Hadoop中Writable类
1.Writable简单介绍
在前面的博客中,经常出现IntWritable,ByteWritable.....光从字面上,就可以看出,给人的感觉是基本数据类型 和 序列化!在Hadoop中自带的org.apache.hadoop.io包中有广泛的Writable类可供选择。它们的层次结构如下图所示:
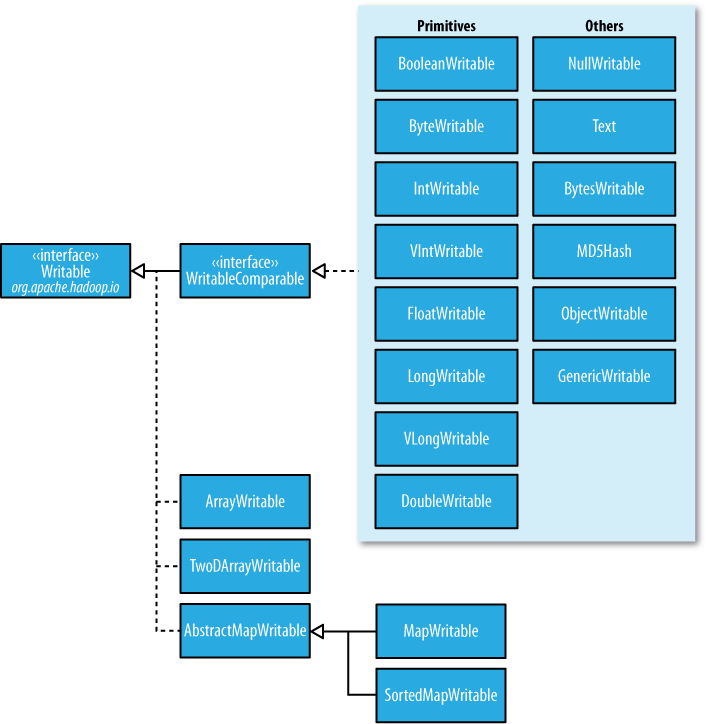
Writable类对Java基本类型提供封装,short 和 char除外(可以存储在IntWritable中)。所有的封装包包含get() 和 set() 方法用于读取或者设置封装的值。如下表所示,Java基本类型的Writable类:
| Java 基本数据类型 | Writable实现 | 序列化大小(字节) |
| boolean | BooleanWritable | 1 |
| byte | ByteWritable | 1 |
|
int |
IntWritable VIntWritable |
4 1~5 |
| float | FloatWritable | 4 |
|
long |
LongWritable VLongWritable |
8 1~9 |
| double | DoubleWritable | 8 |
2.IntWritable 和 VIntWritable
如上表所示,这两个的区别,很明显,序列化的大小,IntWriable是固定的4个字节,而VintWritable是1~5个字节,是可以变化的!这两个分别在什么场合用?如果需要编码的数值在-127~127之间,变长格式就只用一个字节进行编码;否则,使用一个字节来表示数值的正负和后跟多少个字节。
相比与定长格式,变长格式有什么优点:
(1).定长格式适合对整个值域空间中分布均匀的数值进行编码,大多数数值变量的分布都不均匀,而且变长格式 一般更节省空间。
(2).还有,就是变长格式的VIntWritable和VLlongWritable可以转换,因为他们的编码实际上一致!选择变长格式,更有增长空间。
通过上面,可以知道,变长格式的范围是1~5个字节,那么什么时候是5个字节,什么时候又是3个字节呢?
| 整数的范围 | 序列化字节的大小(字节) |
| -127~127 (-2^7 - 1 ~ 2^7 -1 ) | 1 |
| -256(2的8次方)~ -128 或者 128~255 | 2 |
| -65536(2的16次方)~ -257 或者 256~65535 | 3 |
| -16777216(2的24次方) ~ -65537 或者 65536 ~ 16777215 | 4 |
| -2147483648(2的31次方) ~ -16777217 或者 16777216 ~ 2147483647 | 5 |
问题:
《Hadoop权威指南》上说,需要编码的数值如果相当小(在-127和127之间,包括-127和127),变长格式就只用一个字节进行编码!理论上,我也认为是正确的,但是,我用代码测试了以下,发现-127~-113之间,占用的是2个字节。如下面的例子以及运行结果:
Example:
package cn.roboson.writable; import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.VIntWritable;
import org.apache.hadoop.io.Writable;
/**
* 这个例子,主要是为了区分定长和变长,还有就是变长的范围
* 1.先定义两个IntWritable
* 2.分别序列化这两个类
* 3.比较序列化后字节大小
* @author roboson
*
*/ public class IntWritableTest { public static void main(String[] args) throws IOException { //定义两个比较小的IntWritable,序列化后1个字节的临界点,《Hadoop权威指南》中所说的是-127~127,但是,我发现只能是-112~127
//超过-112后,就成为2个字节了
IntWritable writable = new IntWritable(127);
VIntWritable vwritable = new VIntWritable(-112);
show(writable,vwritable); //验证不是从-127~127
writable.set(-113);
vwritable.set(-113);
show(writable,vwritable); //序列化后两个字节大小的范围 -256(2的8次方)~ -128 或者 128~255
writable.set(-256);
vwritable.set(-256);
show(writable,vwritable); //序列化后3个字节大小的范围 -65536(2的16次方)~ -257 或者 256~65535
writable.set(-65536);
vwritable.set(-65536);
show(writable,vwritable); //序列化后4个字节大小的范围 -16777216(2的24次方) ~ -65537 或者 65536 ~ 16777215
writable.set(-16777216);
vwritable.set(-16777216);
show(writable,vwritable); //序列化后4个字节大小的范围 -2147483648(2的31次方) ~ -16777217 或者 16777216 ~ 2147483647
writable.set(-2147483648);
vwritable.set(-2147483648);
show(writable,vwritable);
} public static byte[] serizlize(Writable writable) throws IOException{ //创建一个输出字节流对象
ByteArrayOutputStream out = new ByteArrayOutputStream();
DataOutputStream dataout = new DataOutputStream(out); //将结构化数据的对象writable写入到输出字节流。
writable.write(dataout);
return out.toByteArray();
} public static byte[] deserizlize(Writable writable,byte[] bytes) throws IOException{ //创建一个输入字节流对象,将字节数组中的数据,写入到输入流中
