谣言检测(PLAN)——《Interpretable Rumor Detection in Microblogs by Attending to User Interactions》
论文信息
论文标题:Interpretable Rumor Detection in Microblogs by Attending to User Interactions
论文作者:Ling Min Serena Khoo, Hai Leong Chieu, Zhong Qian, Jing Jiang
论文来源:2020,
论文地址:download
论文代码:download
Background
基于群体智能的谣言检测:Figure 1
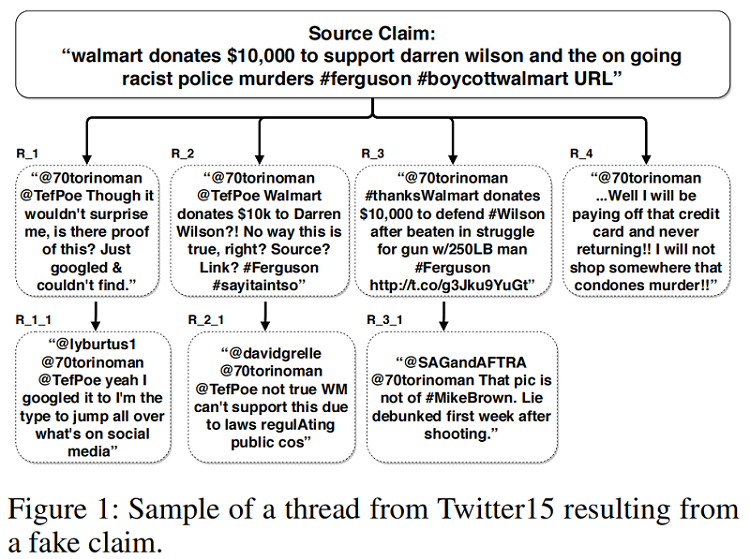
本文观点:基于树结构的谣言检测模型,往往忽略了 Branch 之间的交互。
1 Introduction
Motivation:a user posting a reply might be replying to the entire thread rather than to a specific user.
Mehtod:We propose a post-level attention model (PLAN) to model long distance interactions between tweets with the multi-head attention mechanism in a transformer network.
We investigated variants of this model:
- a structure aware self-attention model (StA-PLAN) that incorporates tree structure information in the transformer network;
- a hierarchical token and post-level attention model (StA-HiTPLAN) that learns a sentence representation with token-level self-attention.
- We utilize the attention weights from our model to provide both token-level and post-level explanations behind the model’s prediction. To the best of our knowledge, we are the first paper that has done this.
- We compare against previous works on two data sets - PHEME 5 events and Twitter15 and Twitter16 . Previous works only evaluated on one of the two data sets.
- Our proposed models could outperform current state-ofthe-art models for both data sets.
目前谣言检测的类型:
(i) the content of the claim.
(ii) the bias and social network of the source of the claim.
(iii) fact checking with trustworthy sources.
(iv) community response to the claims.
2 Approaches
2.1 Recursive Neural Networks
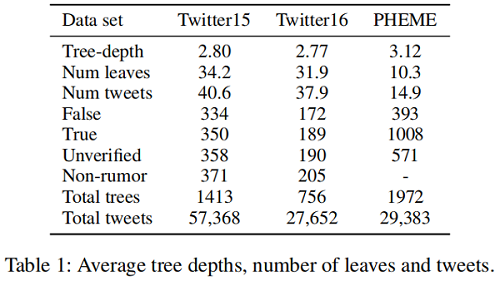
观点:谣言传播树通常是浅层的,一个用户通常只回复一次 source post ,而后进行早期对话。
|
Dataset |
Twitter15 |
Twitter16 |
PHEME |
|
Tree-depth |
2.80 |
2.77 |
3.12 |
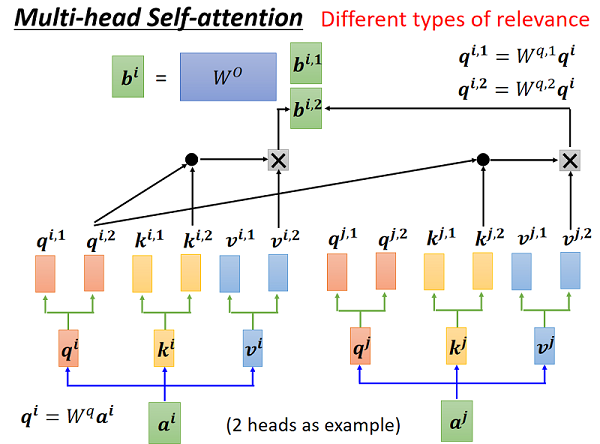
2.2 Transformer Networks
Transformer 中的注意机制使有效的远程依赖关系建模成为可能。
Transformer 中的注意力机制:
$\alpha_{i j}=\operatorname{Compatibility}\left(q_{i}, k_{j}\right)=\operatorname{softmax}\left(\frac{q_{i} k_{j}^{T}}{\sqrt{d_{k}}}\right)\quad\quad\quad(1)$
$z_{i}=\sum_{j=1}^{n} \alpha_{i j} v_{j}\quad\quad\quad(2)$
2.3 Post-Level Attention Network (PLAN)
框架如下:
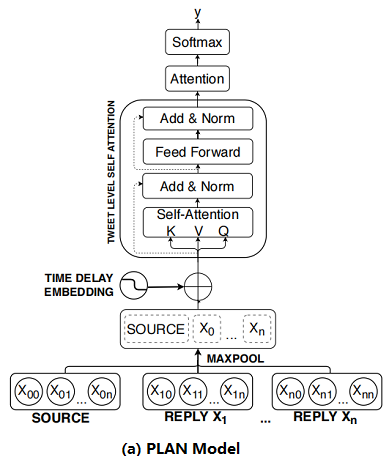
首先:将 Post 按时间顺序排列;
其次:对每个 Post 使用 Max pool 得到 sentence embedding ;
然后:将 sentence embedding $X^{\prime}=\left(x_{1}^{\prime}, x_{2}^{\prime}, \ldots, x_{n}^{\prime}\right)$ 通过 $s$ 个多头注意力模块 MHA 得到 $U=\left(u_{1}, u_{2}, \ldots, u_{n}\right)$;
