爬虫开发3.requests模块
requests模块
- 基于如下5点展开requests模块的学习
- 什么是requests模块
- requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求。功能强大,用法简洁高效。在爬虫领域中占据着半壁江山的地位。
- 为什么要使用requests模块
- 因为在使用urllib模块的时候,会有诸多不便之处,总结如下:
- 手动处理url编码
- 手动处理post请求参数
- 处理cookie和代理操作繁琐
- ......
- 使用requests模块:
- 自动处理url编码
- 自动处理post请求参数
- 简化cookie和代理操作
- ......
- 因为在使用urllib模块的时候,会有诸多不便之处,总结如下:
- 如何使用requests模块
- 安装:
- pip install requests
- 使用流程
- 指定url
- 基于requests模块发起请求
- 获取响应对象中的数据值
- 持久化存储
- 安装:
- 通过5个基于requests模块的爬虫项目对该模块进行学习和巩固
- 基于requests模块的get请求
- 需求:爬取搜狗指定词条搜索后的页面数据
- 基于requests模块的post请求
- 需求:登录豆瓣电影,爬取登录成功后的页面数据
- 基于requests模块ajax的get请求
- 需求:爬取豆瓣电影分类排行榜 https://movie.douban.com/中的电影详情数据
- 基于requests模块ajax的post请求
- 需求:爬取肯德基餐厅查询http://www.kfc.com.cn/kfccda/index.aspx中指定地点的餐厅数据
- 综合练习
- 需求:爬取搜狗知乎指定词条指定页码下的页面数据
- 基于requests模块的get请求
- 代码展示
怎么看网页是get还是post请求?
- 需求:爬取搜狗指定词条搜索后的页面数据(基于get请求)
import requests
import os
#指定搜索关键字
word = input('enter a word you want to search:')
#自定义请求头信息
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
}
#指定url
url = 'https://www.sogou.com/web'
#封装get请求参数
prams = {
'query':word,
'ie':'utf-8'
}
#发起请求
response = requests.get(url=url,params=param) #获取响应数据
page_text = response.text with open('./sougou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
需求:登录豆瓣电影,爬取登录成功后的页面数据(基于post请求)
import requests
import os
url = 'https://accounts.douban.com/login'
#封装请求参数
data = {
"source": "movie",
"redir": "https://movie.douban.com/",
"form_email": "15027900535",
"form_password": "bobo@15027900535",
"login": "登录",
}
#自定义请求头信息
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
}
response = requests.post(url=url,data=data)
page_text = response.text
with open('./douban111.html','w',encoding='utf-8') as fp:
fp.write(page_text)
基于ajax加载网页中的代码来源一般是服务器将整个网页的数据全部返回,但这在访问量大的情况下会给服务器带来不小的压力,
因此有些时候采用的是ajax,只给部分内容,其余的有关数据方面的信息只在用户需要时返回。由于ajax的异步的特性,
所以不会影响到用户的访问体验。有些网页内容使用AJAX加载,只要记得,AJAX一般返回的是JSON,
直接对AJAX地址进行post或get,就返回JSON数据了
- 需求:爬取豆瓣电影分类排行榜 https://movie.douban.com/中的电影详情数据
- 确定ajax对应的请求路径,和提交的数据
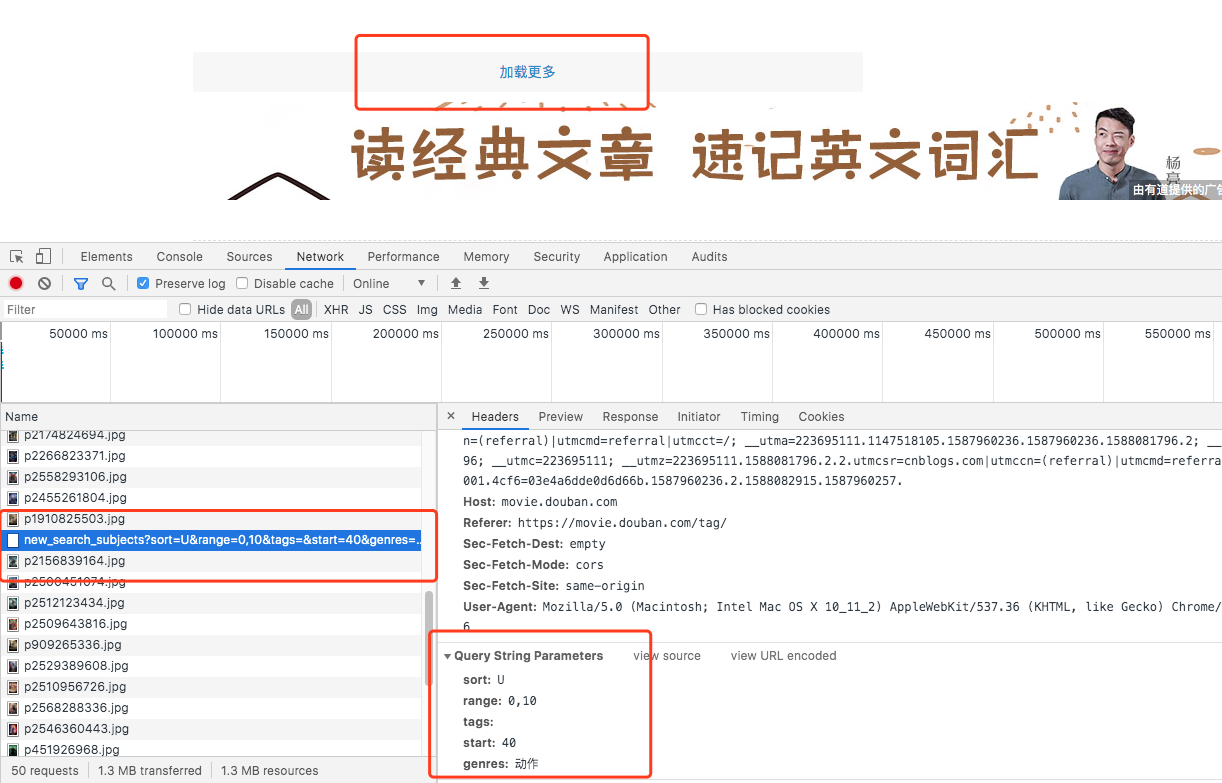
