MapReduce数据流(一)
在上一篇文章中我们讲解了一个基本的MapReduce作业由那些基本组件组成,从高层来看,所有的组件在一起工作时如下图所示:
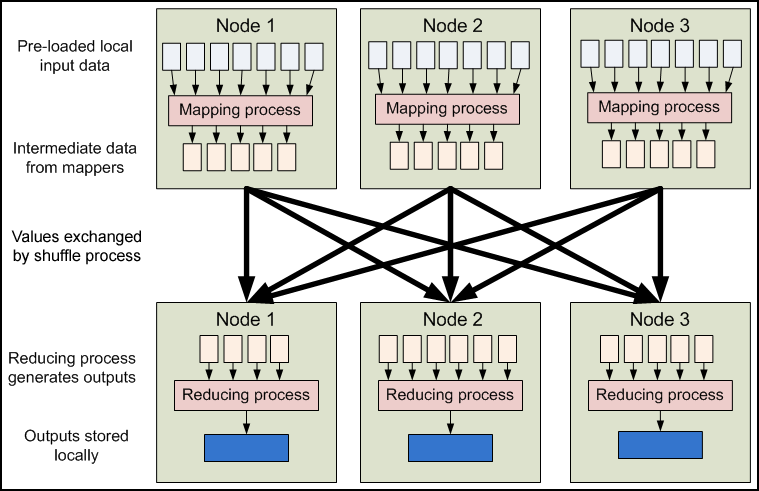
图4.4高层MapReduce工作流水线
MapReduce的输入一般来自HDFS中的文件,这些文件分布存储在集群内的节点上。运行一个MapReduce程序会在集群的许多节点甚至所有节点上运行mapping任务,每一个mapping任务都是平等的:mappers没有特定“标识物”与其关联。因此,任意的mapper都可以处理任意的输入文件。每一个mapper会加载一些存储在运行节点本地的文件集来进行处理(译注:这是移动计算,把计算移动到数据所在节点,可以避免额外的数据传输开销)。
当mapping阶段完成后,这阶段所生成的中间键值对数据必须在节点间进行交换,把具有相同键的数值发送到同一个reducer那里。Reduce任务在集群内的分布节点同mappers的一样。这是MapReduce中唯一的任务节点间的通信过程。map任务间不会进行任何的信息交换,也不会去关心别的map任务的存在。相似的,不同的reduce任务之间也不会有通信。用户不能显式的从一台机器封送信息到另外一台机器;所有数据传送都是由Hadoop MapReduce平台自身去做的,这些是通过关联到数值上的不同键来隐式引导的。这是Hadoop MapReduce的可靠性的基础元素。如果集群中的节点失效了,任务必须可以被重新启动。如果任务已经执行了有副作用(side-effect)的操作,比如说,跟外面进行通信,那共享状态必须存在可以重启的任务上。消除了通信和副作用问题,那重启就可以做得更优雅些。
近距离观察
在上一图中,描述了Hadoop MapReduce的高层视图。从那个图你可以看到mapper和reducer组件是如何用到词频统计程序中的,它们是如何完成它们的目标的。接下来,我们要近距离的来来看看这个系统以获取更多的细节。

图4.5细节化的Hadoop MapReduce数据流
图4.5展示了流线水中的更多机制。虽然只有2个节点,但相同的流水线可以复制到跨越大量节点的系统上。下去的几个段落会详细讲述MapReduce程序的各个阶段。
输入文件:文件是MapReduce任务的数据的初始存储地。正常情况下,输入文件一般是存在HDFS里。这些文件的格式可以是任意的;我们可以使用基于行的日志文件,也可以使用二进制格式,多行输入记录或其它一些格式。这些文件会很大—数十G或更大。
输入格式:InputFormat类定义了如何分割和读取输入文件,它提供有下面的几个功能:
- 选择作为输入的文件或对象;
- 定义把文件划分到任务的InputSplits;
- 为RecordReader读取文件提供了一个工厂方法;
Hadoop自带了好几个输入格式。其中有一个抽象类叫FileInputFormat,所有操作文件的InputFormat类都是从它那里继承功能和属性。当开启Hadoop作业时,FileInputFormat会得到一个路径参数,这个路径内包含了所需要处理的文件,FileInputFormat会读取这个文件夹内的所有文件(译注:默认不包括子文件夹内的),然后它会把这些文件拆分成一个或多个的InputSplit。你可以通过JobConf对象的setInputFormat()方法来设定应用到你的作业输入文件上的输入格式。下表给出了一些标准的输入格式:
|
输入格式 |
描述 |
键 |
值 |
|
TextInputFormat |
默认格式,读取文件的行 |
行的字节偏移量 |
行的内容 |
|
KeyValueInputFormat |
把行解析为键值对 |
第一个tab字符前的所有字符 |
行剩下的内容 |
|
SequenceFileInputFormat |
Hadoop定义的高性能二进制格式 |
用户自定义 |
用户自定义 |
表4.1MapReduce提供的输入格式
默认的输入格式是TextInputFormat,它把输入文件每一行作为单独的一个记录,但不做解析处理。这对那些没有被格式化的数据或是基于行的记录来说是很有用的,比如日志文件。更有趣的一个输入格式是KeyValueInputFormat,这个格式也是把输入文件每一行作为单独的一个记录。然而不同的是TextInputFormat把整个文件行当做值数据,KeyValueInputFormat则是通过搜寻tab字符来把行拆分为键值对。这在把一个MapReduce的作业输出作为下一个作业的输入时显得特别有用,因为默认输出格式(下面有更详细的描述)正是按KeyValueInputFormat格式输出数据。最后来讲讲SequenceFileInputFormat,它会读取特殊的特定于Hadoop的二进制文件,这些文件包含了很多能让Hadoop的mapper快速读取数据的特性。Sequence文件是块压缩的并提供了对几种数据类型(不仅仅是文本类型)直接的序列化与反序列化操作。Squence文件可以作为MapReduce任务的输出数据,并且用它做一个MapReduce作业到另一个作业的中间数据是很高效的。
MapReduce数据流(一)的更多相关文章
- MapReduce数据流
图4.5细节化的Hadoop MapReduce数据流 图4.5展示了流线水中的更多机制.虽然只有2个节点,但相同的流水线可以复制到跨越大量节点的系统上.下去的几个段落会详细讲述MapReduce程序 ...
