[离线计算-Spark|Hive] HDFS小文件处理
背景
HDFS 小文件过多会对hadoop 扩展性以及稳定性造成影响, 因为要在namenode 上存储维护大量元信息.
大量的小文件也会导致很差的查询分析性能,因为查询引擎执行查询时需要进行太多次文件的打开/读取/关闭.
小文件解决思路
通常能想到的方案就是通过Spark API 对文件目录下的小文件进行读取,然后通过Spark的算子repartition操作进行合并小文件,repartition 分区数通过输入文件的总大小和期望输出文件的大小通过预计算而得。
总体流程如下:
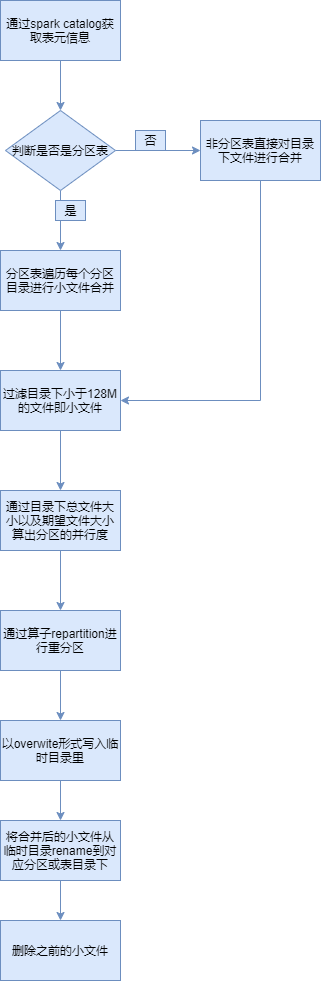
该方案适合针对已发现有小文件问题,然后对其进行处理. 下面介绍下hudi是如何实现在写入时实现对小文件的智能处理.
Hudi小文件处理
Hudi会自管理文件大小,避免向查询引擎暴露小文件,其中自动处理文件大小起很大作用
在进行insert/upsert操作时,Hudi可以将文件大小维护在一个指定文件大小
hudi 小文件处理流程:

每次写入都会遵循此过程,以确保Hudi表中没有小文件。
核心代码:
写入文件分配:
org.apache.hudi.table.action.commit.UpsertPartitioner#assignInserts
//获取分区路径
Set<String> partitionPaths = profile.getPartitionPaths();
//根据先前提交期间写入的记录获取平均记录大小。用于估计有多少记录打包到一个文件中。
long averageRecordSize = averageBytesPerRecord(table.getMetaClient().getActiveTimeline().getCommitTimeline().filterCompletedInstants(),config);
LOG.info("AvgRecordSize => " + averageRecordSize);
//获取每个分区文件路径下小文件
Map<String, List<SmallFile>> partitionSmallFilesMap =
getSmallFilesForPartitions(new ArrayList<String>(partitionPaths), jsc);
for (String partitionPath : partitionPaths) {
...
List<SmallFile> smallFiles = partitionSmallFilesMap.get(partitionPath);
//未分配的写入记录
long totalUnassignedInserts = pStat.getNumInserts();
...
for (SmallFile smallFile : smallFiles) {
//hoodie.parquet.max.file.size 数据文件最大大小,Hudi将试着维护文件大小到该指定值
//算出数据文件大小 - 小文件 就是剩余可以写入文件大小, 除以平均记录大小就是插入的记录行数
long recordsToAppend = Math.min((config.getParquetMaxFileSize() - smallFile.sizeBytes) / averageRecordSize, totalUnassignedInserts);
//分配记录到小文件中
if (recordsToAppend > 0 && totalUnassignedInserts > 0) {
// create a new bucket or re-use an existing bucket
int bucket;
if (updateLocationToBucket.containsKey(smallFile.location.getFileId())) {
bucket = updateLocationToBucket.get(smallFile.location.getFileId());
LOG.info("Assigning " + recordsToAppend + " inserts to existing update bucket " + bucket);
} else {
bucket = addUpdateBucket(partitionPath, smallFile.location.getFileId());
LOG.info("Assigning " + recordsToAppend + " inserts to new update bucket " + bucket);
}
bucketNumbers.add(bucket);
recordsPerBucket.add(recordsToAppend);
//减去已经分配的记录数
totalUnassignedInserts -= recordsToAppend;
}
//如果记录没有分配完
if (totalUnassignedInserts > 0) {
//hoodie.copyonwrite.insert.split.size 每个分区条数
long insertRecordsPerBucket = config.getCopyOnWriteInsertSplitSize();
//是否自动计算每个分区条数
if (config.shouldAutoTuneInsertSplits()) {
insertRecordsPerBucket = config.getParquetMaxFileSize() / averageRecordSize;
}
//计算要创建的bucket
int insertBuckets = (int) Math.ceil((1.0 * totalUnassignedInserts) / insertRecordsPerBucket);
...