实现代码
import requests
import urllib.request
if __name__ == "__main__": #指定ajax-get请求的url(通过抓包进行获取)
url = 'https://movie.douban.com/j/chart/top_list?' #定制请求头信息,相关的头信息必须封装在字典结构中
headers = {
#定制请求头中的User-Agent参数,当然也可以定制请求头中其他的参数
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
} #定制get请求携带的参数(从抓包工具中获取)
param = {
'type':'5',
'interval_id':'100:90',
'action':'',
'start':'0',
'limit':'20'
}
#发起get请求,获取响应对象
response = requests.get(url=url,headers=headers,params=param) #获取响应内容:响应内容为json串
print(response.text)- 需求:爬取肯德基餐厅查询http://www.kfc.com.cn/kfccda/index.aspx中指定地点的餐厅数据
#!/usr/bin/env python
# -*- coding:utf-8 -*- import requests
import urllib.request
if __name__ == "__main__": #指定ajax-post请求的url(通过抓包进行获取)
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' #定制请求头信息,相关的头信息必须封装在字典结构中
headers = {
#定制请求头中的User-Agent参数,当然也可以定制请求头中其他的参数
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
} #定制post请求携带的参数(从抓包工具中获取)
data = {
'cname':'',
'pid':'',
'keyword':'北京',
'pageIndex': '1',
'pageSize': '10'
}
#发起post请求,获取响应对象
response = requests.get(url=url,headers=headers,data=data) #获取响应内容:响应内容为json串
print(response.text) - 需求:爬取搜狗知乎指定词条指定页码下的页面数据
import requests
import os
#指定搜索关键字
word = input('enter a word you want to search:')
#指定起始页码
start_page = int(input('enter start page num:'))
end_page = int(input('enter end page num:'))
#自定义请求头信息
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
}
#指定url
url = 'https://zhihu.sogou.com/zhihu'
#创建文件夹
if not os.path.exists('./sougou'):
os.mkdir('./sougou')
for page in range(start_page,end_page+1):
#封装get请求参数
params = {
'query':word,
'ie':'utf-8',
'page':str(page)
}
#发起post请求,获取响应对象
response = requests.get(url=url,params=params)
#获取页面数据
page_text = response.text
fileName = word+'_'+str(page)+'.html'
filePath = './sougou/'+fileName
with open(filePath,'w',encoding='utf-8') as fp:
fp.write(page_text)
print('爬取'+str(page)+'页结束')
爬虫开发3.requests模块的更多相关文章
- 爬虫开发5.requests模块的cookie和代理操作
代理和cookie操作 一.基于requests模块的cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests ...
