机器学习笔记—混合高斯和 EM 算法
本文介绍密度估计的 EM(Expectation-Maximization,期望最大)。
假设有 {x(1),...,x(m)},因为是无监督学习算法,所以没有 y(i)。
我们通过指定联合分布 p(x(i),z(i))=p(x(i)|z(i))p(z(i)) 来对数据建模。这里 z(i)~Multinomial(Φ),其中 Φj≥0,Φ1+Φ2+...+Φk=1,参数 Φj 给定 p(z(i)=j),x(i)|z(i)=j~N(μj,∑j)。k 表示 z(i) 能取的值的个数,所以,通过从 {1,...,k} 中随机选择 z(i),x(i) 从 k 个依赖于 z(i) 的高斯中生成。这就是高斯混合模型。z(i) 是隐随机变量,它们是隐藏的,这增大了估计问题的难度。
模型的参数是 Φ,μ 和 ∑,为对它们做估计,数据的似然为:
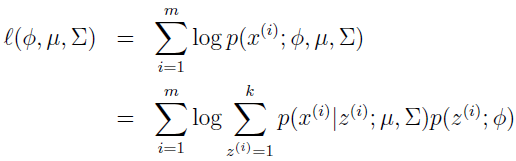
如果通过对参数求导并设为 0 来解,会发现不可能在封闭形式中找到最大似然估计。
随机变量 z(i) 表示 x(i) 来自 k 个高斯分布中的哪一个,如果知道 z(i) 的值,最大似然估计问题就简单了

最大化后参数为:
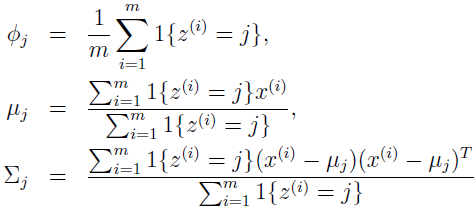 可以看到,如果知道 z(i),最大似然估计就跟高斯判别分析模型的参数估计差不多,除了 z(i) 扮演类标识的角色。
可以看到,如果知道 z(i),最大似然估计就跟高斯判别分析模型的参数估计差不多,除了 z(i) 扮演类标识的角色。
尽管如此,在我们的密度估计问题中,z(i) 是未知的,怎么办?
EM 算法是一个迭代算法,主要分两步:在 E 步,猜测 z(i) 的值;在 M 步,基于猜测更新模型的参数。因为在 M 步假装第一步是正确的,最大化就变简单了。这是算法:


在 E 步,给定 x(i),使用当前参数,用贝叶斯规则计算 z(i) 的后验概率。
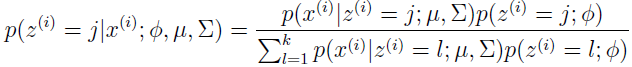
其中 p(x(i)|z(i)=j;μ;∑) 是由 x(i) 的以 μj 为均值和 ∑j 为方差的高斯密度估计出来的;p(z(i)=j;Φ) 是由 Φj 给定的。在 E 步计算的 wj(i) 代表 z(i) 的软估计。
如果拿 M 步的更新同上面 z(i) 已知时的公式做对比,它们是相等的,除了指示函数 I{z(i)=j} 以 wj(i) 代替。
EM 算法会让人想起 K-均值聚类,差别在于硬聚类绑定 c(i) 以软绑定 wj(i) 代替。同 K-均值类似,它也会陷入局部最优,所以多对初始参数赋几次值是个好主意。
很清楚,EM 算法对重复猜测未知 z(i) 有一个非常自然的解释,但它能保证收敛吗?下篇文章将更广地介绍 EM,使我们可以把它应用到其它包含隐变量的估计问题,也会有收敛的证明。
参考资料:
1、http://cs229.stanford.edu/notes/cs229-notes7b.pdf
机器学习笔记—混合高斯和 EM 算法的更多相关文章
- Python机器学习笔记:异常点检测算法——LOF(Local Outiler Factor)
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 在数据挖掘方面,经常需 ...
- 机器学习(七)EM算法、GMM
一.GMM算法 EM算法实在是难以介绍清楚,因此我们用EM算法的一个特例GMM算法作为引入. 1.GMM算法问题描述 GMM模型称为混合高斯分布,顾名思义,它是由几组分别符合不同参数的高斯分布的数据混 ...
