C# 正则表达式 转自-每日一bo
最近写爬虫时需要用到正则表达式,有段时间没有使用正则表达式现在渐渐感觉有些淡忘,现在使用还需要去查询一些资料。为了避免以后这样的情况,在此记录下正则表达式的一些基本使用方法附带小的实例。让以后在使用时能一目了然知道他的使用,为开发节约时间,同时也分享给大家。
正则元字符
在说正则表达式之前我们先来看看通配符,我想通配符大家都用过。通配符主要有星号(*)和问号(?),用来模糊搜索文件。winodws中我们常会使用搜索来查找一些文件。如:*.jpg,XXX.docx的方式,来快速查找文件。其实正则表达式和我们通配符很相似也是通过特定的字符匹配我们所要查询的内容信息。已下代码都是区分大小写。
常用元字符
| 代码 | 说明 |
| . | 匹配除换行符以外的任意字符。 |
| \w | 匹配字母或数字或下划线或汉字。 |
| \s | 匹配任意的空白符。 |
| \d | 匹配数字。 |
| \b | 匹配单词的开始或结束。 |
| [ck] | 匹配包含括号内元素的字符 |
| ^ | 匹配行的开始。 |
| $ | 匹配行的结束。 |
| \ | 对下一个字符转义。比如$是个特殊的字符。要匹配$的话就得用\$ |
| | | 分支条件,如:x|y匹配 x 或 y。 |
反义元字符
| 代码 | 说明 |
| \W | 匹配任意不是字母,数字,下划线,汉字的字符。 |
| \S | 匹配任意不是空白符的字符。等价于 [^ \f\n\r\t\v]。 |
| \D | 匹配任意非数字的字符。等价于 [^0-9]。 |
| \B | 匹配不是单词开头或结束的位置。 |
| [^CK] | 匹配除了CK以外的任意字符。 |
特殊元字符
| 代码 | 说明 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
限定符
| 代码 | 说明 |
| * | 匹配前面的子表达式零次或多次。 |
| + | 匹配前面的子表达式一次或多次。 |
| ? | 匹配前面的子表达式零次或一次。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。 |
| {n,} | n 是一个非负整数。至少匹配n 次。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
懒惰限定符
| 代码 | 说明 |
| *? |
重复任意次,但尽可能少重复。 如 "acbacb" 正则 "a.*?b" 只会取到第一个"acb" 原本可以全部取到但加了限定符后,只会匹配尽可能少的字符 ,而"acbacb"最少字符的结果就是"acb" 。 |
| +? | 重复1次或更多次,但尽可能少重复。与上面一样,只是至少要重复1次。 |
| ?? |
重复0次或1次,但尽可能少重复。 如 "aaacb" 正则 "a.??b" 只会取到最后的三个字符"acb"。 |
| {n,m}? |
重复n到m次,但尽可能少重复。 如 "aaaaaaaa" 正则 "a{0,m}" 因为最少是0次所以取到结果为空。 |
| {n,}? |
重复n次以上,但尽可能少重复。 如 "aaaaaaa" 正则 "a{1,}" 最少是1次所以取到结果为 "a"。 |
捕获分组
| 代码 | 说明 |
| (exp) | 匹配exp,并捕获文本到自动命名的组里。 |
| (?<name>exp) | 匹配exp,并捕获文本到名称为name的组里。 |
| (?:exp) | 匹配exp,不捕获匹配的文本,也不给此分组分配组号以下为零宽断言。 |
| (?=exp) |
匹配exp前面的位置。 如 "How are you doing" 正则"(?<txt>.+(?=ing))" 这里取ing前所有的字符,并定义了一个捕获分组名字为 "txt" 而"txt"这个组里的值为"How are you do"; |
| (?<=exp) |
匹配exp后面的位置。 如 "How are you doing" 正则"(?<txt>(?<=How).+)" 这里取"How"之后所有的字符,并定义了一个捕获分组名字为 "txt" 而"txt"这个组里的值为" are you doing"; |
| (?!exp) |
匹配后面跟的不是exp的位置。 如 "123abc" 正则 "\d{3}(?!\d)"匹配3位数字后非数字的结果 |
| (?<!exp) |
匹配前面不是exp的位置。 如 "abc123 " 正则 "(?<![0-9])123" 匹配"123"前面是非数字的结果也可写成"(?!<\d)123" |
得到上面秘籍后我们可以小试牛刀...
