configure HDFS(hadoop 分布式文件系统) high available
注:来自尚学堂小陈老师上课笔记
1.安装启动zookeeper
a)上传解压zookeeper包
b)cp zoo_sample.cfg zoo.cfg修改zoo.cfg文件
c)dataDir=/opt/data/zookeeper
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
这里的node1是自己主机名,可以写ip
d)分别在node1 node2 node3 的数据目录/opt/data/zookeeper下面创建myid文件,里面写对应server.后面的数字
e)配置环境变量并source生效
export ZK_HOME=/opt/soft/zookeeper-3.4.6
export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZK_HOME/bin
f)启动 zkServer.sh start启动,隔一分钟,通过zkServer.sh status查看状态
2.配置hadoop配置文件
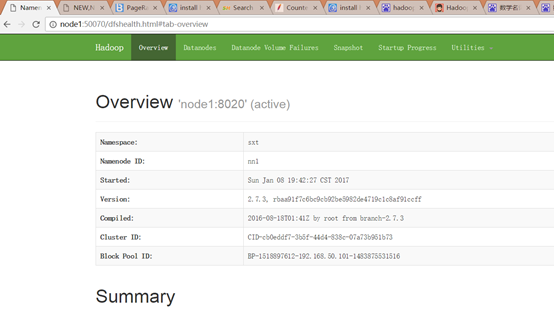
配置hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>sxt</value>
</property>
<property>
<name>dfs.ha.namenodes.sxt</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.sxt.nn1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.sxt.nn2</name>
<value>node2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.sxt.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.sxt.nn2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/sxt</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.sxt</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
配置core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://sxt</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/data/journal</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
3.启动所有journalnode
hadoop-daemon.sh start journalnode
4.其中一个namenode节点执行格式化
hdfs namenode -format
5.另外一个namenode节点格式化拷贝
首先要将刚才格式化之后的namenode启动起来
hadoop-daemon.sh start namenode
hdfs namenode -bootstrapStandby
6.上传配置到zookeeper集群
hdfs zkfc -formatZK
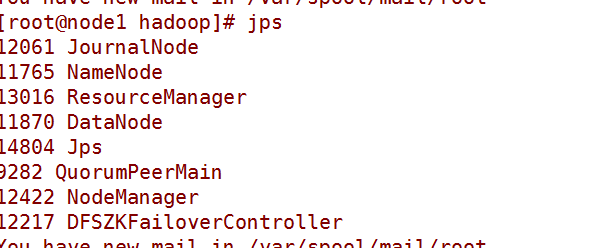
7.启动
先stop-dfs.sh
然后start-dfs.sh
hadoop-daemon.sh start namenode


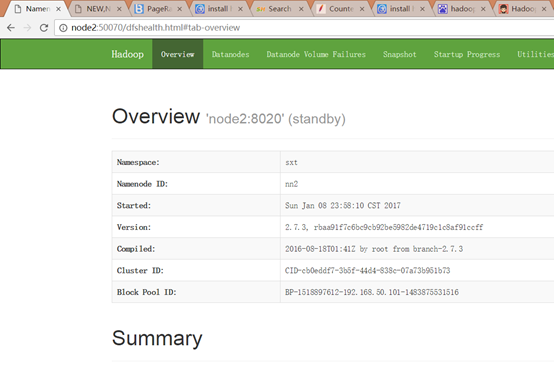
configure HDFS(hadoop 分布式文件系统) high available的更多相关文章
- Hadoop分布式文件系统HDFS详解
Hadoop分布式文件系统即Hadoop Distributed FileSystem. 当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区(Partition)并 ...
- Hadoop分布式文件系统HDFS的工作原理
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数据访问,非常适合大规模数据集上的应 ...
- HDFS(Hadoop Distributed File System )hadoop分布式文件系统。
HDFS(Hadoop Distributed File System )hadoop分布式文件系统.HDFS有如下特点:保存多个副本,且提供容错机制,副本丢失或宕机自动恢复.默认存3份.运行在廉价的 ...
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
- 对Hadoop分布式文件系统HDFS的操作实践
原文地址:https://dblab.xmu.edu.cn/blog/290-2/ Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop核 ...
- Hadoop分布式文件系统(HDFS)设计
Hadoop分布式文件系统是设计初衷是可靠的存储大数据集,并且使应用程序高带宽的流式处理存储的大数据集.在一个成千个server的大集群中,每个server不仅要管理存储的这些数据,而且可以执行应用程 ...
- Hadoop 分布式文件系统:架构和设计
引言 Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点.但同时,它和其他的分布式文件系统 ...
- 【官方文档】Hadoop分布式文件系统:架构和设计
http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html 引言 前提和设计目标 硬件错误 流式数据访问 大规模数据集 简单的一致性模型 “移动计 ...
- 在Hadoop分布式文件系统的索引和搜索
FROM:http://www.drdobbs.com/parallel/indexing-and-searching-on-a-hadoop-distr/226300241?pgno=3 在今天的信 ...
随机推荐
- js实现多张图片同时放大缩小相对位置不变
项目要求需要用js实现同时放大多张图片相对位置不变,就和同事去一家国外网站的js文件中跟踪扒取了这一算法, 庆幸的是算法抠出来了并整理了出来,但遗憾的只知计算过程却弄不明白算法原理: 大体上是核心运算 ...
- Ubuntu(Linux) + mono + jexus +asp.net MVC3
Ubuntu(Linux) + mono + jexus +asp.net MVC3 部署 感谢 张善友 的建议,我把 微信订餐 由nginx 改成 jexus,目前运行状况来说,确实稳定了很多, ...
- Strategic Game HDU
Strategic Game Time Limit: 20000/10000 MS (J ...
- bootstrap悬浮顶部或者底部
这是bootstrap提供的样式,只需要引入bootstrap.css即可. 需要使用的class样式: navbar navbar-inverse navbar-inner navbar-fixed ...
- .NET/Mono
C#(或者说.NET/Mono)能做的那些事 不做语言之争,只陈述事实: 1.桌面软件 不仅是在Windows上,有了开源的Mono,在Apple Mac和Linux(如:Ubuntu)上也有C#的施 ...
- C#外挂QQ
C#外挂QQ找茬辅助源码,早期开发 这是一款几年前开发的工具,当年作为一民IT纯屌,为了当年自己心目中的一位女神熬夜开发完成.女神使用后找茬等级瞬间从眼明手快升级为三只眼...每次看到这个就会想起 ...
- 认识WinDbg
WinDbg学习笔记(一)--认识WinDbg 一.前言 本人学习WinDbg已经有好几天了,虽说技术掌握的还不太熟练,不过也总算是入门了在学习WinDbg的过程中,觉得WinDbg真的比Oll ...
- python学习之路二(字符串,字典,序列和元组)
# -*- coding: utf-8 -* ''' Created on 2013-7-26 @author: lixingle ''' #!/usr/bin/python import math# ...
- C/C++ 中 const 修饰符用法总结
C/C++ 中 const 修饰符用法总结 在这篇文章中,我总结了一些C/C++语言中的 const 修饰符的常见用法,供大家参考. const 的用法,也是技术性面试中常见的基础问题,希望能够帮大家 ...
- C#HTTP代理的实现之注册表实现
HTTP代理的实现形式,可以通过修改注册表项,然后启动浏览器来实现,也可以通过SOCKET通信,构造HTTP头实现.下面是关于注册表实现的方式. 注册表实现,只需要修改几个关键的注册表项就可以了. 第 ...