最后:通过 attention 机制聚合这些输出并使用全连接层进行预测 :
$\begin{array}{l}\alpha_{k}=\operatorname{softmax}\left(\gamma^{T} u_{k}\right) &\quad\quad\quad(3)\\v=\sum\limits _{k=0}^{m} \alpha_{k} u_{k} &\quad\quad\quad(4)\\p=\operatorname{softmax}\left(W_{p}^{T} v+b_{p}\right) &\quad\quad\quad(5)\end{array}$
where $\gamma \in \mathbb{R}^{d_{\text {model }}}, \alpha_{k} \in \mathbb{R}$,$W_{p} \in \mathbb{R}^{d_{\text {model }}, K}$,$b \in \mathbb{R}^{d_{\text {model }}}$,$u_{k}$ is the output after passing through $s$ number of MHA layers,$v$ and $p$ are the representation vector and prediction vector for $X$
回顾:
2.4 Structure Aware Post-Level Attention Network (StA-PLAN)
上述模型的问题:线性结构组织的推文容易失去结构信息。
为了结合显示树结构的优势和自注意力机制,本文扩展了 PLAN 模型,来包含结构信息。
$\begin{array}{l}\alpha_{i j}=\operatorname{softmax}\left(\frac{q_{i} k_{j}^{T}+a_{i j}^{K}}{\sqrt{d_{k}}}\right)\\z_{i}=\sum\limits _{j=1}^{n} \alpha_{i j}\left(v_{j}+a_{i j}^{V}\right)\end{array}$
其中, $a_{i j}^{V}$ 和 $a_{i j}^{K}$ 是代表上述五种结构关系(i.e. parent, child, before, after and self) 的向量。
2.5 Structure Aware Hierarchical Token and Post-Level Attention Network (StA-HiTPLAN)
本文的PLAN 模型使用 max-pooling 来得到每条推文的句子表示,然而比较理想的方法是允许模型学习单词向量的重要性。因此,本文提出了一个层次注意模型—— attention at a token-level then at a post-level。层次结构模型的概述如 Figure 2b 所示。
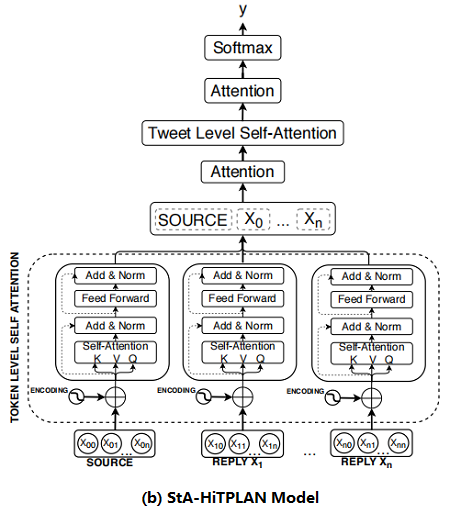
2.6 Time Delay Embedding
source post 创建的时候,reply 一般是抱持怀疑的状态,而当 source post 发布了一段时间后,reply 有着较高的趋势显示 post 是虚假的。因此,本文研究了 time delay information 对上述三种模型的影响。
To include time delay information for each tweet, we bin the tweets based on their latency from the time the source tweet was created. We set the total number of time bins to be 100 and each bin represents a 10 minutes interval. Tweets with latency of more than 1,000 minutes would fall into the last time bin. We used the positional encoding formula introduced in the transformer network to encode each time bin. The time delay embedding would be added to the sentence embedding of tweet. The time delay embedding, TDE, for each tweet is:
$\begin{array}{l}\mathrm{TDE}_{\text {pos }, 2 i} &=&\sin \frac{\text { pos }}{10000^{2 i / d_{\text {model }}}} \\\mathrm{TDE}_{\text {pos }, 2 i+1} &=&\cos \frac{\text { pos }}{10000^{2 i / d_{\text {model }}}}\end{array}$
where pos represents the time bin each tweet fall into and $p o s \in[0,100)$, $i$ refers to the dimension and $d_{\text {model }}$ refers to the total number of dimensions of the model.