小试牛刀
在C#中使用正则表达式主要是通过Regex类来实现。命名空间:using System.Text.RegularExpressions。
其中常用方法:
| 名称 | 说明 |
| IsMatch(String, String) | 指示 Regex 构造函数中指定的正则表达式在指定的输入字符串中是否找到了匹配项。 |
| Match(String, String) | 在指定的输入字符串中搜索 Regex 构造函数中指定的正则表达式的第一个匹配项。 |
| Matches(String, String) | 在指定的输入字符串中搜索正则表达式的所有匹配项。 |
| Replace(String, String) | 在指定的输入字符串内,使用指定的替换字符串替换与某个正则表达式模式匹配的所有字符串。 |
| Split(String, String) | 在由 Regex 构造函数指定的正则表达式模式所定义的位置,拆分指定的输入字符串。 |
在使用正则表达式前我们先来看看“@”符号的使用。
学过C#的人都知道C# 中字符串常量可以以@ 开头声名,这样的优点是转义序列“不”被处理,按“原样”输出,即我们不需要对转义字符加上 \ (反斜扛),就可以轻松coding。如:
string filePath = @"c:\Docs\Source\CK.txt" // rather than "c:\\Docs\\Source\\CK.txt"
如要在一个用 @ 引起来的字符串中包括一个双引号,就需要使用两对双引号了。这时候你不能使用 \ 来转义爽引号了,因为在这里 \ 的转义用途已经被 @ “屏蔽”掉了。如:
string str=@"""Ahoy!"" cried the captain." // 输出为: "Ahoy!" cried the captain.
字符串匹配:
在实际项目中我们常常需要对用户输入的信息进行验证。如:匹配用户输入的内容是否为数字,是否为有效的手机号码,邮箱是否合法....等。
实例代码:
string RegexStr = string.Empty;
#region 字符串匹配 RegexStr = "^[0-9]+$"; //匹配字符串的开始和结束是否为0-9的数字[定位字符]
Console.WriteLine("判断'R1123'是否为数字:{0}", Regex.IsMatch("R1123", RegexStr));
Console.WriteLine("判断'1123'是否为数字:{0}", Regex.IsMatch("", RegexStr)); RegexStr = @"\d+"; //匹配字符串中间是否包含数字(这里没有从开始进行匹配噢,任意位子只要有一个数字即可)
Console.WriteLine("'R1123'是否包含数字:{0}", Regex.IsMatch("R1123", RegexStr));
Console.WriteLine("'博客园'是否包含数字:{0}", Regex.IsMatch("博客园", RegexStr)); RegexStr = @"^Hello World[\w\W*]"; //已Hello World开头的任意字符(\w\W:组合可匹配任意字符)
Console.WriteLine("'HeLLO WORLD xx hh xx'是否已Hello World开头:{0}", Regex.IsMatch("HeLLO WORLD xx hh xx", RegexStr, RegexOptions.IgnoreCase));
Console.WriteLine("'LLO WORLD xx hh xx'是否已Hello World开头:{0}", Regex.IsMatch("LLO WORLD xx hh xx", RegexStr,RegexOptions.IgnoreCase));
//RegexOptions.IgnoreCase:指定不区分大小写的匹配。 #endregion
显示结果:

字符串查找:
实例代码:
string RegexStr = string.Empty; #region 字符串查找 string LinkA = "<a href=\"http://www.baidu.com\" target=\"_blank\">百度</a>"; RegexStr = @"href=""[\S]+"""; // ""匹配"
Match mt = Regex.Match(LinkA, RegexStr); Console.WriteLine("{0}。", LinkA);
Console.WriteLine("获得href中的值:{0}。", mt.Value); RegexStr = @"<h[^23456]>[\S]+<h[1]>"; //<h[^23456]>:匹配h除了2,3,4,5,6之中的值,<h[1]>:h匹配包含括号内元素的字符
Console.WriteLine("{0}。GetH1值:{1}", "<H1>标题<H1>", Regex.Match("<H1>标题<H1>", RegexStr, RegexOptions.IgnoreCase).Value);