- 爬虫简介与requests模块
爬虫简介与requests模块 一 爬虫简介 概述 网络爬虫是一种按照一定规则,通过网页的链接地址来寻找网页的,从网站某一个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这 ...
- 爬虫基础之requests模块
1. 爬虫简介 1.1 概述 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本. 1.2 爬虫的价值 在互 ...
- python网络爬虫之二requests模块
requests http请求库 requests是基于python内置的urllib3来编写的,它比urllib更加方便,特别是在添加headers, post请求,以及cookies的设置上,处理 ...
- 爬虫中之Requests 模块的进阶
requests进阶内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 引入 有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个 ...
- 爬虫简介和requests模块
目录 爬虫介绍 requests模块 requests模块 1.requests模块的基本使用 2.get 请求携带参数,调用params参数,其本质上还是调用urlencode 3.携带header ...
- 爬虫入门之Requests模块学习(四)
1 Requests模块解析 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用 Requests 继承了urllib2的所有特性.Requests支持HTTP连接保 ...
- 爬虫(四):requests模块
1. requests模块 1.1 requests简介 requests 是一个功能强大.简单易用的 HTTP 请求库,比起之前用到的urllib模块,requests模块的api更加便捷.(本质就 ...
- Python爬虫学习1: Requests模块的使用
Requests函数库是学习Python爬虫必备之一, 能够帮助我们方便地爬取. Requests: 让HTTP服务人类. 本文主要参考了其官方文档. Requests具有完备的中英文文档, 能完全满 ...
随机推荐
- cmder 设置
添加到系统变量 windows10可直接使用小娜搜索环境变量,然后将Cmder.exe所在目录加入Path项即可.之后通过win+r输入cmder即可启动 添加到右键菜单 在管理员权限的命令窗口下(可 ...
- <mvc:annotation-driven />讲解
<mvc:annotation-driven />是一种简写形式,完全可以手动配置替代这种简写形式,简写形式可以让初学者快速应用默认配置方案.<mvc:annotation-driv ...
- resultset 记录数
JDBC中的ResultSet API没有直接获取记录条数的方法,现介绍几个: 方法一:利用ResultSet的getRow方法来获得ResultSet的总行数 Java代码 ResultSet rs ...
- Excel VBA入门(七)注释、宏按钮及错误处理
系统性的知识前面已经讲完,从本章开始,本系列教程涉及的将会是一些相对凌散的内容. 1. 注释 代码注释是一件利人利己的事,为了方便自己在代码需要更新修改时,依然能够快速地看懂自己完的每一行代码到底是什 ...
- memcache分布式的高速缓存系统
http://baike.baidu.com/link?url=8v9IdWg0i_ptrTfz0APh32-SbvNUAWvXrcZM5vuJ8BrjCR2oylrieOXJ3vkSuRAq3kQV ...
- 01-MySQL优化大的思路
首先不是看它的表结构等等.从整体上去观察,不断去看它的状态.这个状态往往不是一两个小时可以看出来的,得写一个脚本,观察它的24小时的周期性变化,不断刷新它的脚本,观察它的Status.主要是看它有没有 ...
- Struts2概述
-------------------siwuxie095 Struts2 概述 1.Struts2 是应用在 Java EE 三层架构中的 Web 层的框架 2.Struts2 是在 Struts1 ...
- selenium+python—实现基本自动化测试
安装selenium 打开命令控制符输入:pip install -U selenium 火狐浏览器安装firebug:www.firebug.com,调试所有网站语言,调试功能 Selenium I ...
- labelimg
------------------------labelimg------------------------- cd /home/luo/TensorflowProject/labelImg py ...
- [C++] Vtable(虚函数表)
Vtable(虚函数表)