Hadoop案例(七)MapReduce中多表合并
MapReduce中多表合并案例
一.案例需求
订单数据表t_order:
|
id |
pid |
amount |
|
1001 |
01 |
1 |
|
1002 |
02 |
2 |
|
1003 |
03 |
3 |
订单数据order.txt
商品信息表t_product
|
pid |
pname |
|
01 |
小米 |
|
02 |
华为 |
|
03 |
格力 |
商品数据pd.txt
小米
华为
格力
将商品信息表中数据根据商品pid合并到订单数据表中。
最终数据形式:
|
id |
pname |
amount |
|
1001 |
小米 |
1 |
|
1004 |
小米 |
4 |
|
1002 |
华为 |
2 |
|
1005 |
华为 |
5 |
|
1003 |
格力 |
3 |
|
1006 |
格力 |
6 |
二.reduce端表合并(数据倾斜)
通过将关联条件作为map输出的key,将两表满足join条件的数据并携带数据所来源的文件信息,发往同一个reduce task,在reduce中进行数据的串联。
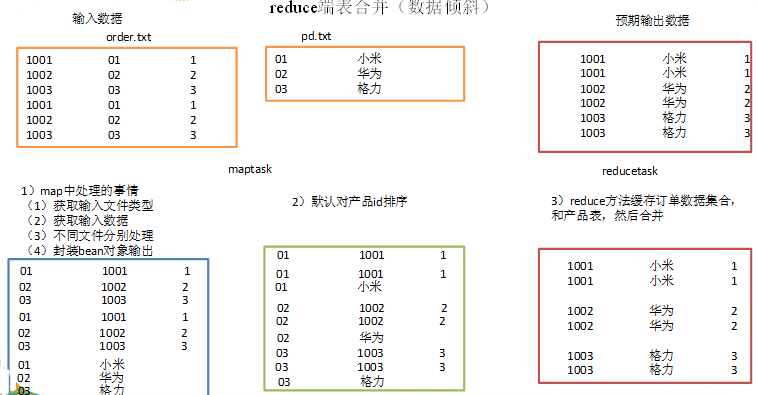
1)创建商品和订合并后的bean类
package com.xyg.mapreduce.table; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable; public class TableBean implements Writable {
private String order_id; // 订单id
private String p_id; // 产品id
private int amount; // 产品数量
private String pname; // 产品名称
private String flag;// 表的标记 public TableBean() {
super();
} public TableBean(String order_id, String p_id, int amount, String pname, String flag) {
super();
this.order_id = order_id;
this.p_id = p_id;
this.amount = amount;
this.pname = pname;
this.flag = flag;
} public String getFlag() {
return flag;
} public void setFlag(String flag) {
this.flag = flag;
} public String getOrder_id() {
return order_id;
} public void setOrder_id(String order_id) {
this.order_id = order_id;
} public String getP_id() {
return p_id;
} public void setP_id(String p_id) {
this.p_id = p_id;
} public int getAmount() {
return amount;
} public void setAmount(int amount) {
this.amount = amount;
} public String getPname() {
return pname;
} public void setPname(String pname) {
this.pname = pname;
} @Override
public void write(DataOutput out) throws IOException {
out.writeUTF(order_id);
out.writeUTF(p_id);
out.writeInt(amount);
out.writeUTF(pname);
out.writeUTF(flag);
} @Override
public void readFields(DataInput in) throws IOException {
this.order_id = in.readUTF();
this.p_id = in.readUTF();
this.amount = in.readInt();
this.pname = in.readUTF();
this.flag = in.readUTF();
} @Override
public String toString() {
return order_id + "\t" + pname + "\t" + amount + "\t" ;
}
}
2)编写TableMapper程序
package com.xyg.mapreduce.table; import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class TableMapper extends Mapper<LongWritable, Text, Text, TableBean>{
TableBean bean = new TableBean();
Text k = new Text(); @Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException { // 1 获取输入文件类型
FileSplit split = (FileSplit) context.getInputSplit();
String name = split.getPath().getName(); // 2 获取输入数据
String line = value.toString(); // 3 不同文件分别处理
if (name.startsWith("order")) {// 订单表处理
// 3.1 切割
String[] fields = line.split(","); // 3.2 封装bean对象
bean.setOrder_id(fields[]);
bean.setP_id(fields[]);
bean.setAmount(Integer.parseInt(fields[]));
bean.setPname("");
bean.setFlag(""); k.set(fields[]);
}else {// 产品表处理
// 3.3 切割
String[] fields = line.split(","); // 3.4 封装bean对象
bean.setP_id(fields[]);
bean.setPname(fields[]);
bean.setFlag("");
bean.setAmount();
bean.setOrder_id(""); k.set(fields[]);
}
// 4 写出
context.write(k, bean);
}
}
3)编写TableReducer程序
package com.xyg.mapreduce.table;
import java.io.IOException;
import java.util.ArrayList;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class TableReducer extends Reducer<Text, TableBean, TableBean, NullWritable> { @Override
protected void reduce(Text key, Iterable<TableBean> values, Context context) throws IOException, InterruptedException { // 1准备存储订单的集合
ArrayList<TableBean> orderBeans = new ArrayList<>();
// 2 准备bean对象
