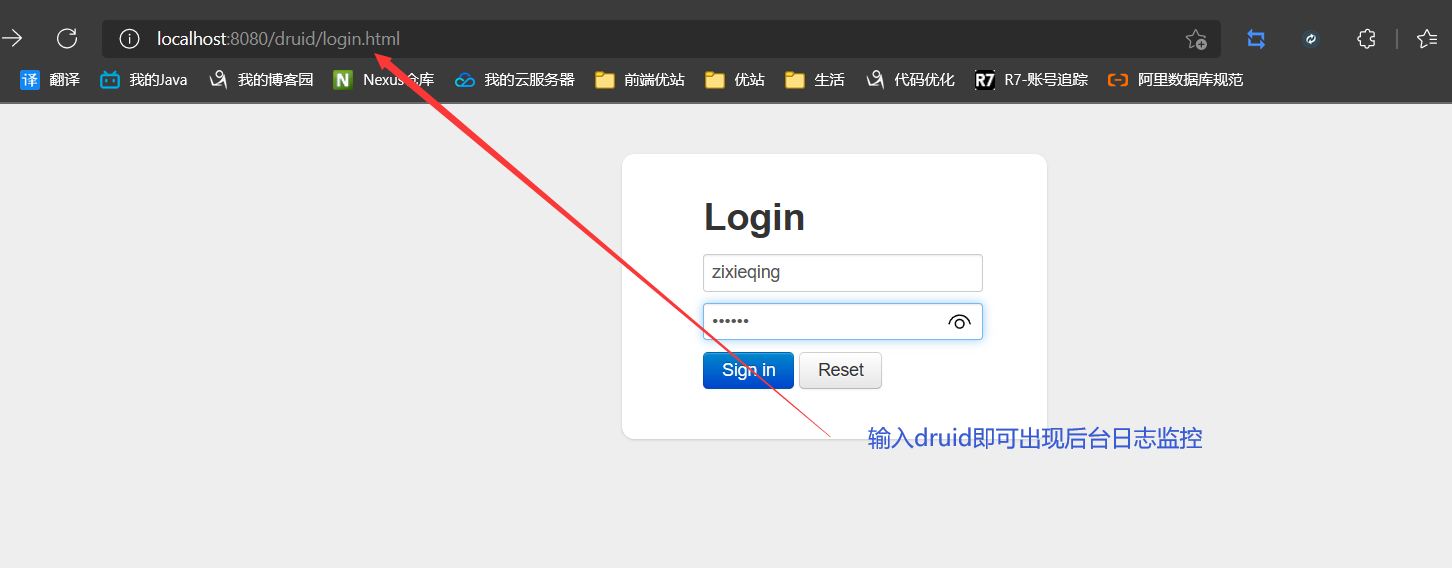
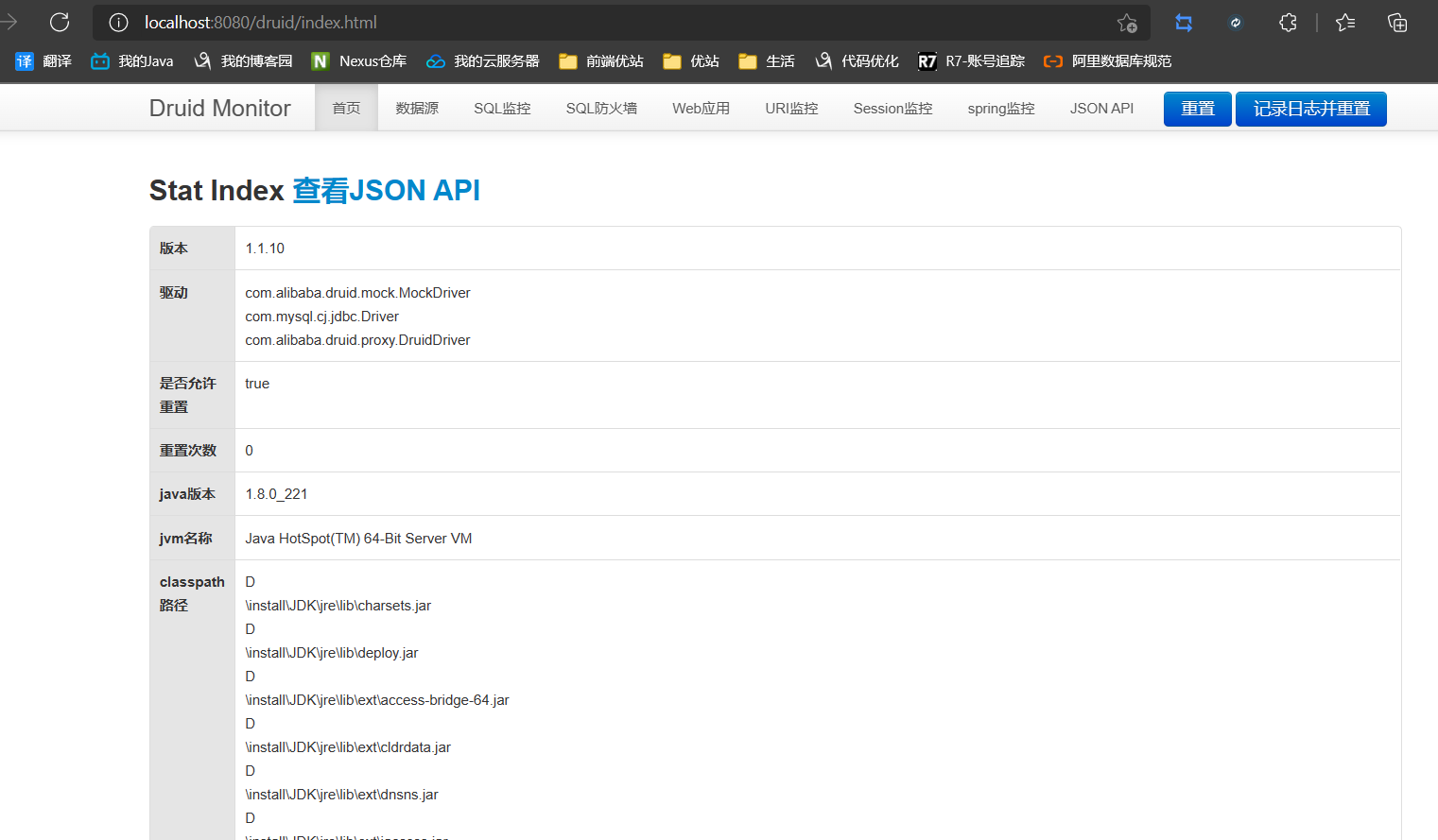
11、整合mybatis
- 注:复杂sql使用xml,简单sql使用注解
11.1、xml版
导入依赖
<!--
mybatis-spring-boot-starter是第三方( mybatis )jar包,不是spring官网的
spring自己的生态是:spring-boot-stater-xxxx
-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
编写实体
package cn.xiegongzi.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User implements Serializable {
private Integer id;
private String username;
private String password;
}
编写dao / mapper层
package cn.xiegongzi.mapper;
import cn.xiegongzi.entity.User;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
/*
* @Mapper 这个注解是mybati-spring提供的,即:和自动装配是一样的效果
* 还可以用:
* @Repository 是spring本身提供的
*
* 以及:在启动类( main )中使用@mapperScan扫包
* */
@Mapper
public interface IUserMapper {
List<User> findALLUser();
}
编写xml的sql语句
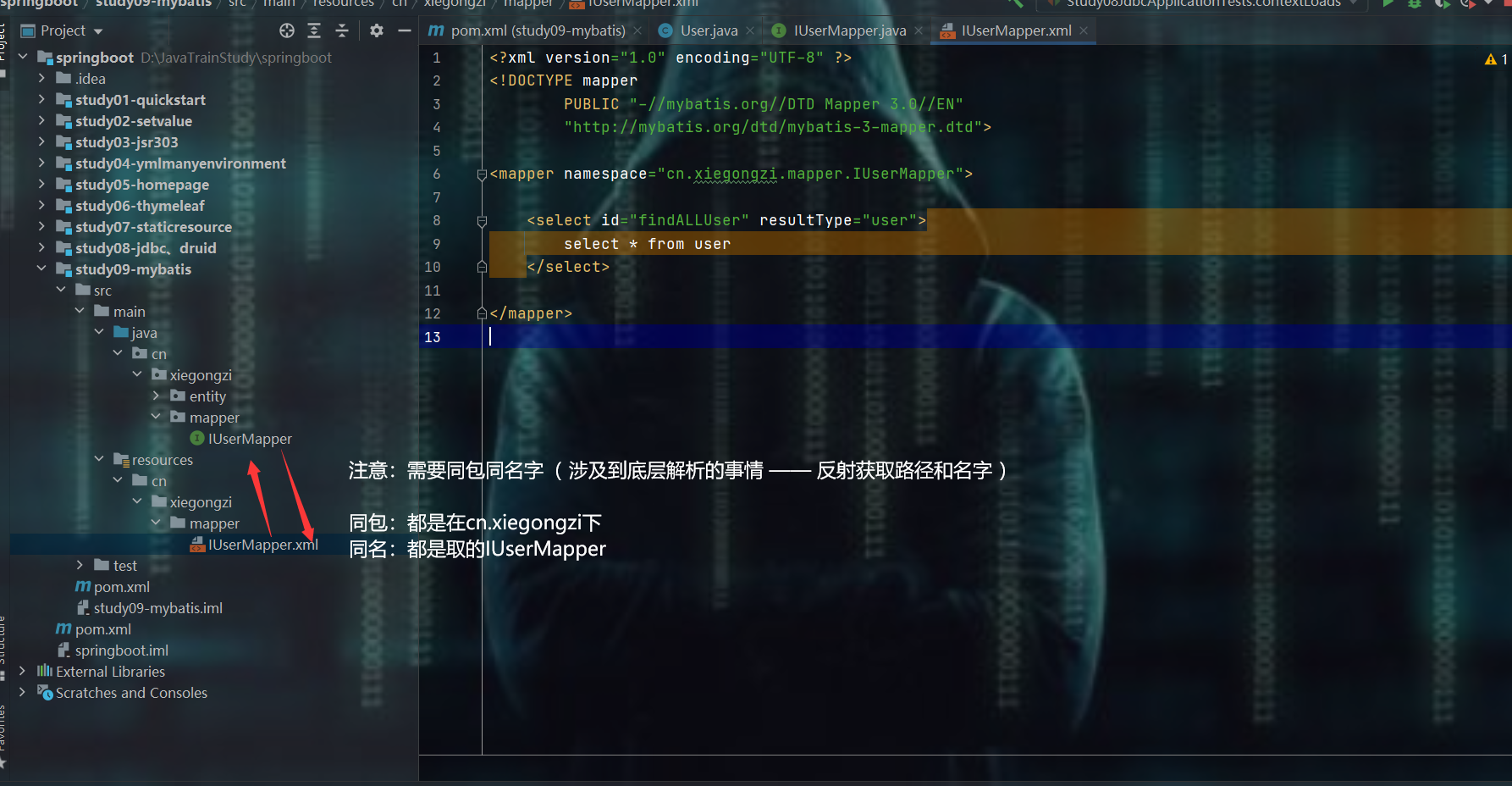
- 注意点:dao层 / mapper和xml的同包同名问题
编写yml
# 编写连接池
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/mybatis_spring?useUnicode=true&characterEncoding=utf-8
username: root
password: "072413"
type: com.alibaba.druid.pool.DruidDataSource
# 把实现类xml文件添加进来
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: cn.xiegongzi.entity # 给实体类配置别名
configuration:
map-underscore-to-camel-case: true # 开启驼峰命名映射
测试
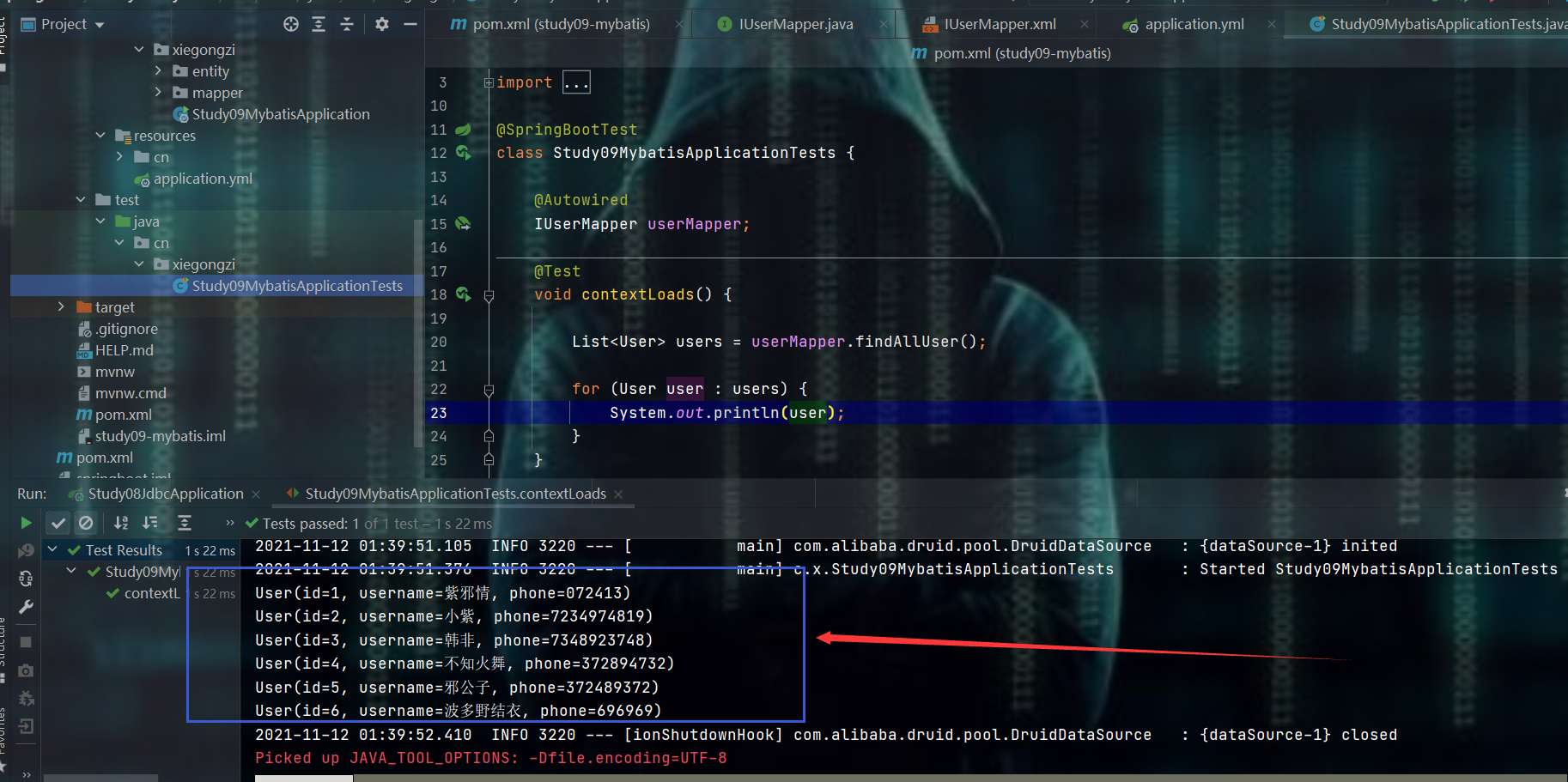
11.2、注解版
- 和ssm整合中的玩法一样,只改动一个地方即可,就是不需要xml了
- 直接在dao层 / mapper的接口方法头上用
@insert()、@delete()、@update()、@select()注解,然后小括号中编写sql字符串即可
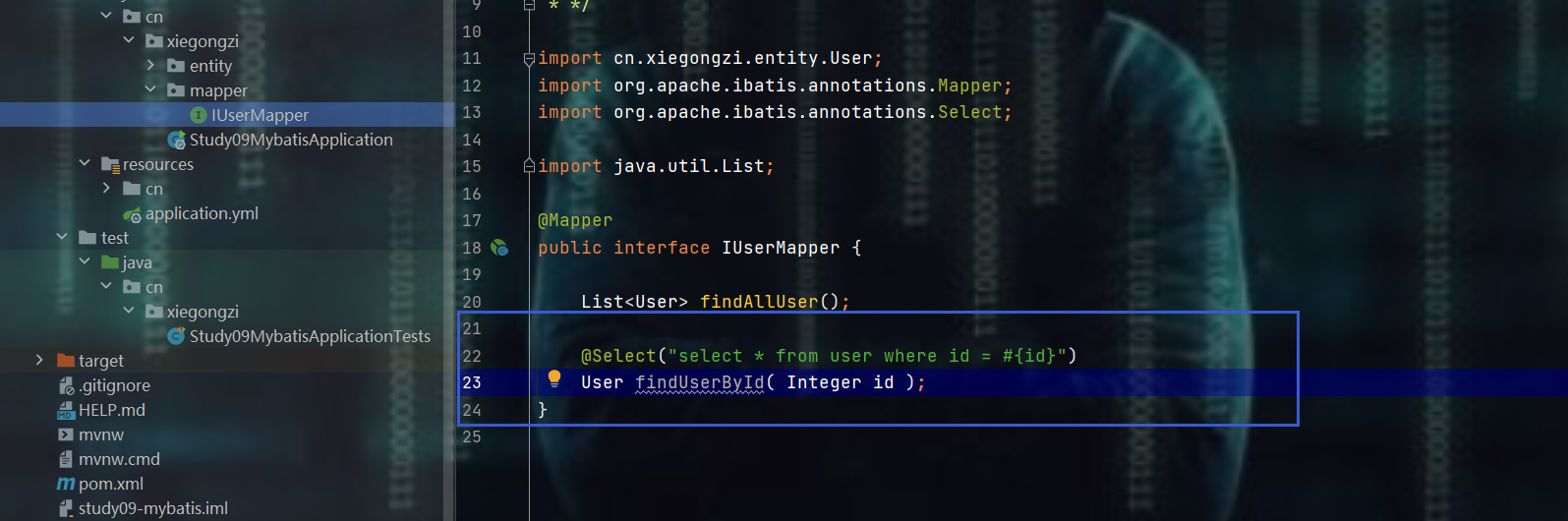
- 当然:也可以给日志设置级别
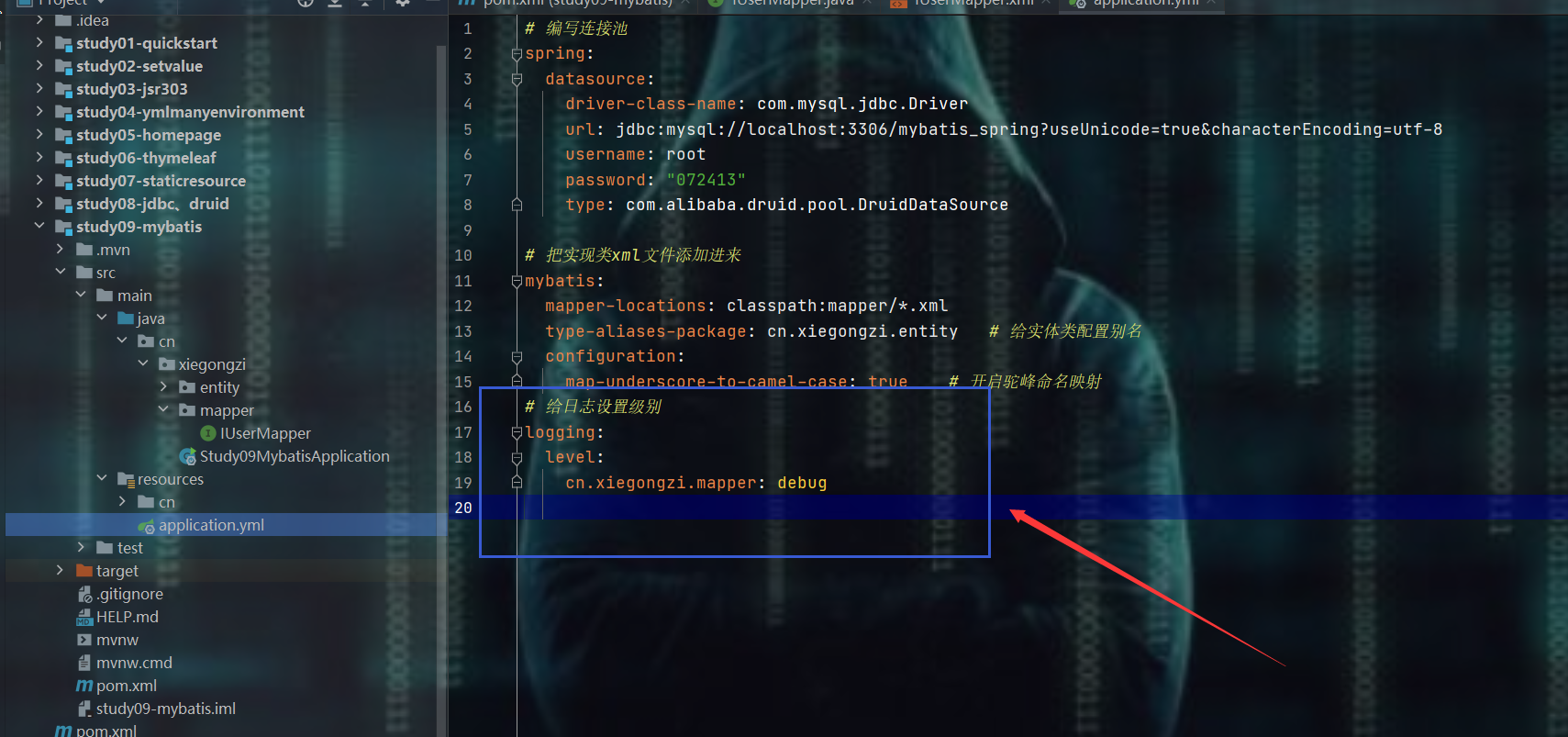
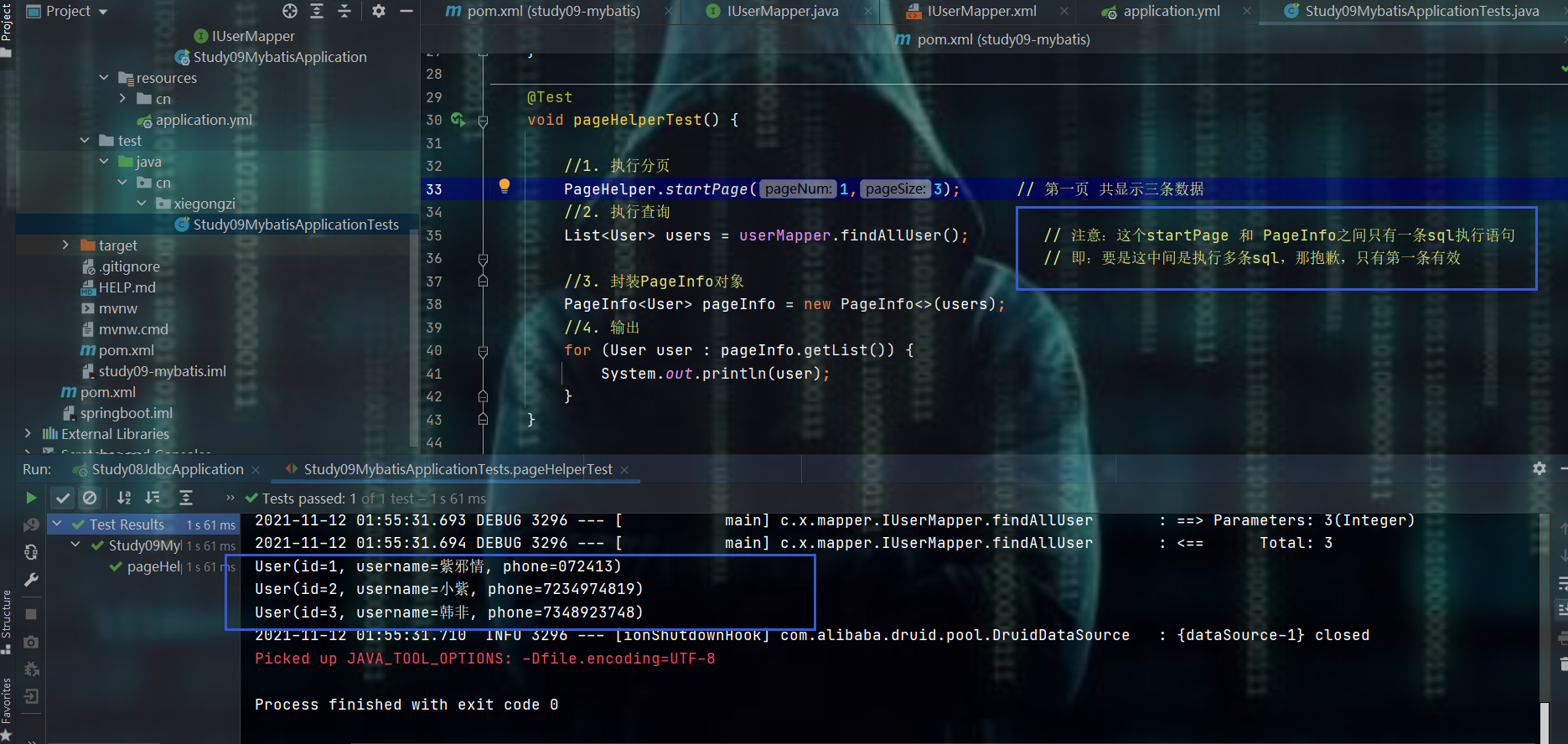
12、整合pageHelper分页插件
依赖
