完全分布式Hadoop2.3安装与配置
一、Hadoop基本介绍
Hadoop优点
1.高可靠性:Hadoop按位存储和处理数据
2.高扩展性:Hadoop是在计算机集群中完成计算任务,这个集群可以方便的扩展到几千台
3.高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度快
4.高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配
5.低成本:Hadoop是开源的,集群是由廉价的PC机组成
Hadoop架构和组件
Hadoop是一个分布式系统基础架构,底层是HDFS(Hadoop Distributed File System)分布式文件系统,它存储Hadoop集群中所有存储节点上的文件(64MB块),HDFS上一层是MapReduce引擎(分布式计算框架),对分布式文件系统中的数据进行分布式计算。
1.HDFS架构
NameNode:Hadoop集群中只有一个NameNode,它负责管理HDFS的目录树和相关文件的元数据信息
Sencondary NameNode:有两个作用,一是镜像备份,二是日志与镜像定期合并,并传输给NameNode
DataNode:负责实际的数据存储,并将信息定期传输给NameNode
2.MapReduce架构(Hadoop0.23以后采用MapReduce v2.0或Yarn)
Yarn主要是把jobtracker的任务分为两个基本功能:资源管理和任务调度与监控,ResourceManager和每个节点(NodeManager)组成了新处理数据的框架。
ResourceManager:负责集群中的所有资源的统一管理和分配,接受来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各种应用程序(ApplicationMaster)。
NodeManager:与ApplicationMaster承担了MR1框架中的tasktracker角色,负责将本节点上的资源使用情况和任务运行进度汇报给ResourceManager。
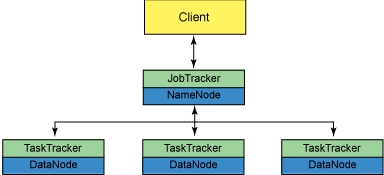
MapReduce v1.0框架(图1)
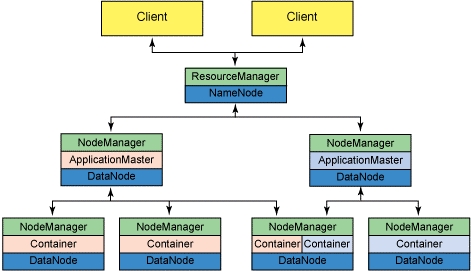
MapReduce v2.0框架(图2)
环境介绍:
master-hadoop 192.168.0.201
slave1-hadoop 192.168.0.202
slave2-hadoop 192.168.0.203
最新稳定版:http://www.apache.org/dist/hadoop/core/hadoop-2.3.0/
JDK下载:http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
参考官方文档:http://hadoop.apache.org/docs/r2.3.0/hadoop-project-dist/hadoop-common/ClusterSetup.html
Hadoop三种运行方式:单节点方式(单台)、单机伪分布方式(一个节点的集群)与完全分布式(多台组成集群)
二、准备环境
1.Hadoop是用Java开发的,必须要安装JDK1.6或更高版本
2.Hadoop是通过SSH来启动slave主机中的守护进程,必须安装OpenSSH
3.Hadoop更新比较快,我们采用最新版hadoop2.3来安装
4.配置对应Hosts记录,关闭iptables和selinux(过程略)
5.创建相同用户及配置无密码认证
三、安装环境(注:三台配置基本相同)
1.安装JDK1.7
|