for (int b = 0; b < insertBuckets; b++) {
bucketNumbers.add(totalBuckets);
if (b == insertBuckets - 1) {
//针对最后一个buket处理,就是写完剩下的记录
recordsPerBucket.add(totalUnassignedInserts - (insertBuckets - 1) * insertRecordsPerBucket);
} else {
recordsPerBucket.add(insertRecordsPerBucket);
}
BucketInfo bucketInfo = new BucketInfo();
bucketInfo.bucketType = BucketType.INSERT;
bucketInfo.partitionPath = partitionPath;
bucketInfo.fileIdPrefix = FSUtils.createNewFileIdPfx();
bucketInfoMap.put(totalBuckets, bucketInfo);
totalBuckets++;
}
}
}
}
获取每个分区路径下小文件:
org.apache.hudi.table.action.commit.UpsertPartitioner#getSmallFiles
if (!commitTimeline.empty()) { // if we have some commits
HoodieInstant latestCommitTime = commitTimeline.lastInstant().get();
List<HoodieBaseFile> allFiles = table.getBaseFileOnlyView()
.getLatestBaseFilesBeforeOrOn(partitionPath, latestCommitTime.getTimestamp()).collect(Collectors.toList());
for (HoodieBaseFile file : allFiles) {
//获取小于 hoodie.parquet.small.file.limit 参数值就为小文件
if (file.getFileSize() < config.getParquetSmallFileLimit()) {
String filename = file.getFileName();
SmallFile sf = new SmallFile();
sf.location = new HoodieRecordLocation(FSUtils.getCommitTime(filename), FSUtils.getFileId(filename));
sf.sizeBytes = file.getFileSize();
smallFileLocations.add(sf);
}
}
}
UpsertPartitioner继承spark的Partitioner, hudi在写入的时候会利用spark 自定分区的机制优化记录分配到不同文件的能力, 从而达到在写入时不断优化解决小文件问题.
涉及到的关键配置:
hoodie.parquet.max.file.size:数据文件最大大小,Hudi将试着维护文件大小到该指定值;
hoodie.parquet.small.file.limit:小于该大小的文件均被视为小文件;
hoodie.copyonwrite.insert.split.size:单文件中插入记录条数,此值应与单个文件中的记录数匹配(可以根据最大文件大小和每个记录大小来确定)
在hudi写入时候如何使用、配置参数?
在写入hudi的代码中 .option中配置上述参数大小,如下:
.option(HoodieStorageConfig.DEFAULT_PARQUET_FILE_MAX_BYTES, 120 * 1024 * 1024)
总结
本文主要介绍小文件的处理方法思路,以及通过阅读源码和相关资料学习hudi 如何在写入时智能的处理小文件问题新思路.Hudi利用spark 自定义分区的机制优化记录分配到不同文件的能力,达到小文件的合并处理.
参考
[离线计算-Spark|Hive] HDFS小文件处理的更多相关文章
- 合并hive/hdfs小文件
磁盘: heads/sectors/cylinders,分别就是磁头/扇区/柱面,每个扇区512byte(现在新的硬盘每个扇区有4K) 文件系统: 文件系统不是一个扇区一个扇区的来读数据,太慢了,所以 ...
- 解决HDFS小文件带来的计算问题
hive优化 一.小文件简述 1.1. HDFS上什么是小文件? HDFS存储文件时的最小单元叫做Block,Hadoop1.x时期Block大小为64MB,Hadoop2.x时期Block大小为12 ...
- Hive如何处理小文件问题?
一.小文件是如何产生的 1.动态分区插入数据,产生大量的小文件,从而导致map数量剧增. 2.reduce数量越多,小文件也越多(reduce的个数和输出文件是对应的). 3.数据源本身就包含大量的小 ...
- hive 处理小文件,减少map数
1.hive.merge.mapfiles,True时会合并map输出.2.hive.merge.mapredfiles,True时会合并reduce输出.3.hive.merge.size.per. ...
- Spark优化之小文件是否需要合并?
我们知道,大部分Spark计算都是在内存中完成的,所以Spark的瓶颈一般来自于集群(standalone, yarn, mesos, k8s)的资源紧张,CPU,网络带宽,内存.Spark的性能,想 ...
