Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系?
RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
1)窄依赖指的是每一个parent RDD的Partition最多被子RDD的一个Partition使用,如图1所示。
2)宽依赖指的是多个子RDD的Partition会依赖同一个parent RDD的Partition,如图2所示。
RDD作为数据结构,本质上是一个只读的分区记录集合。一个RDD可以包含多个分区,每个分区就是一个dataset片段。RDD可以相互依赖。
1)如果RDD的每个分区最多只能被一个Child RDD的一个分区使用,则称之为narrow dependency。
2)如果多个Child RDD分区都可以依赖,则称之为wide / shuffle dependency 。
Spark之所以将依赖分为narrow 和 shuffle / wide 。基于两点原因
1、首先,narrow dependencies可以支持在同一个cluster node上,以pipeline形式执行多条命令,例如在执行了map后,紧接着执行filter。
相反,shuffle / wide dependencies 需要所有的父分区都是可用的,可能还需要调用类似MapReduce之类的操作进行跨节点传递。
2、其次,则是从失败恢复的角度考虑。 narrow dependencies的失败恢复更有效,因为它只需要重新计算丢失的parent partition即可,而且可以并行地在不同节点进行重计算。
相反,shuffle / wide dependencies 牵涉RDD各级的多个parent partition。
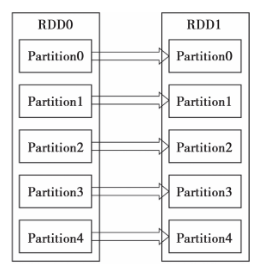
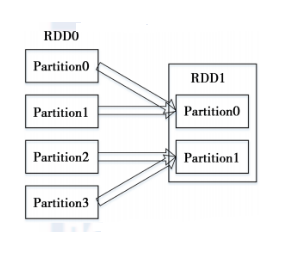
图 1 RDD的窄依赖 图 2 RDD的宽依赖
接下来可以从不同类型的转换来进一步理解RDD的窄依赖和宽依赖的区别,如图3所示。
对于map和filter形式的转换来说,它们只是将Partition的数据根据转换的规则进行转化,并不涉及其他的处理,可以简单地认为只是将数据从一个形式转换到另一个形式。对于union,只是将多个RDD合并成一个,parent RDD的Partition(s)不会有任何的变化,可以认为只是把parent RDD的Partition(s)简单进行复制与合并。对于join,如果每个Partition仅仅和已知的、特定的Partition进行join,那么这个依赖关系也是窄依赖。对于这种有规则的数据的join,并不会引入昂贵的Shuffle。对于窄依赖,由于RDD每个Partition依赖固定数量的parent RDD(s)的Partition(s),因此可以通过一个计算任务来处理这些Partition,并且这些Partition相互独立,这些计算任务也就可以并行执行了。
对于groupByKey,子RDD的所有Partition(s)会依赖于parent RDD的所有Partition(s),子RDD的Partition是parent RDD的所有Partition Shuffle的结果,因此这两个RDD是不能通过一个计算任务来完成的。同样,对于需要parent RDD的所有Partition进行join的转换,也是需要Shuffle,这类join的依赖就是宽依赖而不是前面提到的窄依赖了。
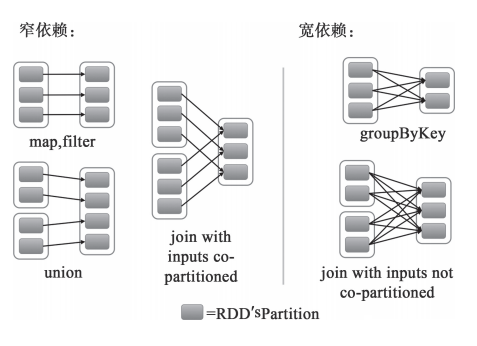
不同的操作依据其特性,可能会产生不同的依赖。例如map、filter操作会产生 narrow dependency 。reduceBykey操作会产生 wide / shuffle dependency。
通俗点来说,RDD的每个Partition,仅仅依赖于父RDD中的一个Partition,这才是窄。 就这么简单!
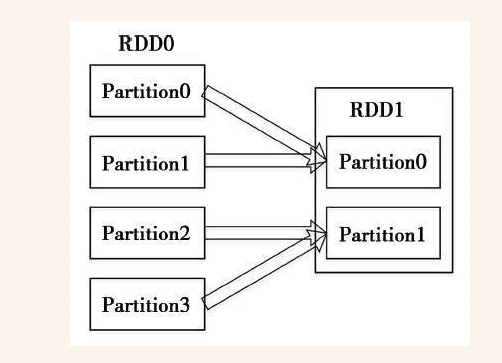
我以前总感觉这是窄依赖,其实 Rdd1的partition0依赖父Rdd0的 partition0和partition1,所以是宽依赖!