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.2.5</version>
</dependency>
测试
13、集成swagger
- 理论知识滤过,自行百度百科swagger是什么
13.1、快速上手
导入依赖
<!--swagger所需要的依赖-->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.8.0</version>
</dependency>
<!--这个依赖是为了渲染swagger文档页面的( 为了好看一点罢了 ) ,swagger真正的依赖是上面两个-->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>swagger-bootstrap-ui</artifactId>
<version>1.8.5</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
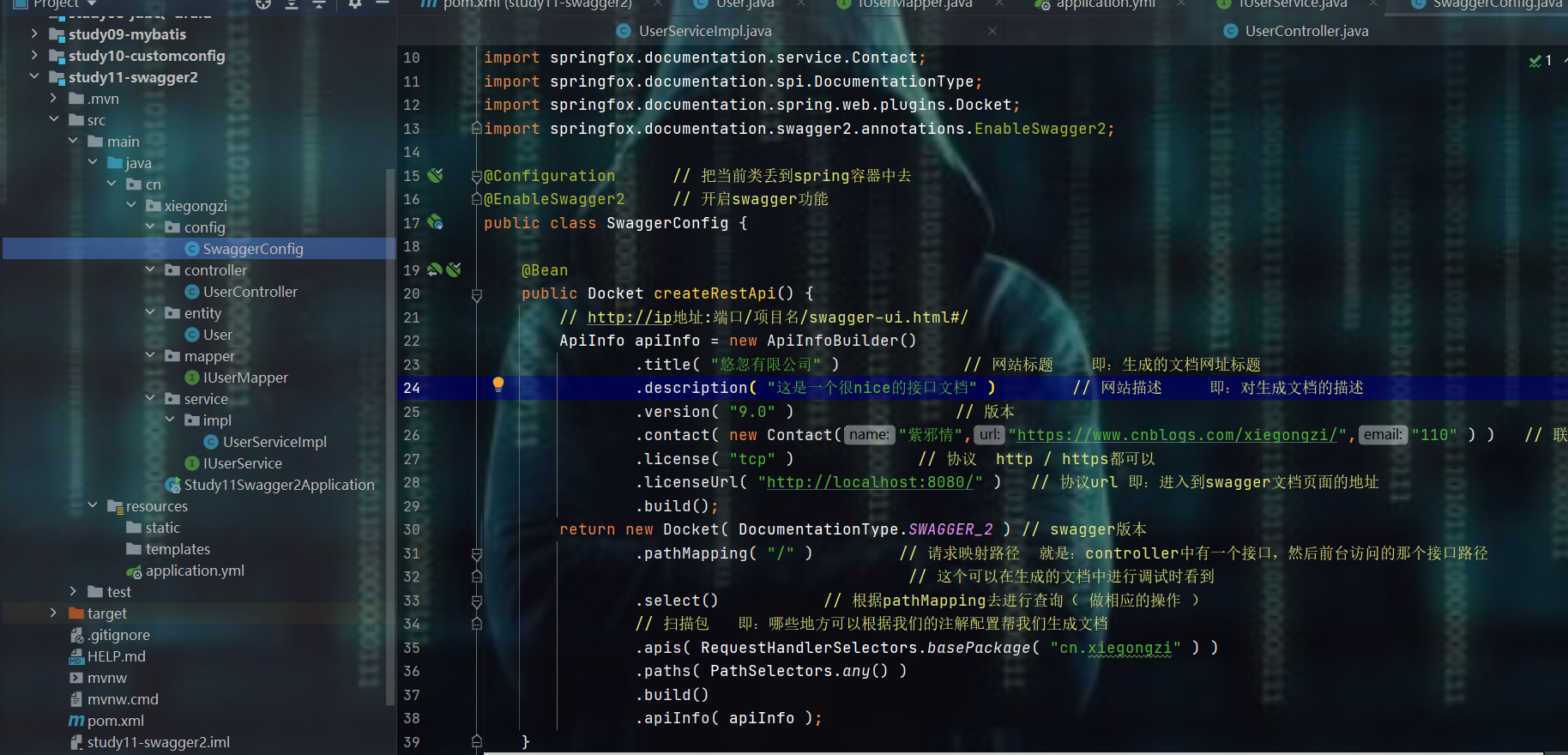
编写swagger配置文件
package cn.xiegongzi.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import springfox.documentation.builders.ApiInfoBuilder;
import springfox.documentation.builders.PathSelectors;
import springfox.documentation.builders.RequestHandlerSelectors;
import springfox.documentation.service.ApiInfo;
import springfox.documentation.service.Contact;
import springfox.documentation.spi.DocumentationType;
import springfox.documentation.spring.web.plugins.Docket;
import springfox.documentation.swagger2.annotations.EnableSwagger2;
@Configuration // 把当前类丢到spring容器中去
@EnableSwagger2 // 开启swagger功能
public class SwaggerConfig {
@Bean
public Docket createRestApi() {
// http://ip地址:端口/项目名/swagger-ui.html#/
ApiInfo apiInfo = new ApiInfoBuilder()
// 网站标题 即:生成的文档网址标题
.title( "悠忽有限公司" )
// 网站描述 即:对生成文档的描述
.description( "这是一个很nice的接口文档" )
// 版本
.version( "9.0" )
// 联系人
.contact( new Contact("紫邪情","https://www.cnblogs.com/xiegongzi/","110" ) )
// 协议 http / https都可以
.license( "tcp" )
// 协议url 即:进入到swagger文档页面的地址
.licenseUrl( "http://localhost:8080/" )
.build();
// swagger版本
return new Docket( DocumentationType.SWAGGER_2 )
