机器学习-kNN-寻找最好的超参数
一 、超参数和模型参数
- 超参数:在算法运行前需要决定的参数
- 模型参数:算法运行过程中学习的参数
- kNN算法没有模型参数
- kNN算法中的k是典型的超参数
寻找好的超参数
- 领域知识
- 经验数值
- 实验搜索
二、通过sklearn中的数据集进行测试
import numpy as np
from sklearn import datasets
# 装载sklearn中的手写数字数据集
digits = datasets.load_digits()
x = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 将数据分成训练数据集合测试数据集,
# 测试数据集占全部数据的20%,
# 设置随机种子为666
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state = 666)
# 设置k为3
knn_clf = KNeighborsClassifier(n_neighbors=3)
# 训练数据模型
knn_clf.fit(x_train,y_train)
# 通过测试数据计算预测结果准确率,并打印出来
print(knn_clf.score(x_test,y_test))
输出结果:0.9888888888888889
三、考虑距离?不考虑距离?
kNN存在一种平票的情况,就是距离最近的k个点中相应类的数量相等,这是需要考虑距离了。
或者可以使用加权距离来计算
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
x = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state = 666)
best_method = ''
best_score = 0.0
best_k = -1
for method in ['uniform','distance']:
for k in range(1,11):
knn_clf = KNeighborsClassifier(n_neighbors=k,weights=method)
knn_clf.fit(x_train,y_train)
score = knn_clf.score(x_test,y_test)
if score > best_score:
best_method = method
best_score = score
best_k = k
print('best_method = %s'%best_method)
print('best_k = %d'%best_k)
print('best_score = %f'%best_score)
运行结果:
best_method = uniform
best_k = 4
best_score = 0.991667
四、搜索 明可夫斯基距离 相应的p
欧拉距离,曼哈顿距离,明可夫斯基距离
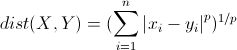
由上可以获取一个超参数p。
%%time
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
x = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state = 666)
best_p = ''
best_score = 0.0
best_k = -1
# for method in ['uniform','distance']:
for k in range(1,11):
for p in range(1,6):
knn_clf = KNeighborsClassifier(n_neighbors=k,weights="distance",p=p)
knn_clf.fit(x_train,y_train)
score = knn_clf.score(x_test,y_test)
if score > best_score:
best_p = p
best_score = score
best_k = k
print('best_p = %s'%best_p)
print('best_k = %d'%best_k)
print('best_score = %f'%best_score)
运行结果:
best_p = 2
best_k = 3
best_score = 0.988889
Wall time: 47.5 s
四、网格搜索kNN最好的参数
sklearn中通过网格搜索可以更快更全面的搜索更好的参数。
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
x = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state = 666)
knn_clf = KNeighborsClassifier(n_neighbors=4,weights='uniform')
knn_clf.fit(x_train,y_train)
knn_clf.score(x_test,y_test)
param_grid = [
{
'weights':['uniform'],
'n_neighbors':[i for i in range(1,11)]
},
{
'weights':['distance'],
'n_neighbors':[i for i in range(1,11)],
'p':[i for i in range(1,6)]
}
]
knn_clf = KNeighborsClassifier()
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(knn_clf,param_grid)
# 需要运行2-5分钟,保持耐心
grid_search.fit(x_train,y_train)
grid_search.best_estimator_ # 最佳的参数对象
grid_search.best_score_ # 准确率
grid_search.best_params_ # 最佳的参数
#为计算机分配资源,输出搜索信息,n_jobs:分配计算机核数,-1位有多少用多少,verbose:为打印信息的等级,值越大,信息越多
grid_search = GridSearchCV(knn_clf,param_grid,n_jobs=-1,verbose=10)
grid_search.fit(x_train,y_train)
五、更多的距离定义
- 向量空间余弦相似度 Cosine Similarity
- 调整余弦相似度 Adjusted Cosine Similarity
- 皮尔森相关系数 Pearson Correlation Coefficient
- Jaccard相似系数 Jaccard Coefficient
机器学习-kNN-寻找最好的超参数的更多相关文章
- 机器学习算法中如何选取超参数:学习速率、正则项系数、minibatch size
机器学习算法中如何选取超参数:学习速率.正则项系数.minibatch size 本文是<Neural networks and deep learning>概览 中第三章的一部分,讲机器 ...
- 机器学习:调整kNN的超参数
一.评测标准 模型的测评标准:分类的准确度(accuracy): 预测准确度 = 预测成功的样本个数/预测数据集样本总数: 二.超参数 超参数:运行机器学习算法前需要指定的参数: kNN算法中的超参数 ...
