论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks
ICCV 2015 CUHK
本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做是一个 黑匣子,只是用来提取特征,而是在大量的图像和 ImageNet 分类任务上关于 CNN 的 feature 做了大量的深度的研究。这些发现促使他们设计了该跟踪系统,他们发现: 不同的卷积层会从不同的角度来刻画目标。顶层的 layer 编码了更多的关于 语义特征并且可以作为种类检测器,而底层的层懈怠了更多的具有判别性的信息,并且可以更好的区分具有相似外观的目标。在跟踪的过程中利用这两种层的不断切换而完成跟踪。作者还发现,对于一个跟踪目标,仅仅一些神经元是与其有关的,于是提出了一种 feature map 选择机制 来移除噪声和不相关的 feature maps,可以减少计算量,并且提升了跟踪的效果。在tracking benchmark 上取得了 state-of-the-art 的效果,具体是如何屌的,让我们进一步的看。
Introduction:
视觉跟踪领域仍然有许多未能很好解决的问题,像:明显的外观改变,姿态的改变,严重的遮挡,以及复杂背景等等。虽然传统方法利用手工设计的方法也研发了许多经典的跟踪算法,但是随着 CNN 的出现,跟踪领域也逐渐被深度学习方面的技术所占领,主要就是因为 CNN 可以得到更好的 feature 表达,这从很大的程度上超越了传统方法,可以看到最近的深度方面的方法基本都将 tracking 的 benchmark 刷到了 90+% 的精度,但是这些方法基本都是在海量数据上先预训练,然后 transfer 到跟踪问题上。因为跟踪问题,只是提供第一帧的 bounding box 使得深度的海量数据训练的方法有些受困。但是,纯粹的利用 CNN 强大的特征表达能力,并不能说跟踪技术发展的有多快,更加只能的算法还有待开发出来。更多的人只是将 CNN 看作是一个黑匣子,这也是本文一直在强调的,那么本文是怎么做的呢?
本文分析了各个层的特征对跟踪的影响,更加合理的选择特征来做到减少计算量的同时,提升跟踪性能。本文发现了两个有意思的属性,即:
1. 不同的层次 feature 对跟踪问题的影响不同,具体表现在:
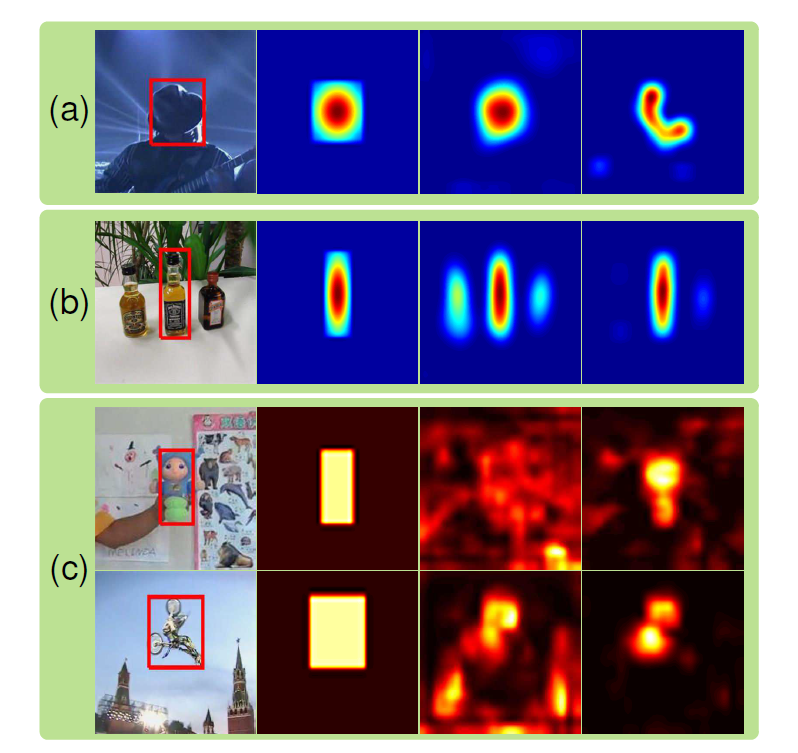
(1)顶层的 CNN 提出的 feature 具有较好的抽象 和 高层语义特征。这些特征对于区分不同的类别,或者对付 形变 和 遮挡 具有更好的鲁棒性。
(2)底层的特征提供了更多的细节的局部信息,可以更好的区分外观类似的目标。
这些方面的具体表现如下图所示:
2. 在 ImageNet 上预训练得到的 CNN feature 来分辨一般性的物体。
但是对于一个物体来讲,并非所有的 feature 都对鲁棒的跟踪有用。只有一部分是有用的,另外一部分就是属于噪声的 feature了,本文就提出一种选择有用的方法,在排除 noise 的同时,可以更好的跟踪目标。
所以本文的贡献点,总结起来就是:
1. 分析了 图像分类上深度神经网络上不同层的特征的属性,以及对跟踪问题的影响。
2. 提出一种结合两种层次特征的跟踪算法,更好的选择特征,实现更加鲁棒的跟踪。
3. 提出一种 feature 选择机制,去除干扰性的 feature,使得跟踪算法更加高效以及精确。
不同层次特征属性的分析:
本文跟踪算法基于 VGG-19,16层卷积 以及 3层 fc。
观察1:Although the receptive field 1 of CNN feature maps is large, the activated feature maps are sparse and localized. The activated regions are highly correlated to the regions of semantic objects .

观察2: Many CNN feature maps are noisy or unrelated for the task of discriminating a particular target from its background.
观察3:Different layers encode different types of features. Higher layers capture semantic concepts on object categories, whereas lower layers encode more discriminative features to capture intra class variations.
