client 如何找到正确的RegionServer(HBase -ROOT-和.META.表)
在HBase中,大部分的操作都是在RegionServer完成的,Client端想要插入,删除,查询数据都需要先找到相应的RegionServer。什么叫相应的RegionServer?就是管理你要操作的那个Region的RegionServer。Client本身并不知道哪个RegionServer管理哪个Region,那么它是如何找到相应的RegionServer的?本文就是在研究源码的基础上揭秘这个过程。 在前面的文章“HBase存储架构”中我们已经讨论了HBase基本的存储架构。在此基础上我们引入两个特殊的概念:-ROOT-和.META.。这是什么?它们是HBase的两张内置表,从存储结构和操作方法的角度来说,它们和其他HBase的表没有任何区别,你可以认为这就是两张普通的表,对于普通表的操作对它们都适用。它们与众不同的地方是HBase用它们来存贮一个重要的系统信息——Region的分布情况以及每个Region的详细信息。 好了,既然我们前面说到-ROOT-和.META.可以被看作是两张普通的表,那么它们和其他表一样就应该有自己的表结构。没错,它们有自己的表结构,并且这两张表的表结构是相同的,在分析源码之后我将这个表结构大致的画了出来:
-ROOT-和.META.表结构
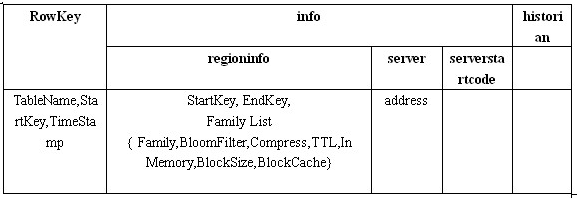
我们来仔细分析一下这个结构,每条Row记录了一个Region的信息。
首先是RowKey,RowKey由三部分组成:TableName, StartKey 和 TimeStamp。RowKey存储的内容我们又称之为Region的Name。哦,还记得吗?我们在前面的文章中提到的,用来存放Region的文件 夹的名字是RegionName的Hash值,因为RegionName可能包含某些非法字符。现在你应该知道为什么RegionName会包含非法字符 了吧,因为StartKey是被允许包含任何值的。将组成RowKey的三个部分用逗号连接就构成了整个RowKey,这里TimeStamp使用十进制 的数字字符串来表示的。这里有一个RowKey的例子:
Table1,RK10000,12345678
然后是表中最主要的Family:info,info里面包含三个 Column:regioninfo, server, serverstartcode。其中regioninfo就是Region的详细信息,包括StartKey, EndKey 以及每个Family的信息等等。server存储的就是管理这个Region的RegionServer的地址。
所以当Region被拆分、合并或者重新分配的时候,都需要来修改这张表的内容。
到目前为止我们已经学习了必须的背景知识,下面我们要正式开始介绍Client端寻找RegionServer的整个过程。我打算用一个假想的例子来学习这个过程,因此我先构建了假想的-ROOT-表和.META.表。
我们先来看.META.表,假设HBase中只有两张用户表:Table1和 Table2,Table1非常大,被划分成了很多Region,因此在.META.表中有很多条Row用来记录这些Region。而Table2很小, 只是被划分成了两个Region,因此在.META.中只有两条Row用来记录。这个表的内容看上去是这个样子的:
.META.行记录结构
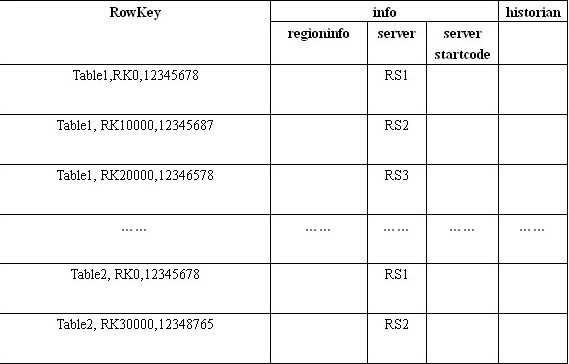
现在假设我们要从Table2里面插寻一条RowKey是RK10000的数据。那么我们应该遵循以下步骤:
1. 从.META.表里面查询哪个Region包含这条数据。
2. 获取管理这个Region的RegionServer地址。
3. 连接这个RegionServer, 查到这条数据。
好,我们先来第一步。
问题 是.META.也是一张普通的表,我们需要先知道哪个RegionServer管理了.META.表,怎么办?有一个方法,我们把管理.META.表的 RegionServer的地址放到ZooKeeper上面不久行了,这样大家都知道了谁在管理.META.。
貌似问题解决了,但对于这个例子我们遇 到了一个新问题。因为Table1实在太大了,它的Region实在太多了,.META.为了存储这些Region信息,花费了大量的空间,自己也需要划 分成多个Region。这就意味着可能有多个RegionServer在管理.META.。怎么办?在ZooKeeper里面存储所有管理.META.的 RegionServer地址让Client自己去遍历?HBase并不是这么做的。
HBase的做法是用另外一个表来记录.META.的Region信息,就和.META.记录用户表的Region信息一模一样。这个表就是-ROOT-表。这也解释了为什么-ROOT-和.META.拥有相同的表结构,因为他们的原理是一模一样的。
假设.META.表被分成了两个Region,那么-ROOT-的内容看上去大概是这个样子的:
-ROOT-行记录结构

这么一来Client端就需要先去访问-ROOT-表。所以需要知道管理-ROOT-表的RegionServer的地址。这个地址被存在ZooKeeper中。默认的路径是:
/hbase/root-region-server
等等,如果-ROOT-表太大了,要被分成多个Region怎么办?嘿嘿,HBase认为-ROOT-表不会大到那个程度,因此-ROOT-只会有一个Region,这个Region的信息也是被存在HBase内部的。
现在让我们从头来过,我们要查询Table2中RowKey是RK10000的数据。整个路由过程的主要代码在org.apache.hadoop.hbase.client.HConnectionManager.TableServers中:
private HRegionLocation locateRegion(final byte[] tableName,
final byte[] row, boolean useCache) throws IOException {
if (tableName == null || tableName.length == 0) {
throw new IllegalArgumentException("table name cannot be null or zero length");
}
if (Bytes.equals(tableName, ROOT_TABLE_NAME)) {
synchronized (rootRegionLock) {
// This block guards against two threads trying to find the root
// region at the same time. One will go do the find while the
// second waits. The second thread will not do find.
if (!useCache || rootRegionLocation == null) {
this.rootRegionLocation = locateRootRegion();
}
return this.rootRegionLocation;
}
} else if (Bytes.equals(tableName, META_TABLE_NAME)) {
return locateRegionInMeta(ROOT_TABLE_NAME, tableName, row, useCache, metaRegionLock);
} else {
// Region not in the cache – have to go to the meta RS
return locateRegionInMeta(META_TABLE_NAME, tableName, row, useCache, userRegionLock);
}
}
这是一个递归调用的过程:
获取Table2,RowKey为RK10000的RegionServer => 获取.META.,RowKey为Table2,RK10000, 99999999999999的RegionServer => 获取-ROOT-,RowKey为.META.,Table2,RK10000,99999999999999,99999999999999的RegionServer => 获取-ROOT-的RegionServer => 从ZooKeeper得到-ROOT-的RegionServer => 从-ROOT-表中查到RowKey最接近(小于) .META.,Table2,RK10000,99999999999999,99999999999999的一条Row,并得到.META.的RegionServer => 从.META.表中查到RowKey最接近(小于)Table2,RK10000, 99999999999999的一条Row,并得到Table2的RegionServer => 从Table2中查到RK10000的Row
到此为止Client完成了路由RegionServer的整个过程,在整个过程中使用了添加“99999999999999”后缀并查找最接近(小于)RowKey的方法。对于这个方法大家可以仔细揣摩一下,并不是很难理解。
最后要提醒大家注意两件事情:
1. 在整个路由过程中并没有涉及到MasterServer,也就是说HBase日常的数据操作并不需要MasterServer,不会造成MasterServer的负担。
2. Client端并不会每次数据操作都做这整个路由过程,很多数据都会被Cache起来。至于如何Cache,则不在本文的讨论范围之内。
原文: http://www.spnguru.com/2010/07/hbase%E4%B8%AD%E7%9A%84client%E5%A6 %82%E4%BD%95%E8%B7%AF%E7%94%B1%E5%88%B0%E6%AD%A3%E7%A1%AE%E7%9A%84regionserver/
client 如何找到正确的RegionServer(HBase -ROOT-和.META.表)的更多相关文章
- hbase源码系列(三)Client如何找到正确的Region Server
客户端在进行put.delete.get等操作的时候,它都需要数据到底存在哪个Region Server上面,这个定位的操作是通过HConnection.locateRegion方法来完成的. loc ...