- 【机器学习】GMM和EM算法
机器学习算法-GMM和EM算法 目录 机器学习算法-GMM和EM算法 1. GMM模型 2. GMM模型参数求解 2.1 参数的求解 2.2 参数和的求解 3. GMM算法的实现 3.1 gmm类的定 ...
- 【机器学习笔记之四】Adaboost 算法
本文结构: 什么是集成学习? 为什么集成的效果就会好于单个学习器? 如何生成个体学习器? 什么是 Boosting? Adaboost 算法? 什么是集成学习 集成学习就是将多个弱的学习器结合起来组成 ...
- Stanford机器学习笔记-9. 聚类(K-means算法)
9. Clustering Content 9. Clustering 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means al ...
- 吴恩达机器学习笔记58-协同过滤算法(Collaborative Filtering Algorithm)
在之前的基于内容的推荐系统中,对于每一部电影,我们都掌握了可用的特征,使用这些特征训练出了每一个用户的参数.相反地,如果我们拥有用户的参数,我们可以学习得出电影的特征. 但是如果我们既没有用户的参数, ...
- 吴恩达机器学习笔记55-异常检测算法的特征选择(Choosing What Features to Use of Anomaly Detection)
对于异常检测算法,使用特征是至关重要的,下面谈谈如何选择特征: 异常检测假设特征符合高斯分布,如果数据的分布不是高斯分布,异常检测算法也能够工作,但是最好还是将数据转换成高斯分布,例如使用对数函数:
- 机器学习笔记(五) K-近邻算法
K-近邻算法 (一)定义:如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别. (二)相似的样本,特征之间的值应该是相近的,使用k-近邻算法需要做标准化处理.否 ...
- [吴恩达机器学习笔记]14降维3-4PCA算法原理
14.降维 觉得有用的话,欢迎一起讨论相互学习~Follow Me 14.3主成分分析原理Proncipal Component Analysis Problem Formulation 主成分分析( ...
随机推荐
- Oulipo----poj3461(kmp模板)
题目链接:http://poj.org/problem?id=3461 和 减花布条 的题对比一下: 求s2中s1的个数kmp模板: #include<stdio.h> #include& ...
- redis哨兵集群、docker入门
redis-sentinel主从复制高可用 Redis-Sentinel Redis-Sentinel是redis官方推荐的高可用性解决方案,当用redis作master-slave的高可用时,如果m ...
- 【开发者笔记】冒泡排序过程呈现之java内置GUI表示
自己玩玩写写,排序的过程多么有趣,特别是把看着电脑吧一堆乱七八糟的数据排成有序组合的时候,看起来贼舒服,特别是强迫症患者.好了,话不多说上代码,也算是自己记录一下吧,没有什么技术含量但个人感觉比较有趣 ...
- git pull和git merge区别&&Git冲突:commit your changes or stash them before you can merge. 解决办法
http://blog.csdn.net/sidely/article/details/40143441 原文: http://www.tech126.com/git-fetch-pull/ Git中 ...
- OS X 10.9 Mavericks下如何安装Command Line Tools(命令行工具)
OS X 10.9 Mavericks下如何安装Command Line Tools(命令行工具) 今天OS X 10.9 Mavericks正式发布,免费更新,立即去更新看看效果. 不过升级后安装命 ...
- [C语言]小记q = (++j) + (++j) + (++j)的值
根据不同的编译器,生产的代码不一样,导致的结果也会不一样. 代码如下: #include <stdio.h> void main() { ; int q; q =(++j)+(++j)+( ...
- hdu2609 How many
地址:http://acm.hdu.edu.cn/showproblem.php?pid=2609 题目: How many Time Limit: 2000/1000 MS (Java/Others ...
- mysql调优小记
对于INNODB,主键就是聚集索引,如果没有主键定义,则第一个唯一非空索引被作为聚集索引.如果没有主键也没有合适的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键类似一个 ...
- iOS开发之NSUserDefaults
在ios中偏好设置保存用户配置的对象 //NSUserDefaults读取 //获取标准函数对象 //通过对象获取名称下NSMutableDictionary数据 NSUserDefaults *de ...
- Python- discover()方法与执行顺序补充
可以根据不同的功能创建不同的测试文件,甚至是不同的测试目录,测试文件中还可以将不同的小功能划分为不同的测试类,在类下编写测试用例,让整体结构更加清晰 但通过addTest()添加.删除测试用例就变得非 ...