// 请求映射路径 就是:controller中有一个接口,然后前台访问的那个接口路径
// 这个可以在生成的文档中进行调试时看到
.pathMapping( "/" )
// 根据pathMapping去进行查询( 做相应的操作 )
.select()
// 扫描包 即:哪些地方可以根据我们的注解配置帮我们生成文档
.apis( RequestHandlerSelectors.basePackage( "cn.xiegongzi" ) )
.paths( PathSelectors.any() )
.build()
.apiInfo( apiInfo );
}
}
编写yml文件
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver # 注意这里加了cj啊
url: jdbc:mysql://localhost:3306/mybatis_spring?useUnicode=true&characterEncoding=utf-8
username: root
password: "072413"
编写实体类
package cn.xiegongzi.entity;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
@ApiModel // 表明这个实体类也可以生成到swagger文档中去 即:后台要接收的参数是一个对象时使用 —— 这个东西可以先不加,在做增加、修改时可以用这个测试一下,从而去swagger中看效果
public class User implements Serializable {
@ApiModelProperty // 表明:要生成的实体类属性是注解下的这个
private Integer id;
@ApiModelProperty
private String username;
@ApiModelProperty
private String phone;
}
编写mapper
package cn.xiegongzi.mapper;
import cn.xiegongzi.entity.User;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
@Mapper
public interface IUserMapper {
@Select("select * from user")
List<User> findAllUser();
}
编写service接口和实现类
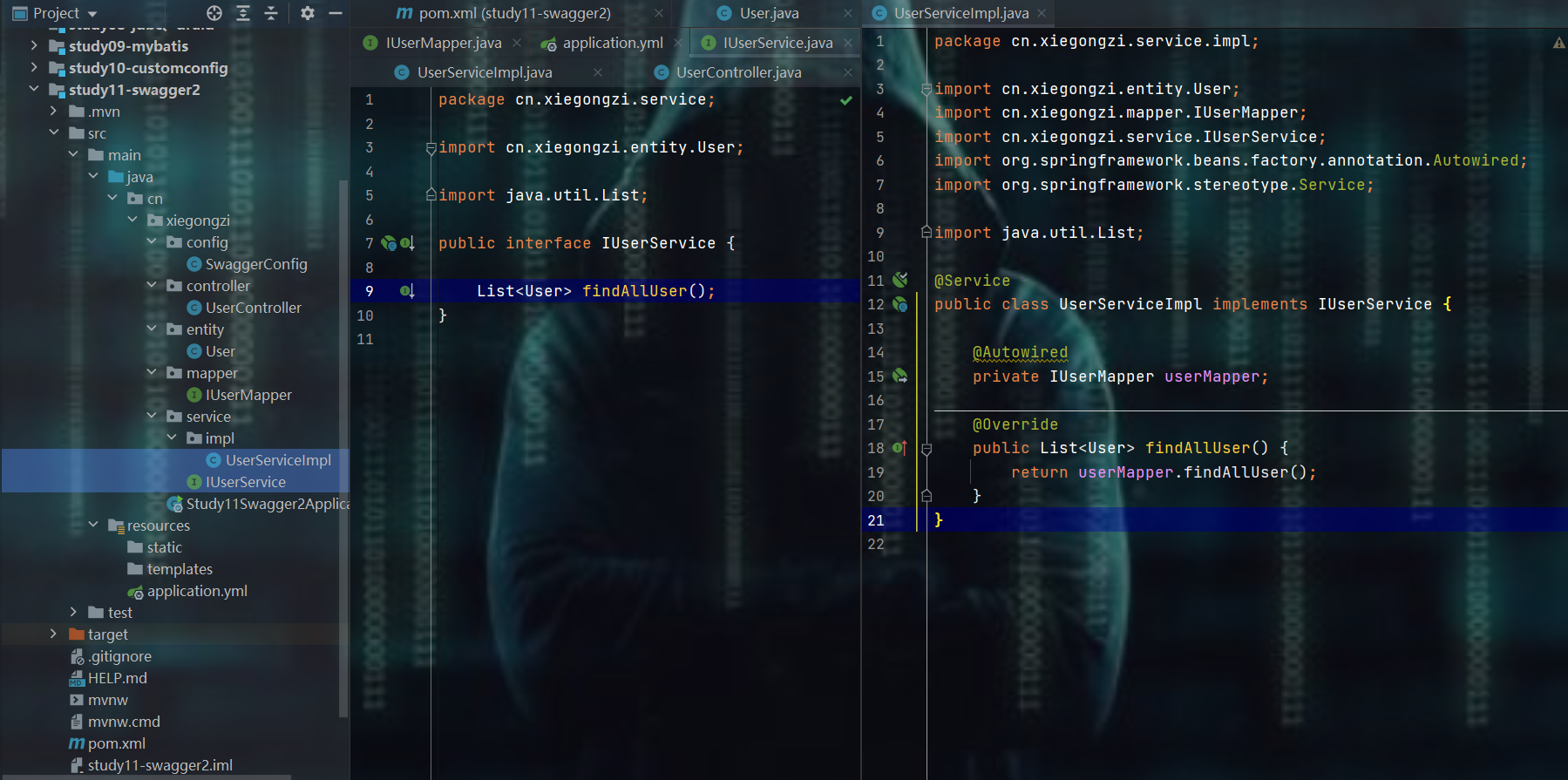
编写controller
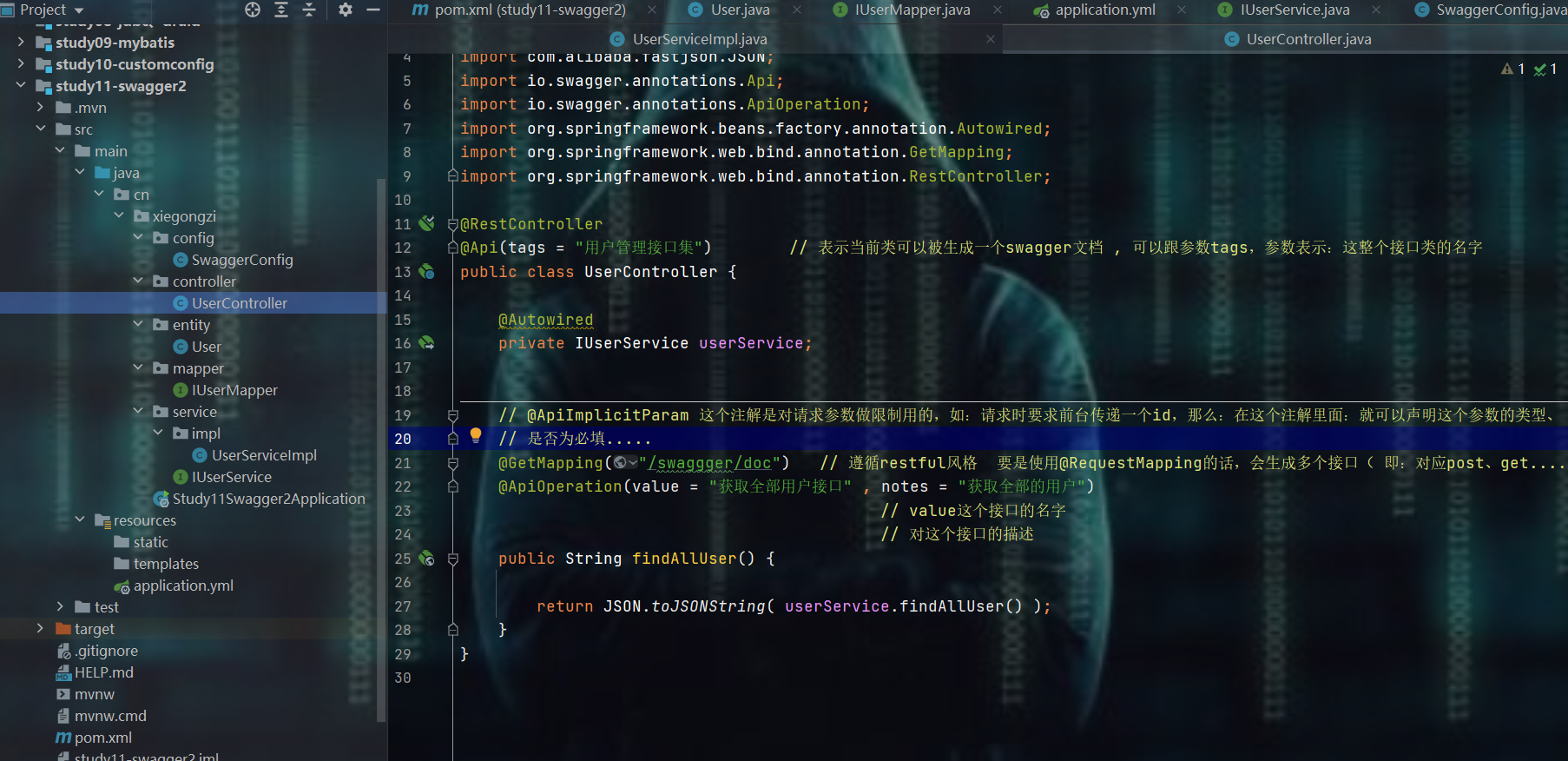
package cn.xiegongzi.controller;
import cn.xiegongzi.service.IUserService;
import com.alibaba.fastjson.JSON;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@Api(tags = "用户管理接口集") // 表示当前类可以被生成一个swagger文档 , 可以跟参数tags,参数表示:这整个接口类的名字
public class UserController {
@Autowired
private IUserService userService;
// @ApiImplicitParam 这个注解是对请求参数做限制用的,如:请求时要求前台传递一个id,那么:在这个注解里面:就可以声明这个参数的类型、
// 是否为必填.....