所提出的跟踪算法网络设计 FCNT:
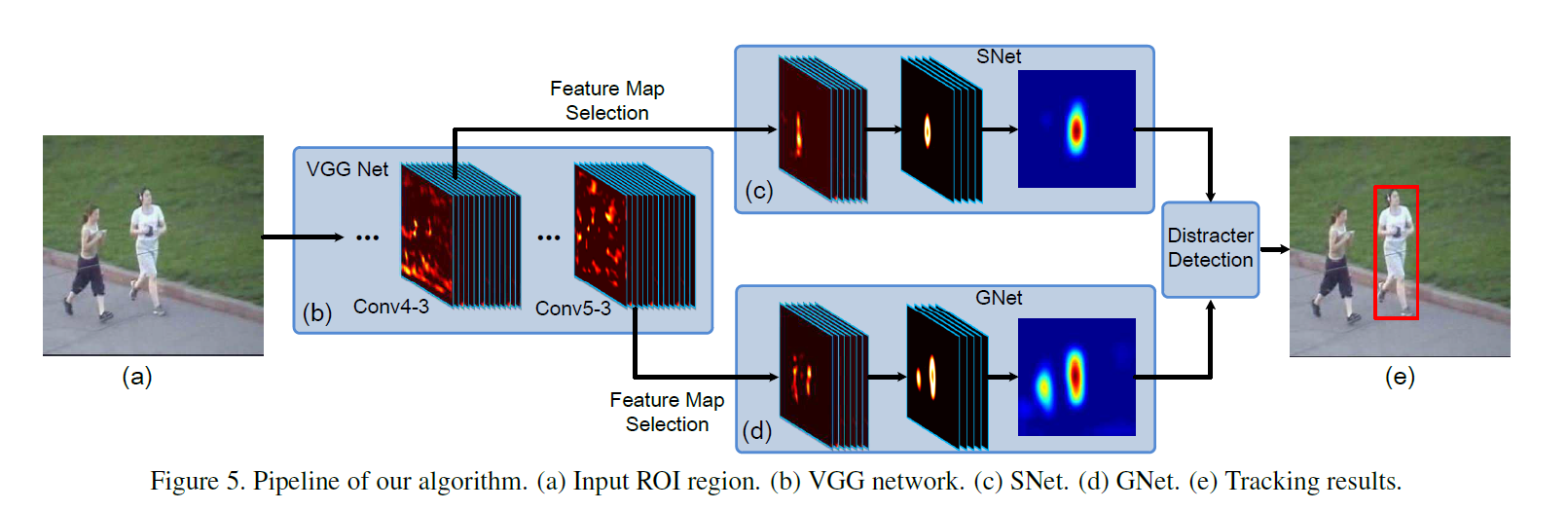
从该网络结构可以看出,本文是将输入的视频帧,首先利用 VGG-19提取feature,然后分别利用 高层的特征,传送给 SNet 以及 GNet,然后分别将这两个特征图进行映射,最后根据一个干扰性判别器,选择其中的一个 heap map 作为最终的输出,给出跟踪目标的 bounding box。然后下一帧到来后,在上一帧的位置中心,提取出一个区域,然后在进行类似的选择和定位。
1. Feature Map Selection
所提出的 feature map selection 方法是基于目标 heat map 回归模型,称为:sel-CNN,并且独立于 Conv4-3 以及 Conv5-3。它将 Conv4-3 和 Conv5-3 的 feature map 作为输入来预测目标 heat map M。该模型通过最小化 预测的前景heat map 与 目标 heat map M 之间的差距来进行训练。
本文的实验部分仅仅对第一帧图像进行了 feature selection。

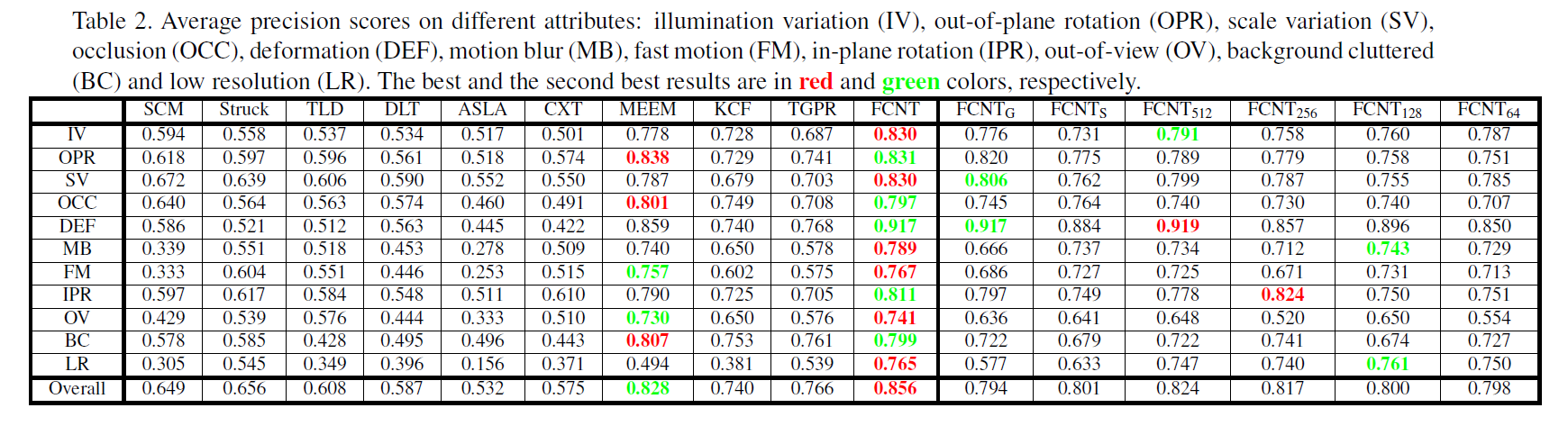
可以看到本文的精度并不算高, 即:0.85,有的传统方法的精度也已经达到了 0.9,更别提最近的深度学习方法了。
但是,从跟踪过程可以看出并不简单,确切的讲,是有点复杂的。。。同样是将 local 和 global 的信息利用起来,本文从另一个角度来解释这个问题,搞得不错。从重构出 heat map,到 heat map 的选择,也可以看出不同层特征的影响。
但是感觉,不应该精度这么低啊!呃呃呃、、、
下面是跟与其他方法的对比,以及 自身关于各种挑战的鲁棒性的分析:

论文笔记之:Visual Tracking with Fully Convolutional Networks的更多相关文章
- 论文笔记(4):Fully Convolutional Networks for Semantic Segmentation
一.FCN中的CNN 首先回顾CNN测试图片类别的过程,如下图: 主要由卷积,pool与全连接构成,这里把卷积与pool都看作图中绿色的convolution,全连接为图中蓝色的fully conne ...