- 三 Client 如何找到正确的 Region Server
客户端在进行put.delete.get等操作的时候,它都需要数据到底存在哪个Region Server上面,这个定位的操作是通过 Connection.locateRegion方法来完成的. loc ...
- 【转】hbase meta表修复
[From]https://www.iteye.com/blog/blackproof-2052898 meta表修复一 查看hbasemeta情况 hbase hbck .重新修复hbase met ...
- hbase meta表修复
meta表修复一 查看hbasemeta情况hbase hbck1.重新修复hbase meta表(根据hdfs上的regioninfo文件,生成meta表)hbase hbck -fixMeta2. ...
- HBase中的Client如何路由到正确的RegionServer
在HBase中,大部分的操作都是在RegionServer完成的,Client端想要插入,删除,查询数据都需要先找到相应的RegionServer.什么叫相应的RegionServer?就是管理你要操 ...
- HBase读写数据的详细流程及ROOT表/META表介绍
一.HBase读数据流程 1.Client访问Zookeeper,从ZK获取-ROOT-表的位置信息,通过访问-ROOT-表获取.META.表的位置,然后确定数据所在的HRegion位置: 2.Cli ...
- Hadoop HBase概念学习系列之META表和ROOT表(六)
在 HBase里的HRegion 里,谈过,HRegion是按照表名+开始/结束主键,即表名+主键范围来区分的.由于主键范围是连续的,所以一般用开始主键就可以表示相应的HRegion了. 不过,因为我 ...
- 异常-Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=hdfs, access=WRITE, inode="/hbase":root:supergroup:drwxr-xr-x
1 详细异常 Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlExce ...
- db2的select语句在db2 client上执行正确,JDBC连接数据库时报错
db2的select语句在db2 client上执行正确,JDBC连接数据库时报错. sql语句是:select ...from QUALIFIER.tableName fetch first 21 ...
随机推荐
- ubuntu无法进入和引导顺序问题解决
今天上班过来发现ubuntu无法进入,因为里面有N多资料没有备份,当时很是捉急.不过后来都解决了: 背景: easyBCD安装ubuntu14.07和windows7双系统.基本上这一年多一直用ubu ...
- Articulate Studio课间制作工具
Articulate Studio可以说是目前国际上用户最广泛的e-learning课件制作工具之 一,通过Articulate Studio,你可以方便.快捷的创建引人入胜的Flash演示和e-le ...
- ECshop模板机制
ECshop模板机制整理 模板机制 近期新项目涉及到ECshop的二次开发,趁此良机正好可以对闻名已久的ECshop系统进行深入了解.要了解一个系统,那么该系统的模板机制就是最重要的一环.相关整理如下 ...
- IDF实验室-简单的ELF逆向 writeup
题目:http://ctf.idf.cn/index.php?g=game&m=article&a=index&id=39 下载得到ElfCrackMe1文件,直接用IDA打开 ...
- ASP.Net Core-依赖注入IoC
一.Ioc IoC全称Inverse of Control,控制反转. 类库和框架的不同之处在于,类库是实现某种单一功能的API,框架是针对一个任务把这些单一功能串联起来形成一个完整的流程,这个流程在 ...
- DBHelper数据库操作类(二)
不错文章:http://www.codefans.net/articles/562.shtml http://www.cnblogs.com/gaobing/p/3878342.html using ...
- openssl enc 加解密
国内私募机构九鼎控股打造APP,来就送 20元现金领取地址:http://jdb.jiudingcapital.com/phone.html内部邀请码:C8E245J (不写邀请码,没有现金送)国内私 ...
- const和readonly差别
我们都知道,const和static readonly的确非常像:通过类名而不是对象名进行訪问,在程序中仅仅读等等.在多数情况下能够混用.二者本质的差别在于,const的值是在编译期间确定的,因此仅仅 ...
- 【iOS知识学习】_iOS动态改变TableView Cell高度
在做tableView的时候,我们有时候须要依据cell的高度动态来调整.近期在网上看到一段代码不错.跟大家Share一下. 在 -(UITableViewCell *)tableView:(UITa ...
- [React Native] Build a Github Repositories component
Nav to Repos component from Dashboard.js: goToRepos(){ api.getRepos(this.props.userInfo.login) .then ...