@GetMapping("/swaggger/doc") // 遵循restful风格 要是使用@RequestMapping的话,会生成多个接口( 即:对应post、get.... )
@ApiOperation(value = "获取全部用户接口" , notes = "获取全部的用户")
// value这个接口的名字
// 对这个接口的描述
public String findAllUser() {
return JSON.toJSONString( userService.findAllUser() );
}
}
测试
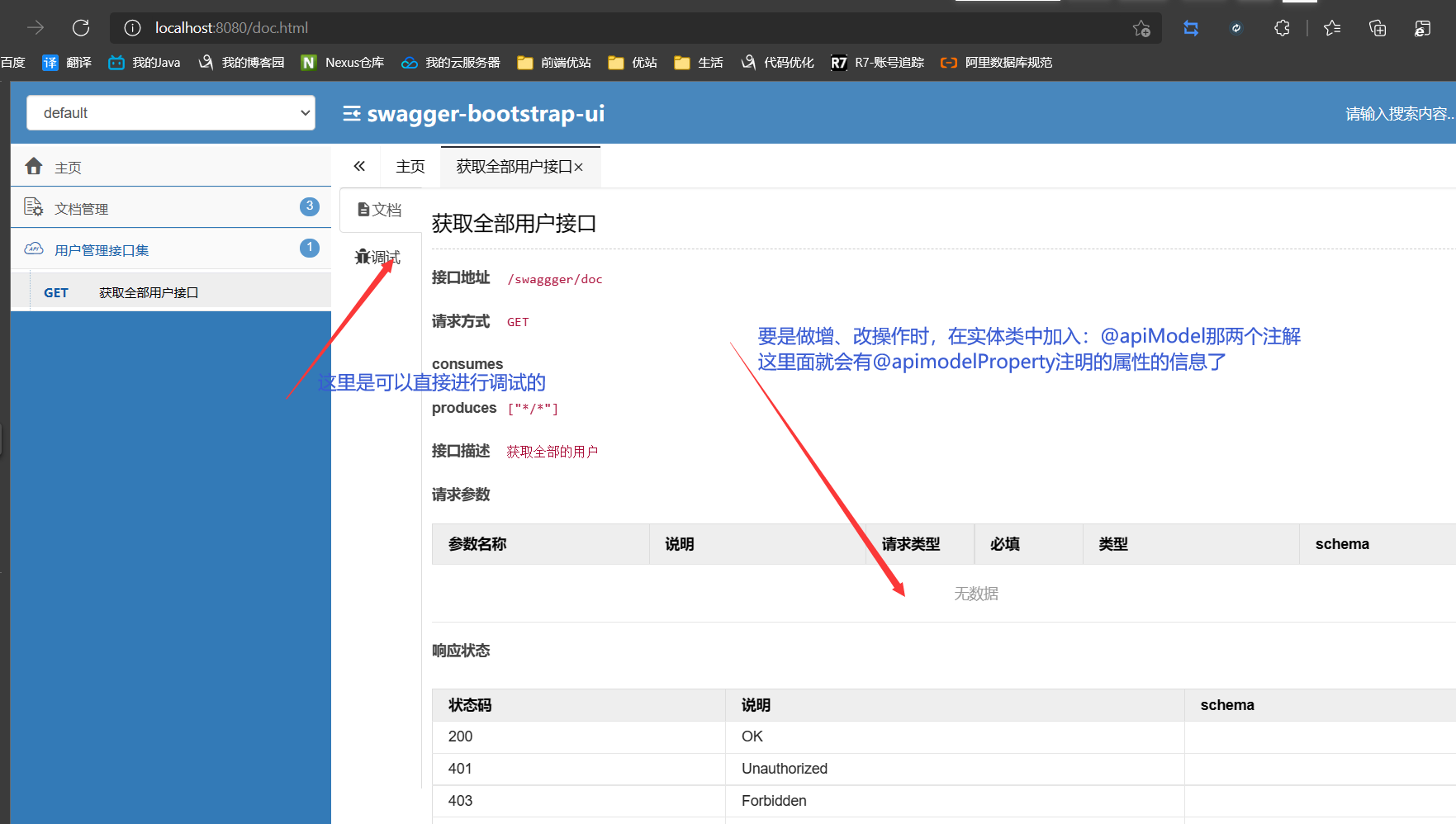
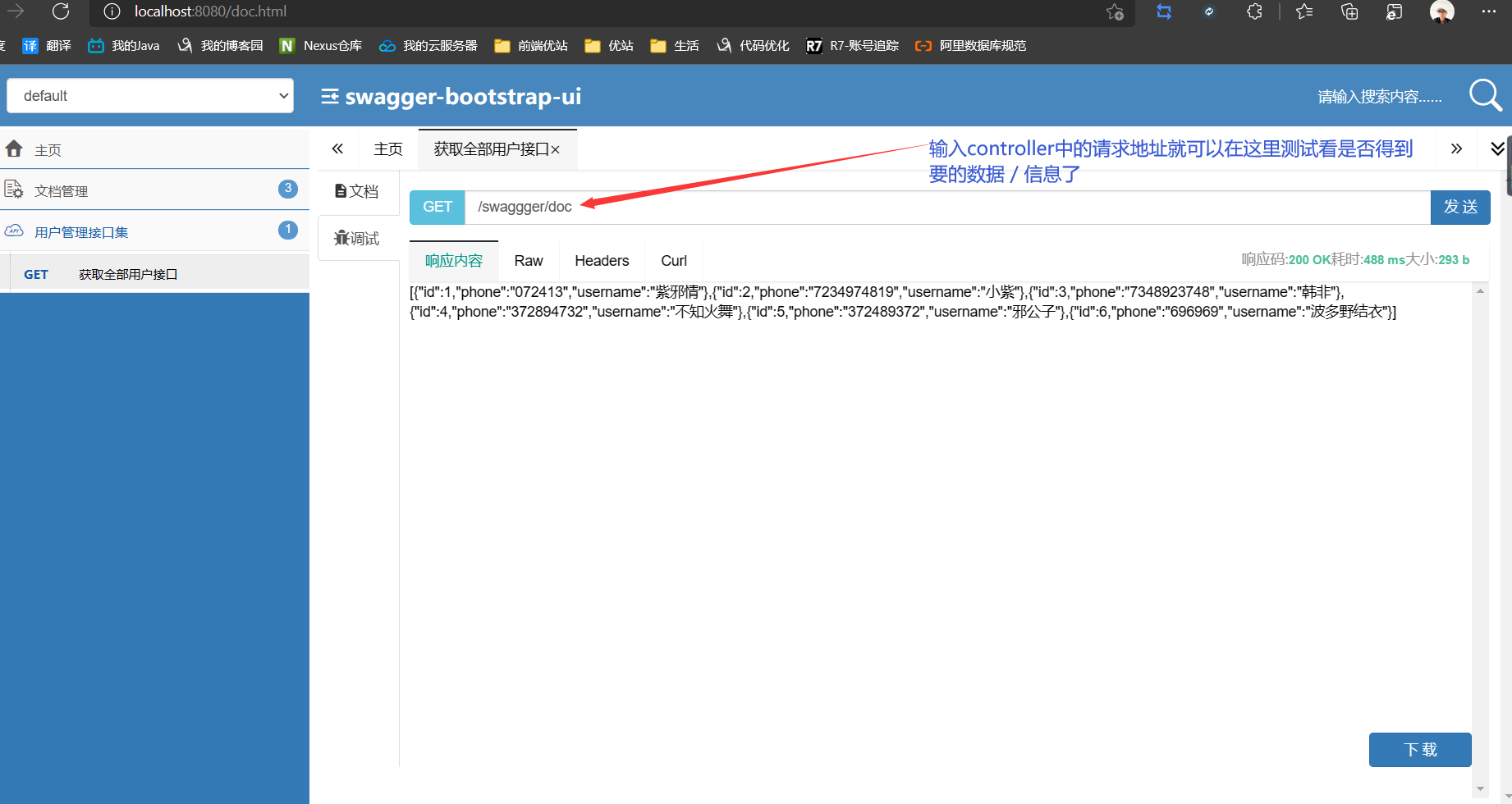
13.2、结语
- 以上的内容是入门,其他的注解开发时自行摸索吧!
