Language Modeling---NLP学习笔记(原创)
本栏目来源于对Coursera 在线课程 NLP(by Michael Collins)的理解。课程链接为:https://class.coursera.org/nlangp-001
1. 语言模型定义:
Model Representation:
- V:集合V包含语料中所有单词,例如:V={the,dog,laughs,saw,barks,cat,...};
- x1x2...xn:x1x2...xn为句子序列,其中n≥1,xn为句子的STOP符(结束标志);
- p(x1,x2,...,xn):集合V的一种可能的分布,其中对任意<x1x2...xn>,p(x1,x2,...,xn)≥0,且 ∑<x1x2...xn>p(x1,x2,...,xn)=1;
例如:假设c(x1x2...xn)是x1x2...xn在语料中出现的频次,N是语料句子总数,定义 p(x1,x2,...,xn)=c(x1x2...xn)/N 但是该模型效果很差由于其无法预测语料中未出现的新单词。
2. 马尔科夫模型(Markov Model)
2.1 定长序列的马尔科夫模型
假设单词序列x1x2...xn为定长的n,对于联合概率P(X1=x1,X2=x2,...Xn=xn),可见x1x2...xn有|V|n种组合。
- 在一阶马尔科夫过程中,假设第i个单词出现与否取决于其前面的单词xi-1:

因此序列x1x2...xn出现的概率为:

- 在二阶马尔科夫过程中(trigram),假设每个单词的出现取决于其前面的两个单词:

因此序列x1x2...xn出现的概率为:

PS:定义x0=x-1=*,即句子序列开始符。
2.1 变长序列的马尔科夫模型
假设单词序列x1x2...xn为可变长度的句子序列,即n为随机变量,此时假设xn为STOP符唯一的表示句子的结尾。继续使用前面的假设,对于二阶马尔科夫过程:
其中xn=STOP
计算流程为:
- (1)初始化i=1,x0=x-1=*;
- (2)在分布中计算xi:P(Xi=xi|Xi-2=xi-2,Xi-1=xi-1);
- (3)若xi=STOP,返回序列x1x2...xi。否则令i=i+1,重复步骤(2)
3. Trigram语言模型
假设P(Xi=xi | Xi-2=xi-2,Xi-1=xi-1) = q(xi | xi-2,xi-1)
其中q(w | u,v)对任意(u,v,w)是模型的参数,w属于集合{V,STOP},u,v属于集合{V,*},x0 = x-1 =*,模型形式如下:

其中q(w|u,v)≥0 且
例如:句子序列 the dog barks STOP
p(the dog barks STOP)=q(the|*,*)×q(dog|*,the)×q(barks|the,dog)×q(STOP|dog,barks)
4. 极大似然估计(Maximum-Likelihood Estimates)
定义c(u,v,w)为trigram(u,v,w)在训练语料中出现的频次,例如c(the,dog,barks)即 “the dog barks”序列在语料中出现的次数,同理c(u,v)为bigram(u,v)在语料中出现的频次,对任意u,v,w,定义:

例如:q(the,dog,barks)估计为:
由于词数量庞大,该方法的问题有:
- 许多词项会出现q(w|u,v)=0由于c(u,v,w)=0,而将未在训练语料中出现的序列组合计算为0是不合理的;
- 当c(u,v)为0时,该定义式无解;
5. 语言模型评估:复杂度(Perplexity)
假设测试集为x(1),x(2),...x(n).其中x(i)为序列,x1(i)x2(i)...xni(i),ni为第i个测试句子的长度并以STOP作为结束符。一种模型的评价标准为计算整个测试集句子出现的概率,即:

PS:概率值越大,模型对新词的预测效果越好。
- M:测试语料集词的总数
- ni:第i个测试句子的长度

平均log概率为:

模型复杂度定义为 2-l ,其中 
PS:复杂度越小,模型对于预测新数据的效果越好。
例如:对于语言模型 q(w|u,v)=1/N,这时该模型的复杂度为N,可见是很差的模型。
6 Trigram模型的平滑估计
借助bigram和unigram的结果来平滑trigram模型。可以使用linear interpolation(线性插值)和discounting methods。
6.1 Linear Interpolation
定义trigram,bigram和unigram的极大似然估计为:

其中c(w)是词w在训练语料中出现的次数,c()是训练语料的总词数。trigram,bigram和unigram有各自的优缺点。unigram不会出现算式分子或分母为0的情况,但是却忽略了句子上下文的关系;相反,trigram充分利用了文本关系但很多算式结果为0.
Linear Interpolation应用如下定义来平滑模型:

其中λ1≥0,λ2≥0,λ3≥0是模型的另外参数,且λ1+λ2+λ3=1。为trigram,bigram和unigram的权重参数。
- 最优λ计算方法:我们从训练语料和测试语料中分离出新的集合称为development data,定义为c'(u,v,w)为development data集合中trigram(u,v,w)出现的频次。development data集合的log似然估计为:

目标函数:
在实际应用中,当c(u,v)很大时,可以增大λ1(由于大的c(u,v)说明trigram更加有效);当c(u,v)=0时,令λ1=0(由于此时qML(w|u,v)没有定义);同理若c(u,v),c(v)都为0,我们就需要λ1=λ2=0(由于trigram,bigram都无定义).
- 还有一种简单计算λ的方法:

其中γ>0,该方法相对粗糙,可能并非最优,但是很简单。
6.2 Discounting Methods
定义discounted counts: 其中任意bigram c(v,w)>0,β在0和1之间;
其中任意bigram c(v,w)>0,β在0和1之间;
因此定义:
例如:对如下数据,词"the"在语料中共出现了48次,下表列出了所有的bigram。另外我们利用discounted count c*(x)=c(x)-β。且β=0.5 最后计算c*(x)/c(the).该定义造成了一些概率丢失,定义如下:

本例中, ,
,

完整定义如下: A(v)={w:c(v,w)>0}且B(v)={w:c(v,w)=0}
本例中,A(the)={dog,woman,man,park,job,telescope,manual,afternoon,country,street},B(the)是此表中其余集合。

因此,若c(v,w)>0,返回c*(v,w)/c(v);否则,将α(v)成比例地分给unigram来评估qML(w)。
- 该方法也可以用来计算trigram模型,对任意bigram(u,v)定义:
A(u,v)={w:c(u,v,w)>0}且B(u,v)={w:c(u,v,w)=0}
- 定义trigram的discounted count:

故trigram模型为:

其中: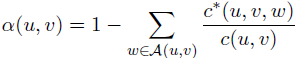
- 求解最优β:通常使用在development data上计算似然概率的方法来求解最优β。定义c'(u,v,w)为development data中trigram(u,v,w)出现的频次,log似然概率为:

通常我们为β设置可能的数值集合(例如{0.1,0.2,0.3,...,0.9})分别计算其log似然概率,从中选出令log似然概率最大的β即可。
本文为原创博客,若转载请注明出处。
@%T2C5(Q`Y6.png)
Language Modeling---NLP学习笔记(原创)的更多相关文章
- MongoDB 学习笔记(原创)
MongoDB 学习笔记 mongodb 数据库 nosql 一.数据库的基本概念及操作 SQL术语/概念 MongoDB术语/概念 解释/说明 database database 数据库 table ...
- 自然语言处理NLP学习笔记一:概念与模型初探
前言 先来看一些demo,来一些直观的了解. 自然语言处理: 可以做中文分词,词性分析,文本摘要等,为后面的知识图谱做准备. http://xiaosi.trs.cn/demo/rs/demo 知识图 ...
- Stanford NLP 学习笔记2:文本处理基础(text processing)
I. 正则表达式(regular expression) 正则表达式是专门处理文本字符串的正式语言(这个是基础中的基础,就不再详细叙述,不了解的可以看这里). ^(在字符前): 负选择,匹配除括号以外 ...
- Stanford NLP学习笔记:7. 情感分析(Sentiment)
1. 什么是情感分析(别名:观点提取,主题分析,情感挖掘...) 应用: 1)正面VS负面的影评(影片分类问题) 2)产品/品牌评价: Google产品搜索 3)twitter情感预测股票市场行情/消 ...
- 自然语言处理NLP学习笔记二:NLP实战-开源工具tensorflow与jiagu使用
前言: NLP工具有人推荐使用spacy,有人推荐使用tensorflow. tensorflow:中文译作:张量(超过3维的叫张量)详细资料参考:http://www.tensorfly.cn/ J ...
- Stanford NLP学习笔记1:课程介绍
Stanford NLP课程简介 1. NLP应用例子 问答系统: IBM Watson 信息提取(information extraction) 情感分析 机器翻译 2. NLP应用当前进展 很成熟 ...
- 自然语言处理NLP学习笔记三:使用Django做一个NLP的Web站点
前言: 前面我们已经能初步实现一个中文自然处理语言的模型了,但交互界面是命令行的,不太友好. 如果想做一个类似http://xiaosi.trs.cn/demo/rs/demo的界面,那就还需要继续往 ...
- NXP NFC移植及学习笔记(原创)
NFC功能介绍 NFC 目前使用的三种功能: 1. P2P模式:基于LLCP协议的基础上,以NDEF数据交换格式来通信. 2. 读写模式:当作为读卡器,对NFC Tag的读写. 3. 卡模拟模式:模块 ...
- stanford NLP学习笔记3:最小编辑距离(Minimum Edit Distance)
I. 最小编辑距离的定义 最小编辑距离旨在定义两个字符串之间的相似度(word similarity).定义相似度可以用于拼写纠错,计算生物学上的序列比对,机器翻译,信息提取,语音识别等. 编辑距离就 ...
- Angular源代码学习笔记-原创
时间:2014年12月15日 14:15:10 /** * @license AngularJS v1.3.0-beta.15 * (c) 2010-2014 Google, Inc. http:// ...
随机推荐
- 对Feign的请求url 重写
需求:对当前请求的 url 重新构建 debug feign 的执行可知,重写 LoadBalancerFeignClient 类中的 execute 方法即可控制当前请求的url 代码分析 当引入 ...
- nginx配置不当导致的目录遍历下载漏洞-“百度杯”CTF比赛 2017 二月场
题目:http://98fe42cede6c4f1c9ec3f55c0f542d06b680d580b5bf41d4.game.ichunqiu.com/login.php 题目内容: 网站要上线了, ...
- 数据库与sql注入的相关知识
数据库与sql注入的相关知识 sql语句明显是针对数据库的一种操作,既然想通过sql注入的方法来拿取数据那么就要先了解一下如何的去操作数据库,这方面并不需要对数据库有多么的精通但是如果了解掌握了其中的 ...
- 老版本ubuntu更新源地址以及sources.list的配置方法 转
转自(http://blog.csdn.net/snaking616/article/details/52966634) 1.国内可用的更新源地址: (1)中科大地址 http://mirrors.u ...
- [ python ] 变量及基础的数据类型
python2 和 python3 不同的编码方式 python2 默认编码方式是 ascii码 python3 默认编码方式是 utf-8 具体表现为:当 python3 和 python2 在打印 ...
- 2017百度春招<不等式排列>
题目: 度度熊最近对全排列特别感兴趣,对于1到n的一个排列,度度熊发现可以在中间根据大小关系插入合适的大于和小于符号(即 '>' 和 '<' )使其成为一个合法的不等式数列.但是现在度度熊 ...
- javascript当中的this详解
总结this的3个规则: this是调用上下文,上下文被创建或者初始化时才确定 非严格模式:this是全局对象:严格模式:this是undefined 函数调用 a. 以函数形式调用的函数通常不使用t ...
- LightOJ 1414 February 29(闰年统计+容斥原理)
题目链接:https://vjudge.net/contest/28079#problem/R 题目大意:给你分别给你两个日期(第二个日期大于等于第一个日期),闰年的2月29日称为闰日,让你求两个日期 ...
- CSS&&xpath
1.元素选择器 <div class="wrap"> 直接选择文档元素div 2.类选择器 <div class="wrap"> 元素的 ...
- Kiggle:Digit Recognizer
题目链接:Kiggle:Digit Recognizer Each image is 28 pixels in height and 28 pixels in width, for a total o ...