Console.WriteLine("{0}。GetH1值:{1}", "<h2>小标<h2>", Regex.Match("<h2>小标<h2>", RegexStr, RegexOptions.IgnoreCase).Value);
//RegexOptions.IgnoreCase:指定不区分大小写的匹配。 RegexStr = @"ab\w+|ij\w{1,}"; //匹配ab和字母 或 ij和字母
Console.WriteLine("{0}。多选结构:{1}", "abcd", Regex.Match("abcd", RegexStr).Value);
Console.WriteLine("{0}。多选结构:{1}", "efgh", Regex.Match("efgh", RegexStr).Value);
Console.WriteLine("{0}。多选结构:{1}", "ijk", Regex.Match("ijk", RegexStr).Value); RegexStr = @"张三?丰"; //?匹配前面的子表达式零次或一次。
Console.WriteLine("{0}。可选项元素:{1}", "张三丰", Regex.Match("张三丰", RegexStr).Value);
Console.WriteLine("{0}。可选项元素:{1}", "张丰", Regex.Match("张丰", RegexStr).Value);
Console.WriteLine("{0}。可选项元素:{1}", "张飞", Regex.Match("张飞", RegexStr).Value); /*
例如:
July|Jul 可缩短为 July?
4th|4 可缩短为 4(th)?
*/ //匹配特殊字符
RegexStr = @"Asp\.net"; //匹配Asp.net字符,因为.是元字符他会匹配除换行符以外的任意字符。这里我们只需要他匹配.字符即可。所以需要转义\.这样表示匹配.字符
Console.WriteLine("{0}。匹配Asp.net字符:{1}", "Java Asp.net SQLServer", Regex.Match("Java Asp.net SQLServer", RegexStr).Value);
Console.WriteLine("{0}。匹配Asp.net字符:{1}", "C# Java", Regex.Match("C# Java", RegexStr).Value); #endregion
显示结果:

贪婪与懒惰

string f = "fooot";
//贪婪匹配
RegexStr = @"f[o]+";
Match m1 = Regex.Match(f, RegexStr);
Console.WriteLine("{0}贪婪匹配(匹配尽可能多的字符):{1}", f, m1.ToString()); //懒惰匹配
RegexStr = @"f[o]+?";
Match m2 = Regex.Match(f, RegexStr);
Console.WriteLine("{0}懒惰匹配(匹配尽可能少重复):{1}", f, m2.ToString());
显示结果:
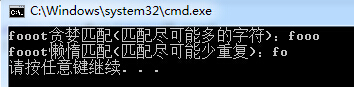
从上面的例子中我们不难看出贪婪与懒惰的区别,他们的名子取的都很形象。
贪婪匹配:匹配尽可能多的字符。
懒惰匹配:匹配尽可能少的字符。
(exp)分组
在做爬虫时我们经常获得A中一些有用信息。如href,title和显示内容等。
string TaobaoLink = "<a href=\"http://www.taobao.com\" title=\"淘宝网 - 淘!我喜欢\" target=\"_blank\">淘宝</a>";
RegexStr = @"<a[^>]+href=""(\S+)""[^>]+title=""([\s\S]+?)""[^>]+>(\S+)</a>";
Match mat = Regex.Match(TaobaoLink, RegexStr);
for (int i = ; i < mat.Groups.Count; i++)
{
Console.WriteLine("第"+i+"组:"+mat.Groups[i].Value);
}
显示结果:

在正则表达式里使用()包含的文本自动会命名为一个组。上面的表达式中共使用了4个()可以认为是分为了4组。
输出结果共分为:4组。
0组:为我们所匹配的字符串。
1组:是我们第一个括号[href=""(\S+)""]中(\S+)所匹配的网址信息。内容为:http://www.taobao.com。
2组:是第二个括号[title=""([\s\S]+?)""]中所匹配的内容信息。内容为:淘宝网 - 淘!我喜欢。
这里我们会看到+?懒惰限定符。title=""([\s\S]+?)"" 这里+?的下一个字符为"双引号,"双引号在匹配字符串后面还有三个。+?懒惰限定符会尽可能少重复,所他会匹配最前面那个"双引号。如果我们不使用+?懒惰限定符他会匹配到:淘宝网 - 淘!我喜欢" target= 会尽可能多重复匹配。
3组:是第三个括号[(\S+)]所匹配的内容信息。内容为:淘宝。
说明:反义元字符所对应的元字符都能组合匹配任意字符。如:[\w\W],[\s\S],[\d\D]..
