Beautiful Soup解析网页
使用前步骤:
1.Beautiful Soup目前已经被移植到bs4,所以导入Beautiful Soup时先安装bs4库。
2.安装lxml库:如果不使用此库,就会使用Python默认的解析器,而lxml具有功能更加强大、速度更快的特点。
爬取:http://www.cntour.cn/
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:XXC
import requests
from bs4 import BeautifulSoup
import re url="http://www.cntour.cn/" #需要爬取的网址
strhtml = requests.get(url); #使用GET方式,获取网页数据 soup = BeautifulSoup(strhtml.text,'lxml') #HTML文档将被转换成Unicode
# 编码格式,然后BeautifulSoup选择最适合的解析器来解析文档,此处指定
# lxml解析器,解析后转换成属性结构,每个节点都是Python对象,保存在变量soup中
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a') #采用select选择器定位数据
for item in data: #数据清洗和组织数据
result = {
'title':item.get_text(), #获得a标签的文本内内容
'link':item.get('href'), #获得a标签的href属性
'ID':re.findall('\d+',item.get('href')) #使用正则匹配其中的数字,\d匹配数字,+匹配一个字符一次或多次
}
print(result)
结果:
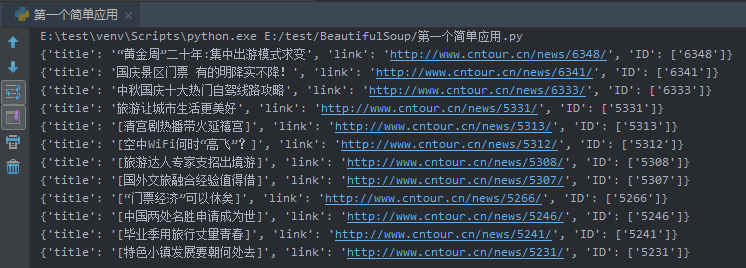
Beautiful Soup解析网页的更多相关文章
- Python Beautiful Soup 解析库的使用
Beautiful Soup 借助网页的结构和属性等特性来解析网页,这样就可以省去复杂的正则表达式的编写. Beautiful Soup是Python的一个HTML或XML的解析库. 1.解析器 解析 ...
- 爬虫5_python2_使用 Beautiful Soup 解析数据
使用 Beautiful Soup 解析数据(感谢东哥) 有的小伙伴们对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Beautiful Soup,有了它我们可以很方便地提取出HT ...
- Beautiful Soup解析库的安装和使用
Beautiful Soup是Python的一个HTML或XML的解析库,我们可以用它来方便地从网页中提取数据.它拥有强大的API和多样的解析方式.官方文档:https://www.crummy.co ...
- Python爬虫之Beautiful Soup解析库的使用(五)
Python爬虫之Beautiful Soup解析库的使用 Beautiful Soup-介绍 Python第三方库,用于从HTML或XML中提取数据官方:http://www.crummv.com/ ...
- 用Beautiful Soup解析html源码
#xiaodeng #python3 #用Beautiful Soup解析html源码 html_doc = """ <html> <head> ...
- Python爬虫系列(四):Beautiful Soup解析HTML之把HTML转成Python对象
在前几篇文章,我们学会了如何获取html文档内容,就是从url下载网页.今天开始,我们将讨论如何将html转成python对象,用python代码对文档进行分析. (牛小妹在学校折腾了好几天,也没把h ...
- 爬虫(五)—— 解析库(二)beautiful soup解析库
目录 解析库--beautiful soup 一.BeautifulSoup简介 二.安装模块 三.Beautiful Soup的基本使用 四.Beautiful Soup查找元素 1.查找文本.属性 ...
- Beautiful Soup 解析html表格
from bs4 import BeautifulSoup import urllib.request doc = urllib.request.urlopen('http://www.bkzy.or ...
- Python3编写网络爬虫06-基本解析库Beautiful Soup的使用
二.Beautiful Soup 简介 就是python的一个HTML或XML的解析库 可以用它来很方便的从网页中提取数据 0.1 提供一些简单的 python式的函数来处理导航,搜索,修改分析树等功 ...
随机推荐
- vpp命令总结
create sub BondEthernet0 834 创建子接口,tag是834 set interface ip table BondEthernet0.834 1 将此接口设置在fib 1里 ...
- LoadRunner11学习记录五 -- 错误提示分析
LoadRunner测试结果具体分析: 一.错误提示分析 分析实例: 1.Error: Failed to connect to server “172.17.7.230″: [10060] Con ...
- java简单例子介绍IOC和AOP
IOC和AOP的一些基本概念 介绍 IOC 一.什么是IOC IoC就是Inversion of Control,控制反转.在Java开发中,IoC意味着将你设计好的类交给系统去控制,而不是在你的类内 ...
- twitter集成第三方登录是窗口一直出现闪退的解决方法
需要创建自己的token,如下图
- Visual Studio 2015 开发 ASP.NET 5 有何变化?(转)
出处:http://www.cnblogs.com/xishuai/p/visual-studio-2015-preview-asp-net-5-change.html 本篇博文目录: ASP.NET ...
- 团体程序设计天梯赛L2-003 月饼 2017-03-22 18:17 42人阅读 评论(0) 收藏
L2-003. 月饼 时间限制 100 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 陈越 月饼是中国人在中秋佳节时吃的一种传统食品,不同地区有许多不 ...
- python读取pop3服务器邮件并且下载
# -*- coding: cp936 -*- import poplib import random import os def getmail(): # 蒋辉文拥有该程序权利 你可以随意使用 em ...
- RPM管理,计划任务与性能监控
=========== RPM 软件包管理: 相关命令: rpm -ivh 软件包名称 rpm -e 软件包名称 rpm -U 软件名称 软件包信息查询: 相关命令: rpm -q 查询指定软 ...
- Java的StringTokenizer类
StringTokenizer是java中object类的一个子类,继承自 Enumeration接口.此类允许一个应用程序进入一个令牌(tokens),而且StringTokenizer类用起来比S ...
- Sublime Text 3 Settings
Preferences - Setting User - > : { "font_size": 14, "word_wrap": true, " ...