3 Experiments and Results
dataset
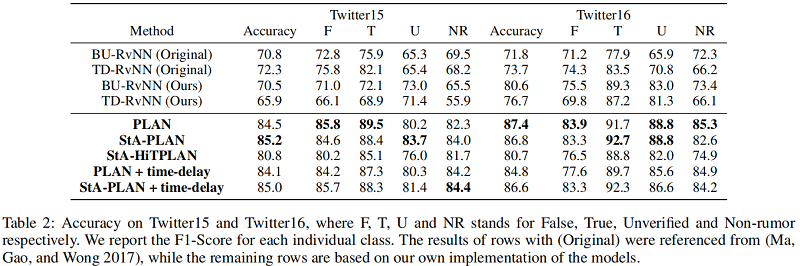
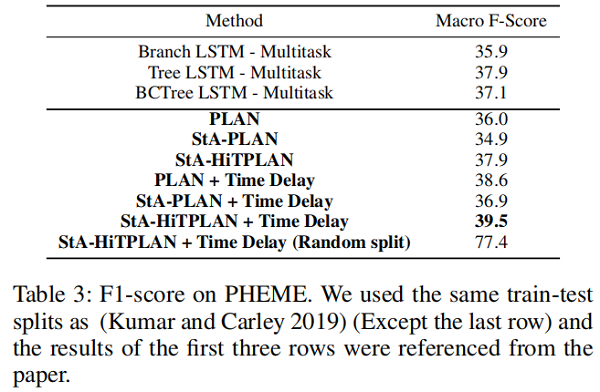
Result
Post-Level Explanations
首先通过最后的 attention 层获得最重要的推文 $tweet_{impt}$ ,然后从第 $i$ 个MHA层获得该层的与 $tweet_{impt}$ 最相关的推文 $tweet _{rel,i}$ ,每篇推文可能被识别成最相关的推文多次,最后按照 被识别的次数排序,取前三名作为源推文的解释。举例如下:

Token-Level Explanation
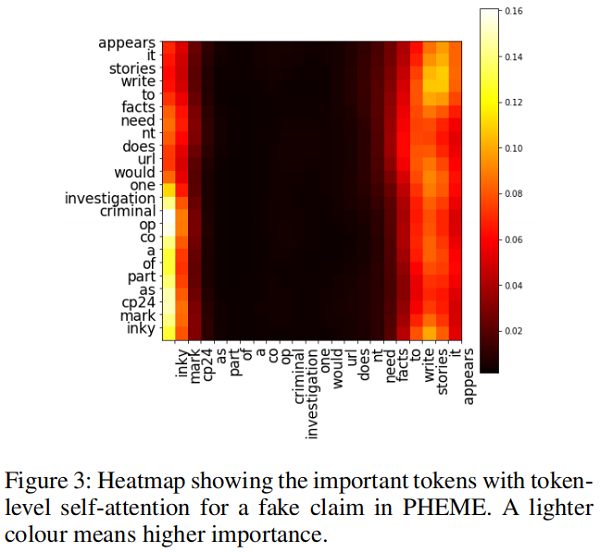
可以使用 token-level self-attention 的自注意力权重来进行 token-level 的解释。比如评论 “@inky mark @CP24 as part of a co-op criminal investigation one would URL doesn’t need facts to write stories it appears.”中短语“facts to write stories it appears”表达了对源推文的质疑,下图的自注意力权重图可以看出大量权重集中在这一部分,这说明这个短语就可以作为一个解释:
谣言检测(PLAN)——《Interpretable Rumor Detection in Microblogs by Attending to User Interactions》的更多相关文章
- 谣言检测——(PSA)《Probing Spurious Correlations in Popular Event-Based Rumor Detection Benchmarks》
论文信息 论文标题:Probing Spurious Correlations in Popular Event-Based Rumor Detection Benchmarks论文作者:Jiayin ...