ByteArrayInputStream in = new ByteArrayInputStream(bytes);
DataInputStream datain = new DataInputStream(in); //将输入流中的字节流数据反序列化
writable.readFields(datain);
return bytes; } public static void show(Writable writable,Writable vwritable) throws IOException{
//对上面两个进行序列化
byte[] writablebyte = serizlize(writable);
byte[] vwritablebyte = serizlize(vwritable); //分别输出字节大小
System.out.println("定长格式"+writable+"序列化后字节长大小:"+writablebyte.length );
System.out.println("变长格式"+vwritable+"序列化后字节长大小:"+vwritablebyte.length );
}
}
运行结果:

先到这,后面的数据类型,下次继续
Hadoop中Writable类的更多相关文章
- Hadoop中Writable类之四
1.定制Writable类型 Hadoop中有一套Writable实现,例如:IntWritable.Text等,但是,有时候可能并不能满足自己的需求,这个时候,就需要自己定制Writable类型. ...
- Hadoop中Writable类之三
1.BytesWritable <1>定义 ByteWritable是对二进制数据组的封装.它的序列化格式为一个用于指定后面数据字节数的整数域(4个字节),后跟字节本身. 举个例子,假如有 ...
- Hadoop中Writable类之二
1.ASCII.Unicode.UFT-8 在看Text类型的时候,里面出现了上面三种编码,先看看这三种编码: ASCII是基于拉丁字母的一套电脑编码系统.它主要用于显示现代英语和其他西欧语言.它是现 ...
- hadoop中Text类 与 java中String类的区别
hadoop 中 的Text类与java中的String类感觉上用法是相似的,但两者在编码格式和访问方式上还是有些差别的,要说明这个问题,首先得了解几个概念: 字符集: 是一个系统支持的所有抽象字符的 ...
- hadoop中典型Writable类详解
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable.html,转载请注明源地址. Hadoop将很多Writable类归入org.apac ...
- hadoop中实现定制Writable类
Hadoop中有一套Writable实现可以满足大部分需求,但是在有些情况下,我们需要根据自己的需要构造一个新的实现,有了定制的Writable,我们就可以完全控制二进制表示和排序顺序. 为了演示如何 ...
- hadoop中的序列化与Writable类
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable-class.html,转载请注明源地址. hadoop中自带的org.apache.h ...
- hadoop中的序列化与Writable接口
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable-interface.html,转载请注明源地址. 简介 序列化和反序列化就是结构化对象 ...
- Hadoop中序列化与Writable接口
学习笔记,整理自<Hadoop权威指南 第3版> 一.序列化 序列化:序列化是将 内存 中的结构化数据 转化为 能在网络上传输 或 磁盘中进行永久保存的二进制流的过程:反序列化:序列化的逆 ...
随机推荐
- Linux学习笔记 - Shell 控制语句
if 语句 语法: #!/bin/bash a= b= if [ $a -eq $b ] then echo "a 等于 b" elif [ $a -gt $b ] then ec ...
- python学习 (三十三) Modules
1: 方法一: 导入整个模块 import math class ModulesDemo(): def builtin_modules(self): print(math.sqrt()) m = Mo ...
- Centos 文件查找命令
find [搜索范围] [搜索条件] #搜索文件 find / -name install.log #避免大范围搜索,会非常耗费系统资源 #find是在系统当中搜索符合条件的文件名.如果需要匹配,使用 ...
- EntityFramework 常见用法汇总
1.Code First 启用存储过程映射实体 1 protected override void OnModelCreating(DbModelBuilder modelBuilder) 2 { 3 ...
- Node.js的适用场景
高并发.聊天.实时消息推送.服务器做前端资源压缩
- [Cpp primer] Namespace using Declarations
If we want to use cin in the standard library, we need to std::cin To simplify this work, we can do ...
- Tkinter Fonts(字体)
Python GUI - Tkinter Fonts:作为一个tuple的第一个元素是字体家族,一个点的大小,可选择一个字符串,包含一个或更多的粗体,斜体,下划线的样式修饰符,加粗. 最多可能有三 ...
- 2018-2019-2 《网络对抗技术》Exp7 网络欺诈防范 Week10 20165233
Exp7 网络欺诈防范 目录 一.基础问题 二.实验步骤 实验点一:简单应用SET工具建立冒名网站 实验点二:ettercap DNS spoof 实验点三:结合应用两种技术,用DNS spoof引导 ...
- requirejs——config
config 函数用于requirejs的配置信息.主要包括:baseUrl.paths: 一.baseUrl: 待续
- Spring boot + Gradle + Eclipse打war包发布总结
首先感谢两位博主的分享 http://lib.csdn.net/article/git/55444?knId=767 https://my.oschina.net/alexnine/blog/5406 ...