SSD固态盘应用于Ceph集群的四种典型使用场景
在虚拟化及云计算技术大规模应用于企业数据中心的科技潮流中,存储性能无疑是企业核心应用是否虚拟化、云化的关键指标之一。传统的做法是升级存储设备,但这没解决根本问题,性能和容量不能兼顾,并且解决不好设备利旧问题。因此,企业迫切需要一种大规模分布式存储管理软件,能充分利用已有硬件资源,在可控成本范围内提供最佳的存储性能,并能根据业务需求变化,从容量和性能两方面同时快速横向扩展。这就是Server SAN兴起的现实基础。
Ceph作为Server SAN的最典型代表,可对外提供块、对象、文件服务的分布式统一存储系统,不可避免成为关注热点,越来越多的企业在生产环境部署和使用Ceph集群,截止今年4月份为止,云计算提供商DreamHost、欧洲核子研究中心CERN等企业已有3PB规模数据量的Ceph生产环境。
Ceph先进的架构,加上SSD固态盘,特别是高速PCIe SSD带来的高性能,无疑将成为Ceph部署的典型场景。同时,由于SSD相对昂贵的价格及企业已有设备的利旧考虑,如何控制成本,利用少量的SSD盘来达到关键业务(如电信计费系统的数据库业务等)对性能的要求,做到性能和成本的最佳平衡点,是用好Ceph的关键。下面讨论Ceph集群中SSD盘四种典型使用场景:
1. 作为OSD的日志盘
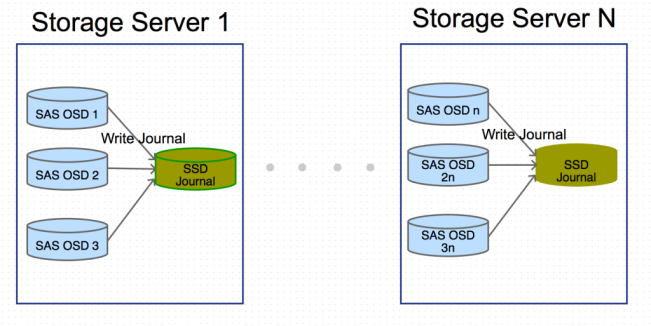
Ceph使用日志来提高性能及保证数据一致性。使用快速的SSD作为OSD的日志盘来提高集群性能是SSD应用于Ceph环境中最常见的使用场景。由于OSD日志读写的特点,在选择SSD盘时,除了关注IOPS性能外,要重点注意以下3个方面:
1)写密集场景
OSD日志是大量小数据块、随机IO写操作。选购SSD作为日志盘,需要重点关注随机、小块数据、写操作的吞吐量及IOPS;当一块SSD作为多个OSD的日志盘时,因为涉及到多个OSD同时往SSD盘写数据,要重点关注顺序写的带宽。
2)分区对齐
在对SSD分区时,使用Parted进行分区并保证4KB分区对齐,避免分区不当带来的性能下降。
3)O_DIRECT和O_DSYNC写模式及写缓存
由Ceph源码可知(ceph/src/os/FileJournal.cc),OSD在写日志文件时,使用的flags是:
- flags |= O_DIRECT | O_DSYNC
O_DIRECT表示不使用Linux内核Page Cache; O_DSYNC表示数据在写入到磁盘后才返回。
由于磁盘控制器也同样存在缓存,而Linux操作系统不负责管理设备缓存,O_DSYNC在到达磁盘控制器缓存之后会立即返回给调用者,并无法保证数据真正写入到磁盘中,Ceph致力于数据的安全性,对用来作为日志盘的设备,应禁用其写缓存。(# hdparm -W 0 /dev/hda 0)
使用工具测试SSD性能时,应添加对应的flag:dd … oflag=direct,dsync; fio … —direct=1, —sync=1…
2. 与SATA、SAS硬盘混用,但独立组成全SSD的Pool
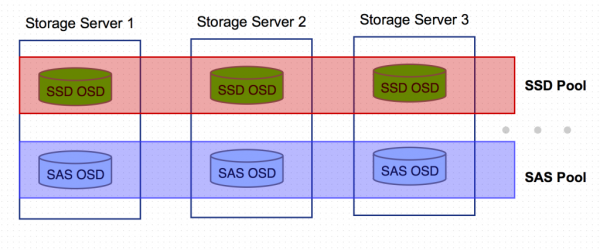
基本思路是编辑CRUSH MAP,先标示出散落在各存储服务器的SSD OSD以及硬盘OSD(host元素),再把这两种类型的OSD聚合起来形成两种不同的数据根(root元素),然后针对两种不同的数据源分别编写数据存取规则(rule元素),最后,创建SSD Pool,并指定其数据存取操作都在SSD OSD上进行。
在该场景下,同一个Ceph集群里存在传统机械盘组成的存储池,以及SSD组成的快速存储池,可把对读写性能要求高的数据存放在SSD池,而把备份数据存放在普通存储池。
