Linux输入输出管理
一、系统输入输出的理解
- 运行一个程序时,需要从某个位置读取输入信息,然后CPU处理,最后将输出
显示在屏幕或文件中;其中,某个位置相当于输入设备,屏幕或文件为输出设备。
- 标准输入:stdin,默认是键盘,只能进行读取操作
- 标准输出:stdout,默认是显示屏,只能进行写入操作
- 标准错误:stderr,默认连接是显示屏,只能进行写入操作
二、系统输入输出的管理
1、输出重定向
> ## 重定向正确输出
2> ## 重定向错误输出
&> ## 重定向所有输出
注意:重定向会覆盖源文件内容;一般错误会被重定向到/dev/null中
实例:(以下实验必须在student用户下完成)
- 使用命令*** find /ect/ -name passwd > file *** 定向正确输出到file,并使用cat命令查看:

- 使用命令*** find /etc/ -name passwd 2>file.err *** 定向错误输出到file.err
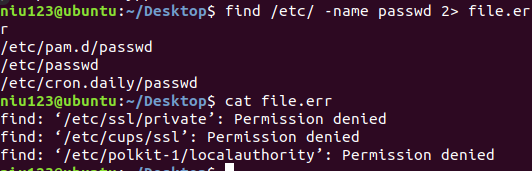
- 命令*** find /etc/ -name passwd &>file.all ***定向所有输出到file中
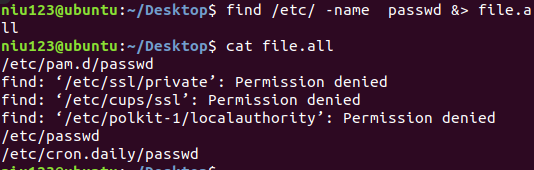
- 使用命令*** >file *** 进行清空file文件

2、输出追加
>> ##追加正确输出到文件最后
2>> ##追加错误输出到文件最后
&>> ##追加所有输出到文件最后
注意:追加不会覆盖源文件,内容会加在源文件末尾
实例:此实例在普通用户下操作
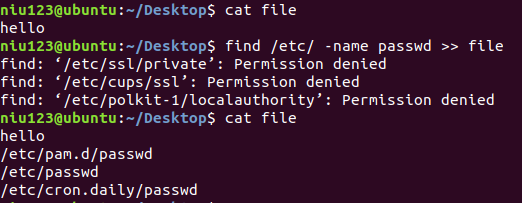
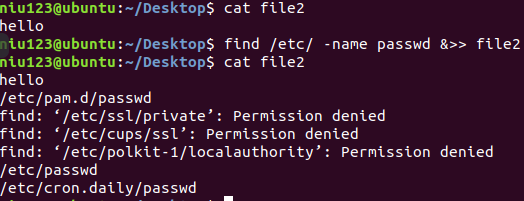
- 使用***find /etc/ -name passwd >> file***命令,把正确结果追加在file文件末尾
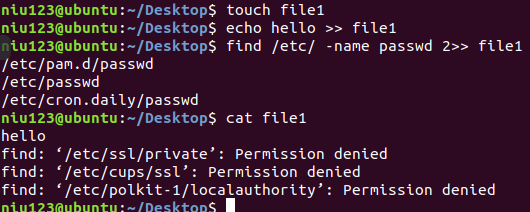
- 使用*** find /etc/ -name passwd 2>> file1 ***命令,把错误结果追加在file1中:
- 使用*** find /etc/ -name passwd &>> file2***命令,把所有输出追加在文件file2中:
3、管道符
- 管道的作用:’|’是把前一条命令的输出变成后一条命令的输入
- 注意:
管道只允许正确输出通过;
通过管道的输入将变成输出,而变成输入的这些输出会被第二条命令处理的;
如果需要保存输出内容,那么要复制一份输出,用到的命令是”tee“;
使用2>&1可以把stderr转换成stdout。
- 实例:(在普通用户下进行操作)
使用***find /etc/ -name passwd | wc -l ***命令时,则会显示出错误结果,正确结果
通过管道后执行wc -l,同时显示行数,结果如下:

使用*** find /etc/ -name passwd 2>&1 | wc -l ***命令,是错误结果通过管道后,在第
二条命令执行,最终显示结果为6:

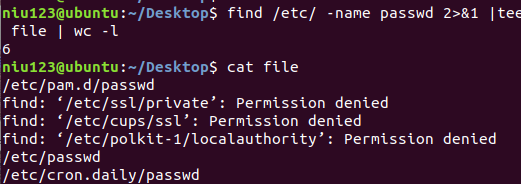
使用***find /etc/ -name passwd 2>&1 | tee file | wc -l***命令,先保存一份输出在file
文件中,并输出行数6,结果如下:(使用tee命令会使file中的内容被覆盖):
4、输入重定向
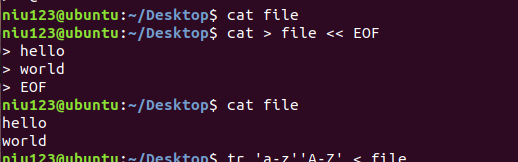
<< ## 重定向输入
实例:重定向输入到文件file中,结果如下:
练习二:
1、显示当前时间,显示格式为hh:mm:ss,并保存到文件time.txt中;
命令:date +%T | tee time.txt

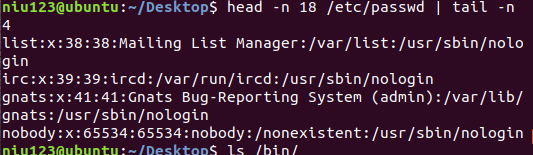
2、显示/etc/passwd 文件的第15-18行内容
命令:head -n 18 /etc/passed | tail -n 4
3、显示/bin中文件包含大写字母的文件,保存在bin_westos_file.txt文件中,并统计个数显示到
屏幕上;
命令:find /bin/ -name *[[:upper:]]* | tee bin_westos_filetxt | wc -l