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@master-hadoop ~]# tar zxvf jdk-7u17-linux-x64.tar.gz[root@master-hadoop ~]# mv jdk1.7.0_17/ /usr/local/jdk1.7[root@slave1-hadoop ~]# vi/etc/profile #末尾添加变量JAVA_HOME=/usr/local/jdk1.7PATH=$PATH:$JAVA_HOME/binCLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/jre/libexport JAVA_HOME CLASSPATHPATH[root@slave1-hadoop ~]#source /etc/profile[root@slave1-hadoop ~]# java-version #显示版本说明配置成功java version"1.7.0_17"Java(TM) SE RuntimeEnvironment (build 1.7.0_17-b02)Java HotSpot(TM) 64-BitServer VM (build 23.7-b01, mixed mode) |
2.创建hadoop用户,指定相同UID
|
1
2
3
4
5
6
|
[root@master-hadoop ~]#useradd -u 600 hadoop[root@master-hadoop ~]#passwd hadoopChanging password for userhadoop.New password:Retype new password:passwd: all authenticationtokens updated successfully. |
3.配置SSH无密码登录(注:master-hadoop本地也要实现无密码登录)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
[root@master-hadoop ~]# su - hadoop[hadoop@master-hadoop ~]$ ssh-keygen -t rsa #一直回车生成密钥[hadoop@master-hadoop ~]$ cd/home/hadoop/.ssh/[hadoop@master-hadoop .ssh]$ lsid_rsa id_rsa.pub[hadoop@slave1-hadoop ~]$ mkdir /home/hadoop/.ssh #登录两台创建.ssh目录[hadoop@slave2-hadoop ~]$ mkdir /home/hadoop/.ssh[hadoop@master-hadoop .ssh]$ scp id_rsa.pub hadoop@slave1-hadoop:/home/hadoop/.ssh/[hadoop@master-hadoop .ssh]$ scp id_rsa.pub hadoop@slave2-hadoop:/home/hadoop/.ssh/[hadoop@slave1-hadoop ~]$ cd/home/hadoop/.ssh/[hadoop@slave1-hadoop .ssh]$ cat id_rsa.pub >> authorized_keys[hadoop@slave1-hadoop .ssh]$ chmod 600 authorized_keys[hadoop@slave1-hadoop .ssh]$ chmod 700 ../.ssh/ #目录权限必须设置700[root@slave1-hadoop ~]# vi /etc/ssh/sshd_config #开启RSA认证RSAAuthentication yesPubkeyAuthentication yesAuthorizedKeysFile .ssh/authorized_keys[root@slave1-hadoop ~]# service sshd restart |