对应于Ceph作为OpenStack里统一存储后端,各组件所使用的四个存储池:Glance Pool存放镜像及虚拟机快照、Nova Pool存放虚拟机系统盘、Cinder Volume Pool存放云硬盘及云硬盘快照、Cinder Backup Pool存放云硬盘备份,可以判断出,Nova及Cinder Volume存储池对IO性能有相对较高的要求,并且大部分都是热数据,可存放在SSD Pool;而Glance和Cinder Backup存储池作为备份冷数据池,对性能要求相对较低,可存放在普通存储池。
这种使用场景,SSD Pool里的主备数据都是在SSD里,但正常情况下,Ceph客户端直接读写的只有主数据,这对相对昂贵的SSD来说存在一定程度上的浪费。这就引出了下一个使用场景—配置CRUSH数据读写规则,使主备数据中的主数据落在SSD的OSD上。
Ceph里的命令操作不详细叙述,简单步骤示例如下:
1)标示各服务器上的SSD与硬盘OSD
- # SAS HDD OSD
- host ceph-server1-sas {
- id -2
- alg straw
- hash 0
- item osd.0 weight 1.000
- item osd.1 weight 1.000
- …
- }
- # SSD OSD
- host ceph-server1-ssd {
- id -2
- alg straw
- hash 0
- item osd.2 weight 1.000
- …
- }
2) 聚合OSD,创建数据根
- root sas {
- id -1
- alg straw
- hash 0
- item ceph-server1-sas
- …
- item ceph-servern-sas
- }
- root ssd {
- id -1
- alg straw
- hash 0
- item ceph-server1-ssd
- …
- item ceph-servern-ssd
- }
3)创建存取规则
- rule sas {
- ruleset 0
- type replicated
- …
- step take sas
- step chooseleaf firstn 0 type host
- step emit
- }
- rule ssd {
- ruleset 1
- type replicated
- …
- step take ssd
- step chooseleaf firstn 0 type host
- step emit
- }
4)编译及使用新的CRUSH MAP
- # crushtool -c ssd_sas_map.txt -o ssd_sas_map
- # ceph osd setcrushmap -i ssd_sas_map
5)创建Pool并指定存取规则
- # ceph osd pool create ssd 4096 4096
- # ceph osd pool set ssd crush_ruleset 1
3. 配置CRUSH数据读写规则,使主备数据中的主数据落在SSD的OSD上
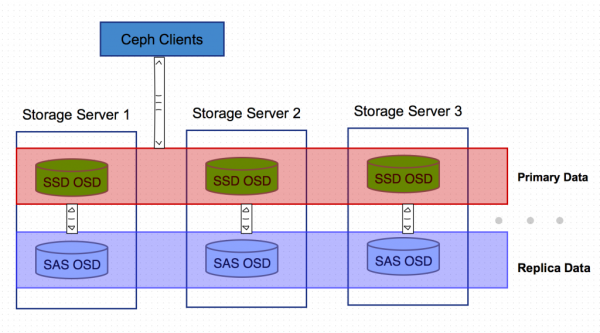
该场景基本思路和第二种类似,SATA/SAS机械盘和SSD混用,但SSD的OSD节点不用来组成独立的存储池,而是配置CURSH读取规则,让所有数据的主备份落在SSD OSD上。Ceph集群内部的数据备份从SSD的主OSD往非SSD的副OSD写数据。
这样,所有的Ceph客户端直接读写的都是SSD OSD 节点,既提高了性能又节约了对OSD容量的要求。
配置重点是CRUSH读写规则的设置,关键点如下:
- rule ssd-primary {
- ruleset 1
