爬虫技术(六)-- 使用HtmlAgilityPack获取页面链接(附c#代码及插件下载)
菜鸟HtmlAgilityPack初体验。。。弱弱的代码。。。
Html Agility Pack是一个开源项目,为网页提供了标准的DOM API和XPath导航。使用WebBrowser和HttpWebRequest下载的网页可以用Html Agility Pack来解析。
HtmlAgilityPack的文档是CHM格式的,有时会无法正常阅读CHM格式的文件。如果是IE不能链接到您请求的网页或者打开后“页面无法显示”。请在要打开的CHM文件上右击属性,会在底下属性多了个“解除锁定”,单击后就可以正常显示了。
如果有需要下载,请点击HtmlAgilityPack.1.4.0下载,解压后找到HtmlAgilityPack.dll,把它添加到项目中。
HtmlAgilityPack.dll中的类都位于HtmlAgilityPack命名空间。
HtmlDocument表示一个完整的HTML文档。用Load方法加载网页。
下面进行HtmlAgilityPack初体验,
实现目标:,点击按钮后,根据给定的网址,打印出该页面的所有链接。简单代码如下:

1 using System;
2 using System.Collections.Generic;
3 using System.ComponentModel;
4 using System.Data;
5 using System.Drawing;
6 using System.Linq;
7 using System.Text;
8 using System.Windows.Forms;
9 using HtmlAgilityPack;
10
11 namespace HtmlAgilityPackDemo1
12 {
13 public partial class Form1 : Form
14 {
15 public Form1()
16 {
17 InitializeComponent();
18 }
19
20 private void Form1_Load(object sender, EventArgs e)
21 {
22
23 }
24
25 private void button1_Click(object sender, EventArgs e)
26 {
27 HtmlWeb webClient = new HtmlWeb();
28 HtmlAgilityPack.HtmlDocument doc = webClient.Load("http://www.cnblogs.com/lmei");
29
30 HtmlNodeCollection hrefList = doc.DocumentNode.SelectNodes(".//a[@href]");
31
32 if (hrefList != null)
33 {
34 foreach (HtmlNode href in hrefList)
35 {
36 HtmlAttribute att = href.Attributes["href"];
37 Console.WriteLine(att.Value);
38
39 }
40
41 }
42
43 }
44 }
45 }
当上面第28行代码写成如下,
HtmlDocument doc = webClient.Load("http://www.cnblogs.com/lmei");
会出现错误提示,

于是修改如下,
HtmlAgilityPack.HtmlDocument doc = webClient.Load("http://www.cnblogs.com/lmei");
接下来,看下控制台的输出,截图如下:

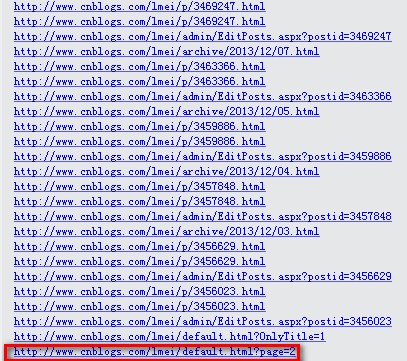
可见,网页上面的超链接都被打印出来了。。。
当然,如果想要抓取的是网页上面的正文,加载后可能出现乱码问题,则可以指定文件的编码:
HtmlAgilityPack.HtmlDocument htmlDoc = new HtmlAgilityPack.HtmlDocument();
Encoding encoder = Encoding.GetEncoding("utf-8");
htmlDoc.Load("http://www.cnblogs.com/lmei/p/3485649.html", encoder);
爬虫技术(六)-- 使用HtmlAgilityPack获取页面链接(附c#代码及插件下载)的更多相关文章
- 爬虫技术 -- 进阶学习(九)使用HtmlAgilityPack获取页面链接(附c#代码及插件下载)
菜鸟HtmlAgilityPack初体验...弱弱的代码... Html Agility Pack是一个开源项目,为网页提供了标准的DOM API和XPath导航.使用WebBrowser和HttpW ...
- 总结整理 -- 爬虫技术(C#版)
爬虫技术学习总结 爬虫技术 -- 基础学习(一)HTML规范化(附特殊字符编码表) 爬虫技术 -- 基本学习(二)爬虫基本认知 爬虫技术 -- 基础学习(三)理解URL和URI的联系与区别 爬虫技术 ...
- wordpress获取当前页面链接
我们知道wordpress的<?php the_permalink(); ?>和<?php echo get_permalink(); ?>可以获取页面链接,但是有些比较复杂的 ...
- 使用webcollector爬虫技术获取网易云音乐全部歌曲
最近在知乎上看到一个话题,说使用爬虫技术获取网易云音乐上的歌曲,甚至还包括付费的歌曲,哥瞬间心动了,这年头,好听的流行音乐或者经典老歌都开始收费了,只能听不能下载,着实很郁闷,现在机会来了,于是开始研 ...
- 使用htmlparse爬虫技术爬取电影网页的全部下载链接
昨天,我们利用webcollector爬虫技术爬取了网易云音乐17万多首歌曲,而且还包括付费的在内,如果时间允许的话,可以获取更多的音乐下来,当然,也有小伙伴留言说这样会降低国人的知识产权保护意识,诚 ...
- 使用htmlparser爬虫技术爬取电影网页的全部下载链接
昨天,我们利用webcollector爬虫技术爬取了网易云音乐17万多首歌曲,而且还包括付费的在内,如果时间允许的话,可以获取更多的音乐下来,当然,也有小伙伴留言说这样会降低国人的知识产权保护意识,诚 ...
- thinkphp下通过页面链接传递的参数获取一次后失效
在thinkphp下通过页面链接传递的参数获取一次后失效,ajax内部无法再次使用.想要使用必须再次用js获取其值,通过ajax传递给后台使用. 1.通过页面链接传递参数给下一页 2.可以再下一页后台 ...
- js 获取页面内链接
今天有同学问如何用 JS 正则表达式获取一段文本中的超链接,并对超链接进行处理,想了几分钟,写了下面的代码: var re = /https?:\/\/[\w\.:~\-\d\/]+(?:\?[\w\ ...
- coolite 获取新的页面链接到当前页面指定位置Panel的运用
如下图所示,点击温州市文成县之前,右边是一片空白,点击后生成新的页面 html运用到了coolite的Panel控件 <Center> <ext:Panel ID="Pan ...
随机推荐
- ios状态栏调整 简单动画的知识点
首先状态栏式view的属性,所以在viewController中直接重写: /** 修改状态栏 */ - (UIStatusBarStyle)preferredStatusBarStyle { // ...
- iOS优化内存方法推荐
1. 用ARC管理内存 ARC(Automatic ReferenceCounting, 自动引用计数)和iOS5一起发布,它避免了最常见的也就是经常是由于我们忘记释放内存所造成的内存泄露.它自动为你 ...
- vs2008中使用正则删除空行
起因 今天下了段代码复制到VS2008中想好好学习下,结果发现每隔一行都有一行空白行(如下图),如果只有几行么手动删下就好了,但是这边估计有几百行,我也不知道VS2008有没有什么支持快速删除空白行的 ...
- mysql merge
merge 是一组 myisam 表的组合, 锁住一个 merge 表它会吧底下所有的表全给锁住. 创建只读表 )) engine = merge union (t1,t2); 创建可插入的表, (以 ...
- 【HDOJ】【3037】Saving Beans
排列组合 啊……这题是要求c(n-1,0)+c(n,1)+c(n+1,2)+......+c(n+m-1,m) 这个玩意……其实就等于c(n+m,m) 好吧然后就是模P……Lucas大法好= = 我S ...
- PHP之cookie相关实例教程与经典代码
·php 中cookie和session的用法比较 ·php会话控制cookie与Session会话处理 ·php中利用cookie实现购物车实例 ·php中cookie与session应用学习笔记 ...
- uva 10106
尝试一下java 的大数类 import java.util.*; import java.io.*; import java.math.BigInteger; public class Main { ...
- soap消息机制 讲解
SOAP(Simple Object Access Protocol,简单对象访问协议)作为一种信息交互协议在分布式应用中非常广泛,如WebService.在使用.Net开发WebService时候, ...
- [转载]Spring Java Based Configuration
@Configuration & @Bean Annotations Annotating a class with the @Configuration indicates that the ...
- Candy
There are N children standing in a line. Each child is assigned a rating value. You are giving candi ...