命令:find /etc/ -name passwd 2>> /dev/null

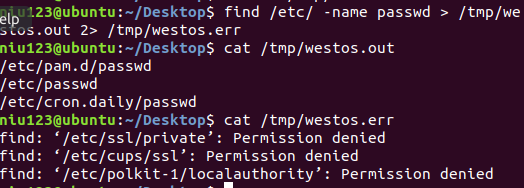
5、在student用户下查找/etc下passwd文件,正确输出保存到/tem/westos.out,错误输出保存
到/tem/westos.err;
find /etc/ -name passwd > /tem/westos.out 1>/tem/westos.err
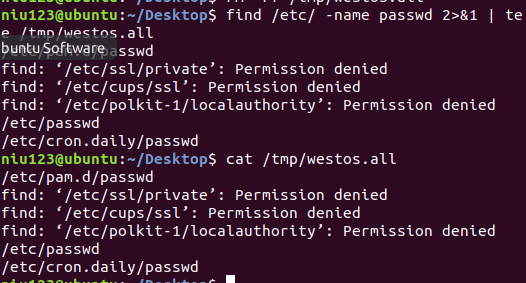
6、在student用户下查找/etc下passed文件,显示命令输出,并保存输出到/tem/westos.all中
命令:find /etc/ -name passwd | tee /tem/westos.all
Linux输入输出管理的更多相关文章
- Linux进程管理(3):总结
7. exit与_exit的差异 为了理解这两个系统调用的差异,先来讨论文件内存缓存区的问题. 在linux中,标准输入输出(I/O)函数都是作为文件来处理.对应于打开的每个文件,在内存中都有对 ...
- Linux进程管理(二)
目录 Linux进程管理(二) 参考 vmstat命令 top命令 Linux进程管理(二)
- 浅谈Linux内存管理机制
经常遇到一些刚接触Linux的新手会问内存占用怎么那么多?在Linux中经常发现空闲内存很少,似乎所有的内存都被系统占用了,表面感觉是内存不够用了,其实不然.这是Linux内存管理的一个优秀特性,在这 ...
- linux内存管理
一.Linux 进程在内存中的数据结构 一个可执行程序在存储(没有调入内存)时分为代码段,数据段,未初始化数据段三部分: 1) 代码段:存放CPU执行的机器指令.通常代码区是共享的,即其它执行程 ...
- Linux软件包管理
Linux软件包管理 Linux软件包管理主要有2类:是二进制包管理.源码包管理 二进制包管理 主要有RPM和YUM两种 RPM包管理 安装 --ivh:-v ,-vv,-vvv显示的安装信息依次详细 ...
- Linux 软件包管理
简介: linux中软件包的管理随着linux版本的不同而不同,一般RPM和DPKG是最常见的两类软件包管理工具.分别应用基于rpm软件包的linux发行版本和基于deb软件包的linux发行版本. ...
- 【CentOS】Linux日常管理
/////////////////////////目录///////////////////////////////////////// 一.日常监控指标相关 1.监控系统状态命令 2.查看系统进程 ...
- linux 用户管理
linux 用户管理 创建一个用户 foo 这个用户只能在/home/foo 上面增加删除文件, foo 不能在其他目录加减文件 useradd -d /home/foo -m foo [root@] ...
- Linux进程管理子系统分析【转】
本文转载自:http://blog.csdn.net/coding__madman/article/details/51298732 Linux进程管理: 进程与程序: 程序:存放在磁盘上的一系列代码 ...
随机推荐
- Git与TortoiseGit使用方法
下载这两个工具 Git地址:https://git-for-windows.github.io/ TortoiseGit地址:http://tortoisegit.org/ 点击 ...
- datanode扩容步骤
新扩容机器规划: hostname ip 进程 slave3 10.183.225.167 datanode,nodemange 1. 修改/etc/hosts 增加新扩容机器的hostname 10 ...
- GATK的硬过滤
https://software.broadinstitute.org/gatk/documentation/article.php?id=2806
- 20145329 《Java程序设计》实验二总结
实验指导教师:娄嘉鹏老师 实验日期:2016.4.12 实验时间:15:30~17:30 实验序号:实验二 实验名称:Java面向对象程序设计 实验目的与要求: 1.初步掌握单元测试和TDD 2.理解 ...
- 什么时候使用namespace
#include<iostream.h> 不用using namespace std; #include<iostream>要用using namespace std;
- mysql5.7.22安装步骤
在官网上下载mysql的压缩包,然后解压 (下载地址:https://dev.mysql.com/downloads/mysql/) 1.打开cmd,建议使用管理员的身份打开cmd,如果不用使用管理员 ...
- 第七篇:Spark SQL 源码分析之Physical Plan 到 RDD的具体实现
/** Spark SQL源码分析系列文章*/ 接上一篇文章Spark SQL Catalyst源码分析之Physical Plan,本文将介绍Physical Plan的toRDD的具体实现细节: ...
- SQL 循环 FOR 语句
) DECLARE My_Cursor CURSOR --定义游标 FOR (SELECT userid FROM User) --查出需要的集合放到游标中 OPEN My_Cursor; --打开游 ...
- Elasticsearch Head 集群健康值:未连接
安装elasticsearch 6.0 x-pack后,登录9200端口需要用户和密码, 这样,在使用elasticsearch head时,就不能直接访问9100了. 按照官方文档的要求,http ...
- ScrambleString, 爬行字符串,动态规划
问题描述: Given a string s1, we may represent it as a binary tree by partitioning it to two non-empty su ...