- 谣言检测——《MFAN: Multi-modal Feature-enhanced Attention Networks for Rumor Detection》
论文信息 论文标题:MFAN: Multi-modal Feature-enhanced Attention Networks for Rumor Detection论文作者:Jiaqi Zheng, ...
- 谣言检测(GACL)《Rumor Detection on Social Media with Graph Adversarial Contrastive Learning》
论文信息 论文标题:Rumor Detection on Social Media with Graph AdversarialContrastive Learning论文作者:Tiening Sun ...
- 谣言检测(ClaHi-GAT)《Rumor Detection on Twitter with Claim-Guided Hierarchical Graph Attention Networks》
论文信息 论文标题:Rumor Detection on Twitter with Claim-Guided Hierarchical Graph Attention Networks论文作者:Erx ...
- 谣言检测(RDEA)《Rumor Detection on Social Media with Event Augmentations》
论文信息 论文标题:Rumor Detection on Social Media with Event Augmentations论文作者:Zhenyu He, Ce Li, Fan Zhou, Y ...
- 谣言检测()《Data Fusion Oriented Graph Convolution Network Model for Rumor Detection》
论文信息 论文标题:Data Fusion Oriented Graph Convolution Network Model for Rumor Detection论文作者:Erxue Min, Yu ...
- 谣言检测()《Rumor Detection with Self-supervised Learning on Texts and Social Graph》
论文信息 论文标题:Rumor Detection with Self-supervised Learning on Texts and Social Graph论文作者:Yuan Gao, Xian ...
- 谣言检测(PSIN)——《Divide-and-Conquer: Post-User Interaction Network for Fake News Detection on Social Media》
论文信息 论文标题:Divide-and-Conquer: Post-User Interaction Network for Fake News Detection on Social Media论 ...
- 论文解读(RvNN)《Rumor Detection on Twitter with Tree-structured Recursive Neural Networks》
论文信息 论文标题:Rumor Detection on Twitter with Tree-structured Recursive Neural Networks论文作者:Jing Ma, Wei ...
随机推荐
- 解气!哈工大被禁用MATLAB后,国产工业软件霸气回击
提起哈尔滨工业大学,相信很多人都不会陌生. 它是中国顶级的C9院校之一,从1920年建校的百余年来,哈工大一直享誉"工科强校"的美称,因其在航天领域的不凡成就,更是被人们誉为&qu ...
- CF Edu Round 131 简要题解 (ABCD)
A 分类讨论即可 . using namespace std; typedef long long ll; typedef pair<int, int> pii; int main() { ...
- 2536-springsecurity系列--关于session管理1
版本信息 <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring ...
- Odoo14 OWL 如何访问model方法和res_id
首先OWL是Odoo14版本新加的功能. 因为是新加的所以并没有太多的说明文档,包括英文板文档也没有:所以你要用它再没有更详细的文档之前你得自己去看源码. 注意owl是没有do_action函数给你跳 ...
- MySQL主从复制原理及搭建过程
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 复制概述 复制即把一台服务器上的数据通过某种手段同步到另外一台或多台从服务器上,使得从服务器在数据上与主服务器保持一致. ...
- 臭名远扬之 goto 语句
C 语言自学之 goto 语句 Dome1:以下程序实现从控制台输出1-10,使用goto语句,实现当输出完3之后跳出循环体. 1 #include <stdio.h> 2 3 int m ...
- ArkUI 数据绑定、列表渲染、事件处理
前言 有过开发微信小程序经验的小伙伴学习鸿蒙应用开发非常容易过渡过来. HML(HarmonyOS Markup Language)是一套类HTML的标记语言,通过组件,事件构建出页面的内容.页面具备 ...
- Taurus.MVC 微服务框架 入门开发教程:项目集成:4、默认安全认证与自定义安全认证。
系列目录: 本系列分为项目集成.项目部署.架构演进三个方向,后续会根据情况调整文章目录. 本系列第一篇:Taurus.MVC V3.0.3 微服务开源框架发布:让.NET 架构在大并发的演进过程更简单 ...
- Python小游戏——外星人入侵(保姆级教程)第一章 05重构模块game_functions
系列文章目录 第一章:武装飞船 05:重构:模块game_functions 一.重构 在大型项目中,经常需要在添加新代码前重构既有代码.重构旨在简化既有代码的结构,使其更容易扩展.在本节中,我们将创 ...
- 创建swarm集群并自动编排
1.基础环境配置 主机名 master node1 node2 IP地址 192.168.***.1 192.168.***.2 192.168.***.3 角色 管理节点 工作节点 工作节点 ...