四、Hadoop的安装与配置(注:三台服务器配置一样,使用scp复制过去)
|
1
2
3
4
5
6
7
|
[root@master-hadoop ~]# tar zxvf hadoop-2.3.0.tar.gz -C /home/hadoop/[root@master-hadoop ~]# chown hadoop.hadoop -R /home/hadoop/hadoop-2.3.0/[root@master-hadoop ~]# vi /etc/profile #添加hadoop变量,方便使用HADOOP_HOME=/home/hadoop/hadoop-2.3.0/PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinexport HADOOP_HOME PATH[root@master-hadoop ~]# source /etc/profile |
1. hadoop-env.sh设置jdk路径
|
1
2
3
|
[hadoop@master-hadoop ~]$ cd hadoop-2.3.0/etc/hadoop/[hadoop@master-hadoop hadoop]$ vi hadoop-env.shexport JAVA_HOME=/usr/local/jdk1.7/ |
2.slaves设置从节点
|
1
2
3
|
[hadoop@master-hadoophadoop]$ vi slavesslave1-hadoopslave2-hadoop |
3.core-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
<configuration><property><name>fs.defaultFS</name><value>hdfs://master-hadoop:9000</value></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>hadoop.tmp.dir</name><value>file:/home/hadoop/tmp</value></property></configuration>4.hdfs-site.xml<configuration><property><name>dfs.namenode.name.dir</name><value>file:/home/hadoop/dfs/name</value></property><property><name>dfs.namenode.data.dir</name><value>file:/home/hadoop/dfs/data</value></property><property><name>dfs.replication</name> #数据副本数量,默认3,我们是两台设置2<value>2</value></property></configuration> |
6.yarn-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