(?<name>exp) 分组取名
当我们匹配分组信息过多后,在某种场合只需取当中某几组信息。这时我们可以对分组取名。通过分组名称来快速提取对应信息。
string Resume = "基本信息姓名:CK|求职意向:.NET软件工程师|性别:男|学历:本专|出生日期:1988-08-08|户籍:湖北.孝感|E - Mail:9245162@qq.com|手机:15000000000";
RegexStr = @"姓名:(?<name>[\S]+)\|\S+性别:(?<sex>[\S]{1})\|学历:(?<xueli>[\S]{1,10})\|出生日期:(?<Birth>[\S]{10})\|[\s\S]+手机:(?<phone>[\d]{11})";
Match matc = Regex.Match(Resume, RegexStr);
Console.WriteLine("姓名:{0},手机号:{1}", matc.Groups["name"].ToString(), matc.Groups["phone"].ToString());
显示结果:

通过(?<name>exp)可以很轻易为分组取名。然后通过Groups["name"]取得分组值。
获得页面中A标签中href值
string PageInfo = @"<hteml>
<div id=""div1"">
<a href=""http://www.baidu.con"" target=""_blank"">百度</a>
<a href=""http://www.taobao.con"" target=""_blank"">淘宝</a>
<a href=""http://www.cnblogs.com"" target=""_blank"">博客园</a>
<a href=""http://www.google.con"" target=""_blank"">google</a>
</div>
<div id=""div2"">
<a href=""/zufang/"">整租</a>
<a href=""/hezu/"">合租</a>
<a href=""/qiuzu/"">求租</a>
<a href=""/ershoufang/"">二手房</a>
<a href=""/shangpucz/"">商铺出租</a>
</div>
</hteml>";
RegexStr = @"<a[^>]+href=""(?<href>[\S]+?)""[^>]*>(?<text>[\S]+?)</a>";
MatchCollection mc = Regex.Matches(PageInfo, RegexStr);
foreach (Match item in mc)
{
Console.WriteLine("href:{0}--->text:{1}",item.Groups["href"].ToString(),item.Groups["text"].ToString());
}
显示结果:

Replace 替换字符串
用户在输入信息时偶尔会包含一些敏感词,这时我们需要替换这个敏感词。
string PageInputStr = "靠.TMMD,今天真不爽....";
RegexStr = @"靠|TMMD|妈的";
Regex rep_regex = new Regex(RegexStr);
Console.WriteLine("用户输入信息:{0}", PageInputStr);
Console.WriteLine("页面显示信息:{0}", rep_regex.Replace(PageInputStr, "***"));
显示结果:

对一些敏感词直接替换成***代替。
Split 拆分字符串
string SplitInputStr = "1xxxxx.2ooooo.3eeee.4kkkkkk.";
RegexStr = @"\d";
Regex spl_regex = new Regex(RegexStr);
string[] str = spl_regex.Split(SplitInputStr);
foreach (string item in str)
{
Console.WriteLine(item);
}
显示结果:

根据数字截取字符串。
转自 http://www.cnblogs.com/caokai520/p/4511848.html
C# 正则表达式 转自-每日一bo的更多相关文章
- 使用C#正则表达式获取必应每日图片地址
微软的Bing搜索引擎首页每天都会提供了一些有趣的图片,下面使用正则表达式获取图片的地址,不管是在手机app还是在网站上都是很好的图片素材,而且每天更新,非常不错. 首先访问微软的API,该地址返回的 ...
- 快速入门系列--Log4net日志组件
Log4net是阿帕奇基金会的非常流行的开源日志组件,是log4j的.NET移植版本,至今已经有11年的历史,使用方便并且非常稳定,此外很重要的一点是其和很多开源组件能很好的组合在一起工作,例如NHi ...