- 【笔记】KNN之网格搜索与k近邻算法中更多超参数
网格搜索与k近邻算法中更多超参数 网格搜索与k近邻算法中更多超参数 网络搜索 前笔记中使用的for循环进行的网格搜索的方式,我们可以发现不同的超参数之间是存在一种依赖关系的,像是p这个超参数,只有在 ...
- lecture16-联合模型、分层坐标系、超参数优化及本课未来的探讨
这是HInton的第16课,也是最后一课. 一.学习一个图像和标题的联合模型 在这部分,会介绍一些最近的在学习标题和描述图片的特征向量的联合模型上面的工作.在之前的lecture中,介绍了如何从图像中 ...
- 如何选取一个神经网络中的超参数hyper-parameters
1.什么是超参数 所谓超参数,就是机器学习模型里面的框架参数.比如聚类方法里面类的个数,或者话题模型里面话题的个数等等,都称为超参数.它们跟训练过程中学习的参数(权重)是不一样的,通常是手工设定的,经 ...
- 超参数 hyperparameters
转载:https://www.cnblogs.com/qamra/p/8721561.html 超参数的定义:在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据 ...
- 【笔记】KNN之超参数
超参数 超参数 很多时候,对于算法来说,关于这个传入的参数,传什么样的值是最好的? 这就涉及到了机器学习领域的超参数 超参数简单来说就是在我们运行机器学习之前用来指定的那个参数,就是在算法运行前需要决 ...
- 机器学习超参数优化算法-Hyperband
参考文献:Hyperband: Bandit-Based Configuration Evaluation for Hyperparameter Optimization I. 传统优化算法 机器学习 ...
- Spark2.0机器学习系列之2:基于Pipeline、交叉验证、ParamMap的模型选择和超参数调优
Spark中的CrossValidation Spark中采用是k折交叉验证 (k-fold cross validation).举个例子,例如10折交叉验证(10-fold cross valida ...
随机推荐
- 201621123037 《Java程序设计》第10周学习总结
作业10-异常 标签(空格分隔): Java 1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常相关内容. 2. 书面作业 本次PTA作业题集异常 1. 常用异常 结合题集题目7 ...
- webgl 初识2
之前的文章介绍了webgl. 这里进一步精简. WebGL的全部内容就是创建不同的着色器, 向着色器提供数据然后调用gl.drawArrays 或 gl.drawElements 让WebGL调用当前 ...
- IE8 没有内容的盒子,如果有定位,浮现在其他盒子上 可能会有点击穿透没有作用的情况
IE8 没有内容的盒子,如果有定位,浮现在其他盒子上 可能会有点击穿透没有作用的情况
- BZOJ 1264 基因匹配(DP+线段树)
很有意思的一道题啊. 求两个序列的最大公共子序列.保证每个序列中含有1-n各5个. 如果直接LCS显然是TLE的.该题与普通的LCS不同的是每个序列中含有1-n各5个. 考虑LCS的经典DP方程.dp ...
- day 05 万恶之源-基本数据类型(dict)
05. 万恶之源-基本数据类型(dict)本节主要内容:1. 字典的简单介绍2. 字典增删改查和其他操作3. 字典的嵌套⼀一. 字典的简单介绍字典(dict)是python中唯⼀一的⼀一个映射类型.他 ...
- request之setAtrribute
当在servlet中有request.SetAtrribute("AtriruteName",AtrributeValue)语句时,在jsp页面获取AtrributeValue有两 ...
- C++解析-外传篇(2):函数的异常规格说明
0.目录 1.异常规格说明 2.unexpected() 函数 3.小结 1.异常规格说明 问题: 如何判断一个函数是否会抛出异常,以及抛出哪些异常? C++提供语法用于声明函数所抛出的异常 异常声明 ...
- [codeforces464D]World of Darkraft - 2 概率期望
D. World of Darkraft - 2 time limit per test 2 seconds memory limit per test 256 megabytes input sta ...
- 两种方法实现TAB菜单及文件操作
1,自定义属性的方法实现----TAB菜单操作 cursor:pointer; 鼠标的小手 <!DOCTYPE html> <html lang="en"> ...
- 【比赛】HNOI2018 游戏
考试的时候线段树区间查询的return条件打成了l==r....于是光荣爆20(线段树都不会打了?) 看膜博士的题解 #include<bits/stdc++.h> #define ui ...