<configuration><property><name>yarn.resourcemanager.address</name><value>master-hadoop:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>master-hadoop:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>master-hadoop:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>master-hadoop:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>master-hadoop:8088</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value></property></configuration> |
7.mapred-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master-hadoop:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master-hadoop:19888</value></property></configuration> |
五、格式化文件系统并启动
1.格式化新的分布式文件系统(hdfs namenode -format)
2.启动HDFS文件系统并使用jps检查守护进程是否启动

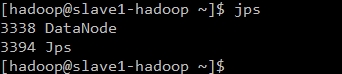
可以看到master-hadoop已经启动NameNode和SecondaryNameNode进程,slave-hadoop已经启动DataNode进程说明正常。
3.启动新mapreduce架构(YARN)

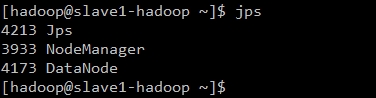
可以看到master-hadoop已经启动ResourceManger进程,slave-hadoop已经启动NodeManager进程说明正常。
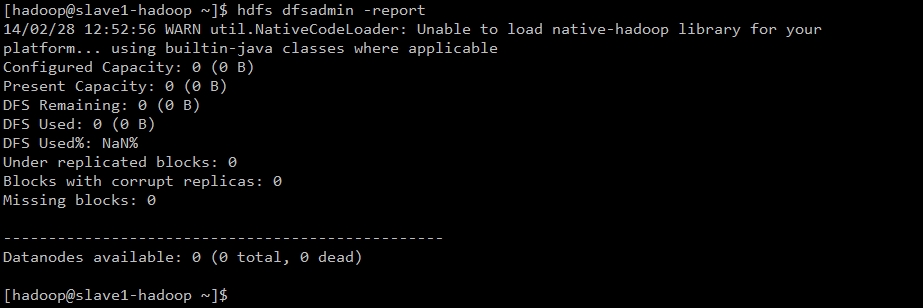
4.查看集群状态
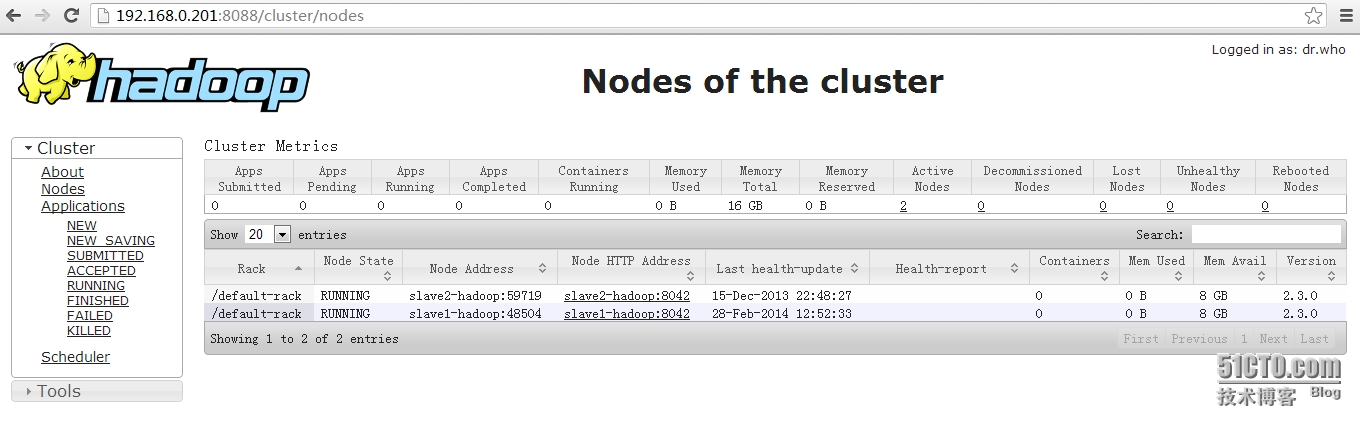
5.通过web查看资源(http://192.168.0.201:8088)
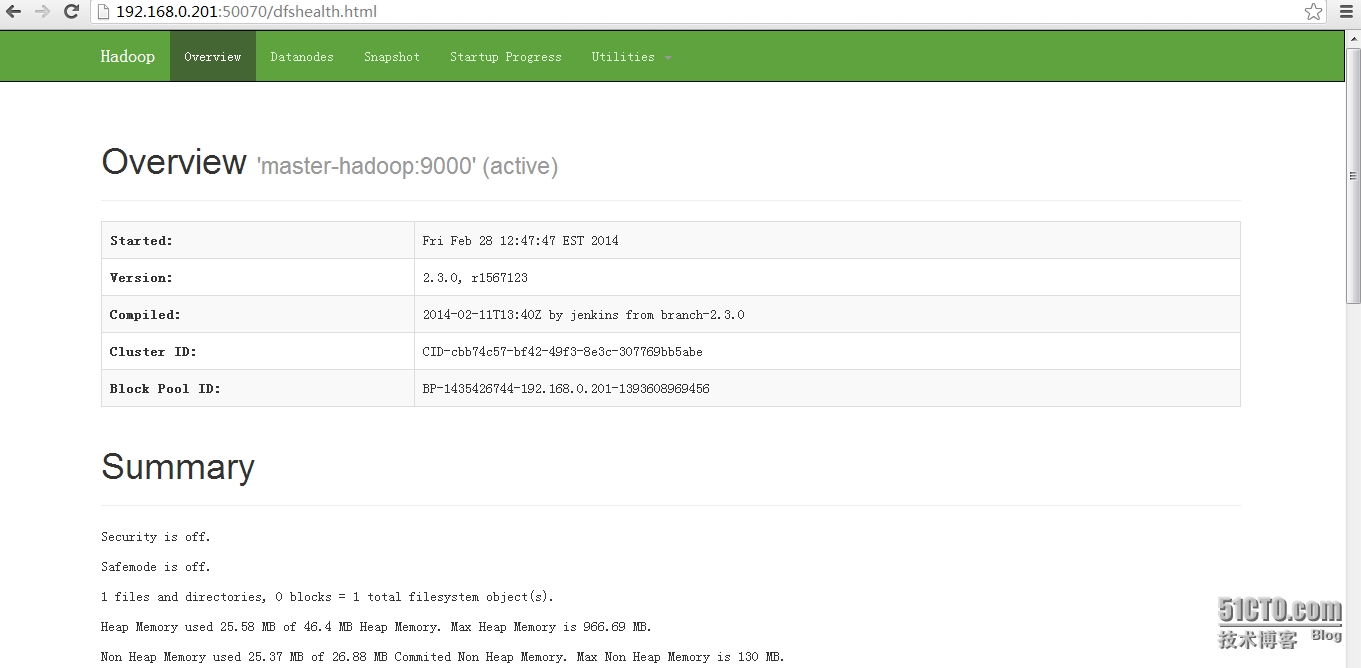
6、查看HDFS状态(http://192.168.0.201:50070)
本文出自 ““企鹅”那点事儿” 博客,请务必保留此出处http://going.blog.51cto.com/7876557/1365883
完全分布式Hadoop2.3安装与配置的更多相关文章
- hadoop2.7.7 分布式集群安装与配置
环境准备 服务器四台: 系统信息 角色 hostname IP地址 Centos7.4 Mster hadoop-master-001 10.0.15.100 Centos7.4 Slave hado ...
- zabbix分布式监控服务 安装与配置
zabbix安装与配置 一.什么是zabbix及优缺点(对比cacti和nagios) Zabbix能监视各种网络参数,保证服务器系统的安全运营:并提供灵活的通知机制以让系统管理员快速定位/解决存 ...
- hadoop2.0安装和配置
hadoop2与hadoop1的配置有些许不同,最主要的是hadoop1里的master变成了yarn 这篇文直接从hadoop的配置开始,因为系统环境和jdk和hadoop1都是一样的. hadoo ...
- 分布式管理系统-git安装及配置
安装完成后,在开始菜单里找到“Git”->“Git Bash”,蹦出一个类似命令行窗口的东西,就说明Git安装成功! 安装完成后,还需要最后一步设置,在命令行输入: $ git config - ...