- HDFS小文件处理——Mapper处理
处理小文件的时候,可以通过org.apache.hadoop.io.SequenceFile.Writer类将所有文件写出到一个seq文件中. 大致流程如下: 实现代码: package study. ...
- HDFS 小文件处理——应用程序实现
在真实环境中,处理日志的时候,会有很多小的碎文件,但是文件总量又是很大.普通的应用程序用来处理已经很麻烦了,或者说处理不了,这个时候需要对小文件进行一些特殊的处理——合并. 在这通过编写java应用程 ...
- SparkHiveContext和直接Spark读取hdfs上文件然后再分析效果区别
最近用spark在集群上验证一个算法的问题,数据量大概是一天P级的,使用hiveContext查询之后再调用算法进行读取效果很慢,大概需要二十多个小时,一个查询将近半个小时,代码大概如下: try: ...
- Hadoop记录-hive merge小文件
1. Map输入合并小文件对应参数:set mapred.max.split.size=256000000; #每个Map最大输入大小set mapred.min.split.size.per.no ...
- hadoop 小文件 挂载 小文件对NameNode的内存消耗 HDFS小文件解决方案 客户端 自身机制 HDFS把块默认复制3次至3个不同节点。
hadoop不支持传统文件系统的挂载,使得流式数据装进hadoop变得复杂. hadoo中,文件只是目录项存在:在文件关闭前,其长度一直显示为0:如果在一段时间内将数据写到文件却没有将其关闭,则若网络 ...
随机推荐
- RabbitMq高级特性之死信队列 通俗易懂 超详细 【内含案例】
RabbitMq高级特性之死信队列 又称 死信交换机 DLX 介绍 当消息成为 Dead message 后,会重新发送到另一个交换机,这个交换机就是 DLX(死信交换机) 消息成为死信的情况公有三种 ...
- AArch64 汇编学习笔记
PIE(Position Independent Executable,位置无关的可执行文件)通过随机化可执行文件各个部分在虚拟内存中的地址使得攻击者无法通过预测地址进行恶意行为. 汇编开发工具: a ...
- 【selenium + python】之BSTestRunner生成测试报告时报错:NameError: name 'unicode' is not defined
好久没生成报告了,最近使用的时候报了一个错误!用的这个报告模板BSTestRunner但是汇报下面的错误: NameError: name 'unicode' is not defined 经查询得知 ...
- 一次Java性能调优实践【代码+JVM 性能提升70%】
这是我第一次对系统进行调优,涉及代码和JVM层面的调优.如果你能看到最后的话,或许会对你日常的开发有帮助,可以避免像我一样,犯一些低级别的错误.本次调优的代码是埋点系统中的报表分析功能,小公司,开发结 ...
- 使用 nuxi upgrade 升级现有nuxt项目版本
title: 使用 nuxi upgrade 升级现有nuxt项目版本 date: 2024/9/10 updated: 2024/9/10 author: cmdragon excerpt: 摘要: ...
- JS之Math.sin与Math.cos介绍及应用-实现鼠标点击后的烟花效果
基本介绍 Math.sin(x) :x 的正玄值.返回值在 -1.0 到 1.0 之间: Math.cos(x) :x 的余弦值.返回的是 -1.0 到 1.0 之间的数: 其中函数中是x是指&quo ...
- 想好新年去哪了吗?合合信息扫描全能王用AI“留住”年味
还有不到十天,除夕就要到了.近几年春节假期中,有人第一次带着孩子直击海面冰风,坐船回老家:也有人选择"漫游"国内外,在旅行中迎接新春的朝气.合合信息旗下扫描全能王APP通过AI扫描 ...
- 游览器 reflow
refer: https://juejin.im/post/5a9372895188257a6b06132e reflow 伤性能. 所以要闪. 有几个频密触发的东西要留意. 1. scroll 2. ...
- 使用 Wake Lock API:保持设备唤醒的最佳实践
在现代 Web 应用中,尤其是涉及视频播放.实时通信.地图导航等长时间运行的任务时,用户常常希望设备不要因为空闲而自动进入睡眠模式或屏幕变暗.为了解决这一问题,Web API 提供了一个名为 Wake ...
- 三大硬核方式揭秘:Java如何与底层硬件和工业设备轻松通信!
大家好,我是V哥,程序员聊天真是三句不到离不开技术啊,这不前两天跟一个哥们吃饭,他是我好多年前的学员了,一直保持着联系,现在都李总了,在做工业互联网相关的项目,真是只要 Java 学得好,能干一辈子, ...