TableBean pdBean = new TableBean(); for (TableBean bean : values) { if ("".equals(bean.getFlag())) {// 订单表
// 拷贝传递过来的每条订单数据到集合中
TableBean orderBean = new TableBean();`
try {
BeanUtils.copyProperties(orderBean, bean);
} catch (Exception e) {
e.printStackTrace();
} orderBeans.add(orderBean);
} else {// 产品表
try {
// 拷贝传递过来的产品表到内存中
BeanUtils.copyProperties(pdBean, bean);
} catch (Exception e) {
e.printStackTrace();
}
}
} // 3 表的拼接
for(TableBean bean:orderBeans){
bean.getPname(pdBean.getPname()); // 4 数据写出去
context.write(bean, NullWritable.get());
}
}
}
4)编写TableDriver程序
package com.xyg.mapreduce.table; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TableDriver { public static void main(String[] args) throws Exception {
// 1 获取配置信息,或者job对象实例
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration); // 2 指定本程序的jar包所在的本地路径
job.setJarByClass(TableDriver.class); // 3 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(TableMapper.class);
job.setReducerClass(TableReducer.class); // 4 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(TableBean.class); // 5 指定最终输出的数据的kv类型
job.setOutputKeyClass(TableBean.class);
job.setOutputValueClass(NullWritable.class); // 6 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[]));
FileOutputFormat.setOutputPath(job, new Path(args[])); // 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
boolean result = job.waitForCompletion(true);
System.exit(result ? : );
}
}
3)运行程序查看结果
1001 小米 1
1001 小米 1
1002 华为 2
1002 华为 2
1003 格力 3
1003 格力 3
缺点:这种方式中,合并的操作是在reduce阶段完成,reduce端的处理压力太大,map节点的运算负载则很低,资源利用率不高,且在reduce阶段极易产生数据倾斜
解决方案: map端实现数据合并
三.map端表合并(Distributedcache)
1.分析
适用于关联表中有小表的情形;
可以将小表分发到所有的map节点,这样,map节点就可以在本地对自己所读到的大表数据进行合并并输出最终结果,可以大大提高合并操作的并发度,加快处理速度。

2.实操案例
(1)先在驱动模块中添加缓存文件
package test;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class DistributedCacheDriver { public static void main(String[] args) throws Exception {
// 1 获取job信息
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration); // 2 设置加载jar包路径
job.setJarByClass(DistributedCacheDriver.class); // 3 关联map
job.setMapperClass(DistributedCacheMapper.class); // 4 设置最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class); // 5 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(args[]));
FileOutputFormat.setOutputPath(job, new Path(args[])); // 6 加载缓存数据
job.addCacheFile(new URI("file:///e:/inputcache/pd.txt")); // 7 map端join的逻辑不需要reduce阶段,设置reducetask数量为0
job.setNumReduceTasks(); // 8 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? : );
}
}
(2)读取缓存的文件数据
package test;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class DistributedCacheMapper extends Mapper<LongWritable, Text, Text, NullWritable>{ Map<String, String> pdMap = new HashMap<>(); @Override
protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
// 1 获取缓存的文件
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("pd.txt"),"UTF-8")); String line;
while(StringUtils.isNotEmpty(line = reader.readLine())){
// 2 切割
String[] fields = line.split("\t"); // 3 缓存数据到集合
pdMap.put(fields[], fields[]);
} // 4 关流
reader.close();
} Text k = new Text(); @Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString(); // 2 截取
String[] fields = line.split("\t"); // 3 获取产品id
String pId = fields[]; // 4 获取商品名称
String pdName = pdMap.get(pId); // 5 拼接
k.set(line + "\t"+ pdName); // 6 写出
context.write(k, NullWritable.get());
}
}
Hadoop案例(七)MapReduce中多表合并的更多相关文章
- hadoop学习(七)----mapReduce原理以及操作过程
前面我们使用HDFS进行了相关的操作,也了解了HDFS的原理和机制,有了分布式文件系统我们如何去处理文件呢,这就的提到hadoop的第二个组成部分-MapReduce. MapReduce充分借鉴了分 ...