- hadoop-2.5安装与配置
安装之前准备4台机器:bluejoe0,bluejoe4,bluejoe5,bluejoe9 bluejoe0作为master,bluejoe4,5,9作为slave bluejoe0作为nameno ...
- hadoop完全分布式模式的安装和配置
本文是将三台电脑用路由器搭建本地局域网,系统为centos6.5,已经实验验证,搭建成功. 一.设置静态IP&修改主机名&关闭防火墙(all-root)(对三台电脑都需要进行操作) 0 ...
- 分布式文件系统FastDFS安装与配置(单机)
安装包如下:fastdfs-nginx-module_v1.16.tar.gzFastDFS_v5.05.tar.gzlibfastcommon-master.zipnginx-1.8.0.tar.g ...
- Ubuntu16.04下伪分布式环境搭建之hadoop、jdk、Hbase、phoenix的安装与配置
一.准备工作 安装包链接: https://pan.baidu.com/s/1i6oNmOd 密码: i6nc 环境准备 修改hostname: $ sudo vi /etc/hostname why ...
- Hadoop:Hadoop单机伪分布式的安装和配置
http://blog.csdn.net/pipisorry/article/details/51623195 因为lz的linux系统已经安装好了很多开发环境,可能下面的步骤有遗漏. 之前是在doc ...
随机推荐
- 关于rewriteRule的一个小问题
RewriteEngine on # RewriteRule ^test.php$ modrewrite.php# RewriteRule ^(.*) http://www.baidu.com [L] ...
- bzoj1025: [SCOI2009] 游戏 6
DP. 每种排法的长度对应所有循环节长度的最小公倍数. 所以排法总数为和为n的几个数的最小公倍数的总数. #include<cstdio> #include<algorithm> ...
- Unity3D之如何创建正确的像素比在屏幕上
关于这篇文章的命名,实在不知道怎么命名好,大概功能就是:比如一张宽高为100x100的图片显示在屏幕上,那2D摄像头的Size值为多少时,屏幕上显示出来图片大小和图片的实际像素一致. 这里涉及到一个G ...
- 使用Unity3D自带动画系统制作下雨效果
之前看了以前版本的unity3d demo AngryBots ,觉得里面的下雨效果不错,刚好前段时间学习了,写出来跟大家分享下,直接开始. 使用自带动画系统制作下雨效果. 先制作下雨的雨滴涟漪 步骤 ...
- [swustoj 1092] 二分查找的最大次数
二分查找的最大次数(1092) 问题描述 这里是一个在排序好的数组A(从小到大)中查找整数X的函数,返回值是查找次数. int binarySearch(inta[],int n,int x)//数组 ...
- oracle静态与动态监听
在运行lsnrctl命令的status时,常会看到如下返回值: 服务“test”包含1个例程. 例程"mydata",状态 UNKOWN,包含此服务的一个处理程序... 服务 ...
- Android学习系列(20)--App数据格式之解析Json
JSON数据格式,在Android中被广泛运用于客户端和网络(或者说服务器)通信,非常有必要系统的了解学习. 恰逢本人最近对json做了一个简单的学习,特此总结一下,以飨各位. 为了文 ...
- linux下判断网络是否连接
本文改写自网上的一个程序,原始程序中为阻塞式调用,而且有现成创建的过程,非常不利于集成到自己程序中,因此对原始程序进行改造,使其可以完成发送一个imcp包的方式来判断网络连通,只需要调用改进后的 bo ...
- java中接口与多重继承的关系
在Java语言中, abstract class 和interface 是支持抽象类定义的两种机制.正是由于这两种机制的存在,才赋予了Java强大的 面向对象能力.abstract class和int ...
- docker专题(2):docker常用管理命令(上)
http://segmentfault.com/a/1190000000751601 本文只记录docker命令在大部分情境下的使用,如果想了解每一个选项的细节,请参考官方文档,这里只作为自己以后的备 ...