- 还有一种,比swagger更好,就是:ApiPost / ApiPost,自行下载安装包,安装之后玩一下
- 另外swagger的常见注释使用和解读网址:http://c.biancheng.net/view/5533.html
14、集成JPA
数据库表字段信息
导入依赖
<!-- 导入jpa需要的依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- 项目需要的依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
编写yml文件
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/mybatis_spring?useUnicode=true&characterEncoding=utf-8
username: root
password: "072413"
jpa:
# 这里可以不用hibernate,还可以用hikari( 这个在前面整合jdbc时见过,就是当时输出的那句话 )
hibernate:
# 指定为update,每次启动项目检测表结构有变化的时候会新增字段,表不存在时会新建表
ddl-auto: update
# 如果指定create,则每次启动项目都会清空数据并删除表,再新建
# 这里面还可以跟:create-drop/create/none
naming:
# 指定jpa的自动表生成策略,驼峰自动映射为下划线格式
implicit-strategy: org.hibernate.boot.model.naming.ImplicitNamingStrategyLegacyJpaImpl # 默认就是这个
# physical-strategy: org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
# 注掉的这种是:不用驼峰名字,直接把实体类的大写字母变小写就完了
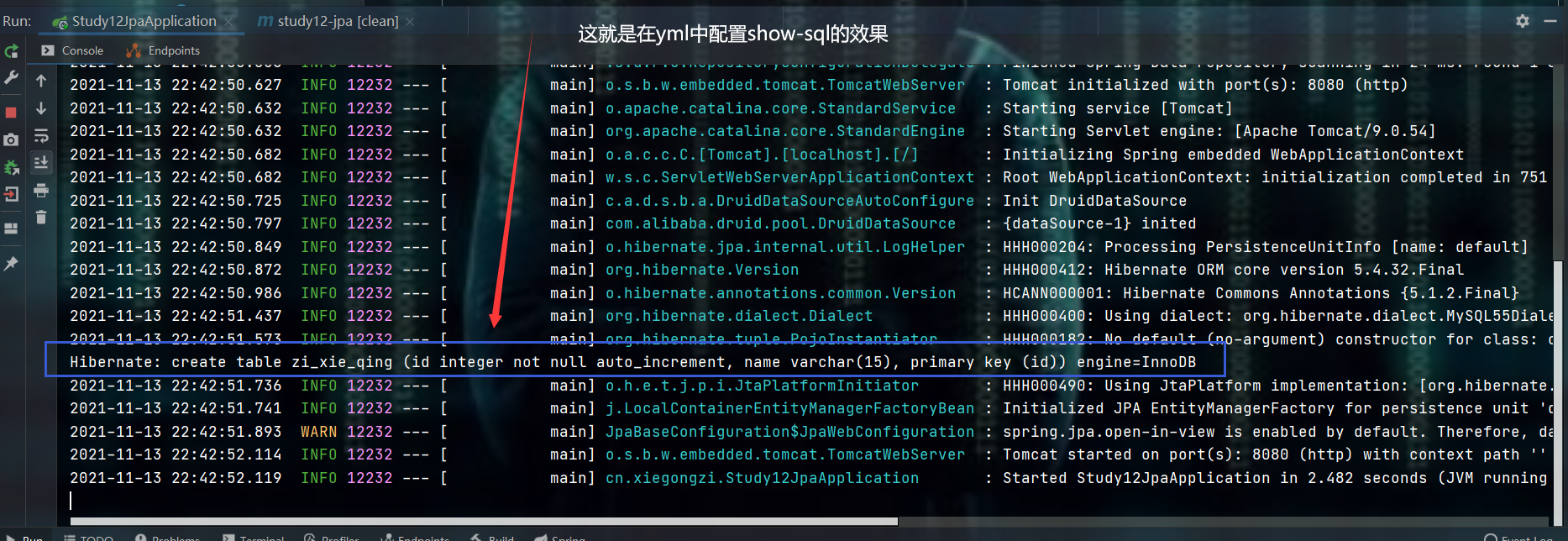
show-sql: true # 在控制台显示sql语句( 不是真的sql语句,而是相当于:说明 ),默认是false
# 使用INNODB引擎
properties.hibernate.dialect: org.hibernate.dialect.MySQL55Dialect
database-platform: org.hibernate.dialect.MySQL55Dialect
# 使用JPA创建表时,默认使用的存储引擎是MyISAM,通过指定数据库版本,可以使用InnoDB
编写实体类
package cn.xiegongzi.entity;
import lombok.Data;
import org.springframework.data.annotation.Id;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import java.io.Serializable;
@Data
// @AllArgsConstructor
// @NoArgsConstructor
@Entity // 表明:当前类和数据库中的这个同类名的数据库表形成ORM映射关系
// 要是数据库中没有这个表,那么:根据yml配置的ddl-auto: update 就会自动帮我们生成
// 注:
public class ZiXieQing implements Serializable {
@javax.persistence.Id
@Id // 表明这个属性是数据库表中的主键
@GeneratedValue(strategy = GenerationType.IDENTITY) // 表示:自增 默认是auto,即:和数据库中的auto_increment是一样的
private int id;
@Column( length = 15 ) // 生成数据库中的列字段,里面的参数不止这些,还可以用其他的,对应数据库列字段的那些操作
// 可以点进源码看一下
private String name;
// public ZiXieQing() {
// }
public ZiXieQing(int id, String name) {
this.id = id;
this.name = name;
}
}
附:@Column注解中可以支持的属性
@Target({ElementType.METHOD, ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface Column {
String name() default "";
boolean unique() default false;
boolean nullable() default true;
boolean insertable() default true;
boolean updatable() default true;
String columnDefinition() default "";
String table() default "";
int length() default 255;
int precision() default 0;
int scale() default 0;
}
编写mapper
package cn.xiegongzi.mapper;
import cn.xiegongzi.entity.ZiXieQing;
import org.springframework.data.jpa.repository.JpaRepository;
@Component // 注:这里别用@Mapper这个注解,因为:@mapper是mybatis提供的注解
// JpaRepository相对mybatis来说就是是外部的东西。因此:并不能支持@mapper注解
// @Repository 当然使用这个spring自带的注解也行 @Configuration 这个注解更可以了
public interface ZiXieQingMapper extends JpaRepository<ZiXieQing , Integer> {
// JpaRepository这里面有默认的一些方法,即:增删查改...
// JpaRepository<ZiXieQing , Integer> 本来样子是:JpaRepository<T , ID>
// T 表示:自己编写的实体类 类型
// ID 表示: 实体类中id字段的类型 注:本示例中,实体类中id是int 因为要弄自增就必须为int,不然和数据库映射时对不上
}
附:JpaRepository中提供的方法
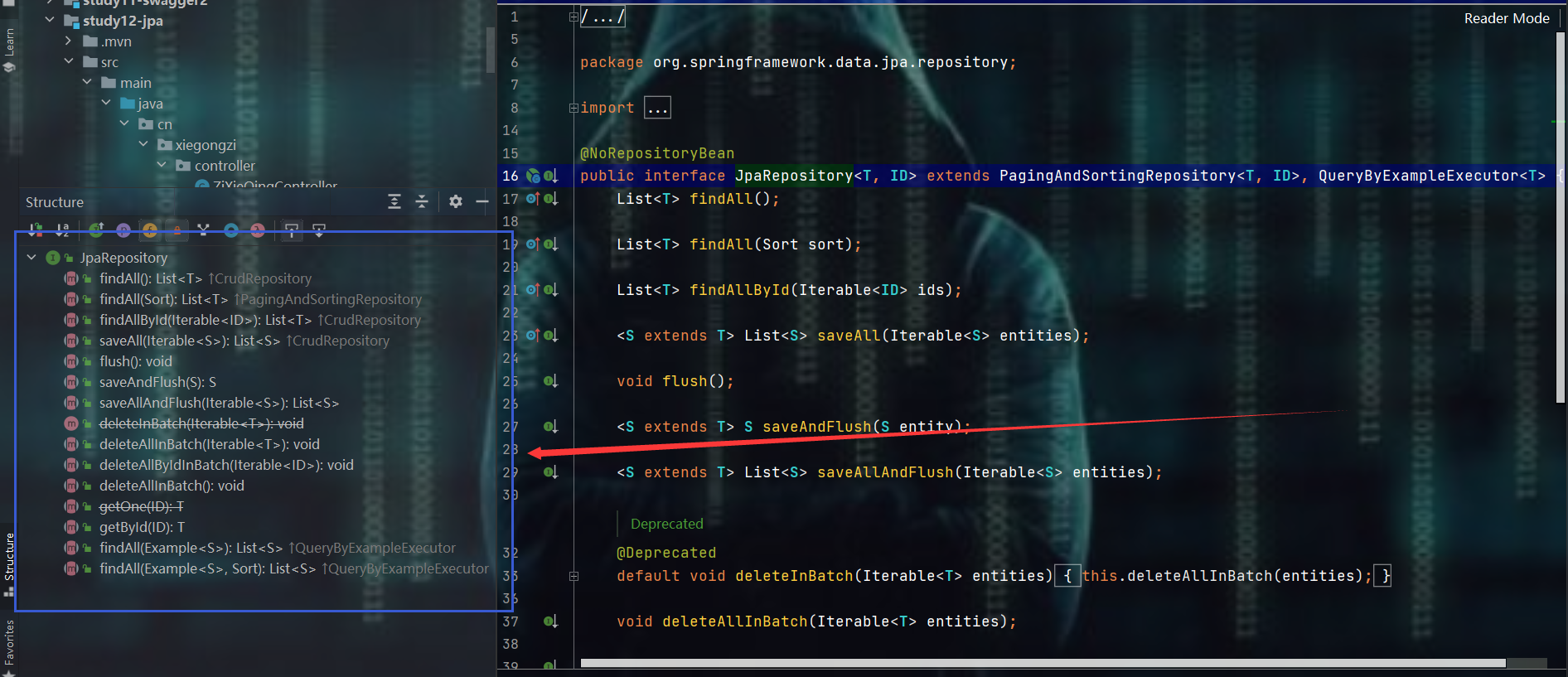
编写service接口和实现类
编写controller
测试
现在去看一下数据库
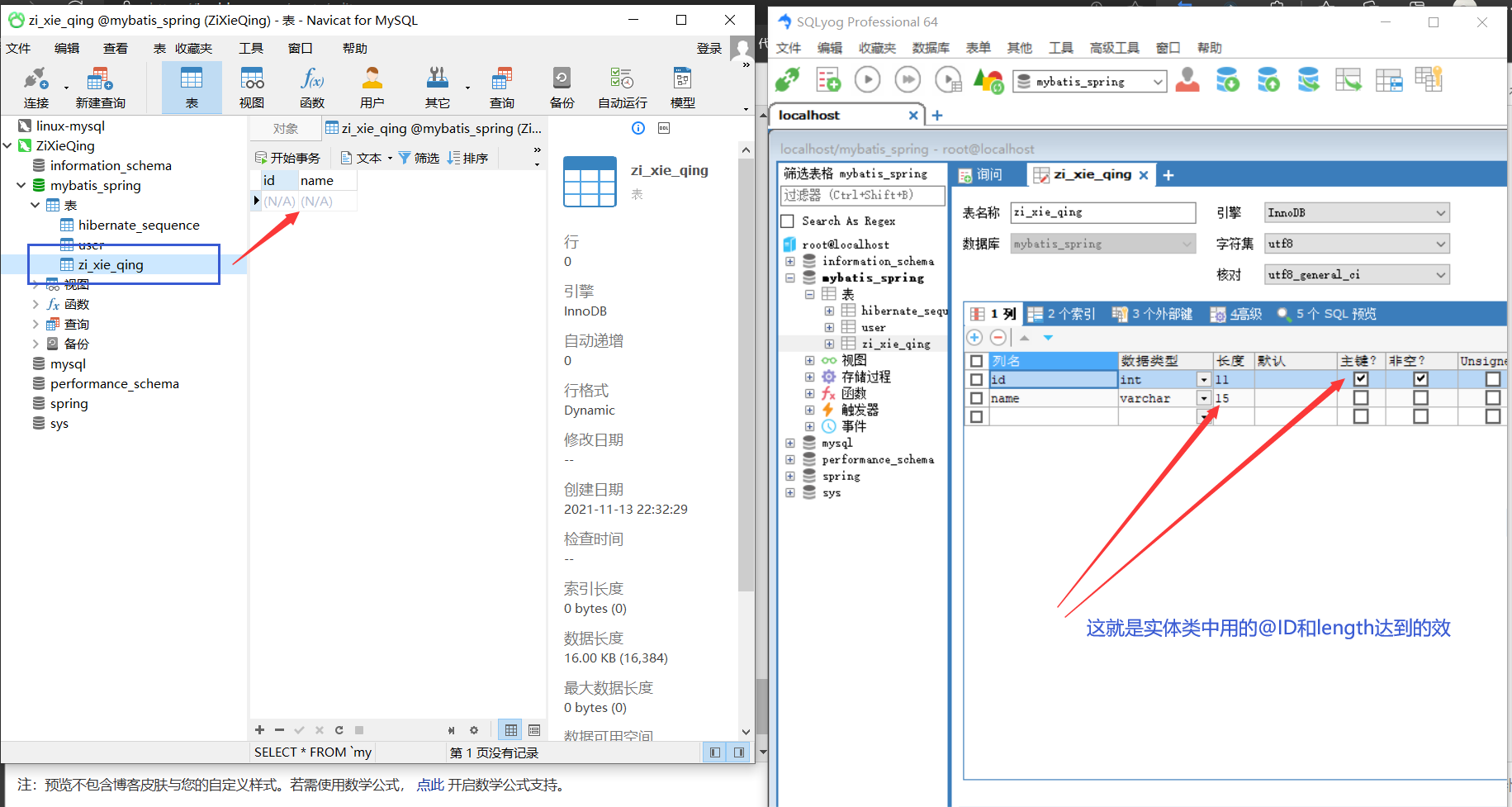
生成出来了,完成
15、集成mybatis-plus
- mybatis-plus官网地址:https://baomidou.com/guide/
导入依赖
<!--mybatis-plus需要的依赖-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
编写yml
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/mybatis_spring?useUnicode=true&characterEncoding=utf-8
username: root
password: "072413"
type: com.alibaba.druid.pool.DruidDataSource
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # mybatis-plus配置日志
map-underscore-to-camel-case: true # 开启驼峰映射 即:实体类属性名和数据库字段采用驼峰映射
auto-mapping-behavior: full # 自动映射字段
mapper-locations: classpath:mapper/*.xml # 如果使用了mybatis和mybatis-plus 那么这里就可以把mybatis的实现类xml集成进来
# 但是:最好别这种做,用了mybatis就别用mybatis-plus,二者最好只用其一
注:别把mybatis和mybatis-plus一起集成到spring中,否则:很容易出问题,虽然:mybatis-plus是mybatis的增强版,既然是增强版,那么就不会抛弃它原有的东西,只会保留原有的东西,然后新增功能,但是:mybatis和mybatis-plus集成到一起之后很容易造成版本冲突,因此:建议二者只选其一集成 ( PS:当然事情不是绝对的 我说的是万一,只是操作不当很容易触发错误而已,但是:二者一起集成也是可以的,当出现报错时可以解决掉,不延伸了 ,这不是这里该做的事情 )
编写实体类
package cn.xiegongzi.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName(value = "user") // 表名注解
public class User implements Serializable {
@TableId(type = IdType.AUTO) // 表示主键,这个主键是一个Long类型的值( 即:snowflake雪花算法 )
private Integer id;
@TableField("username") // 数据库字段名 就是:当实体类中的字段和数据库字段不一样时可以使用
private String name;
private String phone;
}
编写mapper
package cn.xiegongzi.mapper;
import cn.xiegongzi.entity.User;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.apache.ibatis.annotations.Mapper;
// @Component
// @Configuration
// 注:这个对象托管,我测试过了,只有两种方法可以做到 即:上面这两个注解无法实现,测试时会报错
@Mapper // @MapperScan("cn.xiegongzi.mapper") 在启动类中加入这个注解也可以实现
public interface IUserMapper extends BaseMapper<User> {