- …
- step take ssd
- step chooseleaf firstn 1 type host #从SSD根节点下取1个OSD存主数据
- step emit
- step take sas
- step chooseleaf firstn -1 type host #从SAS根节点下取其它OSD节点存副本数据
- step emit
- }
4. 作为Ceph Cache Tiering技术中的Cache层
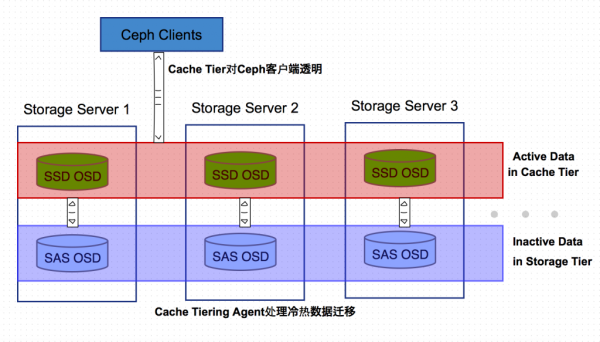
Cache Tiering的基本思想是冷热数据分离,用相对快速/昂贵的存储设备如SSD盘,组成一个Pool来作为Cache层,后端用相对慢速/廉价的设备来组建冷数据存储池。
Ceph Cache Tiering Agent处理缓存层和存储层的数据的自动迁移,对客户端透明操作透明。Cahe层有两种典型使用模式:
1)Writeback模式
Ceph客户端直接往Cache层写数据,写完立即返回,Agent再及时把数据迁移到冷数据池。当客户端取不在Cache层的冷数据时,Agent负责把冷数据迁移到Cache层。也就是说,Ceph客户端直接在Cache层上进行IO读写操作,不会与相对慢速的冷数据池进行数据交换。
这种模式适用于可变数据的操作,如照片/视频编辑、电商交易数据等等。
2)只读模式
Ceph客户端在写操作时往后端冷数据池直接写,读数据时,Ceph把数据从后端读取到Cache层。
这种模式适用于不可变数据,如微博/微信上的照片/视频、DNA数据、X射线影像等。
CRUSH算法是Ceph集群的核心,在深刻理解CRUSH算法的基础上,利用SSD的高性能,可利用较少的成本增加,满足企业关键应用对存储性能的高要求。
附. 名词解释:
- I. Ceph: 开源分布式统一存储(块、对象、文件)项目。
- II. Ceph OSD:Ceph Object Store Device的缩写,可以指Ceph里的一个存储单元,也可以指Ceph里的OSD管理进程。每台服务器上可运行多个OSD进程,典型的Ceph集群由奇数个Monitor节点和多个OSD节点组成。
- III. CRUSH:CRUSH算法是Ceph的核心模块,它通过计算数据存储位置来决定如何存取数据,同时也让Ceph客户端可以直接和各OSD节点通信而不是一个中心节点,这样,避免了Ceph集群的单点故障、性能瓶颈,极大增强了线性扩展能力。
- IV. SSD:Solid State Drive,固态盘,不解释。
- V. SATA/SAS/PCIe:不同数据总线接口。高端存储里大部分存储节点采用PCIe技术进行互联;PCIe接口SSD也是大势所趋。SATA和SAS,一个指令集是ATA,一个是SCSI,两者都可用来作为机械盘或固态盘的接口。
- VI. 几种写缓存模式:
- Write-through:向高速Cache写入数据时同时也往后端慢速设备写一份,两者都写完才返回。
- Write-back:向高速Cache写完数据后立即返回,数据不保证立即写入后端设备。给调用者的感觉是速度快,但需要额外的机制来防止掉电带来的数据不一致。
- none:禁用写缓存,直接往Cache后端慢速设备写数据。
- 计算机内各级存储设备都存在Cache机制(CPU寄存器->L1缓存->L2缓存->内存->设备控制器缓存->物理设备)
SSD固态盘应用于Ceph集群的四种典型使用场景的更多相关文章
- CEPH集群操作入门--配置
参考文档:CEPH官网集群操作文档 概述 Ceph存储集群是所有Ceph部署的基础. 基于RADOS,Ceph存储集群由两种类型的守护进程组成:Ceph OSD守护进程(OSD)将数据作为对象 ...