- Hadoop压缩之MapReduce中使用压缩
1.压缩和输入分片 Hadoop中文件是以块的形式存储在各个DataNode节点中,假如有一个文件A要做为输入数据,给MapReduce处理,系统要做的,首先从NameNode中找到文件A存储在哪些D ...
- Hadoop框架下MapReduce中的map个数如何控制
控制map个数的核心源码 long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job)); //getFormatMinS ...
- MapReduce案例:统计共同好友+订单表多表合并+求每个订单中最贵的商品
案例三: 统计共同好友 任务需求: 如下的文本, A:B,C,D,F,E,OB:A,C,E,KC:F,A,D,ID:A,E,F,LE:B,C,D,M,LF:A,B,C,D,E,O,MG:A,C,D,E ...
- mysql两表合并,对一列数据进行处理
加班一时爽,一直加班~一直爽~ 欢迎收看http://www.996.icu/ 今天弄了下MySQL中两表合并的并且要处理一列数据,这列数据原来都是小写字母,处理时将这列数据改成驼峰命名的~~ 基本 ...
- Hadoop学习笔记—12.MapReduce中的常见算法
一.MapReduce中有哪些常见算法 (1)经典之王:单词计数 这个是MapReduce的经典案例,经典的不能再经典了! (2)数据去重 "数据去重"主要是为了掌握和利用并行化思 ...
- 从Hadoop框架与MapReduce模式中谈海量数据处理(含淘宝技术架构) (转)
转自:http://blog.csdn.net/v_july_v/article/details/6704077 从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到 ...
- hadoop笔记之MapReduce的应用案例(利用MapReduce进行排序)
MapReduce的应用案例(利用MapReduce进行排序) MapReduce的应用案例(利用MapReduce进行排序) 思路: Reduce之后直接进行结果合并 具体样例: 程序名:Sort. ...
- MapReduce 示例:减少 Hadoop MapReduce 中的侧连接
摘要:在排序和reducer 阶段,reduce 侧连接过程会产生巨大的网络I/O 流量,在这个阶段,相同键的值被聚集在一起. 本文分享自华为云社区<MapReduce 示例:减少 Hadoop ...
随机推荐
- 特征点检测学习_2(surf算法)
依旧转载自作者:tornadomeet 出处:http://www.cnblogs.com/tornadomeet 特征点检测学习_2(surf算法) 在上篇博客特征点检测学习_1(sift算法) 中 ...
- [CodeForces]String Reconstruction
http://codeforces.com/contest/828/problem/C 并查集的神奇应用. #include<bits/stdc++.h> using namespace ...
- php开启压缩gzip
php服务的开启压缩,节省带宽 看是否开启压缩的网站 http://www.cnblogs.com/GaZeon/p/5421906.html 找到php.ini,修改下面的 ,重启php-fpm z ...
- 高并发大容量NoSQL解决方案探索
大数据时代,企业对于DBA也提出更高的需求.同时,NoSQL作为近几年新崛起的一门技术,也受到越来越多的关注.本文将基于个推SRA孟显耀先生所负责的DBA工作,和大数据运维相关经验,分享两大方向内容: ...
- 正则(?is)
Q:经常看见的正则前面的 (?i) (?s) (?m) (?is) (?im) 是什么意思?A: 称为内联匹配模式,通常用内联匹配模式代替使用枚举值RegexOptions指定的全局匹配模式,写起来更 ...
- tomcat maven插件启动报错tomcat-users.xml cannot be read
tomcat maven插件启动报错tomcat-users.xml cannot be read [ERROR] Failed to execute goal org.codehaus.mojo:t ...
- string的内存本质
虽然没有研究过string的源代码,不过可以确定的是string的内存空间是在堆上开辟的,它自己负责释放空间,不用我们关系. 我们用一个动态分配的字符串指针初始化一个string对象retStr,它会 ...
- HDU3068 最长回文 MANACHER+回文串
原题链接:http://acm.hdu.edu.cn/showproblem.php?pid=3068 Problem Description 给出一个只由小写英文字符a,b,c...y,z组成的字符 ...
- [洛谷P2750] [USACO5.5]贰五语言Two Five
洛谷题目链接:[USACO5.5]贰五语言Two Five 题目描述 有一种奇怪的语言叫做"贰五语言".它的每个单词都由A-Y这25个字母各一个组成.但是,并不是任何一种排列都是一 ...
- System Administrator(构造,图论)
System Administrator time limit per test 2 seconds memory limit per test 256 megabytes input standar ...