所有的依赖都要实现trait Dependency[T]:
abstract class Dependency[T] extends Serializable { def rdd: RDD[T]}其中rdd就是依赖的parent RDD。对于窄依赖的实现是:abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] { //返回子RDD的partitionId依赖的所有的parent RDD的Partition(s) def getParents(partitionId: Int): Seq[Int] override def rdd: RDD[T] = _rdd}现在有两种窄依赖的具体实现,一种是一对一的依赖,即OneToOneDependency:class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) { override def getParents(partitionId: Int) = List(partitionId)还有一个是范围的依赖,即RangeDependency,它仅仅被org.apache.spark.rdd.UnionRDD使用。UnionRDD是把多个RDD合成一个RDD,这些RDD是被拼接而成,即每个parent RDD的Partition的相对顺序不会变,只不过每个parent RDD在UnionRDD中的Partition的起始位置不同。因此它的getPartents如下:
override def getParents(partitionId: Int) = { if(partitionId >= outStart && partitionId < outStart + length) { List(partitionId - outStart + inStart) } else { Nil }}其中,inStart是parent RDD中Partition的起始位置,outStart是在UnionRDD中的起始位置,length就是parent RDD中Partition的数量。
对于宽依赖的实现是:
宽依赖的实现只有一种:ShuffleDependency。子RDD依赖于parent RDD的所有Partition,因此需要Shuffle过程:
class ShuffleDependency[K, V, C]( @transient _rdd: RDD[_ <: Product2[K, V]], val partitioner: Partitioner, val serializer: Option[Serializer] = None, val keyOrdering: Option[Ordering[K]] = None, val aggregator: Option[Aggregator[K, V, C]] = None, val mapSideCombine: Boolean = false)extends Dependency[Product2[K, V]] {override def rdd = _rdd.asInstanceOf[RDD[Product2[K, V]]]//获取新的shuffleIdval shuffleId: Int = _rdd.context.newShuffleId()//向ShuffleManager注册Shuffle的信息val shuffleHandle: ShuffleHandle =_rdd.context.env.shuffleManager.registerShuffle( shuffleId, _rdd.partitions.size, this) _rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))}Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)的更多相关文章
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark RDD概念学习系列之RDD的转换(十)
RDD的转换 Spark会根据用户提交的计算逻辑中的RDD的转换和动作来生成RDD之间的依赖关系,同时这个计算链也就生成了逻辑上的DAG.接下来以“Word Count”为例,详细描述这个DAG生成的 ...
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
- Spark RDD概念学习系列之RDD的5大特点(五)
RDD的5大特点 1)有一个分片列表,就是能被切分,和Hadoop一样,能够切分的数据才能并行计算. 一组分片(partition),即数据集的基本组成单位,对于RDD来说,每个分片都会被一个计 ...
- Spark RDD概念学习系列之RDD是什么?(四)
RDD是什么? 通俗地理解,RDD可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的.详细见 Spark的数据存储 Spark的核心数据模型是RDD,但RDD是个抽象类 ...
- Spark RDD概念学习系列之RDD的容错机制(十七)
RDD的容错机制 RDD实现了基于Lineage的容错机制.RDD的转换关系,构成了compute chain,可以把这个compute chain认为是RDD之间演化的Lineage.在部分计算结果 ...
- Spark RDD概念学习系列之RDD的缓存(八)
RDD的缓存 RDD的缓存和RDD的checkpoint的区别 缓存是在计算结束后,直接将计算结果通过用户定义的存储级别(存储级别定义了缓存存储的介质,现在支持内存.本地文件系统和Tachyon) ...
- Spark RDD概念学习系列之RDD的操作(七)
RDD的操作 RDD支持两种操作:转换和动作. 1)转换,即从现有的数据集创建一个新的数据集. 2)动作,即在数据集上进行计算后,返回一个值给Driver程序. 例如,map就是一种转换,它将数据集每 ...
- Spark RDD概念学习系列之RDD的缺点(二)
RDD的缺点? RDD是Spark最基本也是最根本的数据抽象,它具备像MapReduce等数据流模型的容错性,并且允许开发人员在大型集群上执行基于内存的计算. 为了有效地实现容错,(详细见ht ...
随机推荐
- UML类图几种关系的总结,泛化 = 实现 > 组合 > 聚合 > 关联 > 依赖
在UML类图中,常见的有以下几种关系: 泛化(Generalization), 实现(Realization),关联(Association),聚合(Aggregation),组合(Compositi ...
- UVa 699 (二叉树) The Falling Leaves
题意: 按先序方式输入一棵二叉树,节点是带权的,左孩子在父节点的左一个单位,右孩子在父节点的右一个单位,从左到右输出相同水平位置节点之和. 分析: 做了好几道二叉树的题,代码应该也很好理解了.这里ma ...
- 51nod 博弈论水题
51nod1069 Nim游戏 有N堆石子.A B两个人轮流拿,A先拿.每次只能从一堆中取若干个,可将一堆全取走,但不可不取,拿到最后1颗石子的人获胜.假设A B都非常聪明,拿石子的过程中不会出现失误 ...
- 在view中常见的四种方法的使用场合
四种方法,使view创建好里面就有东西:[1.init 2.initWithFrame使用代码创建的时候.(从文件创建的时候不一定调用:1.init 2.initWithFrame这两个方法) 3 ...
- android 项目随记一
1. requestWindowFeature(); requestWindowFeature可以设置的值有: // 1.DEFAULT_FEATURES:系统默认状态,一般不需要指定 ...
- 对于fmri的设计矩阵构造的一个很直观的解释-by 西南大学xulei教授
本程序意在解释这样几个问题:完整版代码在本文的最后. 1.实验的设计如何转换成设计矩阵? 2.设计矩阵的每列表示一个刺激条件,如何确定它们? 3.如何根据设计矩阵和每个体素的信号求得该体素对刺激的敏感 ...
- == Rickard Oberg & TheServerSide
看了Hani Suleiman和Rickard Oberg ,发现其实每个所谓的权威都应该有被质疑的绝对,可能往往权威会令人觉得理所应当
- 【转】eclipse怎么设置字体大小
原文网址:http://jingyan.baidu.com/article/f96699bb9442f3894e3c1b15.html 1. 打开eclipse,找到window 2. 点击后在下拉 ...
- linux 安装SVN
1.环境centos6.4 2.安装svnyum -y install subversion 3.配置 建立版本库目录mkdir /www/svndata svnserve -d -r /www/sv ...
- git 创建一个新分支,并将一个分支内容复制给创建的新分支
git checkout -b newBranchName