- ceph集群部署
最近在学习 kubernetes 过程中,想实现 pod 数据的持久化.在调研的过程中,发现 ceph 在最近几年发展火热,也有很多案例落地企业.在选型方面,个人更加倾向于社区火热的项目,Gluste ...
- ceph-deploy离线部署ceph集群及报错解决FAQ
ceph-deploy部署ceph集群 环境介绍 主机名 ip地址 操作系统 角色 备注 ceph-node1 10.153.204.13 Centos7.6 mon.osd.mds.mgr.rgw. ...
- CEPH-5:ceph集群基本概念与管理
ceph集群基本概念与管理 ceph集群基本概念 ceph集群整体结构图 名称 作用 osd 全称Object Storage Device,主要功能是存储数据.复制数据.平衡数据.恢复数据等.每个O ...
- 分布式存储系统之Ceph集群存储池操作
前文我们了解了ceph的存储池.PG.CRUSH.客户端IO的简要工作过程.Ceph客户端计算PG_ID的步骤的相关话题,回顾请参考https://www.cnblogs.com/qiuhom-187 ...
- 分布式存储系统之Ceph集群RBD基础使用
前文我们了解了Ceph集群cephx认证和授权相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/16748149.html:今天我们来聊一聊ceph集群的 ...
- ceph集群性能测试结果
对ceph存储集群(8台万兆服务器)从以下几个方面进行测试的结果 1.读写稳定性 无故障下的ceph集群性能完全满足业务对磁盘性能的需求. 测试数据结果如下表1-1,1-2 2.业务稳定性 ceph集 ...
- ubuntu 16.04安装ceph集群(双节点)
Ceph是一个分布式存储,可以提供对象存储.块存储和文件存储,其中对象存储和块存储可以很好地和各大云平台集成.一个Ceph集群中有Monitor节点.MDS节点(可选,用于文件存储).至少两个OSD守 ...
- 小型ceph集群的搭建
了解ceph DFS(distributed file system)分布式存储系统,指文件系统管理的物理存储资源,不一定直接连接在本地节点上,而是通过计算机网络与节点相连,众多类别中,ceph是当下 ...
随机推荐
- React-Native进阶_5.导航 Naviagtion
有这样一个组件 他可以控制页面跳转 返回,在移动端叫做导航控制器, 在RN中叫路由 我们使用的 react-native-navigation 是一个开源组件库介绍:A complete nativ ...
- Synchronized之一:基本使用
目录: <Java并发编程之三:volatile关键字解析 转载> <Synchronized之一:基本使用> Synchronized作用 1.Synchronized可以保 ...
- python使用progressbar显示进度条
progressbar安装: pip install progressbar 用法一 # -*- coding=utf-8 -*- import time from progressbar impor ...
- Swift GCD
var queue: dispatch_queue_t = dispatch_get_main_queue()// 主线程 queue = dispatch_get_global_queue(DISP ...
- html 刷新 按钮 代码
<input type=button value=刷新 onclick="history.go(0)"> <input type=button value=刷新 ...
- C/C++比较容易搞混的一些写法
#include <stdio.h> int main() { int a = 101; char ch = *(char *)&a; //*(char *)&a:含义就是 ...
- 使用POI对excel进行操作生成二维数组
import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import ja ...
- python笔记-11 rabbitmq
一.理解rabbitmq的基本背景 1.理解消息队列 1.1 普通queue 在前面的博客中所提到的队列,此处均称之为普通队列 简述一下普通队列的一些分类及不足 1.1.1 基本Queue:queue ...
- 重温CLR(十三) 定制特性
利用定制特性,可宣告式为自己的代码构造添加注解来实现特殊功能.定制特性允许为几乎每一个元数据表记录项定义和应用信息.这种可扩展的元数据信息能在运行时查询,从而动态改变代码的执行方式.使用各种.NET技 ...
- 百度地图API秘钥生成步骤
百度API