// BaseMapper 和 JPA一样,内部有很多方法 , 即:CRUD.....,还有分页( 分页就是page()这个方法 )
// BaseMapper原来的样子是:BaseMapper<T> T表示实体类 类型
}
注意点:别用@Component和@Configuration这两个注解实现对象托管,会报错:错误如下
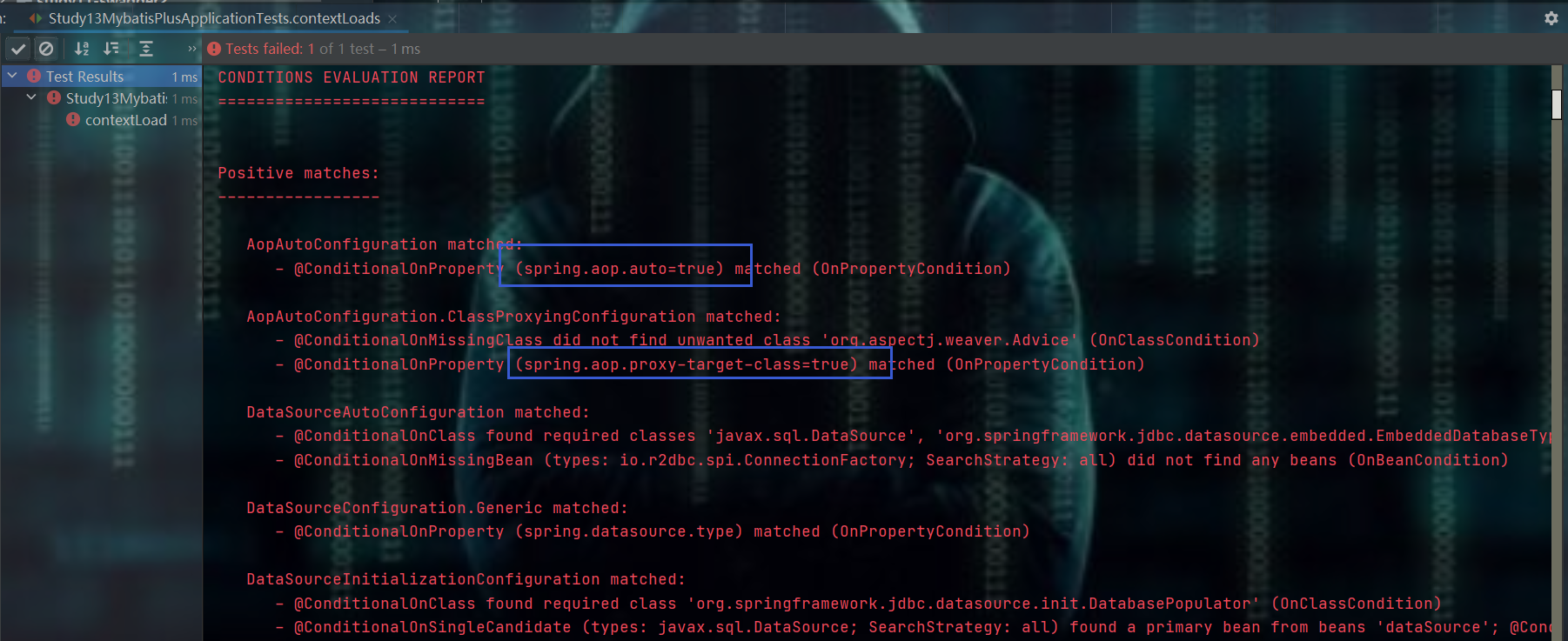
报的错很多,总之一句话就是:导入的依赖没有导入,即:依赖我已经导入了,但是:报我没有相应的依赖,我得出的理由:mybatis / mybatis-plus相对spring来说是外部的,因此:使用spring的@Component和@Configuration注解来实现对象托管,mybatis并不买账,只能用它自己的注解才可以
附:BaseMapper<T>提供的方法如下:
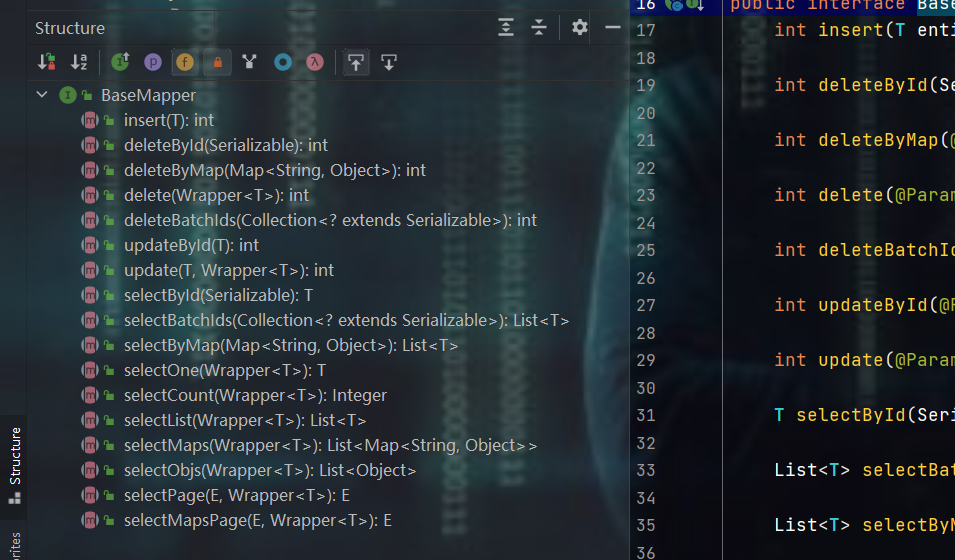
测试
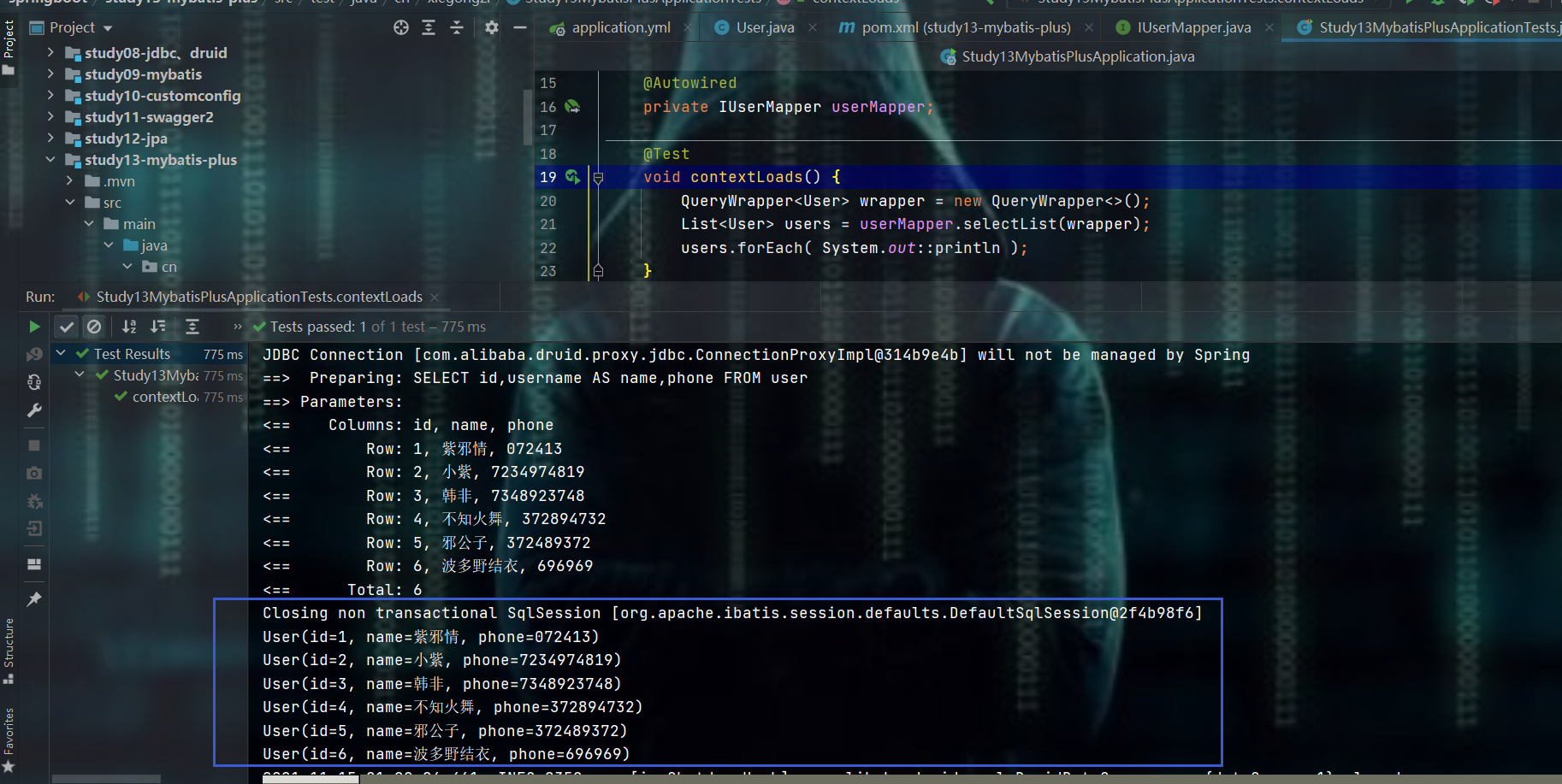
其他的知识,在mybatis-plus官网中都有
15、分布式本地缓存技术ehcache
- 还有一种比较流行的是
Caffeine这个东西要更简单一点,而且不需要借助xml文件,而ehcache需要借助xml文件
15.1、Ehcache介绍
- Ehacahe是一个比较成熟的Java缓存框架,最早从hibernate发展而来,是进程中的缓存系统,它提供了用内存、磁盘文件存储,以及分布式存储方式等多种灵活的cache管理方案
15.2、ehcache常用注解
15.2.1、@CacheConfig注解
- 用于标准在类上,可以存放该类中所有缓存的公有属性( 如:设置缓存名字 )
@CacheConfig(cacheNames = "users")
public class UserService{
}
- 当然:这个注解其实可以使用
@Cacheable来代替
15.2.2、@Cacheable注解( 读数据时 ) - 用得最多
- 应用到读取数据的方法上,如:查找数据的方法,使用了之后可以做到先从本地缓存中读取数据,若是没有在调用此注解下的方法去数据库中读取数据,当然:还可以将数据库中读取的数据放到用此注解配置的指定缓存中
@Cacheable(value = "user", key = "#userId")
User selectUserById( Integer userId );
@Cacheable注解的属性
- value、cacheNames
- 这两个参数其实是等同的( cacheNames为Spring 4新增的,作为value的别名 )
- 这两个属性的作用:用于指定缓存存储的集合名
- key
- 作用:缓存对象存储在Map集合中的key值
- condition
- 作用:缓存对象的条件,即:只有满足这里面配置的表达式条件的内容才会被缓存,如:@Cache( key = "#userId",condition="#userId.length() < 3" 这个表达式表示只有当userId长度小于3的时候才会被缓存
- unless
- 作用:另外一个缓存条件,它不同于condition参数的地方在于此属性的判断时机( 此注解中编写的条件时在函数被
调用之后才做判断,所以:这个属性可以通过封装的result进行判断 )
- 作用:另外一个缓存条件,它不同于condition参数的地方在于此属性的判断时机( 此注解中编写的条件时在函数被
- keyGenerator
- 作用:用于指定key生成器,若需要绑定一个自定义的key生成器,我们需要去实现
org.springframewart.cahce.intercceptor.KeyGenerator接口,并使用改参数来绑定 - 注意点:改参数与上面的key属性是互斥的
- 作用:用于指定key生成器,若需要绑定一个自定义的key生成器,我们需要去实现
- cacheManager
- 作用:指定使用哪个缓存管理器,也就是当有多个缓存器时才需要使用
- cacheResolver
- 作用:指定使用哪个缓存解析器
- 需要通过
org.springframewaork.cache.interceptor.CacheResolver接口来实现自己的缓存解析器
15.2.3、@CachePut注解 ( 写数据时 )
- 用在
写数据的方法上,如:新增 / 修改方法,调用方法时会自动把对应的数据放入缓存,@CachePut的参数和@Cacheable差不多
@CachePut(value="user", key = "#userId")
public User save(User user) {
users.add(user);
return user;
}
15.2.4、@CacheEvict注解 ( 删除数据时 )
- 用在删除数据的方法上,调用方法时会从缓存中移除相应的数据
@CacheEvict(value = "user", key = "#userId")
void delete( Integer userId);
- 这个注解除了和
@Cacheable一样的参数之外,还有另外两个参数:- allEntries:默认为false,当为true时,会移除缓存中该注解该属性所在的方法的所有数据
- beforeInvocation:默认为false,在调用方法之后移除数据,当为true时,会在调用方法之前移除数据
15.2.5、@Cacheing组合注解 - 推荐
@Caching(
put = {
@CachePut(value = "user", key = "#userId"),
@CachePut(value = "user", key = "#username"),
@CachePut(value = "user", key = "#userAge"),
}
)
- 指的是:将userId、username、userAge放到名为user的缓存中存起来
15.3、SpringBoot集成Ehcache
15.3.1、配置Ehache
依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache</artifactId>
</dependency>
在
application.yml配置文件中加入配置
cache:
ehcache:
# 配置ehcache.xml配置文件所在地
config: class:ehcache.xml
在主启动类开启缓存功能
@SpringBootAllication
@EnableCaching
public class Starter {
public static void main(String[] args) {
SpringApplication.run(Starter.class);
}
}
编写
ehcache.xml配置文件
- 在
resources目录下新建rhcache.xml,并编写如下内容:
<ehcache name="myCache">
<!--缓存磁盘保存路径-->
<diskStore path = "D:/test/cache"/>
<!--默认的缓存配置
maxElementsInMemory 缓存最大数目
eternal 对象是否永久有效 一旦设置了,那么timeout将不再起作用
timeToIdleSeconds 设置对象在实效前能允许的闲置时间( 单位:秒 ),默认值是0,即:可闲置时间无穷大
仅当eternal=“false"对象不是永久有效时使用
timeToLiveSeconds 设置对象失效前能允许的存活时间( 单位:秒 )
最大时间介于创建时间和失效时间之间
maxElementsOnDisk 磁盘最大缓存个数
diskExpiryThreadIntervalSeconds 磁盘失效时,线程运行时间间隔,默认是120秒
memoryStoreEvictionPolicy 当达到设定的maxElementsInMemory限制时,Ehcache将会根据指定的策略去清理内存
默认策略是LRU( 即:最近最少使用策略 )
还可以设定的策略:
FIFO 先进先出策略
LFU 最近最少被访问策略
LRU 最近最少使用策略
缓存的元素有一个时间戳,当缓存容量满了,同时又需要腾出地方来缓存新的元素时,
那么现有缓存元素中的时间戳 离 当前时间最远的元素将被清出缓存
-->
<defaultCache
maxElementsInMemory="10000"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
maxElementsOnDisk="10000000"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU"/>
<!--下面的配置是自定义缓存配置,可以复制粘贴,用多套
name 起的缓存名
overflowToDisk 当系统宕机时,数据是否保存到上面配置的<diskStore path = "D:/test/cache"/>磁盘中
diskPersistent 是否缓存虚拟机重启期数据
另外的配置项:
clearOnFlush 内存数量最大时是否清除
diskSpoolBufferSizeMB 设置diskStore( 即:磁盘缓存 )的缓冲区大小,默认是30MB
每个Cache都应该有自己的一个缓冲区
-->
<cache
name="users"
eternal="false"
maxElementsInMemory="100"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="0"
timeToLiveSeconds="300"
memoryStoreEvictionPolicy="LRU"
/>
</ehcache>
15.3.2、在项目中使用ehcahe
- 使用常用的
@Cacheable注解举例
查询条件是单个时( service实现类中直接开注解 )
// 这里的value值就是前面xml中配置的哪个cache name值
@Cacheable(value="users", key = "#username")
public User queryUserByUsername(String username) {
return userMapper.selectUserByUsername(username);
}
查询条件是多个时( service实现类中直接开注解 )
- 本质:字符串的拼接
// 这里的UserDAO.username+就是封装的UserDAO,里面的属性有username、userage、userPhone