- Visual Tracking with Fully Convolutional Networks
http://blog.csdn.net/carrierlxksuper/article/details/48918297 传统的跟踪方法依赖低维的人工特征,但这种特征对目标的外观变化等问题不够鲁棒. ...
- 论文笔记(5):Fully Convolutional Multi-Class Multiple Instance Learning
这篇论文主要介绍了如何使用图片级标注对像素级分割任务进行训练.想法很简单却达到了比较好的效果.文中所提到的loss比较有启发性. 大体思路: 首先同FCN一样,这个网络只有8层(5层VGG,3层全卷积 ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- 论文笔记:SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks
SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks 2019-04-02 12:44:36 Paper:ht ...
- 【Semantic Segmentation】 Instance-sensitive Fully Convolutional Networks论文解析(转)
这篇文章比较简单,但还是不想写overview,转自: https://blog.csdn.net/zimenglan_sysu/article/details/52451098 另外,读这篇pape ...
- 【Detection】R-FCN: Object Detection via Region-based Fully Convolutional Networks论文分析
目录 0. Paper link 1. Overview 2. position-sensitive score maps 2.1 Background 2.2 position-sensitive ...
- 论文翻译:2020_FLGCNN: A novel fully convolutional neural network for end-to-end monaural speech enhancement with utterance-based objective functions
论文地址:FLGCNN:一种新颖的全卷积神经网络,用于基于话语的目标函数的端到端单耳语音增强 论文代码:https://github.com/LXP-Never/FLGCCRN(非官方复现) 引用格式 ...
- 论文阅读(Xiang Bai——【CVPR2016】Multi-Oriented Text Detection with Fully Convolutional Networks)
Xiang Bai--[CVPR2016]Multi-Oriented Text Detection with Fully Convolutional Networks 目录 作者和相关链接 方法概括 ...
随机推荐
- 使用sslsplit嗅探tls/ssl连接
首先发一个从youtube弄到的sslsplit的使用教程 http://v.qq.com/page/x/k/s/x019634j4ks.html 我最近演示了如何使用mitmproxty执行中间人攻 ...
- hdu 2042
Ps:...好简单的一道题...直接AC,就是利用递归 代码: #include "stdio.h"int find(int num,int n);int main(){ int ...
- method chaining
经常写Java的话,可能比较熟悉下面这种函数调用方式 object.method1().method2() 术语叫所谓的method chaining,在c++里面,为了支持这种调用格式,你必须保障函 ...
- HtmlString类创建HTML Hepler 扩展MVC TextBox组件
第一步:定义静态类 第二步:定义静态方法1 public static class MyTextBoxEx(){ //扩展方法三要素: //1.静态类 //2.静态方法 //3.this关键字 pub ...
- magento和discuz(ucenter)整合集成开发思路
discuz自带ucenter,主要就是用于和其他程序的通信.我们可以下载discuz的ucenter开发手册进行magento和discuz的集成.里面有一些ucenter的一些接口函数和参数说明, ...
- Redis 设计与实现读书笔记一 Redis List
list结构体 adlist.h/list(源码位置) /* * 双端链表结构 */ typedef struct list { // 表头节点 listNode *head; // 表尾节点 lis ...
- Day09_面向对象第四天
1.多态的概念和前提(掌握) 1.概念-什么是多态(掌握) 对象在不同时刻表现出来的不同状态. 2.针对引用类型的理解 编译期间状态和运行期间状态不一样 比如 ...
- 设置viewport进行缩放
<meta name="viewport" content="width=320,maximum-scale=1.3,user-scalable=no"& ...
- Qt之添加Windows资源文件(.rc文件)
简述 在Windows下使用Qt时,通常会用到Windows的资源文件 - 为exe设置信息,其中包括:文件说明.产品名称.产品版本.版权等信息... 由于是Windows平台相关的东西,Qt助手中对 ...
- hadoop问题锦集(一)-搭建集群环境时的常见问题
1.没有主机的路由 1.namenode与datanode之间ping不通了 2.防火墙得关闭: ufw status ufw disabled 2. ssh localhost ssh:connec ...