- 简述MapReduce数据流
目前it基本都是一个套路,获得数据然后进行逻辑处理,存储数据. 基本上弄清楚整个的数据流向就等于把握了命脉. 现在说说mapreduce的数据流 1.首先数据会按照TextInputFormat按照特 ...
- MapReduce数据流(二)
输入块(InputSplit):一个输入块描述了构成MapReduce程序中单个map任务的一个单元.把一个MapReduce程序应用到一个数据集上,即是指一个作业,会由几个(也可能几百个)任务组成. ...
- 理解hadoop的Map-Reduce数据流(data flow)
http://blog.csdn.net/yclzh0522/article/details/6859778 Map-Reduce的处理过程主要涉及以下四个部分: 客户端Client:用于提交Map- ...
- MapReduce数据流-输出
- MapReduce数据流-Reduce
- MapReduce数据流-Partiton&Shuffle
- MapReduce数据流-Mapper
- MapReduce数据流-输入
随机推荐
- 数据存储之SQLite
SQLite是目前主流的嵌入式关系型数据库,其最主要的特点就是轻量级.跨平台,当前很多嵌入式操作系统都将其作为数据库首选.虽然SQLite是一款轻型数据库,但是其功能也绝不亚于很多大型关系数据库.学习 ...
- google_apactest_round_A_problem_D
先尝试过小数据 题目 有8张卡牌,每个卡牌都可以有不同的等级,每个卡牌的不同等级具有不同的攻击力,可以通过花钱给卡牌充值从而升级,且每次只能升一级,比如可以花1个硬币将卡牌2从1级升级到2级,同时卡牌 ...
- hiho_1048_状态压缩2
题目大意 用1x2的单元拼接出 NxM的矩形,单元可以横放或者纵放,N < 1000, M <= 5. 求不同的拼接方案总数. 分析 计算机解决问题的基本思路:搜索状态空间.如果采用dfs ...
- ubuntu server nginx 安装与配置
ubuntu server nginx 安装与配置 一:关于nginx http://wiki.ubuntu.org.cn/Nginx http://nginx.org/cn http://wiki. ...
- Windows7隐藏字体
今天突然发现字体Times New Roman消失了,如下图所示: 图1.1 不仅仅Times New Roman,还有System.MS Sans Serif--这些熟悉的字体都消失了,不能选用了! ...
- java 内部类3(匿名内部类)
匿名内部类: 1.没有类名的类就叫匿名内部类 2.好处:简化书写. 3.使用前提:必须有继承或实现关系......不要想着你自己没有钱你没可是你爸有 4.一般用于于实参.(重点) class Oute ...
- GoF--单例设计模式
保证一个类仅有一个实例,并提供一个访问它的全局访问点
- iOS 面试基础题目
转载: iOS 面试基础题目 题目来自博客:面试百度的记录,有些问题我能回答一下,不能回答的或有更好的回答我放个相关链接供参考. 1面 Objective C runtime library:Obje ...
- C#综合揭秘——细说多线程(上)
引言 本文主要从线程的基础用法,CLR线程池当中工作者线程与I/O线程的开发,并行操作PLINQ等多个方面介绍多线程的开发. 其中委托的BeginInvoke方法以及回调函数最为常用. 而 I/O线程 ...
- android浮动搜索框
android浮动搜索框的配置比较繁琐,需要配置好xml文件才能实现onSearchRequest()方法. 1.配置搜索的XML配置文件,新建文件searchable.xml,保存在res/xml ...