@Cache(value="users", key = "#UserDAO.username+'-'+#UserDAO.userage+'-'+#UserDAO.userPhone")
public User queryUserByUsername(UserDAO userDAO) {
return userMapper.selectUserByUserDAO(userDAO);
}
其他的注解也都是差不多的
16、定时任务
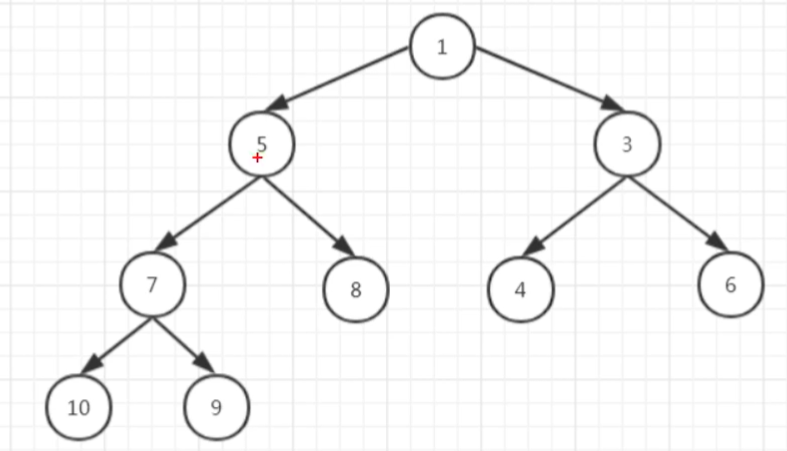
16.1、小顶堆数据结构
- 就是一个完全二叉树,同时这个二叉树遵循一个规则,根节点存的值永远小于两个子节点存的值
- 树结构只是一种逻辑结构,因此:数据还是要存起来的,而这种小顶堆就是采用了数组

即:数组下标为0的位置不放值,然后把树结构的数据放在对应位置
- 树结构数据转成数组数据的规律:从上到下、从左到右 - 即:根节点、左孩子节点、右孩子节点( 对照上面两个图来看 )
- 这种存储方式找父节点也好找,就是数组中( 当前数值的下标值 % 2 ) ,这种算法的原理:就是利用二叉树的深度 和 存放数据个数的关系( 数列 ),即:顶层最多可以放多少个数据?2的0次方;第二层最多可以存放多少个数据?2的1次方...........
这种小顶堆需要明白三个点:
- 存数据的方式: 上述提到了
- 取数据的方式:从底向上。即:从最底层开始,若比找寻的值小,那就找父节点,父节点也比所找寻数值小,继续找父节点的父节点.,要是比父节点大,那就找相邻兄弟节点嘛.........依次类推,最后就可以找到所找寻的数据了
- 存数据的方式:自底向上、逐渐上浮。即:从最底层开始,存的值 和 父节点相比,比父节点小的话,那存的值就是父节点存的值进行换位.....以此类推
16.2、时间轮算法

16.3、基础型时间轮
- 模仿时钟,24个刻度( 数组,每一个刻度作为数组的下标 ),每一个刻度后面就是一个链表,这个链表中放对应的定时任务,到了指定时间点就把后面链表中的任务全部遍历出来执行
- 缺点:当要弄年、月、秒这种就又要再加轮子,这样就很复杂了,因此:此种方式只适合记一天24小时的定时任务,涉及到年月秒就不行了
16.4、round型时间轮
- 在前面基础型时间轮的基础上,在每一个刻度的位置再加一个round值( 每个刻度后面还是一个链表存定时任务 ),round值记录的就是实际需求的值,如:一周,那round值就为7,当然这个round值可以是1,也可以是30....,每一次遍历时钟数组的那24个刻度时,遍历到某一个刻度,那么就让round值减1,知道round值为0时,就表示24数组中当前这个刻度存的定时任务该执行了
- 缺点:需要让round值减1,那么就是需要对时间轮进行遍历,如:定时任务应该是4号执行,但是3号遍历时间轮时,定时任务并不执行,而此时也需要遍历时间轮从而让round值减1,这浪费了性能
16.5、分量时间轮
后续的定时任务框架就是基于这个做的,如:Spring中有一个@Scheduleed( cron = "x x x x ...." )注解,它的这个cron时间表达式就是基于这种分量时间轮
使用多个轮子
- 如:一个时间轮记录小时0 - 24,而另一个轮子记录天数0 - 30天
- 先遍历天伦中的刻度,若今天是0 -30中要执行定时任务的那一天,那么天轮的刻度指向的就是时轮
- 然后再去遍历时轮中对应的那个刻度,从而找到这个刻度后面的链表,将链表遍历出来,执行定时任务
16.6、Timer定时任务
底层原理就是:小顶堆,只是它的底层用了一个taskQueue任务队列来充当小顶堆中的哪个数组,存取找的逻辑都是和小顶堆一样的
有着弊端:
- schedule() API 真正的执行时间 取决上一个任务的结束时间 - 会出现:少执行了次数
- scheduleAtFixedRate() API 想要的是严格按照预设时间 12:00:00 12:00:02 12:00:04,但是最终结果是:执行时间会乱
- 底层调的是
run(),也就是单线程 - 缺点:任务阻塞( 阻塞原因:任务超时 )

package com.tuling.timer;
import java.util.Date;
import java.util.Timer;
import java.util.TimerTask;
public class TimerTest {
public static void main(String[] args) {
Timer t = new Timer();// 任务启动
for (int i=0; i<2; i++){
TimerTask task = new FooTimerTask("foo"+i);
t.scheduleAtFixedRate(task,new Date(),2000);// 任务添加 10s 5次 4 3
// 预设的执行时间nextExecutorTime 12:00:00 12:00:02 12:00:04
// schedule 真正的执行时间 取决上一个任务的结束时间 ExecutorTime 03 05 08 丢任务(少执行了次数)
// scheduleAtFixedRate 严格按照预设时间 12:00:00 12:00:02 12:00:04(执行时间会乱)
// 单线程 任务阻塞 任务超时
}
}
}
class FooTimerTask extends TimerTask {
private String name;
public FooTimerTask(String name) {
this.name = name;
}
public void run() {
try {
System.out.println("name="+name+",startTime="+new Date());
Thread.sleep(3000);
System.out.println("name="+name+",endTime="+new Date());
// 因为是单线程,所以解决办法:使用线程池执行
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
16.7、定时任务线程池
底层原理就是timer + 线程池来做到的
如下的
Executors.newScheduledThreadPool(5);创建线程池的方法在高并发情况下,最好别用

package com.tuling.pool;
import java.util.Date;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class ScheduleThreadPoolTest {
public static void main(String[] args) {
// 这种线程池叫做垃圾 - 了解即可
// 缺点:允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);
for (int i=0;i<2;i++){
scheduledThreadPool.scheduleAtFixedRate(new Task("task-"+i),0,2, TimeUnit.SECONDS);
}
}
}
class Task implements Runnable{
private String name;
public Task(String name) {
this.name = name;
}
public void run() {
try {
System.out.println("name="+name+",startTime="+new Date());
Thread.sleep(3000);
System.out.println("name="+name+",endTime="+new Date());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
16.8、@Scheduled注解实现
- 这玩意儿是Spring提供的
- 缺点就是其定时时间不能动态更改,它适用于具有固定任务周期的任务
这个注解的几个属性
- fixedRate 表示任务执行之间的时间间隔,具体是指两次任务的开始时间间隔,即第二次任务开始
时,第一次任务可能还没结束 - fixedDelay 表示任务执行之间的时间间隔,具体是指本次任务结束到下次任务开始之间的时间间
隔 - initialDelay 表示首次任务启动的延迟时间
- cron 表达式:秒 分 小时 日 月 周 年
cron表达式说明
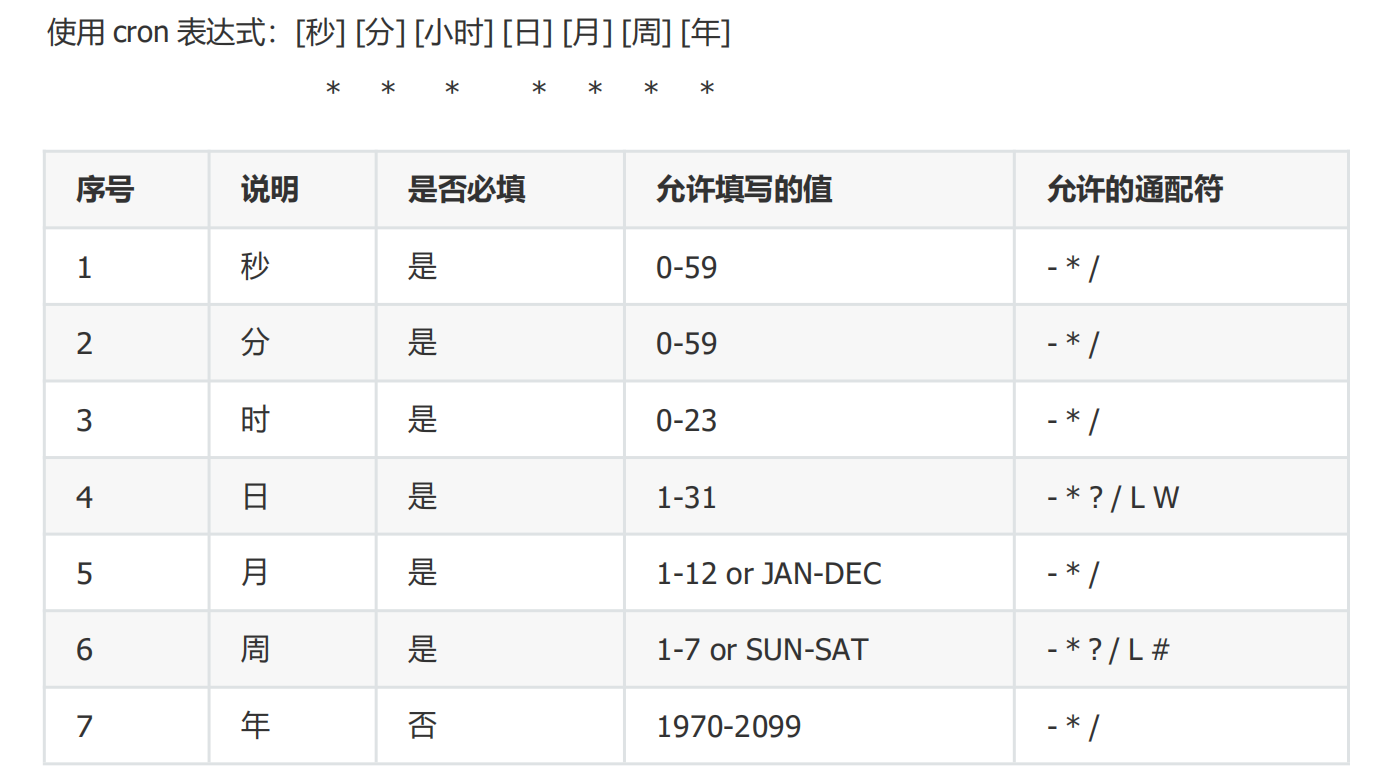
- 上图通配符含义
| 通配符 | 意义 |
|---|---|
? |
表示不指定值,即不关心某个字段的取值时使用 需要注意的是,月份中的日期和星期可能会起冲突,因此在配置时这两个得有一个是 ? |
* |
表示所有值,例如:在秒的字段上设置 * ,表示每一秒都会触发 |
, |
用来分开多个值,例如在周字段上设置 "MON,WED,FRI" 表示周一,周三和周五触发 |
- |
表示区间,例如在秒上设置 "10-12",表示 10,11,12秒都会触发 |
/ |
用于递增触发,如在秒上面设置"5/15" 表示从5秒开始,每增15秒触发(5,20,35,50) |
# |
序号(表示每月的第几个周几),例如在周字段上设置"6#3"表示在每月的第三个周六,(用 在母亲节和父亲节再合适不过了) |
L |
表示最后的意思 在日字段设置上,表示当月的最后一天(依据当前月份,如果是二月还会自动判断是否是润年 在周字段上表示星期六,相当于"7"或"SAT"(注意周日算是第一天) 如果在"L"前加上数字,则表示该数据的最后一个。例如在周字段上设置"6L"这样的格式,则表 示"本月最后一个星期五" |
W |
表示离指定日期的最近工作日(周一至周五) 例如在日字段上设置"15W",表示离每月15号最近的那个工作日触发。如果15号正好是周六,则找最近的周五(14号)触发, 如果15号是周未,则找最近的下周一(16号)触发,如果15号正好在工作日(周一至周五),则就在该天触发 如果指定格式为 "1W",它则表示每月1号往后最近的工作日触发。如果1号正是周六,则将在3号下周一触发。(注,"W"前只能设置具体的数字,不允许区间"-") |
L 和 W组合 |
如果在日字段上设置"LW",则表示在本月的最后一个工作日触发(一般指发工资 ) |
周字段的设置 |
若使用英文字母是不区分大小写的 ,即 MON 与mon相同 |
cron表达式举例
“0 0 12 * * ?” 每天中午12点触发
“0 15 10 ? * *” 每天上午10:15触发
“0 15 10 * * ?”