- CSS 实现垂直居中的几种方案
最近在学关系型数据库相关,MySQL 和 Postgre,捎带着学了 PHP,为了练手这几天就忙着自己搭博客,项目部署在某云上,该云算是良心,给的空间自己搭博客用足够了.本来想着每日一bo的,所以有的 ...
- R 语言爬虫 之 cnblog博文爬取
Cnbolg Crawl a). 加载用到的R包 ##library packages needed in this case library(proto) library(gsubfn) ## Wa ...
- [每日一题JS] 正则表达式
判断字符串是否是这样组成的,第一个必须是字母,后面可以是字母.数字.下划线,总长度为5-20 var reg = /\b[a-zA-Z]{1}[a-zA-Z0-9_]{4,19}\b/; var fl ...
- [每日一题] OCP1z0-047 :2013-08-22 正则表达式---[^Ale|ax.r$]'
正确答案:DE 一.Oracle正则表达式的相关知识点 '[^Ale|ax.r$]': ^:匹配行的开始字符 $:匹配行的结束字符 []:方括号表示指定一个匹配列表,该列表匹配列表中显示的任何表达式. ...
- [每日一题] OCP1z0-047 :2013-08-01 正则表达式--- REGEXP_REPLACE 函数
这题又是考正则表达式,我们先根据题意,操作如下: hr@OCM> col "PHONE NUMBER" for a50 hr@OCM> SELECT phone_num ...
- 每日英语:Is Bo Xilai the Past or Future?
Bo Xilai may be in jail, but a struggle is now underway within the Communist Party over the policies ...
- 每日英语:Prosecutors Wrap Up Case Against Bo
Prosecutors wrapped up their case against Bo Xilai on Sunday, sparring with the defiant former Commu ...
随机推荐
- 变形--缩放 scale()
缩放 scale()函数 让元素根据中心原点对对象进行缩放. 缩放 scale 具有三种情况: 1. scale(X,Y)使元素水平方向和垂直方向同时缩放(也就是X轴和Y轴同时缩放) 例如: div: ...
- jquery 数组求差集,并集
var alpha = [1, 2, 3, 4, 5, 6], beta = [4, 5, 6, 7, 8, 9]; $.arrayIntersect = function(a, b){ return ...
- hue安装与部署
运行环境 centOS 6.6 hadoop 2.4.0 hive 1.2.0 spark 1.4.1 HUE 3.9 介绍: Hue是一个开源的Apache Hadoop UI系统,最早是由Clou ...
- BaseAction的一般写法
package com.mi.action; import java.util.Map; import javax.servlet.http.HttpServletRequest; import ja ...
- ionic之AngularJS扩展 移动开发(视图导航一)
目录: 内联模板 : script 路由机制 : 状态机 导航视图 : ion-nav-view 模板视图 : ion-view 导航栏 : ion-nav-bar 回退按钮 : ion-nav-ba ...
- SSAS更改默认端口号,使用非默认端口号的时候Olap连接字符串的格式
Sql server的Analysis Service服务默认使用的是2382或2383端口,但是实际上我们可以通过配置文件手动更改SSAS使用其它端口号. 修改SSAS使用端口号的方法如下,找到你的 ...
- UIViewController启动过程
流程:判断是否view属性为nil,如果为空,调用loadView方法,如果重写了loadView方法,那么从代码创建普通视图,如果没有重写并且有storyBoard或者xib文件,那么从storyB ...
- android 项目学习随笔十二(ListView加脚布局)
1.ListView加脚布局 头布局initHeaderView,在onTouchEvent事件中进行显示隐藏头布局切换 脚布局initFooterView,实现接口OnScrollListener, ...
- linux网站目录及Apache权限的设置
apache服务器访问权限设置禁止所有访问:Options Indexes FollowSymLinks 改为 Option None Apache单个或多个目录禁止访问方法 这种方法通常用来 ...
- 161010、在大型项目中组织CSS
编写CSS容易. 编写可维护的CSS难. 这句话你之前可能听过100次了. 原因是CSS中的一切都默认为全局的.如果你是一个C程序员你就知道全局变量不好.如果你是任何一种程序员,你都知道隔离和可组合的 ...