“0 15 10 * * ? *”
“0 15 10 * * ? 2005” 2005年的每天上午10:15 触发
“0 0/5 14 * * ?” 在每天下午2点到下午2:55期间的每5分钟触发
“0 0-5 14 * * ?” 在每天下午2点到下午2:05期间的每1分钟触发
“0 10,44 14 ? 3 WED” 每年三月的星期三的下午2:10和2:44触发
“0 15 10 ? * MON-FRI” 周一至周五的上午10:15触发
“0 15 10 ? * 6L” 每月的最后一个星期五上午10:15触发
“0 15 10 ? * 6L 2002-2005” 2002年至2005年的每月的最后一个星期五上午10:15触发
“0 15 10 ? * 6#3” 每月的第三个星期五上午10:15触发
0 23-7/2,8 * * * 晚上11点到早上8点之间每两个小时,早上八点
0 11 4 * 1-3 每个月的4号和每个礼拜的礼拜一到礼拜三的早上11点
以上的定时任务都还不知最终要用的,最终用的是Quartz,前面这些只是为了给这个东西打基础而已,具体知识自行百度
最后:SpringBoot还有很多内容,那些也就是整合各种框架而已,到了现在整合了这么多,那也有点门路了,其实都差不多是通同样的套路:1、引入SpringBoot整合的对应框架依赖;2、编写对应的配置;3、使用对应的注解 / 编写业务逻辑。差不多都是这样的套路,因此:到时需要时直接面向百度编程即可
SpringBoot 2.X 快速掌握的更多相关文章
- SpringBoot系列: RestTemplate 快速入门
====================================相关的文章====================================SpringBoot系列: 与Spring R ...
- springboot之swagger快速启动
springboot之swagger快速启动 简介 介绍 可能大家都有用过swagger,可以通过ui页面显示接口信息,快速和前端进行联调. 没有接触的小伙伴可以参考官网文章进行了解下demo页面. ...
- SpringBoot+SpringMVC+MyBatis快速整合搭建
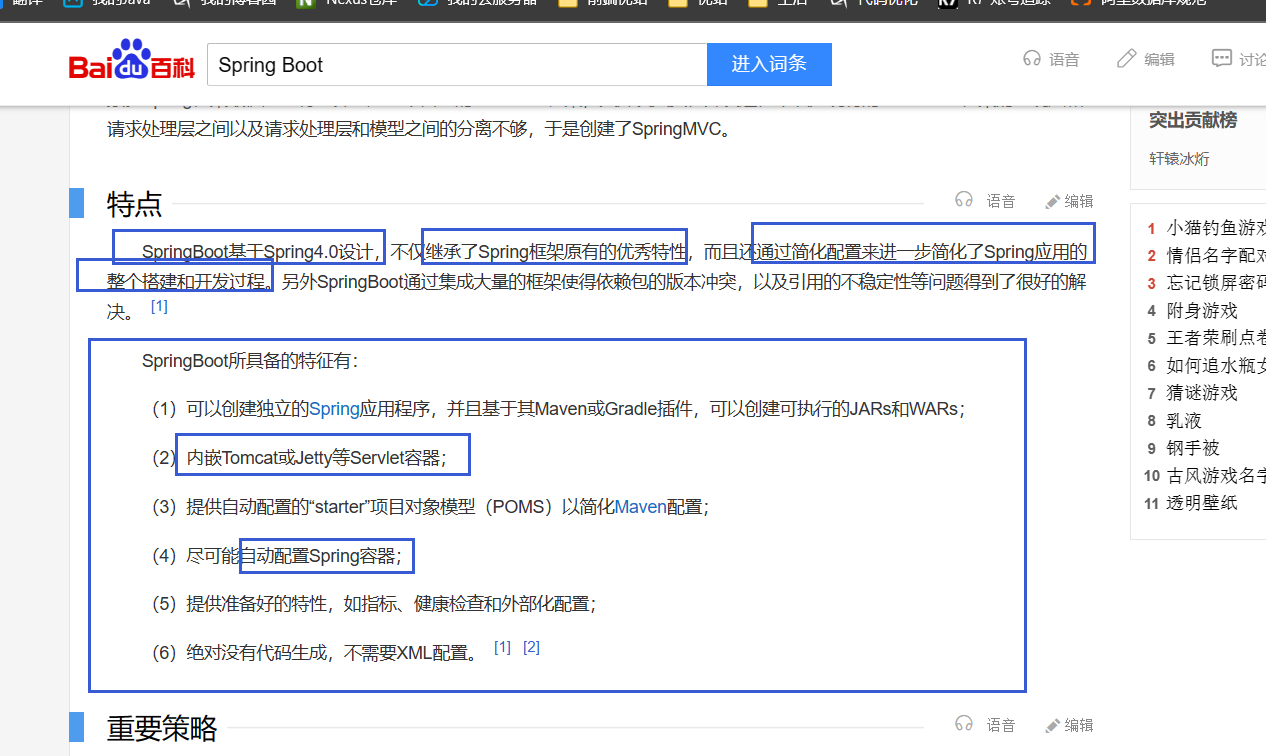
作为开发人员,大家都知道,SpringBoot是基于Spring4.0设计的,不仅继承了Spring框架原有的优秀特性,而且还通过简化配置来进一步简化了Spring应用的整个搭建和开发过程.另外Spr ...
- SpringBoot 通过jjwt快速实现token授权
A 10分钟了解JSON Web令牌(JWT)https://baijiahao.baidu.com/s?id=1608021814182894637&wfr=spider&for=p ...
- 在线Online表单来了!JeecgBoot 2.1 版本发布——基于SpringBoot+AntDesign的快速开发平台
项目介绍 Jeecg-Boot 是一款基于SpringBoot+代码生成器的快速开发平台! 采用前后端分离架构:SpringBoot,Ant-Design-Vue,Mybatis,Shiro,JWT. ...
- 基于SpringBoot+AntDesign的快速开发平台,JeecgBoot 2.0.2 版本发布
Jeecg-Boot 是一款基于SpringBoot+代码生成器的快速开发平台! 采用前后端分离架构:SpringBoot,Ant-Design-Vue,Mybatis,Shiro,JWT. 强大的代 ...
- springboot之swagger快速启动(新的ui)
springboot之swagger快速启动(新的ui) 功能点: 集成swagger前端接口文档 Swagger 整合 zuul 智能列表 无缝集成 knife4j 前端文档 支持 v0.1.2RE ...
- Springboot 完整搭建快速入门,必看!
前言 手把手教你Springboot微服务项目搭建快速入门,通过本文学习Springboot的搭建快速入门,掌握微服务大致的配置服务,后续将会继续将核心组件引入到项目中,欢迎关注,点赞,转发. Spr ...
- SpringBoot(一)_快速实战搭建项目
现在在学习springboot 相关的知识,感觉真的很好用,用idea 进行开发,根据慕课网和纯洁的微笑的课程.进行总结下. 使用idea创建springboot项目 (1)单击 File | New ...
- 基于SpringBoot+Mybatis+AntDesign快速开发平台,Jeecg-Boot 1.1 版本发布
Jeecg-Boot 1.1 版本发布,初成长稳定版本 导读 平台首页UI升级,精美的首页支持多模式 提供4套代码生成器模板(支持单表.一对多) 集成Excel简易工具类,支持单表.一对多导入 ...
随机推荐
- SQL之总结(二)
4.关于取两个日期之间的年份: ceil(MONTHS_BETWEEN(sysdate, c.sendtime)/12) workTime ceil(n) 取大于等于n的最小整数 floor(n) 取 ...
- java读取xml文件并转换成对象,并进行修改
1.首先要写工具类,处理读取和写入xml文件使用的工具.XMLUtil.javaimport java.io.FileInputStream; import java.io.FileWriter; i ...
- 微信小程序列表拖动排序Demo
wxml页面编写 <view class="container"> <view bindtap="box" class="box&q ...
- java并发问题总结
1.java中产生并发问题的主要原因有哪三个? 原子性.可见性和有序性 2.什么是java内存模型? java虚拟机规范中用来屏蔽掉各种硬件和操作系统内存访问差异,java内存模型的主要目标是定义程序 ...
- 防抖-小程序-input输入频繁时搜索出bug
html: <input type="text" class="input_search" placeholder="搜索周边店铺" ...
- UnrealEngine创建自定义资产类型
导语 这篇文章记录了将UObject实例保存在Asset文件的方法,用这个方法可以将自定义的UObject数据序列化保存到文件,可以用于自定义UE资源类型. 创建UObject类 这一步比较简单,按照 ...
- B3log开源博客compose搭建
B3log开源博客搭建 docker 安装 yum install docker-ce-17.12.1.ce docker-compose 安装 curl -L https://github.com/ ...
- Promql基础语法2
数据样本 直方图类型 delta函数 运算操作 数学运算 node_disk_info / 100 当瞬时向量与标量之间进行数学运算时,数学运算符会依次作用域瞬时向量中的每一个样本值,从而得到一组新的 ...
- python数据处理-matplotlib入门(4)-条形图和直方图
摘要:先介绍条形图直方图,然后用随机数生成一系列数据,保存到列表中,最后统计出相关随机数据的概率并展示 前述介绍了由点进行划线形成的拆线图和散点形成的曲线图,连点成线,主要用到了matplotlib中 ...
- Bugku CTF练习题---社工---密码
Bugku CTF练习题---社工---密码 flag:KEY{zs19970315} 解题步骤: 1.观察题目,思考题目要求 2.发现其中有姓名和生日这两个信息.从社工角度出发,感觉可能是名字+生日 ...